深入理解HDFS 错误恢复
我们从动态的角度来看 hdfs
先从场景出发,我们知道 hdfs 的写文件的流程是这样的:
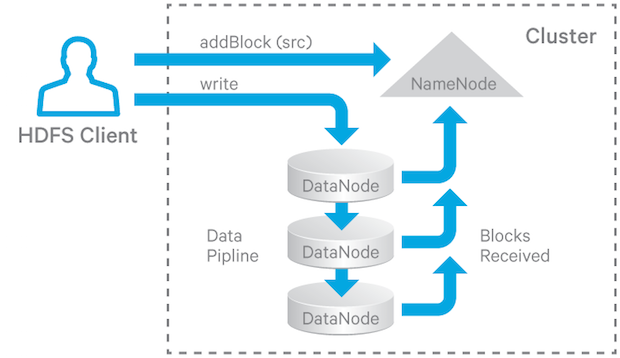
数据以 pipeline 的方式写入 hdfs ,然后对于读取操作,客户端选择其中一个保存块副本的 DataNode 来读数据.考虑这样两个场景:
- hbase rs 在写 wal log 的时候.如果一个 rs 挂了.那么这个 rs 会转移并且通过读取 wal log 来恢复之前的状态.如果这个rs 挂的时候 ,写 wal log 的 pipeline 没有完成,那么必然这份 wal log 数据在不同的dn 上是存在差异的. 那么 hdfs 是如何保证 rs 转移后能够恢复到正确的状态?
- 流计算写入hdfs ,如果中间 datanode 挂了.hdfs 是如何保证这个流计算程序不抛出错误,并持续运行下去的?
这里就引出了 hdfs 一个非常重要的特性就是 hdfs 写的错误恢复.对于 hdfs 的写的错误恢复.进而就需要了解三个重要概念: lease recovery, block recovery, and pipeline recovery . hdfs 的写的容错性就是由这三个概念保证的. 这三个概念也是相互关联,相互包含的.一切跟写文件有关:
- 租约恢复 在客户端可以写入 HDFS 文件之前,它必须获得租约,这本质上是一个锁。如果客户端希望继续写,则必须在约定的时间段内续租。如果租约没有明确更新或持有它的客户端死亡了,那么它就会过期。发生这种情况时,HDFS 将代表客户端关闭文件并释放租约,以便其他客户端可以写入该文件。这个过程称为租约恢复。
- 块恢复 如果正在写入的文件的最后一个块没有传递到管道中的所有 DataNode,那么当发生租约恢复时,写入不同节点的数据量可能会不同。在租约恢复导致文件关闭之前,需要一个过程来确保最后一个块的所有副本具有相同的长度.此过程称为块恢复。块恢复仅在租约恢复过程中触发,并且在租约恢复中仅在文件的最后一个块不处于 COMPLETE 状态时才触发块恢复。
- 管道恢复 在写入管道操作期间,管道中的某些 DataNode 可能会失败。发生这种情况时,底层的写操作不能只是失败。相反,HDFS 将尝试从错误中恢复,以允许管道继续运行并且客户端继续写入文件。从管道错误中恢复的机制称为管道恢复。
我们知道写文件,就是写 block . 上面这些错误恢复,最终的目的无非是要保证所有客户端的文件的所有 block 都能够完整的写入所有的 datanode . 所以,还得从更细致的角度去看 block,了解 block 的一些概念及语义
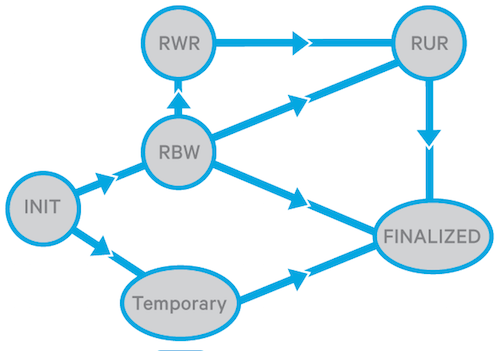
首先,把 datanode 中的 block 称之为 replica(副本) .用以区分 namenode 中的 block(块). 对于 replica ,它有如下几种状态,也对应了 replica 写入到 datanode 的一个动态过程:
- FINALIZED 当副本处于此状态时,对副本的写入完成并且副本中的数据被“冻结”(长度已确定),除非重新打开副本以进行追加。具有相同 generation stamp 的块的所有最终副本(称为 GS)应该具有相同的数据。最终副本的 GS 可能会因恢复发生而增加。
- RBW (Replica Being Written) 这是正在写入的任何副本的状态,无论文件是为写入而创建的,还是为追加而重新打开的。 RBW 副本始终打开文件的一个块。数据仍在往副本里面写,尚未最终确定。 RBW 副本的数据(不一定是所有)对读取客户端可见。如果发生任何故障,将尝试将数据保存在 RBW 副本中。
- RWR (Replica Waiting to be Recovered) 如果一个 DataNode 死掉并重新启动,它的所有 RBW 副本都将更改为 RWR 状态。 RWR 副本要么过时并因此被丢弃,要么将参与租约恢复中的块恢复。
- RUR (Replica Under Recovery) 非 TEMPORARY 副本在参与租约恢复时将更改为 RUR 状态。
- TEMPORARY 临时副本,用于块复制,由 replication monitor 或cluster balancer 来发起。它类似于 RBW 副本,只是它的数据对所有读取器客户端都是不可见的。如果块复制失败,将删除一个 TEMPORARY 副本。
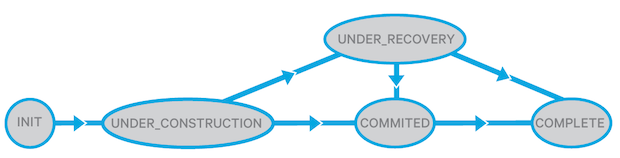
以上就是 datanode 的 副本状态,接着对比一下 namenode 的块状态:
- UNDER_CONSTRUCTION 这是写入时的状态。 UNDER_CONSTRUCTION 块是打开文件的最后一个块;它的长度和 GS 仍然是可变的,并且它的数据(不一定是全部)对读者是可见的。 NameNode 中的 UNDER_CONSTRUCTION 块会跟踪管道中的合法 RBW 及 RWR 副本的位置。
- UNDER_RECOVERY 如果一个文件的最后一个块在相应客户端的租约到期时处于 UNDER_CONSTRUCTION 状态,那么就会开始块恢复,同时它将变为 UNDER_RECOVERY 状态。
- COMMITTED COMMITTED 意味着一个块的数据和 GS 不再可变(除非它被重新打开用以追加, 并且此时上报上来的有相同 GS/长度的 FINALIZED 副本的 DataNode 数要少于设定的最小副本数。为了服务读取请求,COMMITTED 块必须跟踪 RBW 副本的位置、GS 及其 FINALIZED 副本的长度。当客户端要求 NameNode 向文件添加新的块或关闭文件时,UNDER_CONSTRUCTION 块将更改为 COMMITTED。如果最后一个或倒数第二个块处于 COMMITTED 状态,则无法关闭文件,客户端必须进行重试。
- COMPLETE 当 NameNode 检测到 匹配 GS/长度要求的 FINALIZED 副本数达到最小副本数的要求时,COMMITTED 块更改为 COMPLETE。只有当文件的所有块都变为 COMPLETE 时才能关闭文件。一个块可能会被强制进入 COMPLETE 状态,即使它没有最小的复制副本数 . 例如,当客户端请求一个新块时,前一个块尚未完成这种情况.
DataNode 将副本的状态保存到磁盘,但 NameNode 不会将块状态保存到磁盘。当 NameNode 重新启动时,它将先前所有打开的文件的最后一个块的状态更改为 UNDER_CONSTRUCTION 状态,并将所有其他块的状态更改为 COMPLETE。
副本和块的简化状态转换如两图所示:
在上面副本/块状态转换过程中,有一个重要的判断依据,那就是 Generation Stamp(GS)
GS 是由 NameNode 持久维护的每个块的单调递增的 8 字节数。块和副本的 GS 主要的作用是以下:
- 检测块的陈旧副本:即,当副本 GS 比块 GS 旧时,例如,在副本中以某种方式跳过 append 操作时,可能会发生这种情况。
- 检测 DataNode 上的过期副本,比如 datanode 死了很长时间后重新加入集群。
当发生以下任何一种情况时,需要生成一个新的 GS:
- 创建了一个新文件
- 客户端打开现有文件以进行 append 或 truncate
- 客户端在向 DataNode(s) 写入数据时遇到错误并请求新的 GS
- NameNode 启动文件的租约恢复
接下来,我们来看租约恢复,块恢复是由租约恢复触发,并且包含在租约恢复过程中的.
租约恢复过程是在 NameNode 上触发的.触发的场景有如下两个:当监控线程监控到租约 hard limit 到期时,或者一个客户端在 soft limit到期时尝试从另一个客户端接管租约时。租约恢复会检查由同一客户端写入的每个打开文件,如果文件的最后一个块不处于 COMPLETE 状态,则对文件执行块恢复,然后关闭文件。
下面是给定文件 f 的租约恢复过程。当客户端异常死亡时,这个客户端写入而打开的每个文件也会发生如下过程:
- 得到 包含 f 的最后一个块的 DataNode。
- 将其中一个 DataNode 指定为主 DataNode p。
- p 从 NameNode 获取新的 GS 标记。
- p 从每个 DataNode 获取这个块的信息。
- p 计算得到这个块的最小长度。
- p 更新具有合法 GS 标记的 DataNode 的块, 让其更新为新的 GS 标记和最小块的长度。
- p 通知 NameNode 更新的结果。
- NameNode 更新 BlockInfo。
- NameNode 删除 f 的租约(其他写入者现在可以获得写入 f 的租约)。
- NameNode 向 edit log 提交更改。
其中步骤 3 到 7 是恢复过程中的块恢复部分。
有时,需要在硬限制到期之前强制恢复文件的租约。为此,可以使用命令强制恢复租约:
hdfs debug recoverLease [-path] [-retries ]
由内到外,接下来,继续看外层的管道恢复 (pipeline recovery)
首先看写入管道(write pipeline)的流程
当 HDFS 客户端写入文件时,数据将作为顺序块写入。为了写入或构造一个块,HDFS 将块分成 packets(实际上不是网络数据包,而是消息;packets 实际是指带着这些消息的类),并将它们传递到写入管道中的每个 DataNode,如下图:
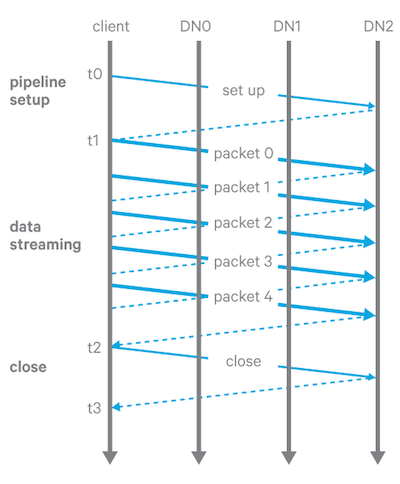
写流水线分为三个阶段:
- 管道启动。客户端沿管道发送 Write_Block 请求,最后一个 DataNode 发送回确认。收到确认后,管道准备好写入。
- 数据流。数据通过管道以数据包的形式发送。客户端缓存数据,直到一个packet 数据包被填满,然后将数据包发送到管道。如果客户端调用 hflush(),那么即使一个数据包没有满,它仍然会被发送到管道并且必须得收到前一个数据包 hflush() 的确认。
- 关闭(finalize 副本并关闭管道)。客户端等待直到所有数据包都被确认,然后发送关闭请求。管道中的所有 DataNode 将相应的副本更改为 FINALIZED 状态并报告回 NameNode。如果配置的最小副本数量的 DataNode 报告了其相应副本的 FINALIZED 状态,则 NameNode 然后将块的状态更改为 COMPLETE。
当管道中的一个或多个 DataNode 在写入块的三个阶段中的任何一个中遇到错误时,则会启动管道恢复。
从管道启动失败中恢复
- 如果管道是为一个新块创建的,客户端会放弃该块并向 NameNode 请求一个新块和一个新的 DataNode 列表。管道为新块重新初始化。
- 如果创建管道 append 块操作,则客户端使用剩余的 DataNode 重建管道并增加块的 GS 标记。
从数据流失败中恢复
- 当管道中的 DataNode 检测到错误(例如,checksum 错误或写入磁盘失败)时,该 DataNode 通过关闭所有 TCP/IP 连接将自己从管道中取出。
- 接着客户端检测到故障,它会停止向管道发送数据,并使用剩余的 DataNode 重建新的管道。接着,该块的所有副本都被更新到一个新的 GS。
- 客户端使用这个新的 GS 继续发送数据包。如果发送的数据已经被某些 DataNode 接收了,他们会忽略该数据包并往管道下游传递.
从关闭失败中恢复
当客户端在关闭状态下检测到故障时,它会使用剩余的 DataNode 重建管道。如果副本尚未最终确定,则每个 DataNode 都会增加副本的 GS 并最终确定副本。
当一个 DataNode 坏时,它会将自己从管道中移除。在管道恢复过程中,客户端可能需要使用剩余的 DataNode 重建新的管道。 (它可能会也可能不会用新的 DataNode 替换坏的 DataNode,这取决于下文中配置的 DataNode 替换策略。)replication 监视器将负责复制块以满足配置的副本数。
失败时 datanode 的替换策略
在使用剩余的 DataNode 设置恢复管道时,关于是否添加额外的 DataNode 以替换坏的 DataNode 有四种可配置策略:
- DISABLE:禁用 DataNode 替换并在dn 上抛出错误。
- NEVER:当管道发生故障时,永远不替换 DataNode(通常不建议)。
- DEFAULT:根据以下条件替换:
a. 假设 r 为配置的副本数。
b. 设 n 为现已有副本数据的节点的数量。
c. 仅当 r >= 3 且满足下面任一条件才添加新的 DataNode- flour(r/2) >= n
- r > n 并且块是被 hflushed/appended
- ALWAYS:当现有的 DataNode 失败时,总是添加一个新的 DataNode。如果无法替换 DataNode,则会失败。
替换策略的开关为 dfs.client.block.write.replace-datanode-on-failure.enable ,值为 false 时,禁用所有策略.
值为 true,打开替换策略,此时通过配置 dfs.client.block.write.replace-datanode-on-failure.policy 来指定策略,默认策略为 default
使用 default 或 always 时,如果管道中只有一个 DataNode 成功,则错误恢复永远不会成功,客户端将无法执行写入直到超时。这种情况可以配置如下属性来解决此问题:dfs.client.block.write.replace-datanode-on-failure.best-effort
默认为false。使用默认设置,客户端将继续尝试,直到满足指定的策略。当该属性设置为 true 时,即使不能满足指定的策略(例如管道中只有一个成功的 DataNode,小于策略要求),仍然允许客户端继续来写。
租约恢复、块恢复和管道恢复对于 HDFS 容错至关重要。它们共同保证了即使存在网络和节点故障的情况下,写入到 HDFS 中是持久且一致的,
深入理解HDFS 错误恢复的更多相关文章
- 再理解HDFS的存储机制
再理解HDFS的存储机制 1. HDFS开创性地设计出一套文件存储方式.即对文件切割后分别存放: 2. HDFS将要存储的大文件进行切割,切割后存放在既定的存储块(Block)中,并通过预先设定的优化 ...
- Android IOS WebRTC 音视频开发总结(七五)-- WebRTC视频通信中的错误恢复机制
本文主要介绍WebRTC视频通信中的错误恢复机制(我们翻译和整理的,译者:jiangpeng),最早发表在[这里] 支持原创,转载必须注明出处,欢迎关注我的微信公众号blacker(微信ID:blac ...
- 连接字符串中Min Pool Size的理解是错误,超时时间已到,但是尚未从池中获取连接。出现这种情况可能是因为所有池连接均在使用,并且达到了最大池大小。
Min Pool Size的理解是错误的 假设我们在一个ASP.NET应用程序的连接字符串中将Min Pool Size设置为30: <add name="cnblogs" ...
- webrtc如何进行错误恢复
视频的压缩方法:(三种帧) 为了视频尽可能的保持高效,视频数据通过不同的编码进行压缩.以帧为单位进行压缩,按照压缩中的不同作用可分类为:内帧(Intra-frames,I帧),预测帧(Predicti ...
- 深入理解HDFS分布式文件系统
深入理解HDFS:Hadoop分布式文件系统: https://blog.csdn.net/bingduanlbd/article/details/51914550
- 深刻理解HDFS工作机制
深入理解一个技术的工作机制是灵活运用和快速解决问题的根本方法,也是唯一途径.对于HDFS来说除了要明白它的应用场景和用法以及通用分布式架构之外更重要的是理解关键步骤的原理和实现细节.在看这篇博文之前需 ...
- 第五篇 SQL Server代理理解代理错误日志
本篇文章是SQL Server代理系列的第五篇,详细内容请参考原文. 正如这一系列的前几篇所述,SQL Server代理作业是由一系列的作业步骤组成,每个步骤由一个独立的类型去执行.在第四篇中我们看到 ...
- 【译】第五篇 SQL Server代理理解代理错误日志
本篇文章是SQL Server代理系列的第五篇,详细内容请参考原文. 正如这一系列的前几篇所述,SQL Server代理作业是由一系列的作业步骤组成,每个步骤由一个独立的类型去执行.在第四篇中我们看到 ...
- 大数据学习day23-----spark06--------1. Spark执行流程(知识补充:RDD的依赖关系)2. Repartition和coalesce算子的区别 3.触发多次actions时,速度不一样 4. RDD的深入理解(错误例子,RDD数据是如何获取的)5 购物的相关计算
1. Spark执行流程 知识补充:RDD的依赖关系 RDD的依赖关系分为两类:窄依赖(Narrow Dependency)和宽依赖(Shuffle Dependency) (1)窄依赖 窄依赖指的是 ...
- 理解HDFS高可用性架构
在Hadoop1.x版本的时候,Namenode存在着单点失效的问题.如果namenode失效了,那么所有的基于HDFS的客户端——包括MapReduce作业均无法读,写或列文件,因为namenode ...
随机推荐
- php环境,性能优化
根据宝塔的推荐进行参数修改 我的是8G内存,修改成4G内存 下面是备份:修改前的 ; Start a new pool named 'www'.; the variable $pool can be ...
- MSPM0G3507外设DMA学习笔记
概述 变量的存储 正常情况下,变量存储在SRAM中,如果要发送该变量的值到外设,需要调用内核操作,使SRAM中的数据送到外设. 此类型操作过多会导致占用CPU高,整体卡顿. DMA控制概述 DMA:D ...
- 【Vue】Re09 Webpack 第一部分(介绍、安装、配置)
一.Webpack的用途 webpack要解决的是统一网页资源的问题 前端工程化出现了很多问题,就是兼容性,浏览器所不能解析 所以需要一个打包,转换等方式处理 二.安装描述介绍 下载安装NodeJS, ...
- NVIDIA黃仁勳給年輕人的忠告 —— 持续强化学习算法会是未来10年的技术变革点
地址: https://www.youtube.com/watch?v=ER4xNhSVJ2c 强化学习,已经不是什么稀奇的概念了,强化学习算法是大语言模型.自动驾驶.人形机器人的核心算法,但是现有的 ...
- 为什么被要求避免使用orcid
前段时间收到了最高机构的通知,要求不要使用orcid,并对之前使用的情况进行自查.得到这个通知,我其实还是蛮无感的,毕竟我一篇论文也没法过,而且也没有用过这个orcid,虽然我自己也是有这个的. 关于 ...
- idea中多线程debug实现方案
1.背景 2.步骤 步骤一: 步骤二: 步骤三: 启动测试,查看个线程状态 完美
- iOS开发基础148-ABM vs MDM
Apple Business Manager (ABM) vs. Mobile Device Management (MDM) Apple Business Manager (ABM) 优点: 集中管 ...
- 你要的高效方案!基于Apache SeaTunnel快速集成SAP进入Redshift
摘要 本文深入探讨了Apache SeaTunnel及其商业版可视化数据同步平台WhaleTunnel在数据整合领域的应用,特别是如何高效地将SAP系统中的数据同步到Amazon Redshift.通 ...
- vue3:setup语法糖使用教程
setup语法糖简介 直接在script标签中添加setup属性就可以直接使用setup语法糖了. 使用setup语法糖后,不用写setup函数:组件只需要引入不需要注册:属性和方法也不需要再返回,可 ...
- 美化一下WPF自带得ToolTip
对照一下原版和美化以后得版本 原版: ---------- 新版: 新增了 圆角 和 阴影效果; 第一步:新建项,最下面有一个自定义控件,取名为CornerToolTip. 第二步:系统会创建一个Co ...