python文件夹批处理操作
如图所示,有一个test文件夹,里面有3个子文件夹,每个子文件夹中有若干图片文件



#场景1 读取一个文件夹中所有文件,存入到一个list表中
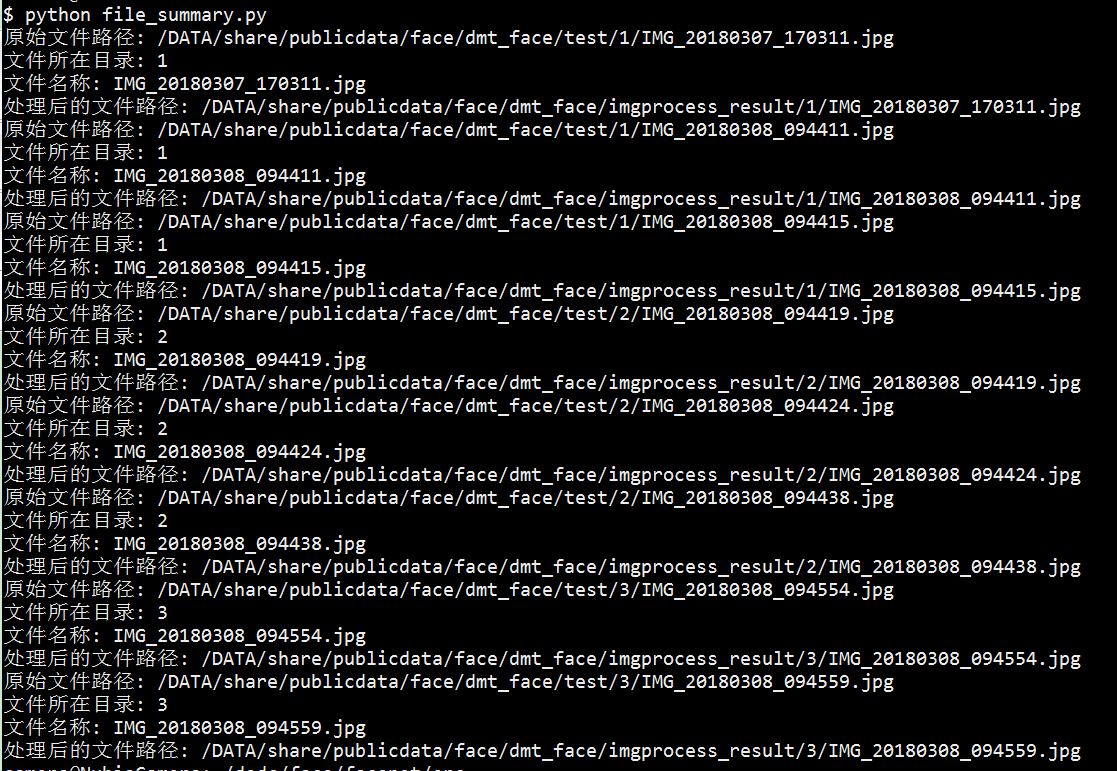
#coding:utf-8
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function import numpy as np
import os
import sys
import math
import numpy
import time
import argparse
import random
import cv2 def findAllfile(path, allfile):
filelist = os.listdir(path)
for filename in filelist:
filepath = os.path.join(path, filename)
if os.path.isdir(filepath):
#print(filepath)
findAllfile(filepath, allfile)
else:
allfile.append(filepath)
return allfile #场景1 读取一个文件夹中所有文件,存入到一个list表中
def process1(srcpath, imgprocess_result): #遍历图像文件夹
image_files = findAllfile(srcpath,[])
#image_files为所有文件的list #判断 目录是否存在,存在就删除,并且重建
if os.path.exists(imgprocess_result):
os.system("rm -rf " + imgprocess_result)
if not os.path.isdir(imgprocess_result): # Create the log directory if it doesn't exist
os.makedirs(imgprocess_result) #是否随机打乱文件顺序
#random.shuffle(image_files) #遍历所有
for facepath in image_files:
print("原始文件路径:", facepath)
#获取文件名称
data_split = facepath.strip().split("/")
image_floder = data_split[-2]
print("文件所在目录:", image_floder)
image_name = data_split[-1]
print("文件名称:", image_name) image_newfloder = imgprocess_result + "/" + image_floder
#判断 目录是否存在,不存在就重建
if not os.path.isdir(image_newfloder): # Create the log directory if it doesn't exist
os.makedirs(image_newfloder) image_newpath = image_newfloder + "/" + image_name
print("处理后的文件路径:", image_newpath) #开始处理文件
#..............
#
# #场景2 首先读取一个文件夹中的所有子目录,然后依次遍历各个子目录的所有文件
def process2(srcpath, imgprocess_result):
#找出所有的子目录
filelist = os.listdir(srcpath)
for filename in filelist:
filepath = os.path.join(srcpath, filename)
if os.path.isdir(filepath):
print("原始子目录路径:", filepath)
image_files = findAllfile(filepath,[])
for facepath in image_files:
print("原始文件路径:", facepath)
#获取文件名称
data_split = facepath.strip().split("/")
image_floder = data_split[-2]
print("文件所在目录:", image_floder)
image_name = data_split[-1]
print("文件名称:", image_name) image_newfloder = imgprocess_result + "/" + image_floder
#判断 目录是否存在,不存在就重建
if not os.path.isdir(image_newfloder): # Create the log directory if it doesn't exist
os.makedirs(image_newfloder) image_newpath = image_newfloder + "/" + image_name
print("处理后的文件路径:", image_newpath) #开始处理文件
#..............
#
# if __name__ == '__main__':
#原始文件夹
srcpath = "/DATA/share/publicdata/face/dmt_face/test"
#处理完毕后存放文件
imgprocess_result = "/DATA/share/publicdata/face/dmt_face/imgprocess_result" print("方法1\n\n\n\n")
process1(srcpath, imgprocess_result)
print("\n\n\n方法2")
process2(srcpath, imgprocess_result)
python文件夹批处理操作的更多相关文章
- python之文件的读写和文件目录以及文件夹的操作实现代码
这篇文章主要介绍了python之文件的读写和文件目录以及文件夹的操作实现代码,需要的朋友可以参考下 为了安全起见,最好还是给打开的文件对象指定一个名字,这样在完成操作之后可以迅速关闭文件,防止一些无用 ...
- python 关于文件夹的操作
在python中,文件夹的操作主要是利用os模块来实现的, 其中关于文件夹的方法为:os.lister() , os.path.join() , os.path.isdir() # path 表示文 ...
- Python 文件夹及文件操作
import os import os.path from shutil import copy def copyfile(src, dst): count = 1 for filename in o ...
- [转]python中对文件、文件夹的操作——os模块和shutil模块常用说明
转至:http://l90z11.blog.163.com/blog/static/187389042201312153318389/ python中对文件.文件夹的操作需要涉及到os模块和shuti ...
- python中对文件、文件夹的操作
python中对文件.文件夹的操作需要涉及到os模块和shutil模块. 创建文件: 1) os.mknod("test.txt") 创建空文件 2) open(&qu ...
- java io流 对文件夹的操作
java io流 对文件夹的操作 检查文件夹是否存在 显示文件夹下面的文件 ....更多方法参考 http://www.cnblogs.com/phpyangbo/p/5965781.html ,与文 ...
- Python文件夹备份
Python文件夹备份 import os,shutil def file_copy(path1,path2): f2 = [filename1 for filename1 in os.listdir ...
- Qt: 文件、文件夹的操作;
Qt没有提供单独的函数来对文件.文件夹进行操作, 但是提供了两个类: QFile, QDir; 1.文件操作 ) 文件是否存在: QFile file("D:/test.jpg") ...
- JAVA文件操作类和文件夹的操作代码示例
JAVA文件操作类和文件夹的操作代码实例,包括读取文本文件内容, 新建目录,多级目录创建,新建文件,有编码方式的文件创建, 删除文件,删除文件夹,删除指定文件夹下所有文件, 复制单个文件,复制整个文件 ...
随机推荐
- GO1.6语言学习笔记1-基础篇
一.GO语言优势 可直接编译成机器码,Go编译生成的是一个静态可执行文件,除了glibc外没有其他外部依赖 静态类型语言,但是有动态语言的感觉 语言层面支持并发.Goroutine和channel ...
- ubuntu 16.04 apt-get 更新使用中科大镜像源
1 备份系统配置 sudo cp /etc/apt/sources.list /etc/apt/source.list.bak 2 编辑配置 sudo vi /etc/apt/sources.list ...
- mysql 批量更新常用操作
mysql更新语句很简单,更新一条数据的某个字段,一般这样写:复制代码 代码如下: UPDATE mytable SET myfield = 'value' WHERE other_field = ' ...
- 在 IE 浏览器中,使用 bootstrap 使得页面滚动条浮动显示,自动隐藏,自动消失
貌似是从 IE10 开始?为了触屏操作优化浏览器的内容显示,IE 浏览器提供了一种可以浮动显示,自动隐藏的滚动条样式,但是这个样式会在某些情况下造成一些困扰,比如下图... 其实默认情况下,桌面版的 ...
- Vector3.Set的正确使用
直接调用position.Set会发现没有用.其实和其本身是结构体有关,要当成一个值类型来看待,因为他全部是在栈中. transform.position.Set(,,); 改成这样即可: var t ...
- 【Android】3.4 图层展示
分类:C#.Android.VS2015.百度地图应用: 创建日期:2016-02-04 3.4 示例4--图层展示 一.简介 1.地图类型 百度地图Android SDK 3.7.1提供了两种类型的 ...
- 代码二次封装-xUtils(android)
通常我们会引用很多lib 而且会出现lib 与我们的功能仅仅差一点点 这种情况我们最好不要去改动源代码 而是进行二次封装 举例我使用 xUtils的二次封装 此处说明我是搞ios的 这个是androi ...
- 每日英语:Prosecutors Wrap Up Case Against Bo
Prosecutors wrapped up their case against Bo Xilai on Sunday, sparring with the defiant former Commu ...
- Mac OSX安装 GitLab 5.x
1)安装mac 2) 创建git用户和git组 4) 安装XCode 5) 安装命令行组件 6) 安装 Home brew $ ruby -e "$(curl -fsSL https://r ...
- 索引长度过长 ERROR 1071 (42000): Specified key was too long; max key length is 767 bytes
1.发现问题 今天在修改innodb表的某个列的长度时,报如下错误: alter table test2 modify column id varchar(500); ERROR 1071 (4200 ...