《算法 - Lru算法》
一:概述
- LRU 用于管理缓存策略,其本身在 Linux/Redis/Mysql 中均有实现。只是实现方式不尽相同。
- LRU 算法【Least recently used(最近最少使用)】
- 根据数据的历史访问记录来进行淘汰数据,其核心思想是 "如果数据最近被访问过,那么将来被访问的几率也更高"。
二:单链表实现的 Lru 算法
- 思路
- 单链表实现
- 流程
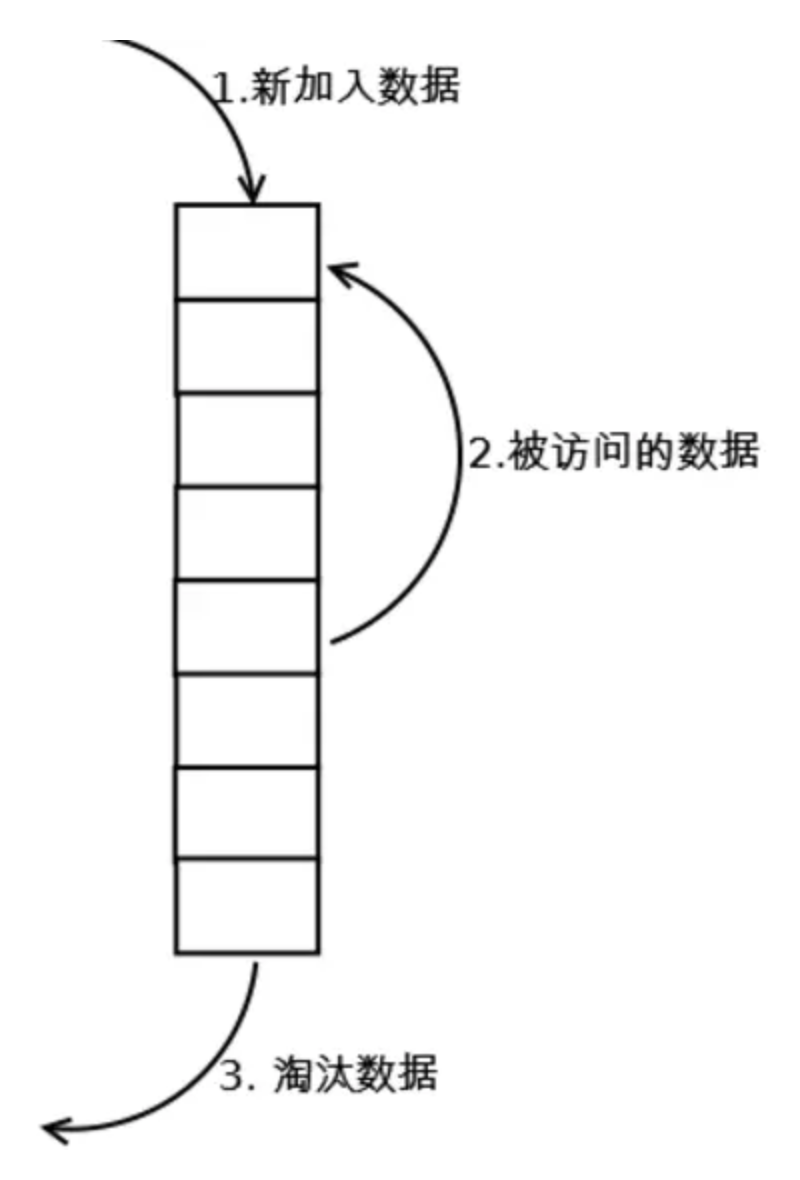
- 1. 新数据插入到链表头部;
- 2. 每当缓存命中(即缓存数据被访问),则将数据移到链表头部;
- 3. 当链表满的时候,将链表尾部的数据丢弃。
- 优点
- 实现简单。
- 当存在热点数据时,LRU的效率很好。
- 缺点
- 偶发性的、周期性的批量操作会导致LRU命中率急剧下降,缓存污染情况比较严重。
- 命中时需要遍历链表,找到命中的数据块索引,然后需要将数据移到头部。
- 流程图
- 
- 代码实现(PHP)
/**
* 思路
* 单链表实现
* 原理
* 单链表
* 流程
* 1. 新数据插入到链表头部;
* 2. 每当缓存命中(即缓存数据被访问),则将数据移到链表头部;
* 3. 当链表满的时候,将链表尾部的数据丢弃。
* 优点
* 实现简单。
* 当存在热点数据时,LRU的效率很好。
* 缺点
* 偶发性的、周期性的批量操作会导致LRU命中率急剧下降,缓存污染情况比较严重。
* 命中时需要遍历链表,找到命中的数据块索引,然后需要将数据移到头部。
*/
class Lru
{
public static $lruList = []; // 顺序存储单链表结构
public static $maxLen = ; // 链表允许最大长度
public static $nowLen = ; // 链表当前长度 /**
* LRU_1 constructor.
* 由于 PHP 不是常驻进程程序,所以链表初始化可以通过 Mysql/Redis 实现
*/
public function __construct()
{
self::$lruList = [];
self::$nowLen = count(self::$lruList);
} /**
* 获取 key => value
* @param $key
* @return null
*/
public function get($key)
{
$value = null; // lru 队列为空,直接返回
if (!self::$lruList) {
self::$lruList[] = [$key => $this->getData($key)]; // 根据实际项目情况获取数据
self::$nowLen++;
return $value;
} // 查找 lru 缓存
for ($i = ; $i < self::$nowLen; $i++) { // 如果存在缓存,则直接返回,并将数据重新插入链表头部
if (isset(self::$lruList[$i][$key])) { $value = self::$lruList[$i][$key]; unset(self::$lruList[$i]); array_unshift(self::$lruList, [$key => $value]); break;
}
} // 如果没有找到 lru 缓存
if (!isset($value)) { // 插入头部
array_unshift(self::$lruList, [$key => $this->getData($key)]); // 根据实际项目情况获取数据
self::$nowLen++; if (self::$nowLen > self::$maxLen) {
self::$nowLen--;
array_pop(self::$lruList);
}
} return $value; } /**
* 输出 Lru 队列
*/
public function echoLruList()
{
var_dump(self::$lruList);
} /**
* 根据真实环境获取数据
* @param $key
* @return string
*/
public function getData($key)
{
return 'data';
}
}
三:Lru K 算法
- 思路
- 为了避免 LRU 的 '缓存污染' 问题
- 增加一个队列来维护缓存出现的次数。其核心思想是将“最近使用过1次”的判断标准扩展为“最近使用过K次”。
- 原理
- 相比LRU,LRU-K需要多维护一个队列,用于记录所有缓存数据被访问的历史。
- 只有当数据的访问次数达到K次的时候,才将数据放入缓存。
- 当需要淘汰数据时,LRU-K会淘汰第K次访问时间距当前时间最大的数据.
- 流程
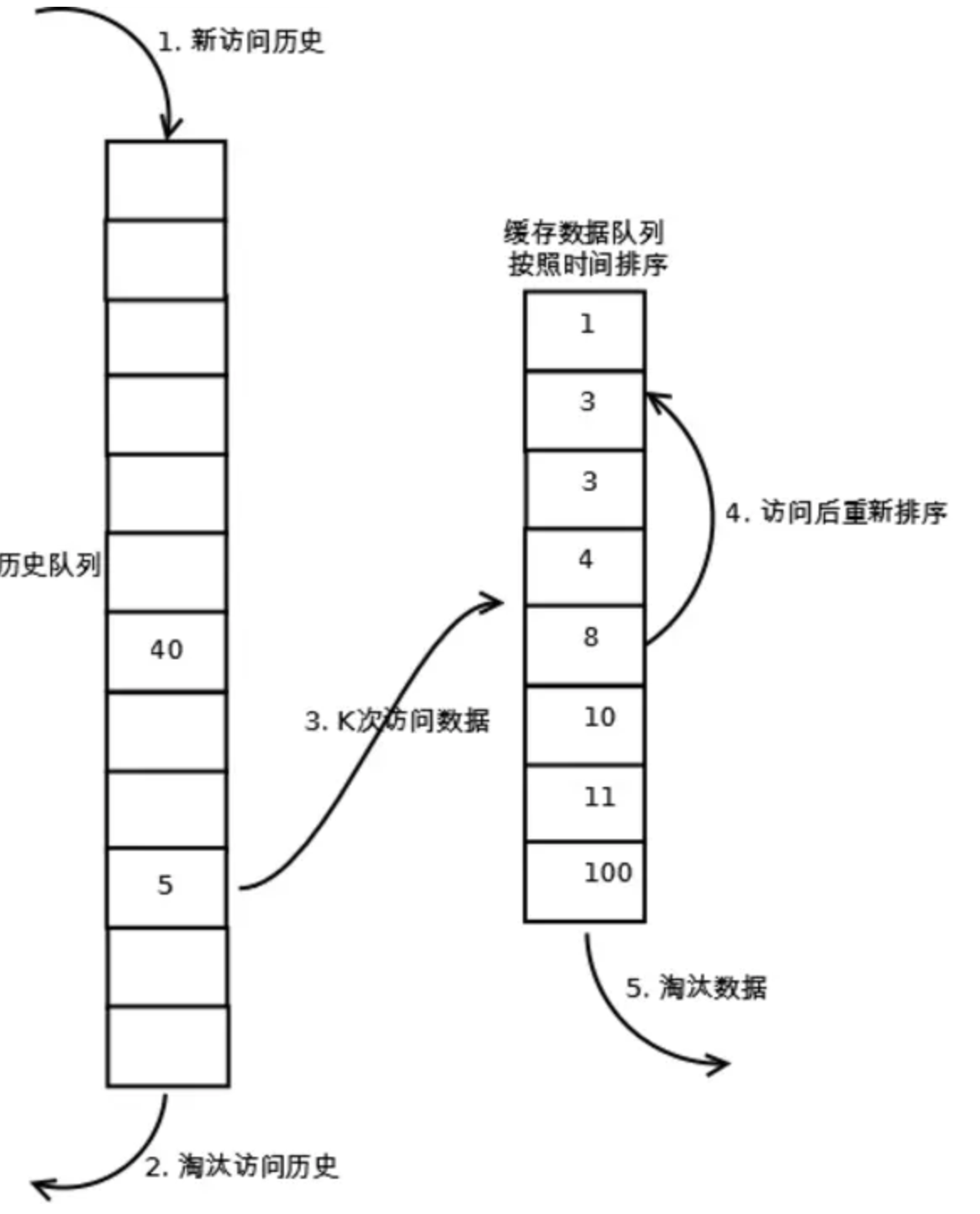
- 1.数据第一次被访问,加入到访问历史列表;
- 2.如果数据在访问历史列表里后没有达到K次访问,则按照一定规则 LRU淘汰;
- 3.当访问历史队列中的数据访问次数达到K次后,将数据索引从历史队列删除,将数据移到缓存队列中,并缓存此数据,缓存队列重新按照时间排序;
- 4.缓存数据队列中被再次访问后,重新排序;
- 5.需要淘汰数据时,淘汰缓存队列中排在末尾的数据,即:淘汰“倒数第K次访问离现在最久”的数据。
- 优点
- LRU-K降低了“缓存污染”带来的问题,命中率比LRU要高。
- 缺点
- LRU-K队列是一个优先级队列,算法复杂度和代价比较高。
- 由于LRU-K还需要维护历史队列,所以消耗的内存会更多。
- 流程图
- 
- 代码实现
/**
* 思路
* 为了避免 LRU 的 '缓存污染' 问题
* 增加一个队列来维护缓存出现的次数。其核心思想是将“最近使用过1次”的判断标准扩展为“最近使用过K次”。
* 原理
* 相比LRU,LRU-K需要多维护一个队列,用于记录所有缓存数据被访问的历史。
* 只有当数据的访问次数达到K次的时候,才将数据放入缓存。
* 当需要淘汰数据时,LRU-K会淘汰第K次访问时间距当前时间最大的数据
* 流程
* 1.数据第一次被访问,加入到访问历史列表;
* 2.如果数据在访问历史列表里后没有达到K次访问,则按照一定规则 LRU淘汰;
* 3.当访问历史队列中的数据访问次数达到K次后,将数据索引从历史队列删除,将数据移到缓存队列中,并缓存此数据,缓存队列重新按照时间排序;
* 4.缓存数据队列中被再次访问后,重新排序;
* 5.需要淘汰数据时,淘汰缓存队列中排在末尾的数据,即:淘汰“倒数第K次访问离现在最久”的数据。
* 优点
* LRU-K降低了“缓存污染”带来的问题,命中率比LRU要高。
* 缺点
* LRU-K队列是一个优先级队列,算法复杂度和代价比较高。
* 由于LRU-K还需要维护历史队列,所以消耗的内存会更多。
*/
class Lru_K
{
public static $historyList = []; // 访问历史队列
public static $lruList = []; // 顺序存储单链表结构
public static $maxLen = ; // 链表允许最大长度
public static $nowLen = ; // 链表当前长度 /**
* LRU_K constructor.
* 由于 PHP 不是常驻进程程序,所以链表初始化可以通过 Mysql/Redis 实现
*/
public function __construct()
{
self::$lruList = [];
self::$historyList = [];
self::$nowLen = count(self::$lruList);
} /**
* 获取 key => value
* @param $key
* @return null
*/
public function get($key)
{
$value = null; // 查找 lru 缓存
for ($i = ; $i < self::$nowLen; $i++) { // 如果存在缓存,则直接返回,并将数据重新插入链表头部
if (isset(self::$lruList[$i][$key])) { $value = self::$lruList[$i][$key]; unset(self::$lruList[$i]); array_unshift(self::$lruList, [$key => $value]); break;
}
} // 如果没有找到 lru 缓存, 则进入历史队列进行计数,当次数大于等于5时候,进入缓存队列
if (!isset($value)) {
self::$historyList[$key]++; $value = $this->getData($key); // 进入缓存队列
if (self::$historyList[$key] >= ) {
array_unshift(self::$lruList, [$key => $value]); // 根据实际项目情况获取数据
self::$nowLen++; if (self::$nowLen > self::$maxLen) {
self::$nowLen--;
array_pop(self::$lruList);
} unset(self::$historyList[$key]); // 历史队列推出
}
} return $value; } /**
* 输出 Lru 队列
*/
public function echoLruList()
{
var_dump(self::$lruList);
var_dump(self::$historyList);
} /**
* 根据真实环境获取数据
* @param $key
* @return string
*/
public function getData($key)
{
return 'data';
}
}
《算法 - Lru算法》的更多相关文章
- 简单物联网:外网访问内网路由器下树莓派Flask服务器
最近做一个小东西,大概过程就是想在教室,宿舍控制实验室的一些设备. 已经在树莓上搭了一个轻量的flask服务器,在实验室的路由器下,任何设备都是可以访问的:但是有一些限制条件,比如我想在宿舍控制我种花 ...
- 利用ssh反向代理以及autossh实现从外网连接内网服务器
前言 最近遇到这样一个问题,我在实验室架设了一台服务器,给师弟或者小伙伴练习Linux用,然后平时在实验室这边直接连接是没有问题的,都是内网嘛.但是回到宿舍问题出来了,使用校园网的童鞋还是能连接上,使 ...
- 外网访问内网Docker容器
外网访问内网Docker容器 本地安装了Docker容器,只能在局域网内访问,怎样从外网也能访问本地Docker容器? 本文将介绍具体的实现步骤. 1. 准备工作 1.1 安装并启动Docker容器 ...
- 外网访问内网SpringBoot
外网访问内网SpringBoot 本地安装了SpringBoot,只能在局域网内访问,怎样从外网也能访问本地SpringBoot? 本文将介绍具体的实现步骤. 1. 准备工作 1.1 安装Java 1 ...
- 外网访问内网Elasticsearch WEB
外网访问内网Elasticsearch WEB 本地安装了Elasticsearch,只能在局域网内访问其WEB,怎样从外网也能访问本地Elasticsearch? 本文将介绍具体的实现步骤. 1. ...
- 怎样从外网访问内网Rails
外网访问内网Rails 本地安装了Rails,只能在局域网内访问,怎样从外网也能访问本地Rails? 本文将介绍具体的实现步骤. 1. 准备工作 1.1 安装并启动Rails 默认安装的Rails端口 ...
- 怎样从外网访问内网Memcached数据库
外网访问内网Memcached数据库 本地安装了Memcached数据库,只能在局域网内访问,怎样从外网也能访问本地Memcached数据库? 本文将介绍具体的实现步骤. 1. 准备工作 1.1 安装 ...
- 怎样从外网访问内网CouchDB数据库
外网访问内网CouchDB数据库 本地安装了CouchDB数据库,只能在局域网内访问,怎样从外网也能访问本地CouchDB数据库? 本文将介绍具体的实现步骤. 1. 准备工作 1.1 安装并启动Cou ...
- 怎样从外网访问内网DB2数据库
外网访问内网DB2数据库 本地安装了DB2数据库,只能在局域网内访问,怎样从外网也能访问本地DB2数据库? 本文将介绍具体的实现步骤. 1. 准备工作 1.1 安装并启动DB2数据库 默认安装的DB2 ...
- 怎样从外网访问内网OpenLDAP数据库
外网访问内网OpenLDAP数据库 本地安装了OpenLDAP数据库,只能在局域网内访问,怎样从外网也能访问本地OpenLDAP数据库? 本文将介绍具体的实现步骤. 1. 准备工作 1.1 安装并启动 ...
随机推荐
- 编程用泰勒公式求e的近似值,直到最后一项小于10的负6次方为止。
#include<stdio.h>#include<math.h>void main(){ int n; float j=1.0,sum=1.0; for(n=1;;n++) ...
- MongoDB 4.2 的主要亮点(转载)
在6月份召开的MongoDB全球用户大会上, MongoDB官宣了MongoDB Server 4.2,在经过100,000多个运行实例的测试后,MongoDB 4.2表现强劲.现在4.2版本正式上线 ...
- Java web开发——文件的上传和下载
一. 功能性需求与非功能性需求 要求操作便利,一次选择多个文件和文件夹进行上传:支持PC端全平台操作系统,Windows,Linux,Mac 支持文件和文件夹的批量下载,断点续传.刷新页面后继续传输. ...
- 在nodejs中操作数据库(MongoDB和MySQL为例)
一.使用nodejs操作MongoDB数据库 ①使用官方的mongodb包来操作 ②使用第三方的mongoose包来操作(比较常用) // 首先必须使MongoDB数据库保持开启状态 // npm下载 ...
- Android Studio一直显示Building“project name”Gradle project info问题详解
关注我,每天都有优质技术文章推送,工作,学习累了的时候放松一下自己. 本篇文章同步微信公众号 欢迎大家关注我的微信公众号:「醉翁猫咪」 Android Studio一直显示 Building&quo ...
- uni-app input text-indent失效解决
有两种方法去解决 第一种 input { padding-left: 10upt } 第二种 input { display: block }
- JVM内存的划分
JVM内存的划分有五片: 1. 寄存器: 2. 本地方法区: 3. 方法区: 4. 栈内存: 5. 堆内存.
- SpringDataRedis的简单案例使用
一.SpringDataRedis环境搭建 第一步.导入坐标 <!-- 缓存 --> <dependency> <groupId>redis.clients< ...
- 除法运算时的一个常见异常之java.lang.ArithmeticException: Non-terminating decimal expansion; no exact representable decimal result.
一.背景 今天在计算库存消耗百分比(消耗的库存/总库存)的时候遇到了一个错误,java.lang.ArithmeticException: Non-terminating decimal expans ...
- 剑指offer:数组中只出现一次的数字
题目描述: 一个整型数组里除了两个数字之外,其他的数字都出现了两次.请写程序找出这两个只出现一次的数字. 思路分析: 1. 直接想法,每个数字遍历,统计出现次数,复杂度O(n^2),超时. 2. 借助 ...