datanode启动异常(Incompatible clusterIDs)
问题:
正常start-all.sh无法启动datanode进程,但是./hadoop-daemon.sh start datanode又可以启动。过一会后datanode进程又莫名消失。
原理:
多次hdfs namenode -format导致namenode生成了新的clusterID, 和datanode的不一致。
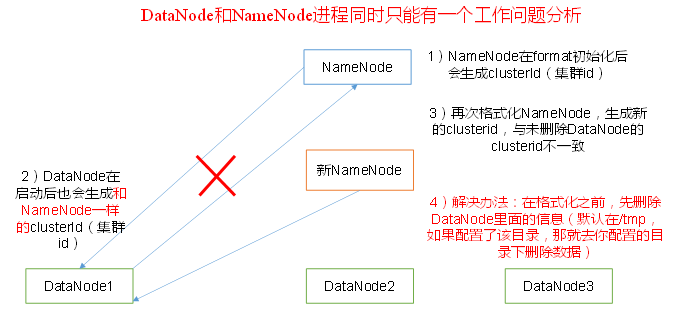
解决:
查日志,发现异常信息如下:
2019-07-22 17:46:09,856 WARN org.apache.hadoop.hdfs.server.common.Storage: Failed to add storage directory [DISK]file:/home/wjy/hadoop/tmp/dfs/data
java.io.IOException: Incompatible clusterIDs in /home/wjy/hadoop-3.1.1/tmp/dfs/data: namenode clusterID = CID-8041cf56-7cbd-423e-a0b6-f782c1e1340f; datanode clusterID = CID-0d8412e3-e59b-4b1b-acdf-871b8cfa2f79
照着网上说的删除本地dfs.data.dir下的所有内容然后重启进程并没有解决我的问题。这个dfs.data.dir是在hdfs-site.xml里找的(由于我用的hadoop3.1.1,所以是dfs.datanode.data.dir):

把data下面的current文件夹删了以后再次格式化namenode,还是那个问题,不同的是namenode的clusterID发生了改变(这很正常,因为重新格式化以后又生成了新的clusterID),datanode的clusterID却一直没变。按理说datanode的clusterID应该是在data/current/VERSION里面被记录的,但是现在我根本就把这个文件夹给删掉了。。。 而且启动datanode时应该会生成一个和namenode一样的clusterID的,并没有。把namenode的VERSION给复制过去做适当的修改还是没用。
后来我发现在下图这个路径下面还有一个data文件夹,下面的VERSION文件中的clusterID正是错误信息中的那个!
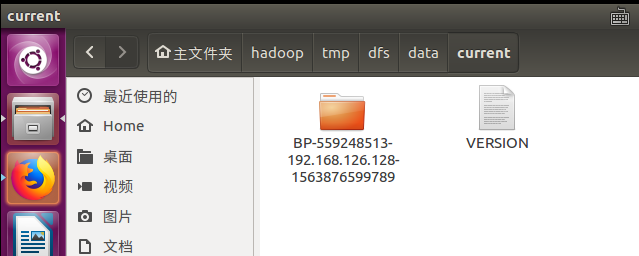
原来我之前删错了。。。 把这个current给删掉再重启一次datanode果然就好了(完全分布式记得要删除所有节点的哦,不然slave的datanode也会起不来的)。
可是很奇怪,为什么这个文件不生成在设置的dfs.datanode.name.dir的文件夹下面呢?而是在这个默认路径里面。
datanode启动异常(Incompatible clusterIDs)的更多相关文章
- hadoop2 datanode启动异常解决步骤
1.datanode起不来2016-11-25 09:46:43,685 WARN org.apache.hadoop.hdfs.server.datanode.DataNode: Invalid d ...
- hadoop异常: 到目前为止解决的最牛逼的一个异常(java.io.IOException: Incompatible clusterIDs)
(注意: 本人用的版本为hadoop2.2.0, 旧的版本和此版本的解决方法不同) 异常为: 9 (storage id DS-2102177634-172.16.102.203-50010-1384 ...
- hadoop集群启动报错: java.io.IOException: Incompatible clusterIDs
java.io.IOException: Incompatible clusterIDs in /export/hadoop-2.7.5/hadoopDatas/datanodeDatas2: nam ...
- 启动Hadoop HDFS时的“Incompatible clusterIDs”错误原因分析
"Incompatible clusterIDs"的错误原因是在执行"hdfs namenode -format"之前,没有清空DataNode节点的data目 ...
- 重新格式化namenode后,出现java.io.IOException Incompatible clusterIDs
错误: java.io.IOException: Incompatible clusterIDs in /data/dfs/data: namenode clusterID = CID-d1448b9 ...
- Hadoop问题:启动hadoop 2.6遇到的datanode启动不了
问题描述:第一次启动输入jps都有,第二次没有datanode 日志如下: 查看日志如下: -- ::, INFO org.mortbay.log: Started HttpServer2$Selec ...
- Hadoop2.6的DataNode启动不了
2016-05-04 18:14:51,990 INFO org.apache.hadoop.ipc.Server: IPC Server Responder: starting 2016-05-04 ...
- Hadoop错误:java.io.IOException: Incompatible clusterIDs
问题: 配置Hadoop集群时,一个节点的DataNode无法启动 排查: 查看hadoop-root-datanode-bigdata114.log文件,错误信息如下: java.io.IOExce ...
- 启动hadoop 2.6遇到的datanode启动不了
转自 http://blog.csdn.net/zhangt85/article/details/42078347 查看日志如下: 2014-12-22 12:08:27,264 INFO org.m ...
随机推荐
- .net core 从 ActionFilterAttribute 获取Request.Body 的正确方式
由于 ModelBinding在动作过滤器之前运行,直接使用 context.ActionArguments["parameter"] 获取模型对象 This article s ...
- ABP 00 常用知识
1.更改本地预览的端口: 文件路径:\src\ContractMS.Web.Mvc\Properties\launchSettings.json 改这里:"applicationUrl&qu ...
- PTES渗透测试执行标准
渗透测试注意事项: 1:测试一定要获得授权方才能进行,切勿进行恶意攻击 2:不要做傻事 3:在没有获得书面授权时,切勿攻击任何目标 4:考虑你的行为将会带来的后果 5:天网恢恢疏而不漏 渗透测试执行标 ...
- R 语言处理excel为data.frame
使用 R包 xlsx 或者 openxlsx 安装 install.packages("xlsx", repos="https://cloud.r-project.org ...
- java并发编程(八) CAS & Unsafe & atomic
参考文档:https://www.cnblogs.com/xrq730/p/4976007.html CAS(Compare and Swap) 一个CAS方法包含三个参数CAS(V,E,N).V表示 ...
- JS字符串转换为JSON的四种方法
转自:https://www.cnblogs.com/hgmyz/p/7451461.html 1.jQuery插件支持的转换方式: 示例: $.parseJSON( jsonstr ); //jQ ...
- Gamma阶段第一次scrum meeting
每日任务内容 队员 昨日完成任务 明日要完成的任务 张圆宁 #91 用户体验与优化:发现用户体验细节问题https://github.com/rRetr0Git/rateMyCourse/issues ...
- 【技术博客】Django+uginx+uwsgi框架的服务器部署
1.登录服务器 使用ssh来直接登录到服务器terminal进行操作,推荐使用XShell和XFtp来进行远程登录和文件传输. 2.运行环境准备 本组获得的华为云服务器为ubuntu16.04版本,先 ...
- Delphi XE7并行编程: 并行For循环
从Delphi XE7开始,引入了全新的并行编程库用于简化并行编程,它位于System.Threading单元中. 下面是一个判断素数的简单例子:function IsPrime (N: Intege ...
- 如何用 Go 实现热重启
热重启 热重启(Zero Downtime),指新老进程无缝切换,在替换过程中可保持对 client 的服务. 原理 父进程监听重启信号 在收到重启信号后,父进程调用 fork ,同时传递 socke ...