mysql进阶-SQL优化篇
SQL优化
-插入数据
批量插入:(一次尽量不超过1000条)
Insert into tb test values(1,'Tom'),(2,'cat'),(3, Jerny');
手动事务提交:
start transaction;
insert into tb_test values(1,'Tom'"),(2,'Cat'),(3, jerry');
insert into tb test values(4,'Tom'),(5,'Cat'),(6, jerry');
insert into tb test values(7,"Tom'),(8,'Cat'),(9,jerry');
commit;
主键顺序插入:
取决于mysql数据组织结构(后面会将主键优化),将插入主键按从小到大进行排列。
大批量数据插入:
如果一次性需要插入大批量数据,使用insert语句插入性能较低,此时可以使用MYSQL数据库提供的load指令进行插入。操作如下。
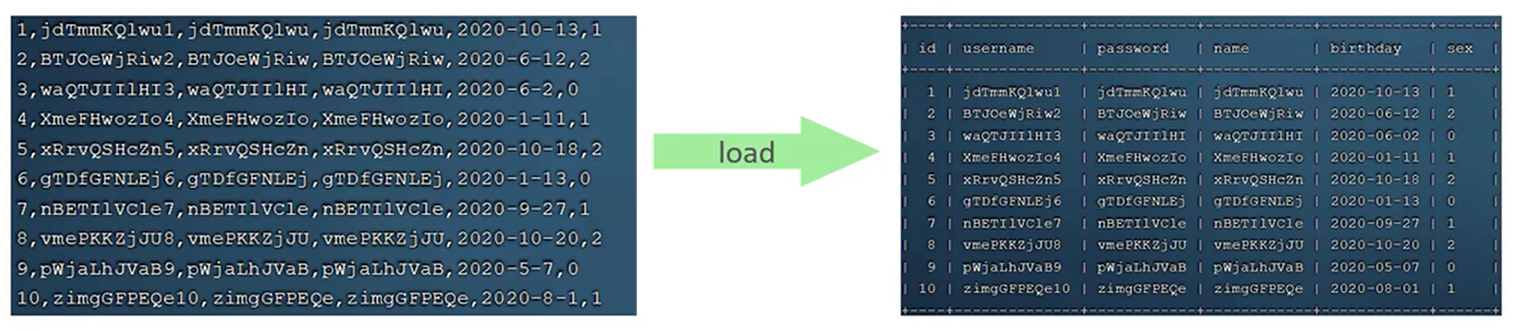
#客户端连接服务端时,加上参数--local-infile
mysql --local-infile -u root -p
#设置全局参数local infile为1,开启从本地加载文件导入数据的开关
select @@local infile;//查看是否开启0否1是
set global local infile =1;
#执行load指令将准备好的数据,加载到表结构中以","隔开字段。每一行通过"\n"分割
load data local infile '/root/sql1.log' into table `tb_user` fields terminated by ',' lines terminated by '\n';
注意:
load插入时最好也按照主键顺序插入,顺序插入性能会高于乱序插入。(为什么请看主键优化)
- 主键优化
在InnoDB存储引擎中,表数据都是根据主键顺序组织存放的,这种存储方式的表称为索引组织表(index organized table IOT)
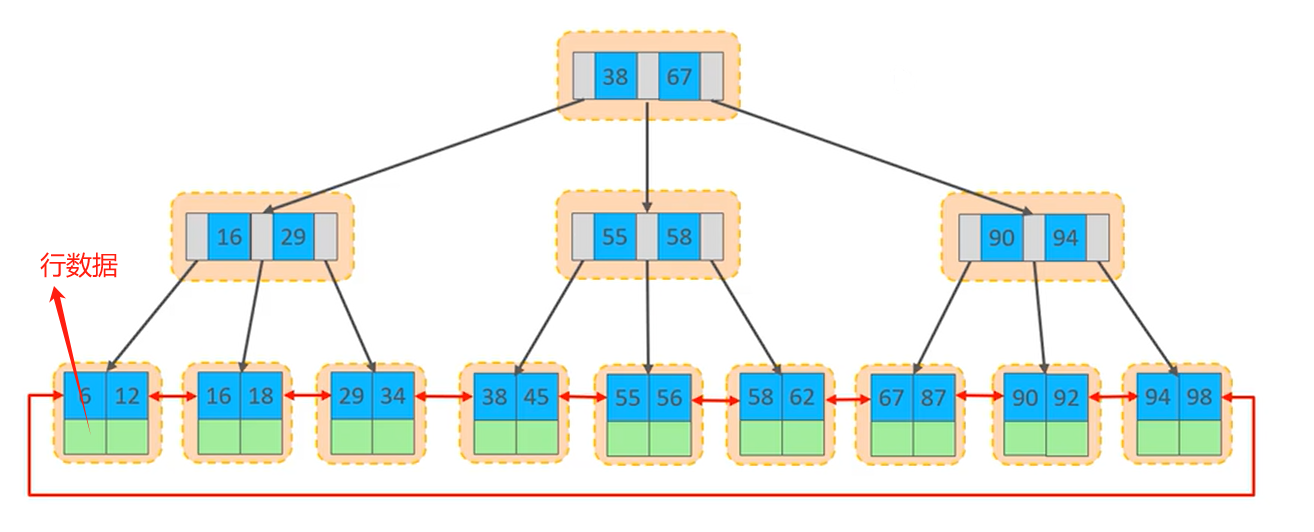
页可以为空也可以填充一半,也可以填充100%。每个页包含了2-N行数据(如果一行数据多大,会行溢出),根据主键排列。
主键顺序插入示意图:

页分裂:
若主键乱序插入因xxxx可能会造成页分裂
页合并:
当删除一行记录时,实际上记录并没有被物理删除,只是记录被标记(flaged)为删除并且它的空间变得允许被其他记录声明使用。
当页中删除的记录达到 MERGE_THRESHOLD(默认为页的50%),InnoDB会开始寻找最靠近的页(前或后)看看是否可以将两个页合并以优化空间使用。
知识小贴士:
MERGE_THRESHOLD:合并页的阈值,可以自己设置,在创建表或者创建索引时指定。
主键的设计原则:
1、满足业务需求的情况下,尽量降低主键的长度。
2、插入数据时,尽量选择顺序插入,选择使用AUTO_INCREMENT自增主键
3、尽量不要使用UUID做主键或者是其他自然主键,如身份证号。
4、业务操作时,避免对主键的修改。
order by优化:
1、Using filesor:通过表的索引或全表扫描,读取满足条件的数据行,然后在排序缓冲区sortbufer中完成排序操作,所有不是通过索引直
接返回排序结果的排序都叫 FileSort 排序。
2、Using index:通过有序索引顺序扫描直接返回有序数据,这种情况即为using index,不需要额外排序,操作效率高。
#没有创建索引时,根据age,phone进行排序
explain select id,age,phone from tb_user order by age , phone,
#创建索引
create index idx_user_age_phone_aa on tb_user(age,phone),
#创建索引后,根据age,phone进行升序排序
explain select id,age,phone from tb_user order by age , phone,
#创建索引后,根据age,phone进行降序排序
explain select id,age,phone from tb_user order by age desc , phone desc ;
补充:
在创建索引时默认是升序的(从小到大)
但是也可以在创建是改变排序顺序:
create index idx_user_age_phone_ad on tb_user(age asc ,phone desc);
该方法创建的索引先通过年龄升序排序然后相同年龄的按手机号倒序排序。
总结:
根据排序字段建立合适的索引,多字段排序时,也遵循最左前缀法则。
尽量使用覆盖索引。
多字段排序,一个升序一个降序,此时需要注意联合索引在创建时的规则(ASC/DESC)>
如果不可避免的出现filesor,大数据量排序时,可以适当增大排序缓冲区大小sort_buffer_size(默认256k)。
如果超过排队缓冲区将会占用磁盘空间,会影响性能。
增加排队缓冲区
show variables like 'sort_buffer_size';//查看排队缓冲区大小
SET sort_buffer_size='2M';//设置排队缓冲区的大小为2M
group by优化:
#删除掉目前的联合索引
drop index idx_user pro_age_sta on tb_user;
#执行分组操作,根据profession字段分组
explain select profession , count(*) from tb_user group by profession;
#创建索引
create index idx_user_pro_age_sta on tb_user(profession,age,status);
#执行分组操作,根据profession字段分组
explain select profession, count(*) from tb_user group by profession ;
#执行分组操作,根据profession字段分组
explain select profession,count(*) from tb_user group by profession, age,
使用总结:
1、在分组操作时,可以通过索引来提高效率,
2、分组操作时,索引的使用也是满足最左前缀法则的。
limit分页 优化
一个常见又非常头疼的问题就是 limit 2000000,10,此时需要MYSQL排序前20000,10 记录,仅仅返回2000000-2000010
的记录,其他记录丢弃,查询排序的代价非常大。
优化方式:通过覆盖索引加子查询的方式
原SQL语句:缺点性能低 只需要查询10条数据其他数据进行丢弃,严重占用服务器的缓存、速度慢
select * from tb_sku limit 9000000,10;
优化后:
第一步:
select id from tb_sku order by id limit 9000000,10;//先查询需要的id, 并对其排序
最终sql
错误写法:原因-mysql不支持在in里面写limit
select * from tb_sku where id in (select id from th sku order by id limit 9000000,10);
正确写法:
select s.* from tb_sku s,(select id from tb sku order by id limit 9000000,10) a where s.id = a.id;
总结:
尽量避免使用大的偏移量,如limit 10000,10,因为这会导致MySQL扫描大量无用的行。
尽量结合where子句来过滤不需要的数据,以减少扫描的行数。
尽量使用有序的索引来避免文件排序,以提高查询效率。
count优化
MyISAM引擎把一个表的总行数存在了磁盘上,因此执行count()的时候会直接返回这个数,效率很高,前提是没有where条件;
InnoDB引擎就麻烦了,它执行 count()的时候,需要把数据一行一行地从引擎里面读出来,然后累积计数。
count的工作原理:
count()是一个聚合函数,对于返回的结果集一行行判断,如果count函数的参数不是 NULL,累计值就加1否则不加,最后返回累计值。
count的用法以及优化思路:
count(主键):
InnoD8 引擎会遍历整张表,把每一行的 主键id 值都取出来,返回给服务层。服务层拿到主键后,直接按行进行累加(主键不可能为null)
count(字段):
没有not null约束:InnoD8 引擎会遍历整张表把每一行的字段值都取出来,返回给服务层,服务层判断是否为null,不为nul,计数累加。
有not nul 约束:InnoD8 引擎会遍历整张表把每一行的字段值都取出来,返回给服务层,直接按行进行累加。
count(1):
InnoDB 引擎遍历整张表,但不取值。服务层对于返回的每一行,放一个数字“1”进去,直接按行进行累加。
count(*):
InnoDB引擎并不会把全部字段取出来,而是专门做了优化,不取值,服务层直接按行进行累加。
效率排序:
count(字段)<count(主键 id)<count(1)~ count(),所以尽量使用 count()。
update优化
mysql进阶-SQL优化篇的更多相关文章
- mysql的sql优化案例
前言 mysql的sql优化器比较弱,选择执行计划貌似很随机. 案例 一.表结构说明mysql> show create table table_order\G***************** ...
- 我的mysql数据库sql优化原则
原文 我的mysql数据库sql优化原则 一.前提 这里的原则 只是针对mysql数据库,其他的数据库 某些是殊途同归,某些还是存在差异.我总结的也是mysql普遍的规则,对于某些特殊情况得特殊对待. ...
- MySQL之SQL优化详解(二)
目录 MySQL之SQL优化详解(二) 1. SQL的执行顺序 1.1 手写顺序 1.2 机读顺序 2. 七种join 3. 索引 3.1 索引初探 3.2 索引分类 3.3 建与不建 4. 性能分析 ...
- 基于MySQL 的 SQL 优化总结
文章首发于我的个人博客,欢迎访问.https://blog.itzhouq.cn/mysql1 基于MySQL 的 SQL 优化总结 在数据库运维过程中,优化 SQL 是 DBA 团队的日常任务.例行 ...
- 【MySQL】SQL优化系列之 in与range 查询
首先我们来说下in()这种方式的查询 在<高性能MySQL>里面提及用in这种方式可以有效的替代一定的range查询,提升查询效率,因为在一条索引里面,range字段后面的部分是不生效的. ...
- mysql索引sql优化方法、步骤和经验
MySQL索引原理及慢查询优化 http://blog.jobbole.com/86594/ 细说mysql索引 https://www.cnblogs.com/chenshishuo/p/50300 ...
- (1.10)SQL优化——mysql 常见SQL优化
(1.10)常用SQL优化 insert优化.order by 优化 1.insert 优化 2.order by 优化 [2.1]mysql排序方式: (1)索引扫描排序:通过有序索引扫描直接返回有 ...
- MySQL之SQL优化详解(一)
目录 慢查询日志 1. 慢查询日志开启 2. 慢查询日志设置与查看 3.日志分析工具mysqldumpslow 序言: 在我面试很多人的过程中,很多人谈到SQL优化都头头是道,建索引,explai ...
- Mysql的SQL优化指北
概述 在一次和技术大佬的聊天中被问到,平时我是怎么做Mysql的优化的?在这个问题上我只回答出了几点,感觉回答的不够完美,所以我打算整理一次SQL的优化问题. 要知道怎么优化首先要知道一条SQL是怎么 ...
- BATJ解决千万级别数据之MySQL 的 SQL 优化大总结
引用 在数据库运维过程中,优化 SQL 是 DBA 团队的日常任务.例行 SQL 优化,不仅可以提高程序性能,还能减低线上故障的概率. 目前常用的 SQL 优化方式包括但不限于:业务层优化.SQL 逻 ...
随机推荐
- [COCI 2023/2024 #3] Slučajna Cesta 题解
前言 期望套期望,很有意思.来一发考场首 A,近 \(\Theta(n)\) 的算法. 题目链接:洛谷. 题意简述 一棵树,每条边随机设有方向.对于所有 \(i\),从 \(i\) 开始随机游走,直到 ...
- [COCI2021-2022#6] Naboj 题解
前言 题目链接:洛谷. 题意简述 给定一张无向图,每条边有个哨兵,初始在边的中间.你可以把某个结点旁边的哨兵全部吸引或远离这个结点.给出最后每个哨兵在边的哪一端,请构造出一种可能的操作方案或报告无解. ...
- manim边学边做--点
几何图形是manim中最重要的一类模块,manim内置了丰富的各类几何图形,本篇从最简单的点开始,逐个介绍manim中的几何模块. manim中点相关的模块主要有3个: Dot:通用的点 Labele ...
- Java数组小白版
一.数组概念 一.数组定义 数组就是指在计算机内存中开辟的连续存储空间,用于存放程序运行中需要用到的一组相同类型数据的容器. 二.数组的声明 +数组的长度 定义数组时需要确定数组的长度(元素的个数), ...
- 痞子衡嵌入式:探析i.MXRT1050在GPIO上增加RC延时电路后导致边沿中断误触发问题(上篇)
大家好,我是痞子衡,是正经搞技术的痞子.今天痞子衡给大家分享的是i.MXRT1050在GPIO上增加RC延时电路后导致边沿中断误触发问题探析. 前段时间有一个 RT1052 客户反馈了一个有趣的问题, ...
- 【CMake系列】05-静态库与动态库编译
在各种项目类型中,可能我们的项目就是一个 库 项目,向其他人提供 我们开发好的 库 (windows下的 dll /lib : linux下的 .a / .so):有时候在一个项目中,我们对部分功能 ...
- HLK-RM60 + openwrt调试
1. 简介 HLK-RM60官网 https://www.hlktech.com/en/Goods-176.html 采用联发科SOC, MT7621/MT7905/MT7975 实际上采购的是MT7 ...
- AI图像放大工具,图片放大无所不能
AI图像放大工具,如ESRGAN,对于提高由Stable Diffusion生成的AI图像质量至关重要.它们被广泛使用,以至于许多Stable Diffusion的图形用户界面(GUI)都内置了支持. ...
- 补: Rest 风格请求处理的的内容补充(1)
补: Rest 风格请求处理的的内容补充(1) Rest风格请求:注意事项和细节 客户端是PostMan 可以直接发送Put,delete等方式请求,可不设置Filter 如果哟啊SpringBoot ...
- 终于有人把Modbus讲明白了
大家好!我是付工. 2012年开始接触Modbus协议,至今已经有10多年了,从开始的懵懂,到后来的顿悟,再到现在的开悟,它始终岿然不动,变化的是我对它的认知和理解. 今天跟大家聊聊关于Modbus协 ...