flask celery 使用方法
一、安装
由于celery4.0不支持window,如果在window上安装celery4.0将会出现下面的错误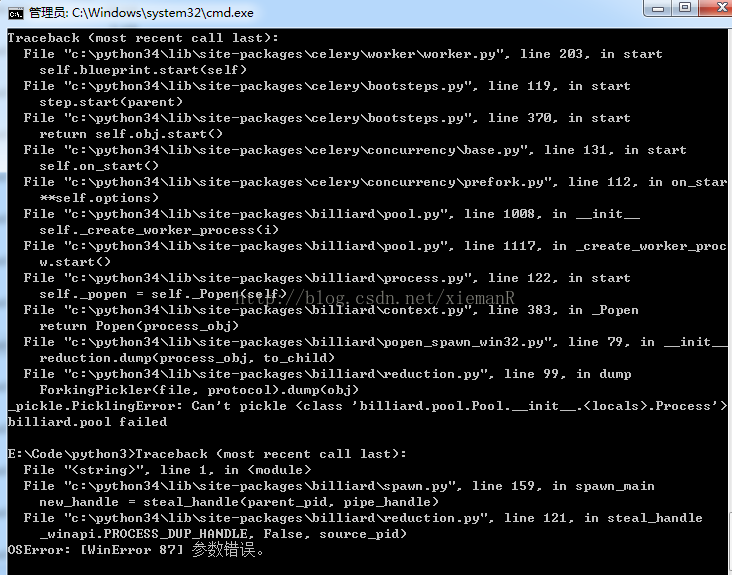 flask_clery
flask_clery
你现在只能安装
pip install celery==3.1
二、安装py for redis 模块
pip install redis
三、安装redis服务
网上很多文章都写得模棱两可,把人坑的不要不要的!!!
Redis对于Linux是官方支持的,但是不支持window,网上很多作者写文章都不写具体的系统环境,大多数直接说pip install redis就可以使用redis了,真的是坑人的玩意,本人深受其毒害
对于windows,如果你需要使用redis服务,那么进入该地址下载
https://github.com/MSOpenTech/redis/releases
redis安装包,双击完成就可以了
如果你在window上不安装该redis包,将会提示
redis.exceptions.ConnectionError: Error 10061 connecting to localhost:6379.
或者
redis.exceptions.ConnectionError
需要注意是:安装目录不能安装在C盘,否则会出现权限依赖错误
四、添加redis环境变量
D:\Program Files\Redis
五、初始化redis
进入redis安装目录,打开cmd运行命令redis-server.exe redis.windows.conf,如果出错
- 双击目录下的
redis-cli.exe - 在出现的窗口中输入
shutdown - 继续输入
exit
六、lask 集成celyer
在Flask配置中添加配置
1 |
# Celery 配置 |
- 在flask工程的
__init__目录下生产celery实例
注意!!以下代码必须在 flask app读取完配置文件后编写,否则会报错
1 |
def make_celery(app): |
完整示例如下
1 |
app = Flask(__name__) |
一份比较常用的配置文件
# 注意,celery4版本后,CELERY_BROKER_URL改为BROKER_URL
BROKER_URL = 'amqp://username:passwd@host:port/虚拟主机名'
# 指定结果的接受地址
CELERY_RESULT_BACKEND = 'redis://username:passwd@host:port/db'
# 指定任务序列化方式
CELERY_TASK_SERIALIZER = 'msgpack'
# 指定结果序列化方式
CELERY_RESULT_SERIALIZER = 'msgpack'
# 任务过期时间,celery任务执行结果的超时时间
CELERY_TASK_RESULT_EXPIRES = 60 * 20
# 指定任务接受的序列化类型.
CELERY_ACCEPT_CONTENT = ["msgpack"]
# 任务发送完成是否需要确认,这一项对性能有一点影响
CELERY_ACKS_LATE = True
# 压缩方案选择,可以是zlib, bzip2,默认是发送没有压缩的数据
CELERY_MESSAGE_COMPRESSION = 'zlib'
# 规定完成任务的时间
CELERYD_TASK_TIME_LIMIT = 5 # 在5s内完成任务,否则执行该任务的worker将被杀死,任务移交给父进程
# celery worker的并发数,默认是服务器的内核数目,也是命令行-c参数指定的数目
CELERYD_CONCURRENCY = 4
# celery worker 每次去rabbitmq预取任务的数量
CELERYD_PREFETCH_MULTIPLIER = 4
# 每个worker执行了多少任务就会死掉,默认是无限的
CELERYD_MAX_TASKS_PER_CHILD = 40
# 设置默认的队列名称,如果一个消息不符合其他的队列就会放在默认队列里面,如果什么都不设置的话,数据都会发送到默认的队列中
CELERY_DEFAULT_QUEUE = "default"
# 设置详细的队列
CELERY_QUEUES = {
"default": { # 这是上面指定的默认队列
"exchange": "default",
"exchange_type": "direct",
"routing_key": "default"
},
"topicqueue": { # 这是一个topic队列 凡是topictest开头的routing key都会被放到这个队列
"routing_key": "topic.#",
"exchange": "topic_exchange",
"exchange_type": "topic",
},
"task_eeg": { # 设置扇形交换机
"exchange": "tasks",
"exchange_type": "fanout",
"binding_key": "tasks",
}, }
在cmd中启动celery服务
执行命令celery -A your_application.celery worker loglevel=info,your_application为你工程的名字,在这里为 get_tieba_film
调用
1 |
@app.route('/')
|
绑定
一个绑定任务意味着任务函数的第一个参数总是任务实例本身(self),就像 Python 绑定方法类似:
1 |
@task(bind=True) |
任务继承
任务装饰器的 base 参数可以声明任务的基类
1 |
import celery |
任务名称
每个任务必须有不同的名称。
如果没有显示提供名称,任务装饰器将会自动产生一个,产生的名称会基于这些信息:
1)任务定义所在的模块,
2)任务函数的名称
显示设置任务名称的例子:
1 |
>>> @app.task(name='sum-of-two-numbers') |
最佳实践是使用模块名称作为命名空间,这样的话如果有一个同名任务函数定义在其他模块也不会产生冲突。
1 |
>>> @app.task(name='tasks.add') |
七、安装flower
将各个任务的执行情况、各个worker的健康状态进行监控并以可视化的方式展现
1 |
pip install flower |
启动flower(默认会启动一个webserver,端口为5555):
1 |
指定broker并启动: celery flower --broker=amqp://guest:guest@localhost:5672// 或 |
八、常见错误
1 |
ERROR/MainProcess] consumer: Cannot connect to redis://localhost:6379/0: |
原因是:redis-server 没有启动
解决方案:到redis安装目录下执行redis-server.exe redis.windows.conf
检查redis是否启动:redis-cli ping
1 |
line 442, in on_task_received |
解决:
1 |
Did you remember to import the module containing this task? |
原因:任务没有注册或注册不成功,只有在启动的时候提示有任务的时候,才能使用该任务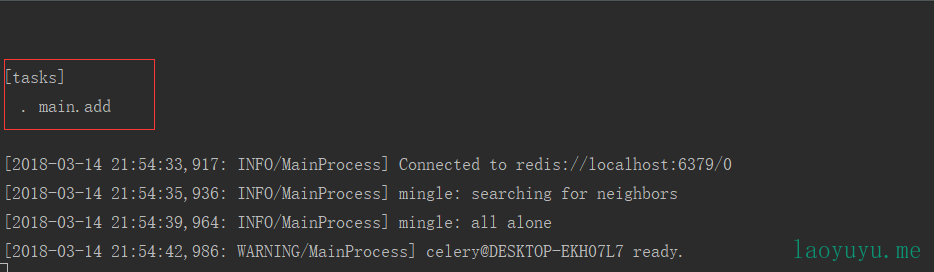 flask_celery
flask_celery
解决:
- 你在那个类中使用celery就在哪个类中执行
celery -A 包名.类名.celery worker -l info - 根据上一部提示的任务列表给任务设置对应的名称
如在Test中
1 |
from main import app, celery @celery.task(name="main.Test.add".) |
目录结构:
1 |
+ Card # 工程 |
则应该启动的命令为:
1 |
celery -A main.Test.celery worker -l info |
同时,如果你的Task.py也有任务,那么你还应该重新创建一个cmd窗口执行
1 |
celery -A main.admin.Task.celery worker -l info |
celery的工作进程可以创建多个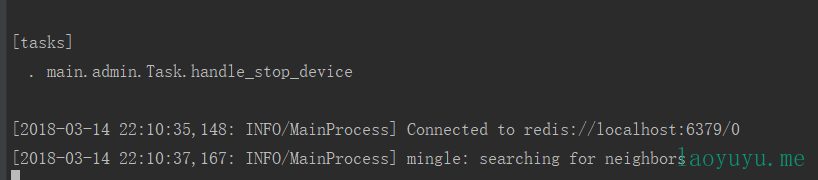 flask_celery
flask_celery flask_celery
flask_celery
参考:
https://www.laoyuyu.me/2018/02/10/python_flask_celery/
https://www.cnblogs.com/cwp-bg/p/8759638.html
celery使用
https://redis.io/topics/quickstart
http://einverne.github.io/post/2017/05/celery-best-practice.html Celery 最佳实践
http://orangleliu.info/2014/08/09/celery-best-practice/ Celery最佳实践-正确使用celery的7条建议
https://www.jianshu.com/p/cc3a0ffb9c76
https://windard.com/opinion/2017/03/18/Task-Queue-Celery 使用 Celery 和 redis 完成任务队列
flask celery 使用方法的更多相关文章
- csrf原理及flask的处理方法
csrf原理及flask的处理方法 为什么需要CSRF? Flask-WTF 表单保护你免受 CSRF 威胁,你不需要有任何担心.尽管如此,如果你有不包含表单的视图,那么它们仍需要保护. 例如,由 A ...
- flask入门小方法
我是在pycharm中写的.那么需要在Termainal中cd 到当前文件所在的文件夹,在运行python py文件名 一开始想用面向对象的方法来封装这些小模块,但发现在面向对象中要用到类属性,以及类 ...
- Flask实战第67天:Flask+Celery实现邮件和短信异步发送
之前在项目中我们发送邮件和 短信都是阻塞的,现在我们来利用Celery来优化它们 官方使用文档: http://flask.pocoo.org/docs/1.0/patterns/celery/ re ...
- [Flask]celery异步任务队列的使用
Celery异步任务队列 目录结构树: 配置文件config.py: # 设置中间人地址 broker_url = 'redis://127.0.0.1:6379/1' 主main.py: impor ...
- flask + celery实现定时任务和异步
参考资料: Celery 官网:http://www.celeryproject.org/ Celery 官方文档英文版:http://docs.celeryproject.org/en/latest ...
- Python Flask API实现方法-测试开发【提测平台】阶段小结(一)
微信搜索[大奇测试开],关注这个坚持分享测试开发干货的家伙. 本篇主要是对之前几次分享的阶阶段的总结,温故而知新,况且虽然看起来是一个小模块简单的增删改查操作,但其实涉及的内容点是非常的密集的,是非常 ...
- flask实现python方法转换服务
一.flask安装 pip install flask 二.flask简介: flask是一个web框架,可以通过提供的装饰器@server.route()将普通函数转换为服务 flask是一个web ...
- celery使用方法
1.celery4.0以上不支持windows,用pip安装celery 2.启动redis-server.exe服务 3.编辑运行celery_blog2.py !/usr/bin/python c ...
- Flask 与 Celery 在 windows 下的集成问题
Flask 与 Celery 在 windows 下的集成问题 所有的 Web 框架内部的视图中不适合执行需要长时间运行的任务,包括 Flask .Django 等.这类型的任务会阻塞 Web 的响应 ...
随机推荐
- win7,8,10取得|取消管理员权限
取得: Windows Registry Editor Version 5.00[HKEY_CLASSES_ROOT\*\shell\runas]@=”管理员取得所有权”“NoWorkingDirec ...
- [Python]项目打包:5步将py文件打包成exe文件 简介
1.下载pyinstaller并解压(可以去官网下载最新版): http://nchc.dl.sourceforge.net/project/pyinstaller/2.0/pyinstaller-2 ...
- 项目重命名&复制项目&删除项目
项目重命名&复制项目&删除项目 CreateTime--2016年10月15日17:25:43 Author:Marydon 1.修改项目名或者复制的项目名 第一步: my ...
- (转)Content-Disposition的使用和注意事项
最近不少Web技术圈内的朋友在讨论协议方面的事情,有的说web开发者应该熟悉web相关的协议,有的则说不用很了解.个人认为这要分层次来看待这个问 题,对于一个新手或者刚入门的web开发人员而言,研究协 ...
- PHP-FastCGI详解
一.什么是 FastCGI FastCGI是一个可伸缩地.高速地在HTTP server和动态脚本语言间通信的接口.多数流行的HTTP server都支持FastCGI,包括Apache.Nginx和 ...
- HUDOJ-----1394Minimum Inversion Number
Minimum Inversion Number Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Java ...
- HDUOJ----1250 Hat's Fibonacci
Hat's Fibonacci Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others)T ...
- Python使用chardet包自动检测编码
chardet:charset detection 一旦自动检测出编码,就可以解码了. 八种文件打开方式 w:一旦打开文件,文件内容就清空了 r:只读方式打开 a:追加方式打开 r+:先读后写 以上四 ...
- SPFA 上手题 数 枚:
1, HDU 1548 A strange lift :http://acm.hdu.edu.cn/showproblem.php?pid=1548 这道题可以灰常巧妙的转换为一道最短路题目,对第i层 ...
- 什么是RESTfull?理解RESTfull架构【转】
越来越多的人开始意识到,网站即软件,而且是一种新型的软件. 这种"互联网软件"采用客户端/服务器模式,建立在分布式体系上,通过互联网通信,具有高延时(high latency).高 ...