Oracle数据库从入门到精通-分组统计查询
视频课程:李兴华 Oracle从入门到精通
视频课程学习者:阳光罗诺
视频来源:51CTO学院
整体内容:
- 统计函数的使用
- 分组统计查询的实现
- 对分组的数据过滤
统计函数
在之前我们就学习过一个COUNT()函数,这个函数的主要作用是统计一张表之中的数据量的个数。和它功能与之类似的常用函数有五个:
- 统计个数COUNT():根据表中的实际数据量返回结果。
- 求和SUM():是针对于数字的统计
- 平均值AVG():是针对数字的统计
- 最小值MIN():各种数据类型都支持。
- 最大值MAX():各种数据类型都支持。
范例:验证各个函数。
代码示例:
SELECT COUNT(*) 人数, AVG(sal)员工平均工资,SUM(sal)每月总支出,MAX(sal) 最高工资, MIN(sal)最低工资 FROM emp;

但是这些函数是允许和其他的函数嵌套的。
范例:统计出公司的平均雇佣年限。
代码示例:
SELECT AVG(MONTHS_BETWEEN(SYSDATE,hiredate)/)
FROM emp;

范例:求出最早和最晚的雇佣日期(找到公司最早雇佣的雇员,以及公司最近雇佣的雇员日期)
代码示例:
SELECT MAX(hiredate) 最晚,MIN(hiredate) 最早 FROM emp;

以上的几个操作函数,在表中没有数据的时候,只有COUNT()函数会返回结果,其他的都是null。
范例:统计Bonus表
代码示例:
SELECT COUNT(*) 人数, AVG(sal)员工平均工资,SUM(sal)每月总支出,MAX(sal) 最高工资, MIN(sal)最低工资 FROM bonus;

在图中我们可以清楚的发现,此时只有COUNT()函数会返回最终的结果,即使没有数据也会返回0,而其他的统计函数结果都是null。
实际上针对于COUNT()函数有三种使用形式:【面试题】
- COUNT(*):可以准确的返回表中的全部记录数。
- COUNT(字段):统计不为null的所有数据量。
- COUNT(DISTINCT 字段):消除重复数据之后的结果。
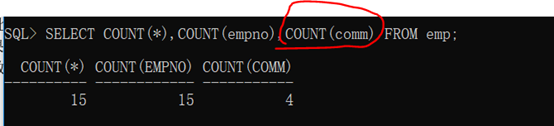
范例:统计查询一
代码示例:
SELECT COUNT(*),COUNT(empno),COUNT(comm) FROM emp;
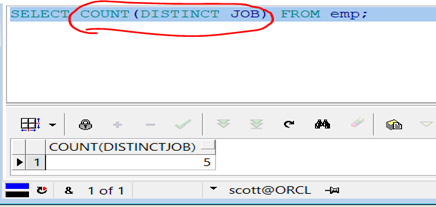
范例:查询二
代码示例:
SELECT COUNT(DISTINCT JOB) FROM emp;
分组统计
分组的前提是存在有重复,1但是允许单独一行记录进行分组。
如果要进行分组应该使用GROUP BY子句来完成,那么此时的语法结构形式如下:
语法结构:
|
【④选出所需要的数据列】SELECT [DISTINCT] * 分组列[别名],分组列[别名],分组列[别名]······ 【①确定数据来源(行和列的集合)】FROM 表名称 [别名],表名称 [别名],······ 【②筛选数据行】[WHERE 限定条件] 此时的条件可以是多个语法结构。 【③针对于筛选的行分组】[GROUP BY 分组字段,分组字段,······] 【⑤数据排序】[ORDER BY 排序字段 [ASC|DESC] 可以设置多个] |
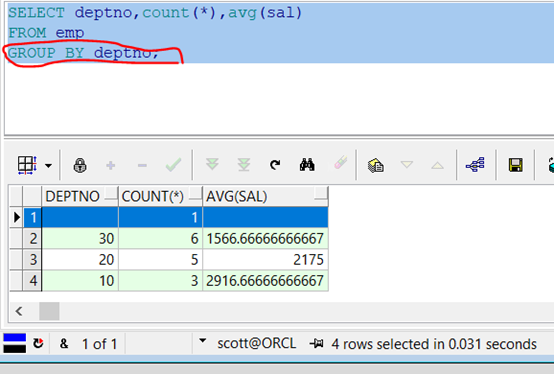
范例:根据部门编号分组,查询出每一个部门的编号、人数、平均工资。
代码示例:
SELECT deptno,count(*),avg(sal) FROM emp GROUP BY deptno;
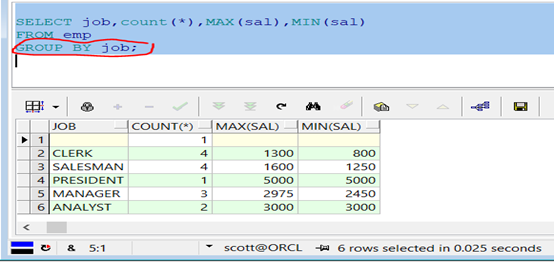
范例:根据职位分组,统计出每一个职位的人数,最低工资与最高工资。
代码示例:
SELECT job,count(*),MAX(sal),MIN(sal) FROM emp GROUP BY job;
查询结果如图:
在GROUP BY 子句中,之所以使用麻烦,是因为分组的时候有一些约定条件。
- 如果查询不适用GROUP BY子句,那么在SELECT子句中只允许出现统计函数,其他任何字段不允许出现。
|
错误代码: |
正确代码: |
|
SELECT empno,COUNT(*) FROM emp; 错误提示: 第 1 行出现错误: ORA-00937: 不是单组分组函数 |
SELECT COUNT(*) FROM emp; |
- 如果查询中使用了额GROUP BY子句,那么SELECT子句中只允许出现分组字段、统计函数,其他任何字段都不允许出现。
|
错误代码: |
正确代码: |
|
SELECT ename,job,COUNT(*) FROM emp GROUP BY job; 错误提示: 第 1 行出现错误: ORA-00979: 不是 GROUP BY 表达式 |
SELECT job,COUNT(*) FROM emp GROUP BY job; |
- 统计函数允许嵌套,但是嵌套之后的SELECT子句里面只允许出现嵌套函数,而不允许任何字段,包括分组字段。
|
错误代码: |
正确代码: |
|
SELECT deptno,MAX(AVG(sal)) FROM emp GROUP BY deptno; 错误提示: 第 1 行出现错误: ORA-00937: 不是单组分组函数 |
SELECT MAX(AVG(sal)) FROM emp GROUP BY deptno; |
多表查询与分析统计(重点)
对于GROUP BY子句而言,是在WHERE子句之后执行的,所以在使用时可以进行限定查询,也可以进行多表查询。
范例:查询出每个部门的名称、部门人数、平均工资。
- 确定要使用的数据表
- dept表:部门名称
- emp表:统计数据
- 确定已知的关联字段。
- 雇员与部门:emp.deptno = dept.deptno;
第一步:查询出每一个部门的名称、雇员编号(COUNT(empno))、基本工资(AVG(sal))。
代码示例:
SELECT d.dname,e.empno,e.sal FROM emp e,dept d WHERE e.deptno=d.deptno;
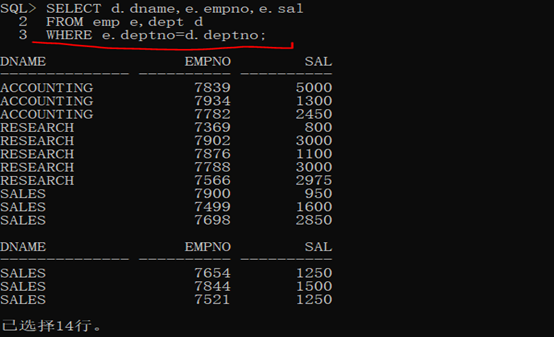
第二步:此时的查询结果中对于部门名称部分出现了重复的内容,按照分组来讲,只要是出现了数据的重复,那么就可以进行分组,只不过此时的分组是针对于临时表(查询结果),既然确定了dname上存在有重复记录,那么就直接针对于dname分组即可。
代码示例:
SELECT d.dname,COUNT(e.empno),AVG(e.sal) FROM emp e,dept d WHERE e.deptno=d.deptno GROUP BY d.dname;
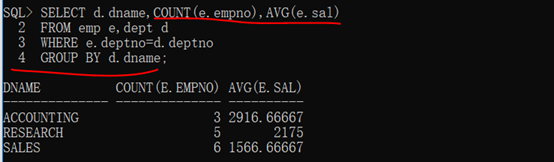
第三步:在dept表中存在有四个部门信息,而此时的要求也是统计所有的部门名称,如果发现数据不完整,立刻使用外连接。
代码示例:
SELECT d.dname,COUNT(e.empno),AVG(e.sal) FROM emp e,dept d WHERE e.deptno=d.deptno(+) GROUP BY d.dname;

范例:查询每个部门的编号、名称、位置、部门人数、平均工资。
第一步:查询每一个部门的编号、名称、位置、雇员编号(COUNT())、工资(AVG(sal)).
代码示例:
SELECT d.deptno,d.dname,d.loc,e.empno,e.sal FROM emp e,dept d WHERE e.deptno(+)=d.deptno;
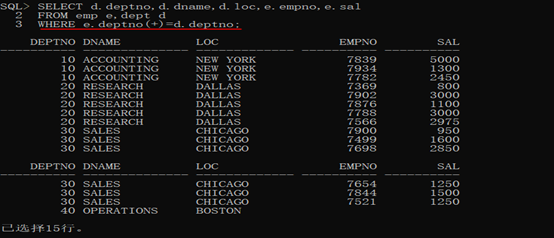
第二步:此时发现三个列(dept列)同时发生着重复,那么就可以进行多字段分组。
代码示例:
SELECT d.deptno,d.dname,d.loc,COUNT(e.empno),AVG(e.sal) FROM emp e,dept d WHERE e.deptno(+)=d.deptno GROUP BY d.deptno,d.dname,d.loc;
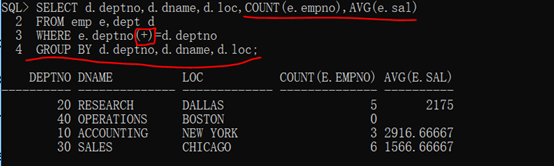
HAVING子句
现在要求查询出每个职位的名称,职位的平均工资,但是要求显示的职位的平均工资高于2000.
即:按照职位先进行分组,同时统计出每个职位的平均工资。随后要求只显示那些平均工资高于2000的职位信息,那么既然现在要针对于显示的数据进行筛选,自然就会首先想到WHERE子句,于是有了如下的代码:
范例:代码示例:
|
错误代码: |
|
SELECT job,AVG(sal) FROM emp WHERE AVG(sal) GROUP BY job; |
|
错误提示: 第 3 行出现错误: ORA-00934: 此处不允许使用分组函数 |
此时直接告诉用户,WHERE子句中不允许出现统计函数(分组函数)。因为GROUP BY子句在WHERE子句之后执行的。那么此时执行WHERE子句时还没有进行分组,那么就自然无法进行统计。此时我们就可以使用HAVING子句来完成。
SQL语法结构:
【⑤选出所需要的数据列】SELECT [DISTINCT] * 分组列[别名],分组列[别名],分组列[别名]······
【①确定数据来源(行和列的集合)】FROM 表名称 [别名],表名称 [别名],······
【②筛选数据行】[WHERE 限定条件] 此时的条件可以是多个语法结构。
【③针对于筛选的行分组】[GROUP BY 分组字段,分组字段,······]
【③针对于筛选的行分组】[HAVING 分组过滤]
【⑥数据排序】[ORDER BY 排序字段 [ASC|DESC] 可以设置多个]
范例:使用HAVING子句
代码示例:
SELECT job,AVG(sal) FROM emp GROUP BY job HAVING AVG(sal)>;

HAVING实在GROUP BY分组之后才进行的筛选,在HAVING里面可以直接使用统计函数。
说明:关于WHERE与HAVING的区别?
- WHERE子句在GROUP BY分组之前进行筛选,指的是选出那些可以参与分组的数据。并且在WHERE子句中不允许使用统计函数
- HAVING子句是在WHERE分组之后执行的,那么就可以使用统计函数。
分组案例:
范例:显示所有销售人员的工作名称以及从事同一个工作的雇员的月工资的总和,并且要求满足从事同一工作的月工资的合计大于5000,显示的结果按照月工资合计的升序排列。
第一步:查询所有非销售人员的信息,WHERE子句即可实现限定查询。
代码示例:
SELECT * FROM emp WHERE job<>'SALESMAN';
查询结果:
第二步:按照职位进行分组,而后求出月工资的总支出。
代码示例:
SELECT job,SUM(sal)
FROM emp
WHERE job<>'SALESMAN'
GROUP BY job;
查询结果:
第三步:分组后的数据进行再次的筛选,使用HAVING子句。
代码示例:
SELECT job,SUM(sal)
FROM emp
WHERE job<>'SALESMAN'
GROUP BY job
HAVING SUM(sal)>;
查询结果:
第四步:按照月工资的合计升序排列。使用ORDER BY子句。
代码示例:
SELECT job,SUM(sal) FROM emp WHERE job<>'SALESMAN' GROUP BY job HAVING SUM(sal)> ORDER BY SUM(sal);
查询结果:

范例:统计所有领取佣金和布领取佣金的人数、平均工资。
代码示例:
SELECT comm,AVG(sal) FROM emp GROUP BY comm;
查询结果:

使用GROUP BY子句会把每一个种子值当作一个分组,所以此时不可能直接使用GROUP BY。
查询出所有领取佣金的雇员的人数、平均工资。————直接使用WHERE子句。不需要使用GROUP BY子句
代码示例:
SELECT '领取佣金' info,COUNT(*),AVG(sal)
FROM emp
WHERE comm IS NOT NULL;
查询结果:

查询出所有不领取佣金的雇员的人数、平均工资。————直接使用WHERE子句。不需要使用GROUP BY子句
代码示例:
SELECT '不领取佣金' info,COUNT(*),AVG(sal)
FROM emp
WHERE comm IS NULL;
查询结果:

既然此时两个查询结果返回的结构完全相同,那么我们就直接连接即可。

Oracle数据库从入门到精通-分组统计查询的更多相关文章
- Oracle数据库从入门到精通 多表查询知识以及范例
视频课程:李兴华 Oracle从入门到精通视频课程 学习者:阳光罗诺 视频来源:51CTO学院 总体内容: 多表查询的意义以及基本问题. 表的连接查询 SQL:1999语法标准对多表查询的支持. 数据 ...
- Oracle数据库从入门到精通 单行函数问题
视频课程:李兴华 Oracle从入门到精通视频课程 学习者:阳光罗诺 视频来源:51CTO学院 Oracle数据库从入门到精通-单行函数 在数据库中,为了方便用户的数据开发,往往会提供一系列的支持函数 ...
- oracle数据库从入门到精通
oracle产品线围绕企业开发平台的企业开发平台四大组件:unix,weblogic中间件,java编程语言,oracle数据库oracle 开发主要分两类数据库管理:dba数据库编程:分两部分 ...
- oracle数据库从入门到精通之四
序列是oracle中较为重要的概念事务对于ddl是不起作用的查询,更新,数据表,约束这些个概念要掌握.在许多数据库之中都会存在一种数据类型--自动增长列,它能够创建流水号12c之前并没有提供这样一个自 ...
- oracle数据库从入门到精通之三
综合案例ddl&dml有一个商品数据库1.数据表的创建 ddl先编写数据库脚本--删除数据表drop table purcase purge;drop table product pur ...
- Oracle数据库基础入门《二》Oracle内存结构
Oracle数据库基础入门<二>Oracle内存结构 Oracle 的内存由系统全局区(System Global Area,简称 SGA)和程序全局区(Program Global Ar ...
- Oracle数据库基础入门《一》Oracle服务器的构成
Oracle数据库基础入门<一>Oracle服务器的构成 Oracle 服务器是一个具有高性能和高可靠性面向对象关系型数据库管理系统,也是一 个高效的 SQL 语句执行环境. Oracle ...
- 《MySQL数据库从入门到精通》 高级运维人才的必备书籍
众所周知,每年就业市场都会迎来千万量级的高校毕业生,然而企业招工难和毕业生就业难的矛盾却一直没有得到很好地解决.究其原因,主要矛盾还是在于传统的学历教育与企业实际需求相脱节.为了杜绝高校毕业生求职时常 ...
- 010.简单查询、分组统计查询、多表连接查询(sql实例)
-------------------------------------day3------------ --添加多行数据:------INSERT [INTO] 表名 [(列的列表)] --SEL ...
随机推荐
- jenkins创建构建任务
构建项目类型 点击 Jenkins 首页 “创建一个新任务” 的链接, 输入任务名称 Jenkins 提供了六种类型的任务. 构建一个自由风格的软件项目 这是Jenkins的主要功能.Jenkins ...
- 部署rails遇到问题
underfined method for has_attched_file when installing paperclip 解决 create the file paperclip.rb ins ...
- 基础js--调试js
1,逻辑错误 常见错误: 是否由于拼写错误而导致申明了新的变量? 是否在条件判定上出现了疏漏? 方法:使用开发者工具调试代码 2,代码错误 常见错误: 是否拼写错误? 是否使用中文的符号? 扩展: 1 ...
- python 多线程与GIL
GIL 与 Python 线程的纠葛 GIL 是什么?它对 python 程序会产生怎样的影响?我们先来看一个问题.运行下面这段 python 代码,CPU 占用率是多少? # 请勿在工作中模仿,危险 ...
- C 标准库 - string.h之memcmp使用
memcmp Compare two blocks of memory. Compares the first num bytes of the block of memory pointed by ...
- CountDownLatch 使用(模拟一场比赛)
java.util.concurrency中的CountDownLatch,主要用于等待一个或多个其他线程完成任务.CountDownLatch在初始化时,会被赋一个整数,每次执行countDown( ...
- R语言统计字符串的字符数ncahr函数
函数计算字符数量,包括在一个字符串的空格的个数. 语法 nchar()函数的基本语法是: nchar(x) 以下是所使用的参数的说明: x - 向量输入. 示例 result <- nchar( ...
- angular2自学笔记(三)---ng2选项卡
学习了这些概念就能简单的描述一个选项功能的选项卡按钮: 数据:1.数组:实例化一个数组的类,如果想要使用这个类中的数据,需要在组件中 使用一个公共属性来暴漏这个类如 heroes=HEROES;con ...
- 【转】Windows 平台下 Go 语言的安装和环境变量设置
1. Go 语言 SDK 安装包下载和安装 最新稳定版 1.5.3 安装包 go1.5.3.windows-amd64.msi下载地址 https://golang.org/dl/,大小约 69 MB ...
- [javaSE] 数据结构(AVL树基本概念)
AVL树是高度平衡的二叉树,任何节点的两个子树的高度差别<=1 实现AVL树 定义一个AVL树,AVLTree,定义AVLTree的节点内部类AVLNode,节点包含以下特性: 1.key——关 ...