利用人工智能(Magpie开源库)给一段中文的文本内容进行分类打标签
当下人工智能是真心的火热呀,各种原来传统的业务也都在尝试用人工智能技术来处理,以此来节省人工成本,提高生产效率。既然有这么火的利器,那么我们就先来简单认识下什么是人工智能吧,人工智能是指利用语音识别、语义理解、图像识别、视觉处理、机器学习、大数据分析等技术实现机器智能自动化做出响应的一种模拟人行为的手段。而我们这里介绍的Magpie则属于人工智能领域里语义理解、机器学习中的一个具体的实现技术。
前述
近期因为工作原因,需要从来自于客户聊天对话的文本中进行用户行为判断,并对其打上相应的标签。而我需要解决的就是利用文本内容进行机器自动分类打标签,但在业务中,一段文本会存有不同的多个标签,那么如何来实现呢?通过Github,找到了Magpie,发现其与我的需求非常吻合。一番折腾后,就有了本文章。
Magpie
Magpie是一个开源的文本分类库,基于一个高层神经网络Keras技术编写,后端默认由Tensorflow来处理。Magpie是由Python语言开发的,且默认只支持英文文本分类,我因为业务需要便在其基础上做了中文文本的支持。如下是Magpie相关的网址:
Magpie官网:https://github.com/inspirehep/magpie
Keras中文文档:https://keras-cn.readthedocs.io/en/latest/
实现
通过上面的介绍,我们清楚了需要实现的业务与目的,以及采用的技术手段。那么,就让我们一起来看看借助Magpie会有什么神秘的事情发生吧。
1、从Magpie下载源码包到本地,通过PyCharm IDE开发工具打开项目后发现有“data”、“magpie”、“save”等目录。其中“data”目录用于存放训练的源数据,“magpie”目录用于存放源代码,“save”目录用于存放训练后的模型文件,具体结如下图:
2、在项目中引用相应的第三方类库,如下:
'nltk~=3.2', 'numpy~=1.12', 'scipy~=0.18', 'gensim~=0.13', 'scikit-learn~=0.18', 'keras~=2.0', 'h5py~=2.6', 'jieba~=0.39',
3、对项目有了一定认识后,现在我们来准备源数据。我们这里假定有三种标签,分别为“军事“、”旅游“'、”政治”,每个标签各准备一定数量的源数据(训练数据理论上是越多越好,这里我偷懒就只按每个标签各准备了50条数据),其中拿出70%做为训练数据,30%做为测试数据,根据Magpie规则将训练源数据放到“data”目录内。
4、数据准备好后,我们需要改动源代码,使其能支持中文。中文面临一个问题就是分词,而我们这里使用jieba分词库。依次打开”magpie\base“目下的”Document“类中,并在该类内加入相应的分词代码,具体代码如下:
from __future__ import print_function, unicode_literals
import re
import io
import os
import nltk
import string
import jieba
from nltk.tokenize import WordPunctTokenizer, sent_tokenize, word_tokenize
nltk.download('punkt', quiet=True) # make sure it's downloaded before using
class Document(object):
""" Class representing a document that the keywords are extracted from """
def __init__(self, doc_id, filepath, text=None):
self.doc_id = doc_id
if text:
text = self.clean_text(text)
text = self.seg_text(text)
self.text = text
self.filename = None
self.filepath = None
else: # is a path to a file
if not os.path.exists(filepath):
raise ValueError("The file " + filepath + " doesn't exist")
self.filepath = filepath
self.filename = os.path.basename(filepath)
with io.open(filepath, 'r', encoding='gbk') as f:
text_context = f.read()
text_context = self.clean_text(text_context)
self.text = self.seg_text(text_context)
print(self.text)
self.wordset = self.compute_wordset()
# 利用jieba包进行分词,并并且去掉停词,返回分词后的文本
def seg_text(self,text):
stop = [line.strip() for line in open('data/stopwords.txt', encoding='utf8').readlines()]
text_seged = jieba.cut(text.strip())
outstr = ''
for word in text_seged:
if word not in stop:
outstr += word
outstr += ""
return outstr.strip()
# 清洗文本,去除标点符号数字以及特殊符号
def clean_text(self,content):
text = re.sub(r'[+——!,;/·。?、~@#¥%……&*“”《》:()[]【】〔〕]+', '', content)
text = re.sub(r'[▲!"#$%&\'()*+,-./:;<=>\\?@[\\]^_`{|}~]+', '', text)
text = re.sub('\d+', '', text)
text = re.sub('\s+', '', text)
return text
def __str__(self):
return self.text
def compute_wordset(self):
tokens = WordPunctTokenizer().tokenize(self.text)
lowercase = [t.lower() for t in tokens]
return set(lowercase) - {',', '.', '!', ';', ':', '-', '', None}
def get_all_words(self):
""" Return all words tokenized, in lowercase and without punctuation """
return [w.lower() for w in word_tokenize(self.text)
if w not in string.punctuation]
def read_sentences(self):
lines = self.text.split('\n')
raw = [sentence for inner_list in lines
for sentence in sent_tokenize(inner_list)]
return [[w.lower() for w in word_tokenize(s) if w not in string.punctuation]
for s in raw]
5、通这上述的改造,我们的分类程序可以较好的支持中文了,接下来就可以进行数据训练了。项目是通过运行”train.py“类来进行训练操作,但在运行之前我们需要对该类做下改动,具体代码如下:
from magpie import Magpie
magpie = Magpie()
magpie.train_word2vec('data/hep-categories', vec_dim=3) #训练一个word2vec
magpie.fit_scaler('data/hep-categories') #生成scaler
magpie.init_word_vectors('data/hep-categories', vec_dim=3) #初始化词向量
labels = ['军事','旅游','政治'] #定义所有类别
magpie.train('data/hep-categories', labels, test_ratio=0.2, epochs=20) #训练,20%数据作为测试数据,5轮
#保存训练后的模型文件
magpie.save_word2vec_model('save/embeddings/here', overwrite=True)
magpie.save_scaler('save/scaler/here', overwrite=True)
magpie.save_model('save/model/here.h5')
6、运行”train.py“类来进行训练数据,截图如下:

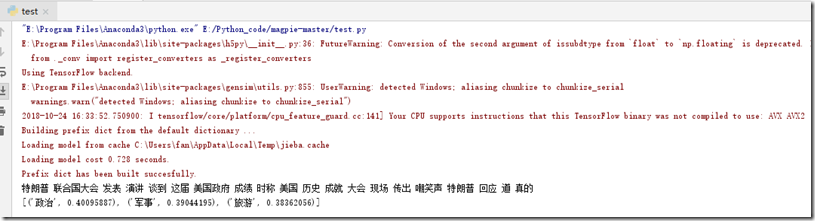
7、模型训练成功后,接下来就可以进行模拟测试了。项目是通过运行”test.py“类来进行测试操作,但在运行之前我们需要对该类做下改动,具体代码如下:
from magpie import Magpie
magpie = Magpie(
keras_model='save/model/here.h5',
word2vec_model='save/embeddings/here',
scaler='save/scaler/here',
labels=['旅游', '军事', '政治']
)
#单条模拟测试数据
text = '特朗普在联合国大会发表演讲谈到这届美国政府成绩时,称他已经取得了美国历史上几乎最大的成就。随后大会现场传出了嘲笑声,特朗普立即回应道:“这是真的。”'
mag1 = magpie.predict_from_text(text)
print(mag1)
'''
#也可以通过从txt文件中读取测试数据进行批量测试
mag2 = magpie.predict_from_file('data/hep-categories/1002413.txt')
print(mag2)
'''
8、运行”test.py“类来进行测试数据,截图如下:
总结
1、文本分类在很多场景中都能应用,比如垃圾邮件分类、用户行为分析、文章分类等,通过本文简单的演示后聪明的你是不是有了一个更大的发现呢!
2、本文使用了Magpie开源库实现模型训练与测试,后台用Tensorflow来运算。并结合jieba分词进行中文切词处理。
3、Magpie本身是不支持中文文本内容的,在这里我加入了jieba分词库后使得整个分类程序有了较好的支持中文文本内容的能力。
4、本文测试分值跟训练数据的数量有一定关系,训练数据理论上是越多越好。
5、分享一句话:人工智能要有多少的智能,就必需要有多少的人工。
声明
本文为作者原创,转载请备注出处与保留原文地址,谢谢。如文章能给您带来帮助,请点下推荐或关注,感谢您的支持!
利用人工智能(Magpie开源库)给一段中文的文本内容进行分类打标签的更多相关文章
- DCMTK开源库的学习笔记4:利用ini配置文件对dcm影像进行归档
转:http://blog.csdn.net/zssureqh/article/details/8846337 背景介绍: 医学影像PACS工作站的服务端需要对大量的dcm文件进行归档,写入数据库处理 ...
- CocoaPods的安装及使用/利用开源库Diplomat实现分享及第三方登录/git的使用
<<史上最简洁版本>> 1.gem sources -l查看 当前的源 //1.1 sudo -i..以下都是以管理员的身份来操作的 2.gem sources --remov ...
- 利用cocoapods管理开源项目,支持 pod install安装整个流程记录(github公有库)
利用cocoapods管理开源项目,支持 pod install安装整个流程记录(github公有库),完成预期的任务,大致有下面几步: 1.代码提交到github平台 2.创建.podspec 3. ...
- C# 人工智能开源库生物特征
C# 人工智能开源库生物特征 Machine learning made in a minute http://accord-framework.net/ Accord.NET是AForge.NET框 ...
- GitHub上那些值得一试的JAVA开源库--转
原文地址:http://www.jianshu.com/p/ad40e6dd3789 作为一名程序员,你几乎每天都会使用到GitHub上的那些著名Java第三方库,比如Apache Commons,S ...
- 各种有用的PHP开源库精心收集
转自:http://my.oschina.net/caroltc/blog/324024 摘要 各种有用的PHP开源库精心收集,包含图片处理,pdf生成,网络协议,网络请求,全文索引,高性能搜索,爬虫 ...
- GitHub上那些值得一试的JAVA开源库
作为一名程序员,你几乎每天都会使用到GitHub上的那些著名Java第三方库,比如Apache Commons,Spring,Hibernate等等.除了这些,你可能还会fork或Star一些其他的开 ...
- [转贴]C++开源库
C++在“商业应用”方面,曾经是天下第一的开发语言,但这一 桂冠已经被java抢走多年.因为当今商业应用程序类型,已经从桌面应用迅速转移成Web应 用.当Java横行天下之后,MS又突然发力,搞出C# ...
- DICOM医学图像处理:开源库mDCM与DCMTK的比較分析(一),JPEG无损压缩DCM图像
背景介绍: 近期项目需求,须要使用C#进行最新的UI和相关DICOM3.0医学图像模块的开发.在C++语言下,我使用的是应用最广泛的DCMTK开源库,在本专栏的起初阶段的大多数博文都是对DCMTK开源 ...
随机推荐
- H5页面获取openid,完成支付公众号(未关注公众号)支付
一.页面授权 // 进入页面获取权限code function initAuthorizeCode() { var appid = $("#appid").val();//公众号a ...
- shred_linux_unix
Sometimes you need to destroy or wipe data from hard drives (for example, before you sell your old h ...
- host is not allowed to connect to this mysql解决方案
报错:1130-host ... is not allowed to connect to this MySql server 解决方法: 1. 改表法. 可能是你的帐号不允许从远程登陆,只能在l ...
- Java 利用缓冲字节流来实现视频、音频、图片的复制粘贴
InputStream:继承自InputStream的流都是用于向程序中输入数据的,且数据单位都是字节(8位). OutputSteam:继承自OutputStream的流都是程序用于向外输出数据的, ...
- Java缓存相关memcached、redis、guava、Spring Cache的使用
随笔分类 - Java缓存相关 主要记录memcached.redis.guava.Spring Cache的使用 第十二章 redis-cluster搭建(redis-3.2.5) 摘要: redi ...
- 关于centos7.5部署oelinker_php版本的问题点汇总
1.下载开源版本https://github.com/eolinker/eoLinker-AMS-Lite-For-PHP到本地,将release文件夹内容copy到apache的/var/www/h ...
- linux centos 6.1 安装 redis
1, yum install redis 检测是否有redis 2,没有的话就运行:yum install epel-release 3,再执行 yum install redis
- Hyberledger-Fabric 1.00 RPC学习(1)
参考:http://hyperledger-fabric.readthedocs.io/en/latest/write_first_app.html 本文的目的就是基于Hyperledger Fabr ...
- 概率分布之间的距离度量以及python实现
1. 欧氏距离(Euclidean Distance) 欧氏距离是最易于理解的一种距离计算方法,源自欧氏空间中两点间的距离公式.(1)二维平面上两点a(x1,y1)与b(x2,y2)间的欧 ...
- springmvc 数据验证 hibernate-validator --->对象验证
数据验证步骤: 1.测试环境的搭建: 2.验证器的注册 在springmvc.xml配置文件中加以下代码: 3.验证注解添加到对应实体类上 4.修改处理器 5.将验证失败信息写入到表单 index.j ...