MapReduce(五) mapreduce的shuffle机制 与 Yarn
一、shuffle机制
1、概述
(1)MapReduce 中, map 阶段处理的数据如何传递给 reduce 阶段,是 MapReduce 框架中最关键的一个流程,这个流程就叫 Shuffle;
(2)Shuffle: 数据混洗 ——(核心机制:数据分区,排序,缓存);
(3) 具体来说:就是将 maptask 输出的处理结果数据,分发给 reducetask,并在分发的过程 中,对数据按 key 进行了分区和排序;
2、主要流程

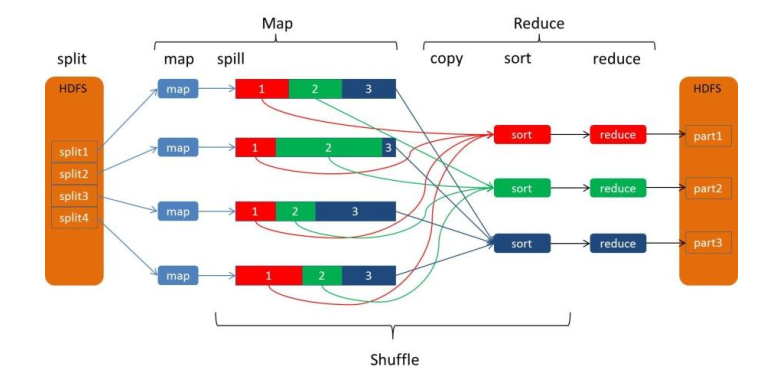
3、详细流程
(1)maptask 收集我们的 map()方法输出的 kv 对,放到内存缓冲区中
(2)从内存缓冲区不断溢出本地磁盘文件,可能会溢出多个文件 (至少一个)
(3)多个溢出文件会被合并成大的溢出文件 (慢慢排序,不是都结束之后才排序)
(4)在溢出过程中,及合并的过程中,都要调用 partitoner 进行分组和针对 key 进行排序
(5)reducetask 根据自己的分区号,去各个 maptask 机器上取相应的结果分区数据
(6)reducetask 会取到同一个分区的来自不同 maptask 的结果文件, reducetask 会将这些文件 再进行合并(归并排序)
(7)合并成大文件后, shuffle 的过程也就结束了,后面进入 reducetask 的逻辑运算过程(从 文件中取出一个一个的键值对 group,调用用户自定义的 reduce()方法)
Shuffle 中的缓冲区大小会影响到 mapreduce 程序的执行效率,原则上说,缓冲区越大,磁 盘 io 的次数越少,执行速度就越快
缓冲区的大小可以通过参数调整, 参数: io.sort.mb 默认 100M (溢出条件0.8(80%))
4、流程图
二、Yarn
1、yarn 概述
YARN( Yet Another Resource Negotiator)
Yarn 是一个资源调度平台,负责为运算程序提供服务器运算资源,相当于一个分布式的操作 系统平台,而 MapReduce 等运算程序则相当于运行于操作系统之上的应用程序
(1)yarn 并不清楚用户提交的程序的运行机制
(2)yarn 只提供运算资源的调度(用户程序向 yarn 申请资源, yarn 就负责分配资源)
(3)yarn 中的主管角色叫 ResourceManager
(4)yarn 中具体提供运算资源的角色叫 NodeManager
(5)这样一来, yarn 其实就与运行的用户程序完全解耦,就意味着 yarn 上可以运行各种类型 的分布式运算程序( mapreduce 只是其中的一种),比如 mapreduce、 storm 程序, spark 程序, tez ……
(6)所以, spark、 storm 等运算框架都可以整合在 yarn 上运行,只要他们各自的框架中有符 合 yarn 规范的资源请求机制即可
(7)yarn 就成为一个通用的资源调度平台,从此,企业中以前存在的各种运算集群都可以整 合在一个物理集群上,提高资源利用率,方便数据共享
2、yarn的重要概念
(1)ResourceManager
ResourceManager 是基于应用程序对集群资源的需求进行调度的 Yarn 集群主控节点,负责协 调和管理整个集群( 所有 NodeManager) 的资源,响应用户提交的不同类型应用程序的解 析,调度,监控等工作。ResourceManager 会为每一个 Application 启动一个 ApplicationMaster,
并且 ApplicationMaster 分散在各个 NodeManager 节点
它主要由两个组件构成:调度器( Scheduler)和应用程序管理器( ApplicationsManager, ASM)
(2)NodoManager
NodeManager 是 YARN 集群当中真正资源的提供者,是真正执行应用程序的容器的提供者, 监控应用程序的资源使用情况( CPU,内存,硬盘,网络), 并通过心跳向集群资源调度器 ResourceManager 进行汇报。
(3)ApplicationMaster (申请容器、监控任务)
ApplicationMaster 对应一个应用程序,职责是: 向资源调度器申请执行任务的资源容器,运 行任务,监控整个任务的执行,跟踪整个任务的状态,处理任务失败以异常情况
(4)Container
Container 是一个抽象出来的逻辑资源单位。 它封装了一个节点上的 CPU,内存,磁盘,网络等信息, MapReduce 程序的所有 task 都是在一个容器里执行完成的,容器的大小是可以 动态调整的
(5)ASM
应用程序管理器 ASM 负责管理整个系统中所有应用程序,包括应用程序提交、与调度器协 商资源以启动 ApplicationMaster、监控 ApplicationMaster 运行状态并在失败时重新启动它等
(6)Scheduler
调度器根据应用程序的资源需求进行资源分配,不参与应用程序具体的执行和监控等工作 资源分配的单位就是 Container,调度器是一个可插拔的组件, 用户可以根据自己的需求实 现自己的调度器。 YARN 本身为我们提供了多种直接可用的调度器,比如 FIFO, Fair Scheduler
和 Capacity Scheduler 等
3、yarn的架构

4、 yarn作业执行流程
YARN 作业执行流程:
(1)用户向 YARN 中提交应用程序,其中包括 ApplicationMaster 程序,启动 ApplicationMaster 的命令,用户程序等。
(2) ResourceManager 为该程序分配第一个 Container,并与对应的 NodeManager 通讯,要求 它在这个 Container 中启动应用程序 ApplicationMaster。
(3)ApplicationMaster 首先向 ResourceManager 注册,这样用户可以直接通过 ResourceManager 查看应用程序的运行状态,然后将为各个任务申请资源,并监控它的运行状态,直到运行结 束,重复 4 到 7 的步骤。
(4) ApplicationMaster 采用轮询的方式通过 RPC 协议向 ResourceManager 申请和领取资源。
(5)一旦 ApplicationMaster 申请到资源后,便与对应的 NodeManager 通讯,要求它启动任务。
(6)NodeManager 为任务设置好运行环境(包括环境变量、 JAR 包、二进制程序等)后,将 任务启动命令写到一个脚本中,并通过运行该脚本启动任务。
(7)各个任务通过某个 RPC 协议向 ApplicationMaster 汇报自己的状态和进度,以让 ApplicationMaster 随时掌握各个任务的运行状态,从而可以在任务败的时候重新启动任务。
(8)应用程序运行完成后, AM 向 RM 注销并关闭自己。
MapReduce(五) mapreduce的shuffle机制 与 Yarn的更多相关文章
- mapreduce (五) MapReduce实现倒排索引 修改版 combiner是把同一个机器上的多个map的结果先聚合一次
(总感觉上一篇的实现有问题)http://www.cnblogs.com/i80386/p/3444726.html combiner是把同一个机器上的多个map的结果先聚合一次现重新实现一个: 思路 ...
- MapReduce框架中的Shuffle机制
Shuffle是map和reduce中间的数据调度过程,包括:缓存.分区.排序等. Shuffle数据调度过程: map task处理hdfs文件,调用map()方法,map task的collect ...
- Hadoop(17)-MapReduce框架原理-MapReduce流程,Shuffle机制,Partition分区
MapReduce工作流程 1.准备待处理文件 2.job提交前生成一个处理规划 3.将切片信息job.split,配置信息job.xml和我们自己写的jar包交给yarn 4.yarn根据切片规划计 ...
- MapReduce框架原理--Shuffle机制
Shuffle机制 Mapreduce确保每个reducer的输入都是按键排序的.系统执行排序的过程(Map方法之后,Reduce方法之前的数据处理过程)称之为Shuffle. partition分区 ...
- MapReduce实例2(自定义compare、partition)& shuffle机制
MapReduce实例2(自定义compare.partition)& shuffle机制 实例:统计流量 有一份流量数据,结构是:时间戳.手机号.....上行流量.下行流量,需求是统计每个用 ...
- mapreduce.shuffle set in yarn.nodemanager.aux-services is invalid
15/07/01 20:14:41 FATAL containermanager.AuxServices: Failed to initialize mapreduce.shuffle java.la ...
- MapReduce详解及shuffle阶段
hadoop1.x和hadoop2.x的区别: Hadoop1.x版本: 内核主要由Hdfs和Mapreduce两个系统组成,其中Mapreduce是一个离线分布式计算框架,由一个JobTracker ...
- MapReduce工作流程及Shuffle原理概述
引言: 虽然MapReduce计算框架简化了分布式程序设计,将所有的并行程序均需要关注的设计细节抽象成公共模块并交由系统实现,用户只需关注自己的应用程序的逻辑实现,提高了开发效率,但是开发如果对Map ...
- hadoop的mapReduce和Spark的shuffle过程的详解与对比及优化
https://blog.csdn.net/u010697988/article/details/70173104 大数据的分布式计算框架目前使用的最多的就是hadoop的mapReduce和Spar ...
随机推荐
- 使用phpMyAdmin管理网站数据库(创建、导入、导出…)
作为一名站长,最重视的就是网站的数据安全了.本节襄阳网站优化就来讲讲如何使用phpMyAdmin管理软件进行mysql数据库的管理,实现基本的数据库管理用户.数据库的创建.数据的导入和导出操作(网站备 ...
- Java+Selenium 3.x 实现Web自动化 - Maven打包TestNG,利用jenkins执行测试
1. Jenkins本地执行测试 or 服务器端执行测试 测试代码计划通过jenkins执行时,通过网上查询各种教程,大多数为本地执行测试,由此可见,本地执行是大多数人的选择. 经过探讨,最终决定采用 ...
- 2019CSUST集训队选拔赛题解(三)
PY学长的放毒题 Description 下面开始PY的香港之行,PY有n个要去的小吃店,这n个小吃店被m条路径联通起来. PY有1个传送石和n−1个传送石碎片. PY可以用传送石标记一个小吃店作为根 ...
- Spring Task中的定时任务无法注入service的解决办法
1.问题 因一个项目(使用的是Spring+SpringMVC+hibernate框架)需要在spring task定时任务中调用数据库操作,在使用 @Autowired注入service时后台报错, ...
- 数据挖掘学习笔记——kaggle 数据预处理
预处理 1. 删除缺失值 a. 删除行即样本(对于样本如果输出变量存在缺失的则直接删除该行,因为无法用该样本训练) b. 删除列,即特征(采用这种删除方式,应保证训练集和验证集都应当删除相同的特征) ...
- [转]C#学习笔记15——C#多线程编程
一.基本概念进程:当一个程序开始运行时,它就是一个进程,进程包括运行中的程序和程序所使用到的内存和系统资源.而一个进程又是由多个线程所组成的.线程:线程是程序中的一个执行流,每个线程都有自己的专有寄存 ...
- JSON.stringify处理对象时的问题
1. JSON.stringify({entry_key: 'test', entry_detail: undefined}) 结果 为 "{"entry_key": & ...
- 关于cnblog.com的用户体验
首先我自己目前是一个学生党,每天在博客园上就上发布一些自己做的东西以及老师布置的作业,还能在上面学习很多别人的一些好的列子,我就希望博客园能够很好地为我们这些学生服务,当我们用它时能够很好地达到我们的 ...
- 软工实践-Alpha 冲刺 (10/10)
队名:起床一起肝活队 组长博客:博客链接 作业博客:班级博客本次作业的链接 组员情况 组员1(队长):白晨曦 过去两天完成了哪些任务 描述: 完成所有界面的链接,整理与测试 展示GitHub当日代码/ ...
- 软工实践 - 第三十次作业 Beta答辩总结
福大软工 · 第十二次作业 - Beta答辩总结 组长本次博客作业链接 项目宣传视频链接 本组成员 1 . 队长:白晨曦 031602101 2 . 队员:蔡子阳 031602102 3 . 队员:陈 ...