Jmeter学习笔记(二十)——后置处理器XPath Extractor使用
一、背景
在使用过程某些操作步骤与其相邻步骤存在一定的依赖关系,需要需要将上一个请求的响应结果作为下一个请求的参数。
Jmeter中后置处理器正则表达式提取器和XPath Extractor都可以将页面上置顶内容获取并保存到一个参数中。
所以可通过两步骤实现上面的需求:
①能够将返回页面上的指定内容保存在参数中;
②能够将GET或POST方法中的数据使用该参数来替换;
二、正则表达式提取器和XPath Extractor的区别
XPath Extractor的使用方法与正则表达式提取器(Regular Expression Extractor)类似,只不过该Expression中指定的不是正则表达式,而是给定的XPath路径。
正则表达式提取器和XPath Extractor的区别:
①正则表达式提取器可以用于对页面任何文本的提取,提取的内容是根据正则表达式在页面内容中进行文本匹配;
②XPath Extractor则可以提取返回页面任意元素的任意属性;
③如果需要提取的文本是页面上某元素的属性值,建议使用XPath Extractor;
④如果需要提取的文本在页面上的位置不固定,或者不是元素的属性,建议使用正则表达式提取器。
三、XPath Extractor界面及说明
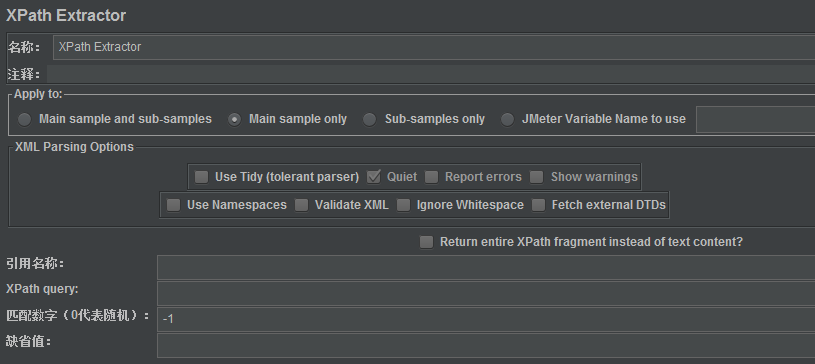
APPly to:作用范围(返回内容的断言范围)
Main sample and sub-samples:作用于父节点的取样器及对应子节点的取样器
Main sample only:仅作用于父节点的取样器
Sub-samples only:仅作用于子节点的取样器
JMeter Variable:作用于jmeter变量(输入框内可输入jmeter的变量名称)
XML Parsing Options:要解析的XML参数
Use Tidy:当需要处理的页面是HTML格式时,必须选中该选项;如果是XML或XHTML格式(例如RSS返回),则取消选中;
Quiet:表示只显示需要的HTML页面,
Report errors:表示显示响应报错,
Show warnings:表示显示警告;
Use Namespaces:如果启用该选项,后续的XML解析器将使用命名空间来分辨;
Validate XML:根据页面元素模式进行检查解析;
Ignore Whitespace:忽略空白内容;
Fetch external DTDs:如果选中该项,外部将使用DTD规则来获取页面内容;
Return entire XPath fragment of text content:返回文本内容的整个XPath片段;
Reference Name(引用名称):存放提取出的值的参数。
XPath Query:用于提取值的XPath表达式。
Default Value(缺省值):参数的默认值。
四、使用实例
1、比如需要提取如下响应文本中的这个元素的属性name的值

2、设置XPath Extractor

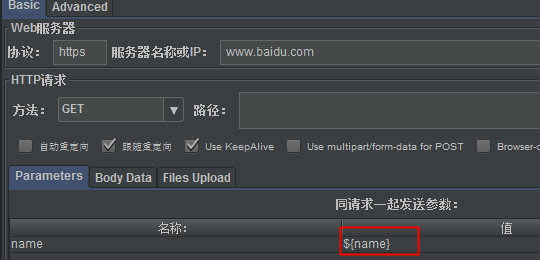
3、引用提取出来的值
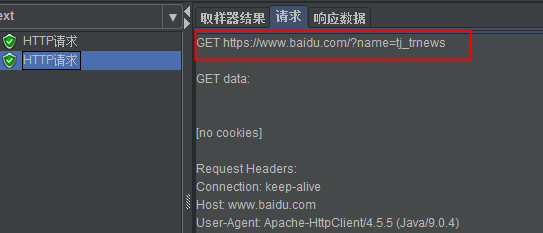
4、执行结果
Jmeter学习笔记(二十)——后置处理器XPath Extractor使用的更多相关文章
- python3.4学习笔记(二十六) Python 输出json到文件,让json.dumps输出中文 实例代码
python3.4学习笔记(二十六) Python 输出json到文件,让json.dumps输出中文 实例代码 python的json.dumps方法默认会输出成这种格式"\u535a\u ...
- python3.4学习笔记(二十四) Python pycharm window安装redis MySQL-python相关方法
python3.4学习笔记(二十四) Python pycharm window安装redis MySQL-python相关方法window安装redis,下载Redis的压缩包https://git ...
- python3.4学习笔记(二十五) Python 调用mysql redis实例代码
python3.4学习笔记(二十五) Python 调用mysql redis实例代码 #coding: utf-8 __author__ = 'zdz8207' #python2.7 import ...
- python3.4学习笔记(二十二) python 在字符串里面插入指定分割符,将list中的字符转为数字
python3.4学习笔记(二十二) python 在字符串里面插入指定分割符,将list中的字符转为数字在字符串里面插入指定分割符的方法,先把字符串变成list然后用join方法变成字符串str=' ...
- python3.4学习笔记(二十) python strip()函数 去空格\n\r\t函数的用法
python3.4学习笔记(二十) python strip()函数 去空格\n\r\t函数的用法 在Python中字符串处理函数里有三个去空格(包括'\n', '\r', '\t', ' ')的函数 ...
- jmeter后置处理器 JSON Extractor取多个变量值
1.需要获取响应数据的请求右键添加-后置处理器-JSON Extractor 2.如果要获取json响应数据多个值时,设置的Variable names (后续引用变量值的变量名设置)与JSON Pa ...
- Jmeter学习笔记(十九)——后置处理器之正则表达式的使用
一.正则表达式提取器的作用 允许用户从服务器的响应中通过使用perl的正则表达式提取值.作为一个后置处理器,该元素会作用在指定范围的取样器,应用正则表达式,提取所需要的值,生成模板字符串,并将结果存储 ...
- 细雨学习笔记:Jmeter之post processors(后置处理器)
后置处理器
- JMeter学习笔记(十八)——返回的响应数据出现中文乱码_解决方案
一.问题描述 使用jmeter过程中遇到了请求返回的响应数据出现中文乱码 二.原因分析 当没有对响应数据or响应页面设置支持解析中文的编码时,JMeter则会以默认的ISO-8859-1格式解析,而其 ...
随机推荐
- 我的node-webkit笔记
话不多说,直接上码: index.html <!DOCTYPE html> <html> <head> <meta charset="utf-8&q ...
- C#实体类对应SQL数据库的自增长ID怎么设置?
/// <summary> /// 自增长ID /// </summary> [DatabaseGenerated(DatabaseGeneratedOption.Identi ...
- SpringMVC异步处理 可使用的返回值类型
CallableMethodReturnValueHandler Callable.class.isAssignableFrom(returnType.getParameterType()); Def ...
- scrapy入门案例
一. 新建项目(scrapy startproject) 在开始爬取之前,必须创建一个新的Scrapy项目.进入自定义的项目目录中,运行下列命令: scrapy startproject scrapy ...
- python 一般处理
#!/usr/bin/env python# -*- coding:utf-8 -*-# Author:afei# QQ:97259460# date = 2019/8/29 s_code1=''s_ ...
- mysql的几个操作
1.忘记密码,从控制台免密码登录: 修改/etc/my.cnf,[mysqld]下加一行:skip-grant-tables 重启mysql: /etc/init.d/mysqld restart 命 ...
- 数学黑洞:卡普雷卡尔常数的php算法实现
首先看一篇文章: 英国广播公司报道,6174乍看没什么奇特之处,但是,自从1949年以来,它一直令数学家.数字控抓狂.痴迷. 不管你挑的四位数是什么,早早晚晚你都会遇到6174:而且,遇到6174就只 ...
- sourceTree安装和使用(windows)
SourceTree的简介 SourceTree 是 Windows 和Mac OS X 下免费的 Git 和 Hg 客户端,拥有可视化界面,容易上手操作.同时它也是Mercurial和Subve ...
- Node.js实现PC端类微信聊天软件(一)
Github StackChat 技术栈 写这个软件StackChat的主要目的是巩固练习Node和对React的实践,也是为了学习东西,所以选用了这些自己还没在项目里使用过的技术,边学变写 Elec ...
- Google Adsense(谷歌网站联盟)广告申请指南
Google AdSense 是一种获取收入的快速简便的方法,适合于各种规模的网站发布商.它可以在网站的内容网页上展示相关性较高的 Google 广告,并且这些广告不会过分夸张醒目.由于所展示的广告同 ...