mysql进阶-SQL优化篇
SQL优化
-插入数据
批量插入:(一次尽量不超过1000条)
Insert into tb test values(1,'Tom'),(2,'cat'),(3, Jerny');
手动事务提交:
start transaction;
insert into tb_test values(1,'Tom'"),(2,'Cat'),(3, jerry');
insert into tb test values(4,'Tom'),(5,'Cat'),(6, jerry');
insert into tb test values(7,"Tom'),(8,'Cat'),(9,jerry');
commit;
主键顺序插入:
取决于mysql数据组织结构(后面会将主键优化),将插入主键按从小到大进行排列。
大批量数据插入:
如果一次性需要插入大批量数据,使用insert语句插入性能较低,此时可以使用MYSQL数据库提供的load指令进行插入。操作如下。
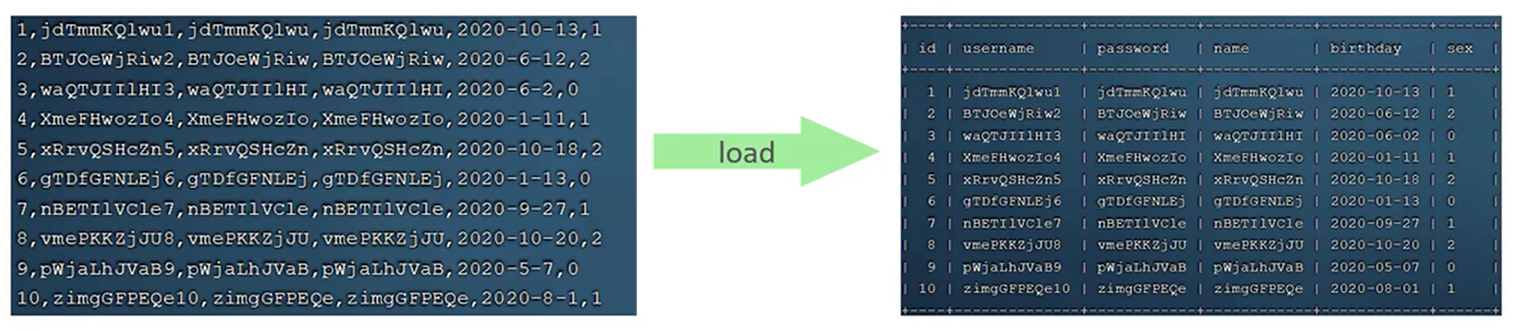
#客户端连接服务端时,加上参数--local-infile
mysql --local-infile -u root -p
#设置全局参数local infile为1,开启从本地加载文件导入数据的开关
select @@local infile;//查看是否开启0否1是
set global local infile =1;
#执行load指令将准备好的数据,加载到表结构中以","隔开字段。每一行通过"\n"分割
load data local infile '/root/sql1.log' into table `tb_user` fields terminated by ',' lines terminated by '\n';
注意:
load插入时最好也按照主键顺序插入,顺序插入性能会高于乱序插入。(为什么请看主键优化)
- 主键优化
在InnoDB存储引擎中,表数据都是根据主键顺序组织存放的,这种存储方式的表称为索引组织表(index organized table IOT)
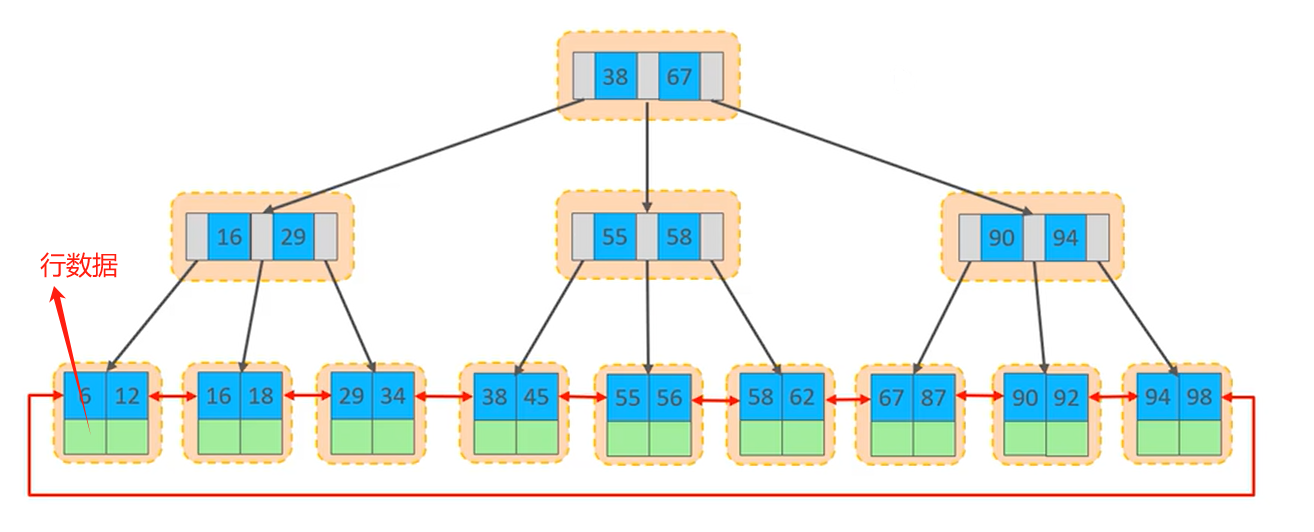
页可以为空也可以填充一半,也可以填充100%。每个页包含了2-N行数据(如果一行数据多大,会行溢出),根据主键排列。
主键顺序插入示意图:

页分裂:
若主键乱序插入因xxxx可能会造成页分裂
页合并:
当删除一行记录时,实际上记录并没有被物理删除,只是记录被标记(flaged)为删除并且它的空间变得允许被其他记录声明使用。
当页中删除的记录达到 MERGE_THRESHOLD(默认为页的50%),InnoDB会开始寻找最靠近的页(前或后)看看是否可以将两个页合并以优化空间使用。
知识小贴士:
MERGE_THRESHOLD:合并页的阈值,可以自己设置,在创建表或者创建索引时指定。
主键的设计原则:
1、满足业务需求的情况下,尽量降低主键的长度。
2、插入数据时,尽量选择顺序插入,选择使用AUTO_INCREMENT自增主键
3、尽量不要使用UUID做主键或者是其他自然主键,如身份证号。
4、业务操作时,避免对主键的修改。
order by优化:
1、Using filesor:通过表的索引或全表扫描,读取满足条件的数据行,然后在排序缓冲区sortbufer中完成排序操作,所有不是通过索引直
接返回排序结果的排序都叫 FileSort 排序。
2、Using index:通过有序索引顺序扫描直接返回有序数据,这种情况即为using index,不需要额外排序,操作效率高。
#没有创建索引时,根据age,phone进行排序
explain select id,age,phone from tb_user order by age , phone,
#创建索引
create index idx_user_age_phone_aa on tb_user(age,phone),
#创建索引后,根据age,phone进行升序排序
explain select id,age,phone from tb_user order by age , phone,
#创建索引后,根据age,phone进行降序排序
explain select id,age,phone from tb_user order by age desc , phone desc ;
补充:
在创建索引时默认是升序的(从小到大)
但是也可以在创建是改变排序顺序:
create index idx_user_age_phone_ad on tb_user(age asc ,phone desc);
该方法创建的索引先通过年龄升序排序然后相同年龄的按手机号倒序排序。
总结:
根据排序字段建立合适的索引,多字段排序时,也遵循最左前缀法则。
尽量使用覆盖索引。
多字段排序,一个升序一个降序,此时需要注意联合索引在创建时的规则(ASC/DESC)>
如果不可避免的出现filesor,大数据量排序时,可以适当增大排序缓冲区大小sort_buffer_size(默认256k)。
如果超过排队缓冲区将会占用磁盘空间,会影响性能。
增加排队缓冲区
show variables like 'sort_buffer_size';//查看排队缓冲区大小
SET sort_buffer_size='2M';//设置排队缓冲区的大小为2M
group by优化:
#删除掉目前的联合索引
drop index idx_user pro_age_sta on tb_user;
#执行分组操作,根据profession字段分组
explain select profession , count(*) from tb_user group by profession;
#创建索引
create index idx_user_pro_age_sta on tb_user(profession,age,status);
#执行分组操作,根据profession字段分组
explain select profession, count(*) from tb_user group by profession ;
#执行分组操作,根据profession字段分组
explain select profession,count(*) from tb_user group by profession, age,
使用总结:
1、在分组操作时,可以通过索引来提高效率,
2、分组操作时,索引的使用也是满足最左前缀法则的。
limit分页 优化
一个常见又非常头疼的问题就是 limit 2000000,10,此时需要MYSQL排序前20000,10 记录,仅仅返回2000000-2000010
的记录,其他记录丢弃,查询排序的代价非常大。
优化方式:通过覆盖索引加子查询的方式
原SQL语句:缺点性能低 只需要查询10条数据其他数据进行丢弃,严重占用服务器的缓存、速度慢
select * from tb_sku limit 9000000,10;
优化后:
第一步:
select id from tb_sku order by id limit 9000000,10;//先查询需要的id, 并对其排序
最终sql
错误写法:原因-mysql不支持在in里面写limit
select * from tb_sku where id in (select id from th sku order by id limit 9000000,10);
正确写法:
select s.* from tb_sku s,(select id from tb sku order by id limit 9000000,10) a where s.id = a.id;
总结:
尽量避免使用大的偏移量,如limit 10000,10,因为这会导致MySQL扫描大量无用的行。
尽量结合where子句来过滤不需要的数据,以减少扫描的行数。
尽量使用有序的索引来避免文件排序,以提高查询效率。
count优化
MyISAM引擎把一个表的总行数存在了磁盘上,因此执行count()的时候会直接返回这个数,效率很高,前提是没有where条件;
InnoDB引擎就麻烦了,它执行 count()的时候,需要把数据一行一行地从引擎里面读出来,然后累积计数。
count的工作原理:
count()是一个聚合函数,对于返回的结果集一行行判断,如果count函数的参数不是 NULL,累计值就加1否则不加,最后返回累计值。
count的用法以及优化思路:
count(主键):
InnoD8 引擎会遍历整张表,把每一行的 主键id 值都取出来,返回给服务层。服务层拿到主键后,直接按行进行累加(主键不可能为null)
count(字段):
没有not null约束:InnoD8 引擎会遍历整张表把每一行的字段值都取出来,返回给服务层,服务层判断是否为null,不为nul,计数累加。
有not nul 约束:InnoD8 引擎会遍历整张表把每一行的字段值都取出来,返回给服务层,直接按行进行累加。
count(1):
InnoDB 引擎遍历整张表,但不取值。服务层对于返回的每一行,放一个数字“1”进去,直接按行进行累加。
count(*):
InnoDB引擎并不会把全部字段取出来,而是专门做了优化,不取值,服务层直接按行进行累加。
效率排序:
count(字段)<count(主键 id)<count(1)~ count(),所以尽量使用 count()。
update优化
mysql进阶-SQL优化篇的更多相关文章
- mysql的sql优化案例
前言 mysql的sql优化器比较弱,选择执行计划貌似很随机. 案例 一.表结构说明mysql> show create table table_order\G***************** ...
- 我的mysql数据库sql优化原则
原文 我的mysql数据库sql优化原则 一.前提 这里的原则 只是针对mysql数据库,其他的数据库 某些是殊途同归,某些还是存在差异.我总结的也是mysql普遍的规则,对于某些特殊情况得特殊对待. ...
- MySQL之SQL优化详解(二)
目录 MySQL之SQL优化详解(二) 1. SQL的执行顺序 1.1 手写顺序 1.2 机读顺序 2. 七种join 3. 索引 3.1 索引初探 3.2 索引分类 3.3 建与不建 4. 性能分析 ...
- 基于MySQL 的 SQL 优化总结
文章首发于我的个人博客,欢迎访问.https://blog.itzhouq.cn/mysql1 基于MySQL 的 SQL 优化总结 在数据库运维过程中,优化 SQL 是 DBA 团队的日常任务.例行 ...
- 【MySQL】SQL优化系列之 in与range 查询
首先我们来说下in()这种方式的查询 在<高性能MySQL>里面提及用in这种方式可以有效的替代一定的range查询,提升查询效率,因为在一条索引里面,range字段后面的部分是不生效的. ...
- mysql索引sql优化方法、步骤和经验
MySQL索引原理及慢查询优化 http://blog.jobbole.com/86594/ 细说mysql索引 https://www.cnblogs.com/chenshishuo/p/50300 ...
- (1.10)SQL优化——mysql 常见SQL优化
(1.10)常用SQL优化 insert优化.order by 优化 1.insert 优化 2.order by 优化 [2.1]mysql排序方式: (1)索引扫描排序:通过有序索引扫描直接返回有 ...
- MySQL之SQL优化详解(一)
目录 慢查询日志 1. 慢查询日志开启 2. 慢查询日志设置与查看 3.日志分析工具mysqldumpslow 序言: 在我面试很多人的过程中,很多人谈到SQL优化都头头是道,建索引,explai ...
- Mysql的SQL优化指北
概述 在一次和技术大佬的聊天中被问到,平时我是怎么做Mysql的优化的?在这个问题上我只回答出了几点,感觉回答的不够完美,所以我打算整理一次SQL的优化问题. 要知道怎么优化首先要知道一条SQL是怎么 ...
- BATJ解决千万级别数据之MySQL 的 SQL 优化大总结
引用 在数据库运维过程中,优化 SQL 是 DBA 团队的日常任务.例行 SQL 优化,不仅可以提高程序性能,还能减低线上故障的概率. 目前常用的 SQL 优化方式包括但不限于:业务层优化.SQL 逻 ...
随机推荐
- 使用Aspire优雅的进行全栈开发——WinUI使用Semantic Kernel调用智普清言LLM总结Asp.Net Core通过Playwright解析的网页内容
前言 这算是一篇学习记录博客了,主要是学习语义内核(Semantic Kernel)的实践,以及Aspire进行全栈开发的上手体验,我是采用Aspire同时启动API服务,Blazor前端服务以及Wi ...
- java多线程之-线程池状态
1.背景 这一节我们来学习一下线程池状态..... 2.线程池状态 状态名称 高3位 是否接受新任务 是否处理队列中的任务 说明 RUNNING 111 是 是 线程池正常运行状态 SHUTDOWN ...
- Ruoyi-Cloud 启动失败的坑,关于 selectConfigList
刚才编辑了一堆,不知道为啥加了个英文单词,当前页面刷新自动搜索了单词,之前的内容总的就是现在都要会SpringCloud,高并发,几个真正懂高并发的,问题一般项目也没有啥高并发.自己之前的项目遇到过高 ...
- Spring AI 更新:支持OpenAI的结构化输出,增强对JSON响应的支持
就在昨晚,Spring AI发了个比较重要的更新.由于最近OpenAI推出了结构化输出的功能,可确保 AI 生成的响应严格遵守预定义的 JSON 模式.此功能显着提高了人工智能生成内容在现实应用中的可 ...
- 轻松易懂,一文告诉你什么是http协议?
阅读本文之前,请详细阅读以下几篇文章: <一文包你学会网络数据抓包> <教你如何抓取网络中的数据包!黑客必备技能> 一.什么是http? Http协议即超文本传送协议 (HTT ...
- 解锁强强组合: 使用 Kafka + ClickHouse 快速搭建流数据实时处理平台(DoubleCloud 博客)
我们想要解决的问题 让我们深入一个现实场景: 设想你负责汇总多个销售点系统产生的大量数据.这些数据需要被实时处理并在高级分析仪表板上展示,以提供全面的洞察. 在数据处理领域,速度至关重要.ClickH ...
- OpenPCDet复现过程记录
0.前言 OpenPCDet项目之前我就复现过,一个很优秀的项目,这几天又需要用到这个项目,再次复现遇到了不少问题,特此记录复现的流程 1.环境准备 1.1.前置条件 以下是我安装的版本 CUDA 1 ...
- layui表格中格式化日期
layui表格中格式化日期 //1.引入 util layui.use(['table', 'admin'], function () { var util = layui.util; //2.表格内 ...
- RedisTemplate常用方法
RedisTemplate常用方法 一.Redis常用的数据类型: String Hash List Set zSet Sorted set 二.RedisTemplate 常用 API 1. Str ...
- String真的不可变吗?
Java中的String是不可变对象 在面向对象及函数编程语言中,不可变对象(英语:Immutable object)是一种对象,在被创造之后,它的状态就不可以被改变.至于状态可以被改变的对象,则被称 ...