处理海量数据的grep、cut、awk、sed 命令
grep、cut、awk、sed 常常应用在查找日志、数据、输出结果等等,并对我们想要的数据进行提取。
通常grep,sed命令是对行进行提取,cut跟awk是对列进行提取
处理海量数据之grep命令
grep应用场景:
通常对数据进行 行的提取
语法:
grep [选项]...[内容]...[file]
-v #对内容进行取反提取
-n #对提取的内容显示行号(原文件中对应行号)
-w #精确匹配
-i #忽略大小写
^ #匹配开头行首
-E #正则匹配
系统文件进行实例演示:
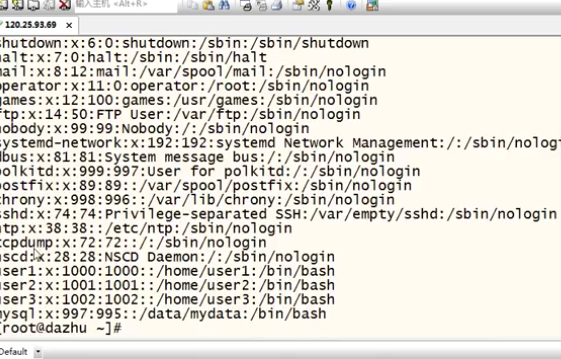
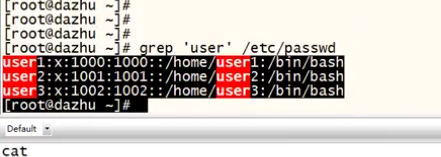
1. 提取是区分大小写的提取
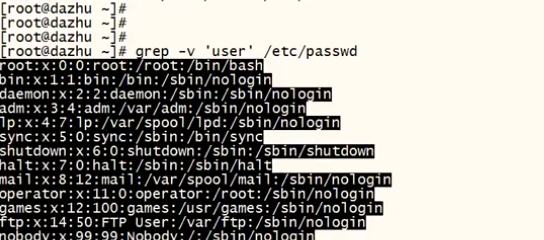
2. -v 提取上述以外的内容
-w 全字符匹配
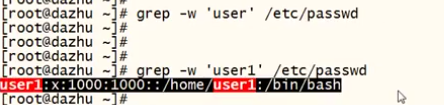
-i

^ 开头
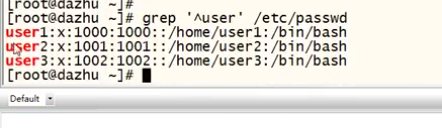
-E 正则

处理海量数据之cut命令
cut应用场景:
通常对数据进行列的提取
语法:
cut [选项]...[file]
-d #指定分割符
-f #指定截取区域
-c #以字符为单位进行分割
注意:不加-d选项,默认为制表符,不是空格
仍然以系统文件为实例
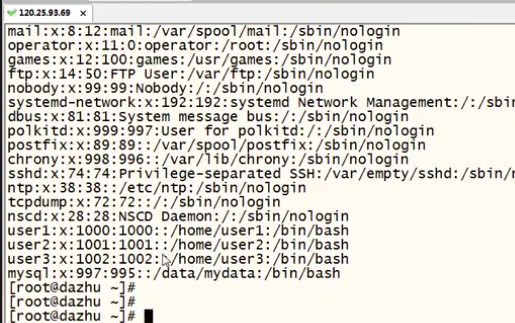
-d与-f:
eg:
以':'为分隔符,截取出/etc/passwd的第一列跟第三列
cut -d ':' -f 1,3 /etc/passwd
eg:
以':'为分隔符,截取出/etc/passwd的第一列到第三列
cut -d ':' -f 1-3 /etc/passwd
eg:
以':'为分隔符,截取出/etc/passwd的第二列到最后一列
cut -d ':' -f 2- /etc/passwd
-c:
eg:
截取/etc/passwd文件从第二个字符到第九个字符
cut -c 2-9 /etc/passwd
eg:
截取linux上面所有可登陆普通用户
/bin/bash #代表可以登录的用户
/sbin/nologin #代表不可以登录的用户
grep '/bin/bash' /etc/passwd | cut -d ':' -f 1 | grep -v root
cut -d ':' -f 1--------第一列代表所有用户

-v #对内容进行取反提取

处理海量数据之awk命令
awk的简介:
其实一门编程语言,支持条件判断,数组,循环等功能,与grep,sed被称为 linux三剑客
awk的应用场景:
通常对数据进行 列的提取 先执行条件再执行动作
语法:
awk '条件 {执行动作}'文件名
awk '条件1 {执行动作} 条件2 {执行动作} ...' 文件名
或awk [选项] '条件1 {执行动作} 条件2 {执行动作} ...' 文件名
特殊要点与举例说明:
printf #格式化输出,不会自动换行。
( %ns:字符串型,n代表有多少个字符;
%ni:整型,n代表输出几个数字;
%.nf:浮点型,n代表的是小数点后有多少个小数)
print #打印出内容,默认会自动换行
\t #制表符(tab键 )
\n #换行符
eg:

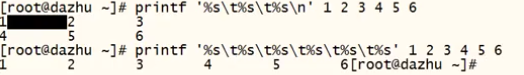

注意:%s 是字符串 %i 是整形
df -h 磁盘空间分区使用率
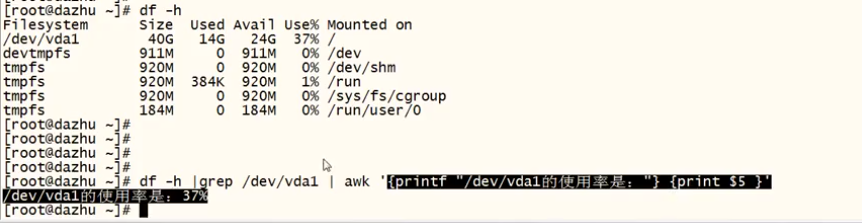
df -h |grep /dev/vda1 | awk '{printf "/dev/vda1的使用率是:"} {print $5 }'
与之前传参不同: $1 #代表第一列 $2 #代表第二列 $0 #代表一整行
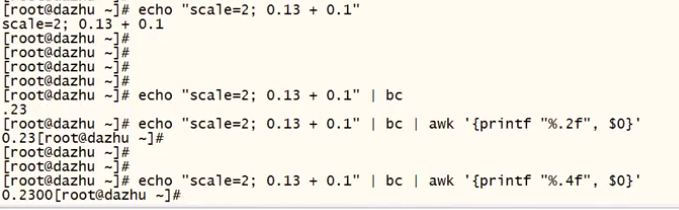
%.nf:浮点型,n代表的是小数点后有多少个小数 \n换行
小数:echo "scale=2; 0.13 + 0.1" | bc | awk '{printf "%.2f\n", $0}'
-F #指定分割符
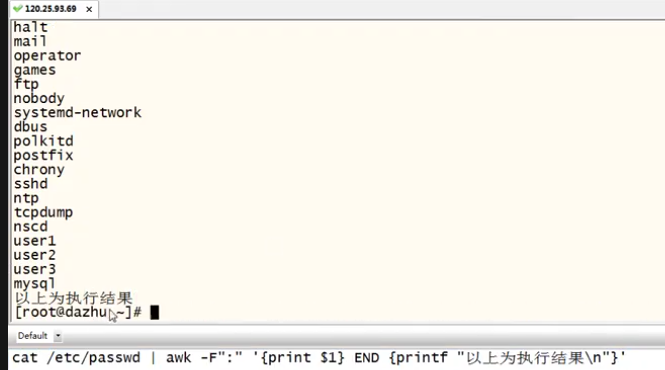
eg:cat /etc/passwd | awk -F":" '{print $1}'
以:为分隔符打印出第一列
另一种方式

BEGIN #在读取所有行内容前就开始执行,常常被用于修改内置变量的值
FS #BEGIN时定义分割符
eg:cat /etc/passwd | awk 'BEGIN {FS=":"} {print $1}'

END #结束的时候 执行 (在最后的时刻才会执行)
NR #行号
eg:df -h | awk 'NR==2 {print $5}'
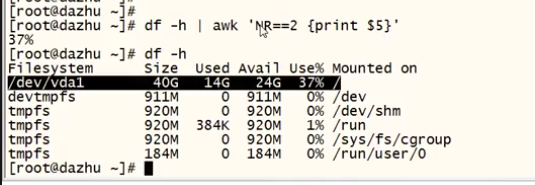
打印多行:

打印行数

处理海量数据之sed命令
sed的应用场景:(只更改输出 不会对源文件进行操作)
主要对数据进行处理(选取,新增,替换,删除,搜索)
sed语法:
sed [选项] [动作] 文件名
常见的选项与参数:
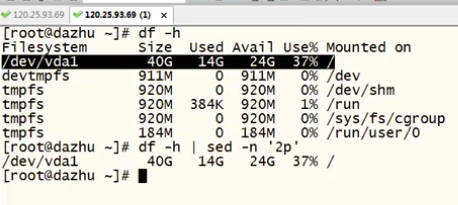
-n #把匹配到的行输出打印到屏幕
p #以行为单位进行查询,通常与-n一起使用
eg:
df -h | sed -n '2p'
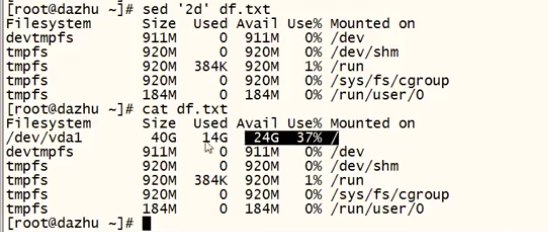
d #删除 (只是打印的内容看不见 并不是对原文件删除)
eg:
sed '2d' df.txt
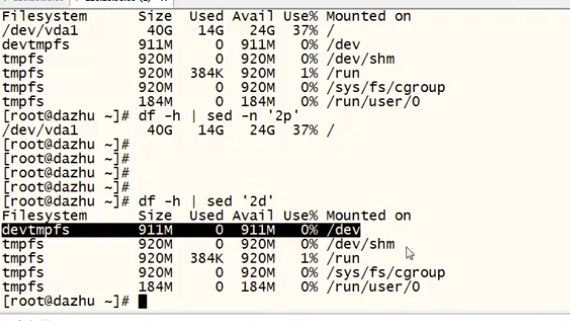
源文件保留
a #在行的下面插入新的内容
eg: sed '2a 1234567890' df.txt
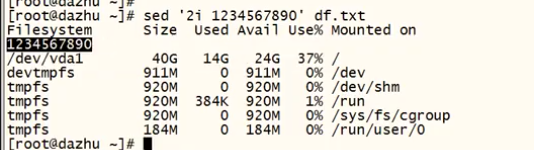
i #在行的上面插入新的内容
eg: sed '2i 1234567890' df.txt
c #替换
eg: sed '2c 1234567890' df.txt
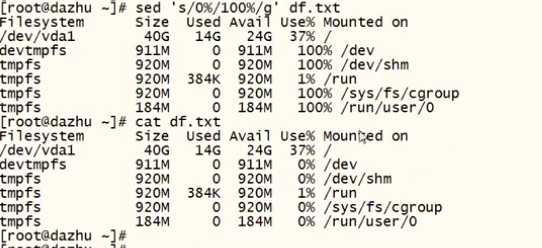
s/要被取代的内容/新的字符串/g #指定内容进行替换
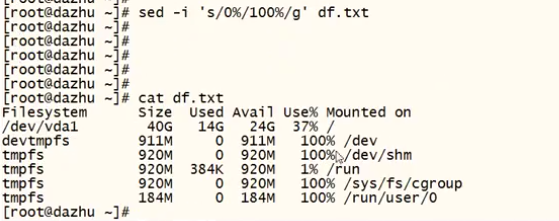
-i #对源文件进行修改(高危操作,慎用,用之前需要备份源文件)
修改 不打印
搜索:(同grep)
在文件中搜索内容 '/100%/p'
eg:
cat -n df.txt | sed -n '/100%/p'

-e #表示可以执行多条动作 (注意)
eg:
cat -n df.txt | sed -n -e 's/100%/100%-----100%/g' -e '/100%-----100%/p'

处理海量数据的grep、cut、awk、sed 命令的更多相关文章
- 无法绕开的cut, awk, sed命令
linux命令的选项和选项后面的值的方式: 如果用 短选项, 选项值就放在短选项的后面, 如果用长选项, 值就用等于的方式. 最重要的是, 短选项后面的值, 跟短选项之间, 可以用空格, 也可以紧接着 ...
- awk sed 命令
awk awk是一个强大的文本分析工具,相对于grep的查找,sed的编辑,awk在其对数据分析并生成报告时,显得尤为强大. 简单来说awk就是把文件逐行的读入,以 空格或TAB 为默认分隔符 将每行 ...
- Linux进阶命令-sort、uniq、 cut、sed、grep、find、awk
命令难度总体来说有简入难,参数都是工作中常常用到的.如果涉及到一些生僻的参数还请百度或man一下. sort(参考学习网站:http://www.cnblogs.com/dong008259/arch ...
- Linux高级命令-sort、uniq、 cut、sed、grep、find、awk
sort(参考学习网站:http://www.cnblogs.com/dong008259/archive/2011/12/08/2281214.html) 功能:根据不同的数据类型进行排序 格式:s ...
- 获取文本中你须要的字段的 几个命令 grep awk cut tr sed
1,grep 2,awk 3,cut 4,tr 5,sed 实例1 获取本地IP地址 /sbin/ifconfig -a|grep inet|grep -v 127.0.0.1|grep -v ine ...
- Linux查找命令:grep,awk,sed
grep grep (global search regular expression(RE) and print out the line,全面搜索正则表达式并把行打印出来)是一种强大的文本搜索工具 ...
- [Shell]字符截取命令:cut, printf, awk, sed
------------------------------------------------------------------------------------------- [cut命令] ...
- Linux中的高级文本处理命令,cut命令,sed命令,awk命令
1.2.1 cut命令 cut命令可以从一个文本文件或者文本流中提取文本列. cut语法 [root@www ~]# cut -d'分隔字符' -f fields ## 用于有特定分隔字符 [r ...
- Linux进阶之正则,shell三剑客(grep,awk,sed),cut,sort,uniq
一.正则表达式:Regular Expression 正则表达式:正则表达式使用单个字符串来描述.匹配一系列符合某个句法规则的字符串.在很多文本编辑器里,正则表达式通常被用来检索.替换那些符合某个模式 ...
随机推荐
- postman(十二):发送携带md5签名、随机数等参数的请求
想起来之前在借助百度翻译接口做翻译小工具的时候,需要把参数进行md5加密后再传输. 而在平时的接口测试工作中难免会遇到类似这种请求参数,比如md5加密.时间戳.随机数等等.固然可以先计算出准确的参数, ...
- [LOJ 2721][UOJ 396][BZOJ 5418][NOI 2018]屠龙勇士
[LOJ 2721][UOJ 396][BZOJ 5418][NOI 2018]屠龙勇士 题意 题面好啰嗦啊直接粘LOJ题面好了 小 D 最近在网上发现了一款小游戏.游戏的规则如下: 游戏的目标是按照 ...
- Ubuntu无法正常输入英文单引号符号 + 误删除package导致系统设置异常(解决方案)
1 先说解决单引号的问题 写代码,遇到了输入英文单引号无法正常输入,需要按两次,而且不是竖向,而是斜的. 然后在寻找解决方案的过程中又遇到了把中文输入法搞得不能使用的问题.破费周折!!! 对Ubunt ...
- [NewLife.XCode]实体工厂(拦截处理实体操作)
NewLife.XCode是一个有10多年历史的开源数据中间件,支持nfx/netcore,由新生命团队(2002~2019)开发完成并维护至今,以下简称XCode. 整个系列教程会大量结合示例代码和 ...
- 十一、Spring之事件监听
Spring之事件监听 ApplicationListener ApplicationListener是Spring事件机制的一部分,与抽象类ApplicationEvent类配合来完成Applica ...
- Neo4j 第十二篇:使用Python驱动访问Neo4j
neo4j官方驱动支持Python语言,驱动程序主要包含Driver类型和Session类型.Driver对象包含Neo4j数据库的详细信息,包括主机url.安全验证等配置,还管理着连接池(Conne ...
- kali渗透综合靶机(十五)--Breach-1.0靶机
kali渗透综合靶机(十五)--Breach-1.0靶机 靶机下载地址:https://download.vulnhub.com/breach/Breach-1.0.zip 一.主机发现 1.netd ...
- 2019-11-29-WPF-模拟触摸设备
原文:2019-11-29-WPF-模拟触摸设备 title author date CreateTime categories WPF 模拟触摸设备 lindexi 2019-11-29 08:47 ...
- ASP.NET MVC 中的过滤器
这里用实例说明各种过滤器的用法,有不对的地方还请大神指出,共同探讨. 1. ActionFilter 方法过滤器: 接口名为 IActionFilter ,在控制器方法调用前/后执行. 在新建的MVC ...
- Asp.netCore 3.0 Web 实现Oauth2.0微信授权登陆的测试
1:Oauth2.0授权的流程截图 官方流程如下: 1 第一步:用户同意授权,获取code 2 第二步:通过code换取网页授权access_token 3 第三步:刷新access_token(如果 ...