Python + Apache Kylin 让数据分析更加简单!
现如今,大数据、数据科学和机器学习不仅是技术圈的热门话题,也是当今社会的重要组成。数据就在每个人身边,同时每天正以惊人的速度快速增长,据福布斯报道:到 2025 年,每年将产生大约 175 个 Zettabytes 的数据量。
目前我们所熟知的行业都越来越依赖于对大数据的高级处理和分析,如金融、医疗保健、农业、能源、媒体、教育等所有重要的社会发展行业,然而这些庞大的数据集让数据分析、数据挖掘、机器学习和数据科学面临了巨大的挑战。
数据科学家和分析师在尝试对于海量数据的分析时会面临数据处理流程复杂、报表查询缓慢等问题,但在实践中发现可通过 Apache Kylin 与 Python 的集成解决这一大难题,从而帮助分析师和数据科学家最终获得对大规模(TB 级和 PB 级)数据集的自由访问。
机器学习和数据科学面临的挑战
机器学习(ML)工程师和数据科学家在对大数据运行计算时遇到的主要挑战之一是处理更大容量的数据时带来的更大的计算复杂度 。
因此,随着数据集的扩大,即使是微不足道的操作也会变得昂贵。此外,随着数据量的增加,算法性能越来越依赖于用于存储和移动数据的技术架构,同时数据量越大,并行数据结构,数据分区和存储以及数据复用变得更加重要。

Apache Kylin 如何解决这些挑战?
Apache Kylin 是一个开源的分布式大数据分析引擎,旨在为 Hadoop上的多维分析(MOLAP)提供 SQL 接口。它允许企业使用和其他大数据分析工具相比更短的的时间快速分析海量数据集。
借助 Apache Kylin,数据团队能够大幅减少分析处理时间以及相关的 IT 和运营成本。它可以通过将大型数据集预先计算到一个(或另一个非常少量)的 OLAP 多维数据集中并将它们存储在列式数据库中来实现查询加速。这使机器学习工程师,数据科学家和分析师能够快速访问数据并执行数据挖掘,轻松发现数据中隐藏的趋势。
下图显示了在引入 Apache Kylin 时,大数据上的机器学习和数据科学活动如何变得更加简单。
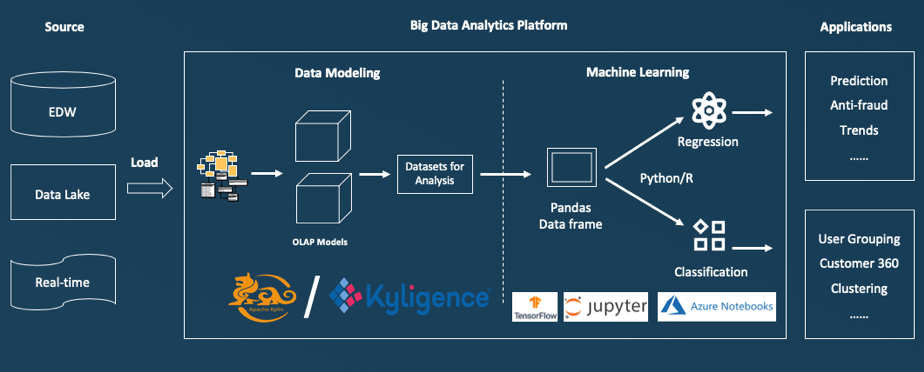 Apache Kylin 如何与大数据平台配合使用
Apache Kylin 如何与大数据平台配合使用
Apache Kylin 如何与 Python 集成
目前 Python 风头正盛,作为领先的编程语言之一,凭借其易用性和丰富的库,Python 已经在大数据中被广泛应用。
Python 还提供了大量数据挖掘工具来协助处理数据,同时也提供已经在机器学习和数据科学社区运行的应用程序。简而言之,如果您正在使用大数据,那么 Python 可能会让您的工作变得更轻松。
使用 Kylinpy 库,Apache Kylin 可以轻松与 Python 集成。Kylinpy 是一个提供 SQLAlchemy 方言实现的 Python 库。因此,任何使用 SQLAlchemy 的应用程序现在都可以查询 Kylin OLAP 多维数据集。此外,它还允许用户通过 Pandas 数据帧访问数据。
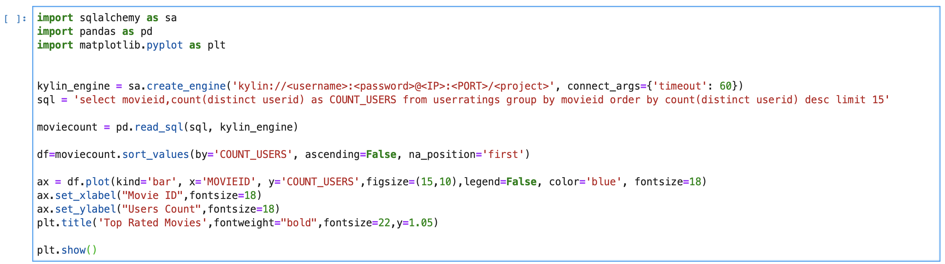
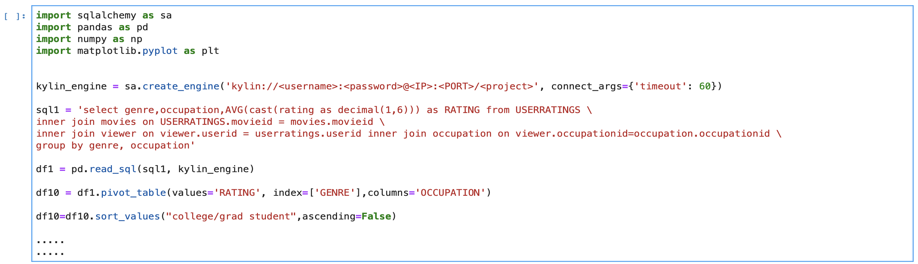
通过 Pandas 访问数据的示例代码:
 使用 Pandas 连接 Apache Kylin
使用 Pandas 连接 Apache Kylin
使用 Apache Kylin 作为数据源的好处
- 轻松访问海量数据集:交互式处理大量(TB / PB)数据。
- 提供标准 JDBC 接口。
- 超高性能:大数据查询亚秒级响应。
- 高扩展性:借助 Kylin 的横向扩展性,可以扩展数据,无需担心性能问题。
- 互联网级并发:支持数千个用户并发查询。
- 极简开发:释放开发人力,专注数据洞察。
用例:使用 Apache Kylin 进行高级分析
数据集:
我们将一个 IMDB 电影数据集(来源:Movielens)导入我们的 Kylin OLAP 多维数据集,并使用 Python 读取数据并执行探索性分析,以便在指定时间段内查找不同流派的电影评级趋势。
目的:
- 确定评分最高的电影。
- 比较男性与女性对不同电影类型的偏好。
- 找出观影人职业与电影流派之间的相关性。
- 分析几周内不同类型的电影评级趋势。
- 比较男女平均评分。
数据生命周期
为了通过 Python 分析数据,使用了 Kylinpy 库并编写了 SQL 来为相关分析提取相关数据。通过 SQL 返回的数据集存储为 Pandas 数据帧,然后对数据帧进行数据处理,以使数据形成适合我们分析的结构。我们利用 Matplotlib 和 Seaborn 库来可视化数据。下图说明了每个阶段的数据生命周期。
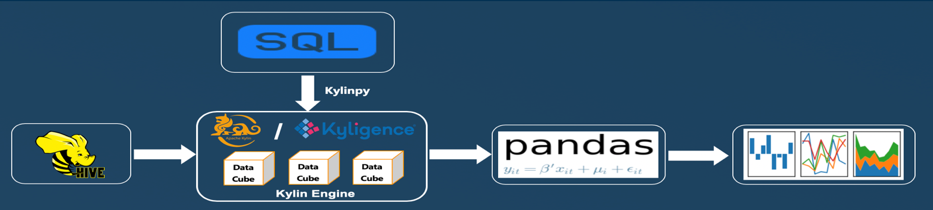 Apache Kylin 数据生命周期
Apache Kylin 数据生命周期
分析
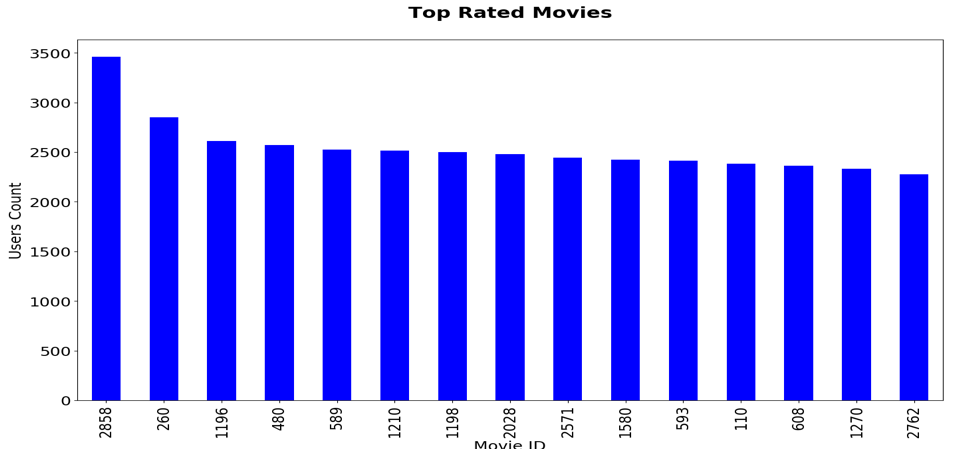
让我们首先看一下排名靠前的几部电影。可以看出,前 15 部电影中,除了前 2 部之外,13 部电影的评分人数几乎相同。此信息是相关发现的起点,可以进一步深入查找我们评分人数较高的电影之间的相关性。
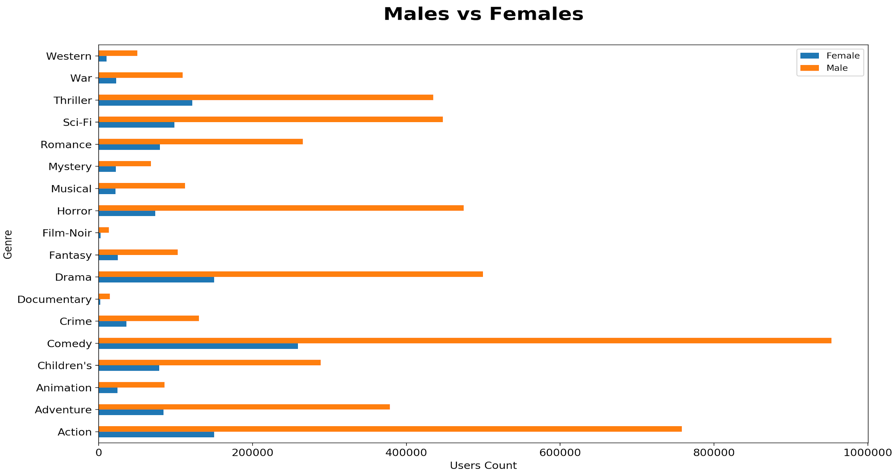
同样,下面的柱状图显示了每种流派电影的评分人的性别比较。这显示了男女观影时对不同流派电影的偏好。

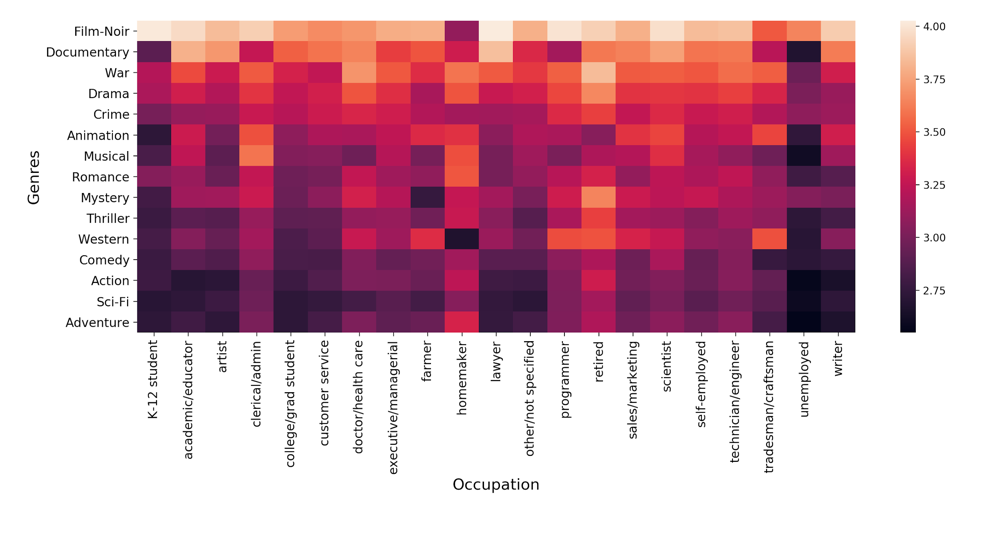
从下面的相关矩阵(热图)中,我们可以说出观影人职业和电影流派之间的关系。例如:农民不喜欢观看悬疑片,而大学生更喜欢侦探片或纪录片。
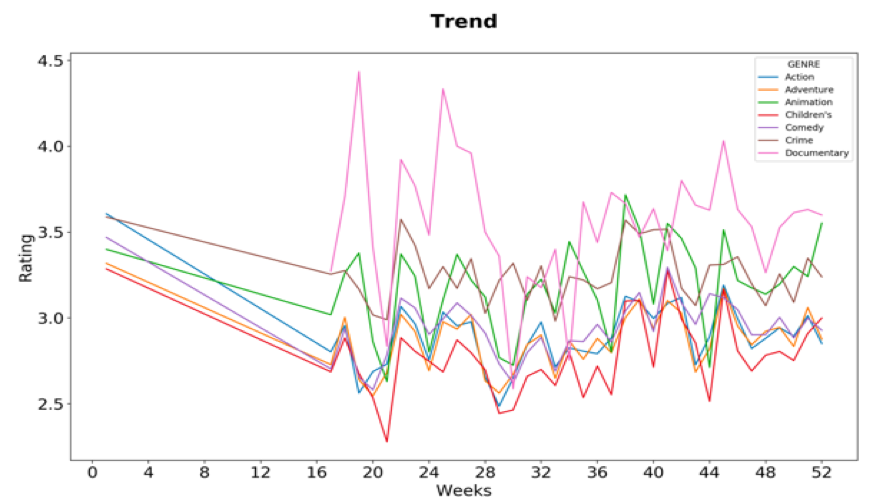
下图显示了某特定年份每周用户对不同流派电影的平均评分趋势。从图表中可以看出,纪录片和犯罪电影是人们的最爱,而儿童电影的平均评分总是最低的。
 Apache Kylin Python SQL 趋势线图
Apache Kylin Python SQL 趋势线图
下面的两个散点图用于并排比较,以推断男性和女性的评级之间的相关性。
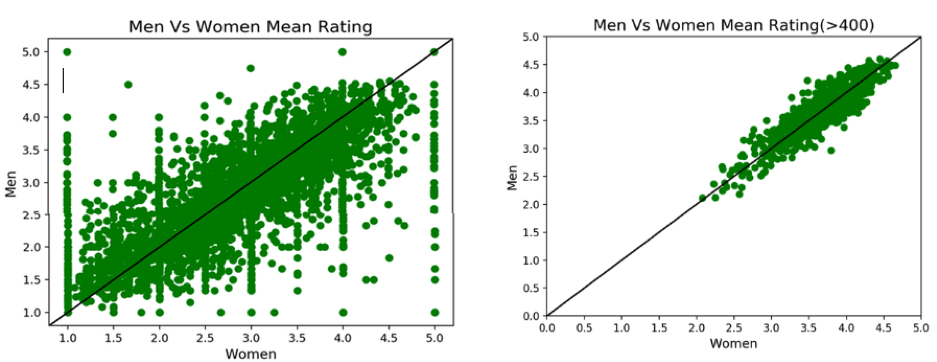
左图:散点图显示男性和女性(所有电影)的平均评分呈线性增长趋势,图中高度集中的部分均匀分布在参考线的两侧,这表明除了少数电影收视率,男性和女性观影偏好趋同。
右图:散点图是通过仅隔离评级超过 400 次的电影而产生的。在这种情况下,我们也可以看到男性和女性的评分相似,这表明我们的初步推论是准确的。
在 Apache Kylin 上开始使用 Python
我们讨论了 Python 如何使用 Kylinpy 库轻松地与 Apache Kylin 的 OLAP 技术集成,而 Kylinpy 库又用于在我们的示例电影数据集上运行高级分析。我们还使用 Pandas,Matplotlib 和 Seaborn 库来操作和可视化 Apache Kylin 多维数据集中的数据。
这样的分析让我们深入了解人们对不同电影类型的喜好随着时间的推移而变化。它还告诉我们不同电影类型变化趋势之间的关联度。像这样的见解可能对电影评论家有用。
如果您或您的团队在访问大量数据集时遇到问题,并希望利用 Kylin 的大数据 OLAP 方法进行机器学习或数据科学操作,那么 Apache Kylin(及其相关企业大数据平台 Kyligence)将为您提供帮助。
Python + Apache Kylin 让数据分析更加简单!的更多相关文章
- Apache Kylin大数据分析平台的演进
转:http://mt.sohu.com/20160628/n456602429.shtml 我是来自Kyligence的李扬,是上海Kyligence的联合创始人兼CTO.今天我主要来和大家分享一下 ...
- 《基于Apache Kylin构建大数据分析平台》
Kyligence联合创始人兼CEO,Apache Kylin项目管理委员会主席(PMC Chair)韩卿 武汉市云升科技发展有限公司董事长,<智慧城市-大数据.物联网和云计算之应用>作者 ...
- 【转】使用Apache Kylin搭建企业级开源大数据分析平台
http://www.thebigdata.cn/JieJueFangAn/30143.html 本篇文章整理自史少锋4月23日在『1024大数据技术峰会』上的分享实录:使用Apache Kylin搭 ...
- 大数据分析神兽麒麟(Apache Kylin)
1.Apache Kylin是什么? 在现在的大数据时代,越来越多的企业开始使用Hadoop管理数据,但是现有的业务分析工具(如Tableau,Microstrategy等)往往存在很大的局限,如难以 ...
- 大数据分析界的“神兽”Apache Kylin有多牛?【转】
本文作者:李栋,来自Kyligence公司,也是Apache Kylin Committer & PMC member,在加入Kyligence之前曾就职于eBay.微软. 1.Apache ...
- 使用Apache Kylin搭建企业级开源大数据分析平台
转:http://www.thebigdata.cn/JieJueFangAn/30143.html 我先做一个简单介绍我叫史少锋,我曾经在IBM.eBay做过大数据.云架构的开发,现在是Kylige ...
- Python运用于数据分析的简单教程
Python运用于数据分析的简单教程 这篇文章主要介绍了Python运用于数据分析的简单教程,主要介绍了如何运用Python来进行数据导入.变化.统计和假设检验等基本的数据分析,需要的朋友可以参考下 ...
- 国人之光:大数据分析神器Apache Kylin
一.简介 Apache Kylin是一个开源的.分布式的分析型数据仓库,提供Hadoop/Spark 之上的 SQL 查询接口及多维分析(OLAP)能力以支持超大规模数据,最初由 eBay 开发并贡献 ...
- Apache Kylin 概述
1 Kylin是什么 今天,随着移动互联网.物联网.AI等技术的快速兴起,数据成为了所有这些技术背后最重要,也是最有价值的"资产".如何从数据中获得有价值的信息?这个问题驱动了相关 ...
随机推荐
- ubuntu 使用新添加的用户登录只有$解决方法
在ubuntu中,使用useradd新建的用户,默认使用的shell是dash,导致界面不美观,操作也不舒服. 情况如下: 只有美元符,不显示用户,很多乱码,且文件没有颜色. 解决方法,将该用户使用的 ...
- Python小知识点+保留字
注意 !/usr/bin/python # -- coding: UTF-8 -- #中文编码 Python空行:函数之间或类的方法之间用空行分隔,表示一段新的代码的开始 Python注释:单行注释采 ...
- magicbook 踩坑
新买了 magicbook pro 16.1寸的荣耀笔记本,在使用过程中发现了一些问题. 电脑详情 规格: magicbook pro 16.1 cpu: 锐龙 R5 操作系统: deepin 15. ...
- Hadoop2-认识Hadoop大数据处理架构-单机部署
一.Hadoop原理介绍 1.请参考原理篇:Hadoop1-认识Hadoop大数据处理架构 二.centos7单机部署hadoop 前期准备 1.创建用户 [root@web3 ~]# useradd ...
- 5_PHP数组_3_数组处理函数及其应用_8_数组与数据结构
以下为学习孔祥盛主编的<PHP编程基础与实例教程>(第二版)所做的笔记. 数组与数据结构 1. array_push() 函数 程序: <?php $stack = array(&q ...
- python 简单工厂模式
abc 是抽象类模块abc.ABC 是继承抽象类 也可直接继承 (metaclass=ABCMeta)abc.abstractmethod 是定义抽象方法 简单工厂模式:通过接口创建对象,但不会暴露 ...
- Django:MTV——模版语句
1.Django框架介绍 1.1MVC框架(Model View Controller) 全名是Model View Controller ,是软件工程中的一种软件架构模式,把软件分为三个基本部分 ...
- Swift 4 中的泛型
作为Swift中最重要的特性之一,泛型使用起来很巧妙.很多人都不太能理解并使用泛型,特别是应用开发者.泛型最适合libraries, frameworks, and SDKs的开发.在这篇文章中,我将 ...
- Ubuntu安装usb库
sudo pip install pyserial sudo pip install pyusb
- 浅析MySQL使用 GROUP BY 分组聚合与细分聚合
原创文章,转载请注明出处:http://www.cnblogs.com/weix-l/p/7521278.html: 若有错误,请评论指出,谢谢! 1. 聚合函数(Aggregate Function ...