18、Python模块基础
一、模块
模块可以看成是一堆函数的集合体。
一个py文件内部就可以放一堆函数,因此一个py文件就可以看成一个模块。
如果这个py文件的文件名为module.py,模块名则是module。
1、模块的四种形式
在Python中,总共有以下四种形式的模块:
- 自定义模块:如果你自己写一个py文件,在文件内写入一堆函数,则它被称为自定义模块,即使用python编写的.py文件
- 第三方模块:已被编译为共享库或DLL的C或C++扩展
,如requests - 内置模块:使用C编写并链接到python解释器的内置模块
,如time - 包(文件夹):把一系列模块组织到一起的文件夹(注:文件夹下有一个__init__.py文件,该文件夹称之为包)
2、为什么要用模块?
- 用第三方或者内置的模块是一种拿来主义,可以极大地提升开发效率。
- 自定义模块,将我们自己程序中用到的公共功能,写入一个python文件,然后程序的各部分组件可以通过导入的方式来引用自定义模块的功能。
二、如何用模块
一般我们使用import和from...import...导入模块。
以下述spam.py内的文件代码为例。
# spam.py
print('from the spam.py')
money = 1000
def read1():
print('spam模块:', money)
def read2():
print('spam模块')
read1()
def change():
global money
money = 0
1、import 模块名
语法如下:
import module1[, module2[,... moduleN]
import导入的模块,访问需要加前缀。
import首次导入模块发生了3件事:
- 以模块为准创造一个模块的名称空间
- 执行模块对应的文件,将执行过程中产生的名字都丢到模块的名称空间
- 在当前执行文件中拿到一个模块名
注意:模块的重复导入会直接引用之前创造好的结果,不会重复执行模块的文件。
# run.py
import spam # from the spam.py
import spam
money = 111111
spam.read1() # 'spam模块:1000'
spam.change()
print(spam.money) #
print(money) #
导入重命名:smt变量指向span模块的名称空间
# run.py
import spam as sm
money = 111111
sm.money
sm.read1() # 'spam模块:1000'
sm.read2
sm.change()
print(money) #
导入多个模块
import spam, time, os
# 推荐使用下述方式
import spam
import time
import os
2、from 模块名 import 具体的函数
语法如下:
from modname import name1[, name2[, ... nameN]]
这个声明不会把整个模块导入到当前的命名空间中,它只会将模块里的一个或多个函数引入进来。
from...import...导入的模块,访问不需要加前缀。
from...import...首次导入模块发生了3件事:
- 以模块为准创造一个模块的名称空间
- 执行模块对应的文件,将执行过程中产生的名字都丢到模块的名称空间
- 在当前执行文件的名称空间中拿到一个名字,该名字直接指向模块中的某一个名字,意味着可以不用加任何前缀而直接使用
- 优点:不用加前缀,代码更加精简
- 缺点:容易与当前执行文件中名称空间中的名字冲突
# run.py
from spam import money
from spam import money,read1
money = 10
print(money) #
rom … import * 语句:导入文件内所有的功能:
# spam.py
__all__ = ['money', 'read1'] # 只允许导入'money'和'read1'
# run.py
from spam import * # 导入spam.py内的所有功能,但会受限制于__all__
money = 111111
read1() # 'spam模块:1000'
change()
read1() # 'spam模块:0'
print(money) #
3、循环导入
以下情况会出现循环导入:
# m1.py
print('from m1.py')
from m2 import x
y = 'm1'
# m2.py
print('from m2.py')
from m1 import y
x = 'm2'
可以使用函数定义阶段只识别语法的特性解决循环导入的问题,或从本质上解决循环导入的问题,但是最好的解决方法是不要出现循环导入。
方案一:
# m1.py
print('from m1.py')
def func1():
from m2 import x
print(x)
y = 'm1'# m2.py
print('from m2.py')
def func1():
from m1 import y
print(y)
x = 'm2'方案二:
5、# m1.py
print('from m1.py')
y = 'm1'
from m2 import x# m2.py
print('from m2.py')
x = 'm2'
from m1 import y
4、dir() 函数
内置的函数 dir() 可以找到模块内定义的所有名称。以一个字符串列表的形式返回:
dir(sys)
['__displayhook__', '__doc__', '__excepthook__', '__loader__', '__name__',
'__package__', '__stderr__', '__stdin__', '__stdout__',
'_clear_type_cache', '_current_frames', '_debugmallocstats', '_getframe',
'_home', '_mercurial', '_xoptions', 'abiflags', 'api_version', 'argv',
'base_exec_prefix', 'base_prefix', 'builtin_module_names', 'byteorder',
'call_tracing', 'callstats', 'copyright', 'displayhook',
'dont_write_bytecode', 'exc_info', 'excepthook', 'exec_prefix',
'executable', 'exit', 'flags', 'float_info', 'float_repr_style',
'getcheckinterval', 'getdefaultencoding', 'getdlopenflags',
'getfilesystemencoding', 'getobjects', 'getprofile', 'getrecursionlimit',
'getrefcount', 'getsizeof', 'getswitchinterval', 'gettotalrefcount',
'gettrace', 'hash_info', 'hexversion', 'implementation', 'int_info',
'intern', 'maxsize', 'maxunicode', 'meta_path', 'modules', 'path',
'path_hooks', 'path_importer_cache', 'platform', 'prefix', 'ps1',
'setcheckinterval', 'setdlopenflags', 'setprofile', 'setrecursionlimit',
'setswitchinterval', 'settrace', 'stderr', 'stdin', 'stdout',
'thread_info', 'version', 'version_info', 'warnoptions']
如果没有给定参数,那么 dir() 函数会罗列出当前定义的所有名称:
a = [1, 2, 3, 4, 5]
import fibo
fib = fibo.fib
print(dir()) # 得到一个当前模块中定义的属性列表
# ['__builtins__', '__name__', 'a', 'fib', 'fibo', 'sys'] b = 5 # 建立一个新的变量 'a'
print(dir())
# ['__annotations__', '__builtins__', '__cached__', '__doc__', '__file__', '__loader__', '__name__', '__package__', '__spec__', 'a', 'b']
del b # 删除变量名a
print(dir())
# ['__annotations__', '__builtins__', '__cached__', '__doc__', '__file__', '__loader__', '__name__', '__package__', '__spec__', 'a']
三、模块搜索路径
1、导入模块时查找模块的顺序
1、先从内存中已经导入的模块中寻找
如果我们在运行run.py文件的时候,快速删除mmm.py文件,我们会发现文件会继续运行,而不会报错,因为mmm已经被导入内存当中。如果我们再一次运行run.py时会报错,因为mmm.py已经被删除了。
# test.py
import m1 # 从m1.py文件中导入的,然后会生成m1模块的名称空间
import time
# 删除m1.py文件,m1模块的名称空间仍然存在 time.sleep(10)
import m1 # 不报错,一定不是从文件中获取了m1模块,而是从内存中获取的
2、内置的模块
验证先从内置中找,不会先找自定义的time.py文件。
# time.py
print('from time.py')
# run.py
import time
print(time) # <module 'time' (built-in)>
3、环境变量sys.path中找(强调:sys.path的第一个值是当前执行文件的所在的文件夹)
import sys
for n in sys.path:
print(n)
# C:\PycharmProjects\untitled\venv\Scripts\python.exe C:/PycharmProjects/untitled/hello.py
# C:\PycharmProjects\untitled
# C:\PycharmProjects\untitled
# C:\Python\Python38\python38.zip
# C:\Python\Python38\DLLs
# C:\Python\Python38\lib
# C:\Python\Python38
# C:\PycharmProjects\untitled\venv
# C:\PycharmProjects\untitled\venv\lib\site-packages
如果mmm.py在C:\PycharmProjects\untitled\day16路径下,而执行文件路径为C:\PycharmProjects\untitled,如果普通导入一定会报错,我们可以把C:\PycharmProjects\untitled\day16添加到环境变量sys.path中,防止报错。
# run.py
import sys
sys.path.append(r'C:\PycharmProjects\untitled\day16')
print(sys.path)
import mmm
mmm.f1()
2、搜索路径以执行文件为准
假设我们有如下目录结构的文件,文件内代码分别是:
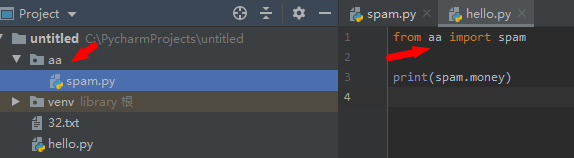
而hello和spam.py不是同目录下的,因此run.py的环境变量无法直接找到m2,需要从文件夹导入
from aa import spam
print(spam.money)
四、Python文件的两种用途
一个模块被另一个程序第一次引入时,其主程序将运行。如果我们想在模块被引入时,模块中的某一程序块不执行,我们可以用__name__属性来使该程序块仅在该模块自身运行时执行。
python文件总共有两种用途,一种是执行文件;另一种是被当做模块导入。
每个模块都有一个__name__属性,当其值是'__main__'时,表明该模块自身在运行,否则是被引入。
1、当run.py运行的时候,aaa.py被当做引用模块,它的__name__ == 'aaa'(模块名),会执行aaa.py中的f1()。
# aaa.py
x = 1
def f1():
print('from f1')
f1()
# run.py
import aaa
2、aaa.py被当做可执行文件时,加上__name__ == '__main__',单独运行aaa.py才会执行aaa.py中的f1()。 run.py运行时可以防止执行f1()。
# aaa.py
x = 1
def f1():
print('from f1') if __name__ == '__main__':
f1()
五、包
包是一种管理 Python 模块命名空间的形式,包的本质就是一个含有.py的文件的文件夹。
包采用"点模块名称"。比如一个模块的名称是 A.B, 那么他表示一个包 A中的子模块 B 。
目录只有包含一个叫做 __init__.py 的文件才会被认作是一个包。
在导入一个包的时候,Python 会根据 sys.path 中的目录来寻找这个包中包含的子目录。
导入包发生的三件事:
- 创建一个包的名称空间
- 由于包是一个文件夹,无法执行包,因此执行包下的.py文件,将执行过程中产生的名字存放于包名称空间中(即包名称空间中存放的名字都是来自于.py)
- 在当前执行文件中拿到一个名字aaa,aaa是指向包的名称空间的
导入包就是在导入包下的.py,导入m1就是导入m1中的__init__。
1、两种方式导入:
- import ...
:
import item.subitem.subsubitem 这种导入形式,除了最后一项,都必须是包,而最后一项则可以是模块或者是包,但是不可以是类,函数或者变量的名字。 - from ... import...:
当使用 from package import item 这种形式的时候,对应的 item 既可以是包里面的子模块(子包),或者包里面定义的其他名称,比如函数,类或者变量。
 ‘
‘
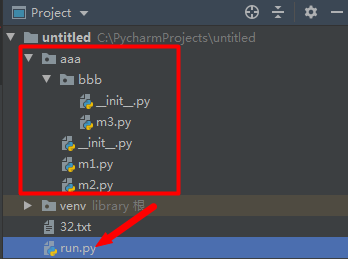
2、import 导入包内的模块
import 可以每次只导入一个包里面的特定模块,他必须使用全名去访问。
import aaa.bbb.m3
print(aaa.bbb.m3.func3())
import方式不能导入函数、变量:import aaa.bbb.m3.f3错误
3、from import方式:
导入模块内具体的模块
这种方式不需要那些冗长的前缀进行访问
from aaa.bbb import m3
print(m3.func3())
导入模块内具体的功能
这种方式不需要那些冗长的前缀进行访问
from aaa.bbb.m3 import func3
print(func3())
4、 绝对导入和相对导入
绝对导入:
# aaa/.py
from aaa.m1 import func1
from aaa.m2 import func2
相对导入:
- .代表当前被导入文件所在的文件夹
- ..代表当前被导入文件所在的文件夹的上一级
- ...代表当前被导入文件所在的文件夹的上一级的上一级
from .m1 import func1
from .m2 import func2
5、from...import *
导入语句遵循如下规则:如果包定义文件 __init__.py 存在一个叫做 __all__ 的列表变量,那么在使用 from package import * 的时候就把这个列表中的所有名字作为包内容导入。
这里有一个例子,在:file:sounds/effects/__init__.py中包含如下代码:
__all__ = ["echo", "surround", "reverse"]
这表示当你使用from sound.effects import *这种用法时,你只会导入包里面这三个子模块。
六、软件开发的目录规范
为了提高程序的可读性与可维护性,我们应该为软件设计良好的目录结构,这与规范的编码风格同等重要,简而言之就是把软件代码分文件目录。假设你要写一个ATM软件,你可以按照下面的目录结构管理你的软件代码:
ATM/
|-- core/
| |-- src.py # 业务核心逻辑代码
|
|-- api/
| |-- api.py # 接口文件
|
|-- db/
| |-- db_handle.py # 操作数据文件
| |-- db.txt # 存储数据文件
|
|-- lib/
| |-- common.py # 共享功能
|
|-- conf/
| |-- settings.py # 配置相关
|
|-- bin/
| |-- run.py # 程序的启动文件,一般放在项目的根目录下,因为在运行时会默认将运行文件所在的文件夹作为sys.path的第一个路径,这样就省去了处理环境变量的步骤
|
|-- log/
| |-- log.log # 日志文件
|
|-- requirements.txt # 存放软件依赖的外部Python包列表,详见https://pip.readthedocs.io/en/1.1/requirements.html
|-- README # 项目说明文件settings.py
# settings.py
import os
BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
DB_PATH = os.path.join(BASE_DIR, 'db', 'db.txt')
LOG_PATH = os.path.join(BASE_DIR, 'log', 'user.log')
# print(DB_PATH)
# print(LOG_PATH)
common.py
# common.py
import time
from conf import settings
def logger(msg):
current_time = time.strftime('%Y-%m-%d %X')
with open(settings.LOG_PATH, mode='a', encoding='utf-8') as f:
f.write('%s %s' % (current_time, msg))
src.py
# src.py
from conf import settings
from lib import common
def login():
print('登陆')
def register():
print('注册')
name = input('username>>: ')
pwd = input('password>>: ')
with open(settings.DB_PATH, mode='a', encoding='utf-8') as f:
f.write('%s:%s\n' % (name, pwd))
# 记录日志。。。。。。
common.logger('%s注册成功' % name)
print('注册成功')
def shopping():
print('购物')
def pay():
print('支付')
def transfer():
print('转账')
func_dic = {
'': login,
'': register,
'': shopping,
'': pay,
'': transfer,
}
def run():
while True:
print("""
1 登陆
2 注册
3 购物
4 支付
5 转账
6 退出
""")
choice = input('>>>: ').strip()
if choice == '': break
if choice not in func_dic:
print('输入错误命令,傻叉')
continue
func_dic[choice]()
run.py
# run.py
import sys
import os
BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
sys.path.append(BASE_DIR)
from core import src
if __name__ == '__main__':
src.run()
七、Python标准库
https://docs.python.org/zh-cn/3.8/library/index.html
18、Python模块基础的更多相关文章
- Python基础篇【第5篇】: Python模块基础(一)
模块 简介 在计算机程序的开发过程中,随着程序代码越写越多,在一个文件里代码就会越来越长,越来越不容易维护. 为了编写可维护的代码,我们把很多函数分组,分别放到不同的文件里,这样,每个文件包含的代码就 ...
- 18 Python 模块引入
Python 模块(Module),是一个 Python 文件,以 .py 结尾,包含了 Python 对象定义和Python语句. 模块让你能够有逻辑地组织你的 Python 代码段. 把相关的代码 ...
- 18.Python模块包(pycharm右键创建文件夹和python package的区别)中__init__.py文件的作用
原来在python模块的每一个包中,都有一个__init__.py文件(这个文件定义了包的属性和方法)然后是一些模块文件和子目录,假如子目录中也有 __init__.py 那么它就是这个包的子包了.当 ...
- python模块基础之json,requeste,xml,configparser,logging,subprocess,shutil。
1.json模块 json 用于[字符串]和 [python基本数据类型] 间进行转换(可用于不同语言之前转换),json.loads,将字符串转成python的基本数据类型,json.dum ...
- python 模块基础 和常用的模块
模块的定义 一个模块就是以.py结尾的python 文件,用来从逻辑上组织python代码.注意,模块名和变量名一样开头不能用数字,可以是双下划线和字母. 为什么要用模块? 将一些复杂的需要重复使用的 ...
- python 模块基础介绍
从逻辑上组织代码,将一些有联系,完成特定功能相关的代码组织在一起,这些自我包含并且有组织的代码片段就是模块,将其他模块中属性附加到你的模块的操作叫做导入. 那些一个或多个.py文件组成的代码集合就称为 ...
- python模块基础之OS模块
OS模块简单的来说它是一个Python的系统编程的操作模块,可以处理文件和目录这些我们日常手动需要做的操作. 可以查看OS模块的帮助文档: >>> import os #导入os模块 ...
- python模块基础之getpass模块
getpass模块提供了可移植的密码输入,一共包括下面两个函数: 1. getpass.getpass() 2. getpass.getuser() getpass.getpass([prompt[, ...
- Python模块基础
概念: 在Python中,一个.py文件就称之为一个模块(Module) 好处: 1. 提高可维护性 2. 可重用 3. 避免函数名.变量名冲突. 每个模块有独立的命名空间,因此相同名字的函数和变量完 ...
随机推荐
- python 本地时间+8小时
current_time = (datetime.datetime.now() + datetime.timedelta(hours=8)).strftime('%Y-%m-%d %H:%M:%S')
- Delphi 开发微信公众平台 (二)- 用户管理
一.用户标签管理 开发者可以使用用户标签管理的相关接口,实现对公众号的标签进行创建.查询.修改.删除等操作,也可以对用户进行打标签.取消标签等操作. 1.创建标签 /// <summary> ...
- FPGA 开发板入手途径有哪些呢?
买到一块 FPGA 开发板,你如何入手呢? 根据博主的经验,你可以通过如下途径来学习: 1.如果你是淘宝上买的,那么可以在淘宝上搜索你的开发板(一般 FPGA 开发板生厂商在淘宝上卖都会附带教程,如米 ...
- 【拆分版】Docker-compose构建Kibana单实例,基于7.1.0
写在前边 今凌晨的时候已经把这整个Docker-compose构建的ELK集群跑起来了,有点没熬住,所以早上起来补文档,今天就上到公司测试服务器上测试了,好开森. 本文内容就是红框的部分,只是启动个K ...
- standard_init_linux.go:178: exec user process caused "no such file or directory"
golang docker build 制作完进项后运行报错 出现该问题的原因是编译的环境和运行的环境不同,可能有动态库的依赖 1.默认go使用静态链接,在docker的golang环境中默认是使用动 ...
- 简洁的 Python Schema
目录 Python Schema使用说明 1. Schema是什么? 2. 安装 1. 给Schema类传入类型(int.str.float等) 2. 给Schema类传入可调用的对象(函数.带__c ...
- 【java】java删除文件delete和deleteOnExit 方法的区别,为什么调用deleteOnExit无效?
delete() 是即刻删除 public boolean delete() { SecurityManager security = System.getSecurityManager(); if ...
- C# Dapper 的简单实用
首先引入dapper PM>Install-Package Dapper -Version 2.0.4 (可能会出现因版本问题而安装失败详情见官网:https://stackexchange. ...
- gcc 编译过程
gcc 编译过程从 hello.c 到 hello(或 a.out)文件, 必须历经 hello.i. hello.s. hello.o,最后才得到 hello(或a.out)文件,分别对应着预处理. ...
- Python基础之面向对象编程
面向对象编程 —— Object Oriented Programming 简写 OOP 01. 面向对象基本概念 我们之前学习的编程方式就是 面向过程 的 面向过程 和 面向对象,是两种不同的 编程 ...