超详细的mysql总结(DQL)
CREATE TABLE IF NOT EXISTS `products` (
id INT PRIMARY KEY AUTO_INCREMENT,
brand VARCHAR(20),
title VARCHAR(100) NOT NULL,
price DOUBLE NOT NULL,
score DECIMAL(2,1),
voteCnt INT,
url VARCHAR(100),
pid INT
)
// 省略 insert into 插入数据部分
首先来查看一下表中的所有数据
SELECT * FROM `products`; // * 代表展示所有的字段,如果只展示部分字段可以指定,可通过as对字段取别名,as可省略
SELECT id, brand as phoneBrand, title phoneTitle, price, score FROM `products`;
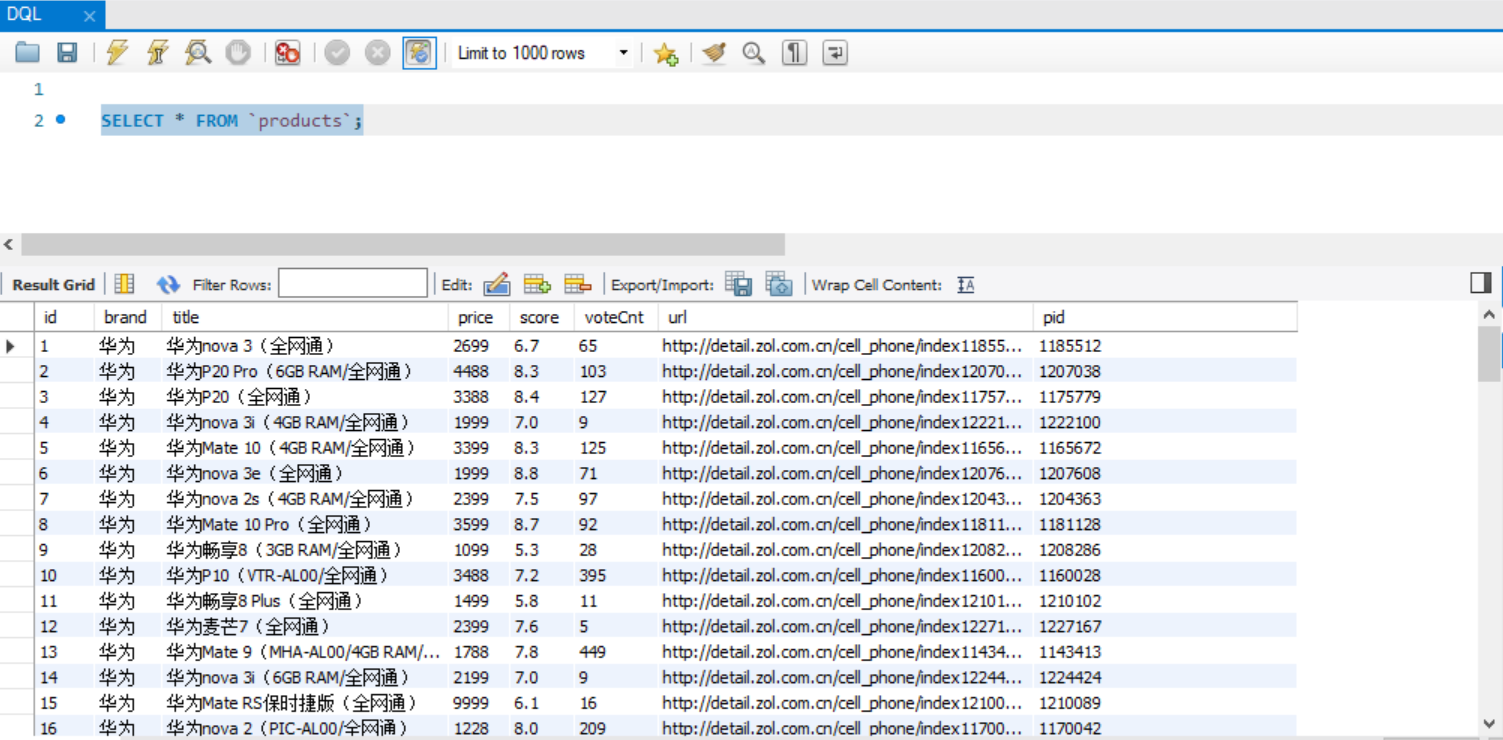
SELECT id, brand as phoneBrand, title phoneTitle, price, score From `products` WHERE brand = '华为'; // where后可以跟多个条件,用 AND() 或者 OR 来进行连接
SELECT * From `products` WHERE brand = '华为' && price > 4000; // 查询价格大于4000的华为手机
SELECT * From `products` WHERE score BETWEEN 5 AND 6; // 查询手机评分在5-6分之间的手机,包含5和6分 SELECT * FROM `products` WHERE brand LIKE '%v%'; // 匹配品牌名称包含字母为V的数据
SELECT * FROM `products` WHERE brand LIKE '_v%'; // 匹配品牌名称包含第二个字母为V的数据
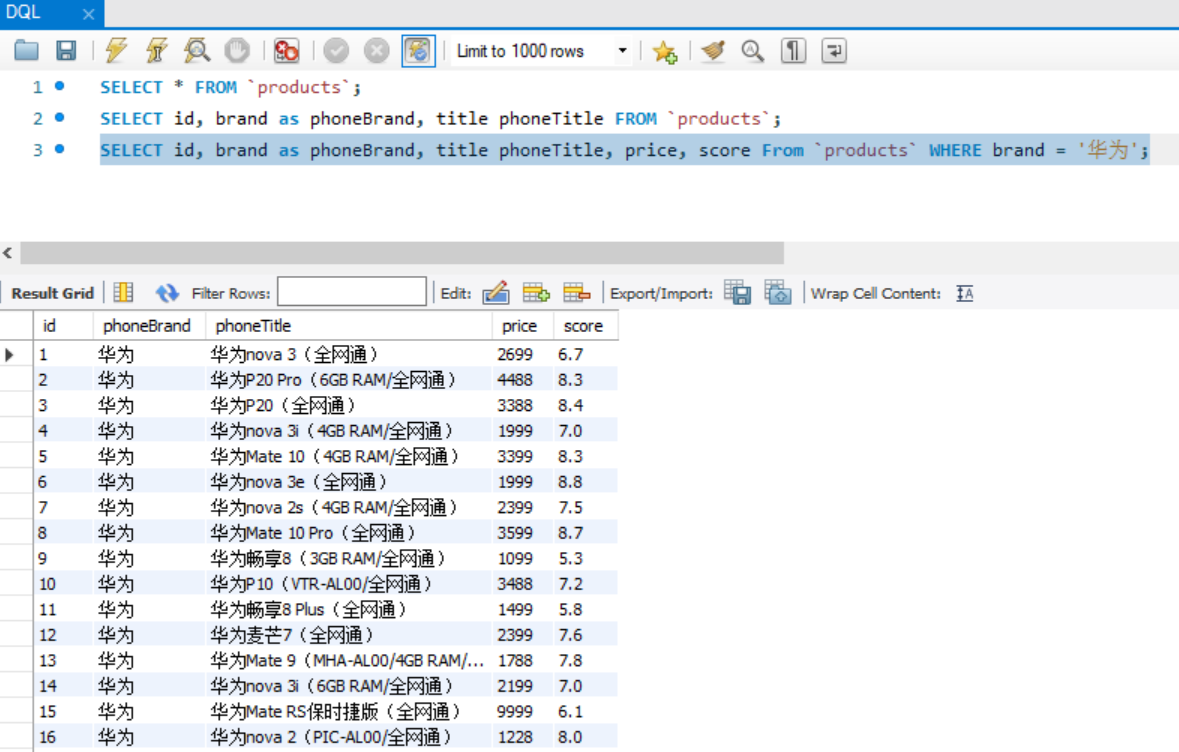
SELECT id, brand as phoneBrand, title phoneTitle, price, score From `products` WHERE brand = '华为' ORDER BY price DESC;
// DESC 代表降序, ASC 代表升序 // 通过price降序排列的时候,相同价格的产品,再对评分倒序排列
SELECT id, brand as phoneBrand, title phoneTitle, price, score From `products` WHERE brand = '华为' ORDER BY price DESC, score DESC;
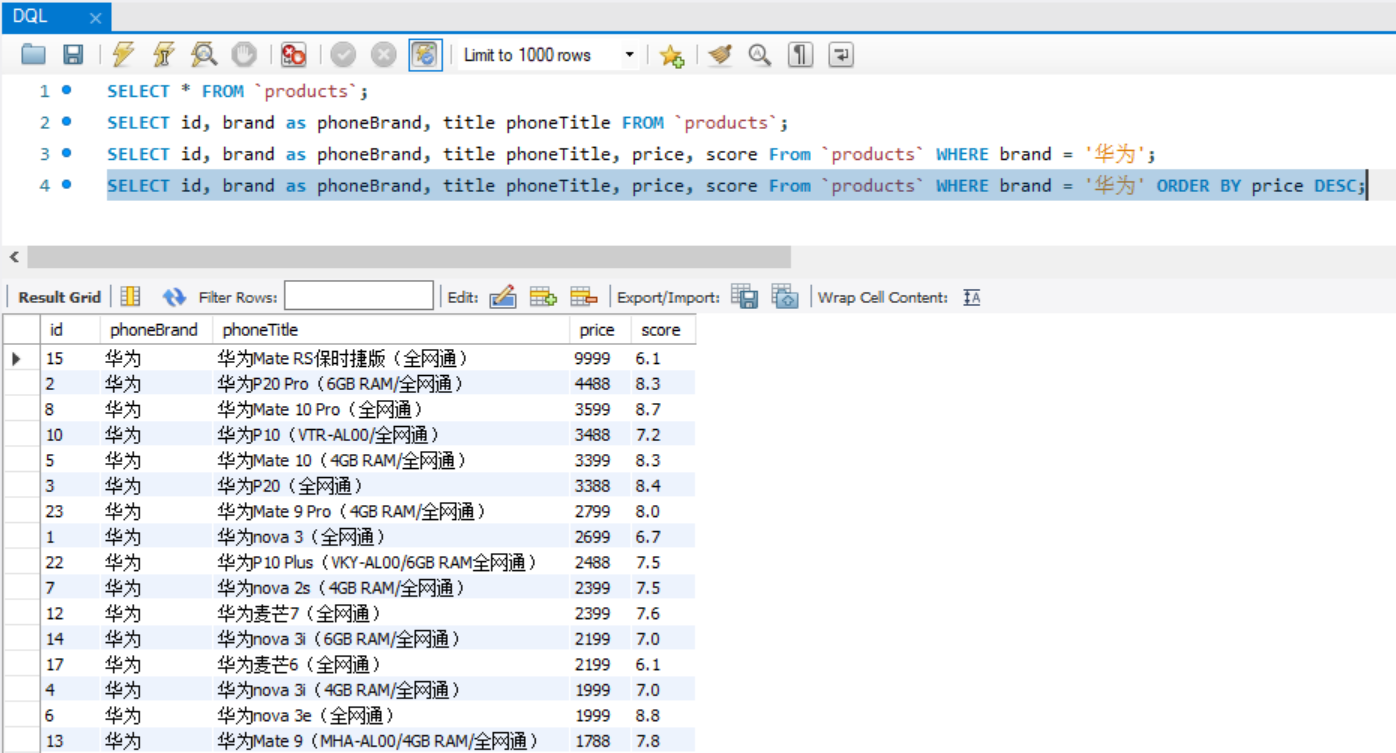
SELECT * FROM `products` LIMIT 10 OFFSET 40;
// LIMIT 10 OFFSET 40 代表偏移40条数据,往后取10条数据
// LIMIT 10, 40 代表偏移10条数据,往后取40条数据
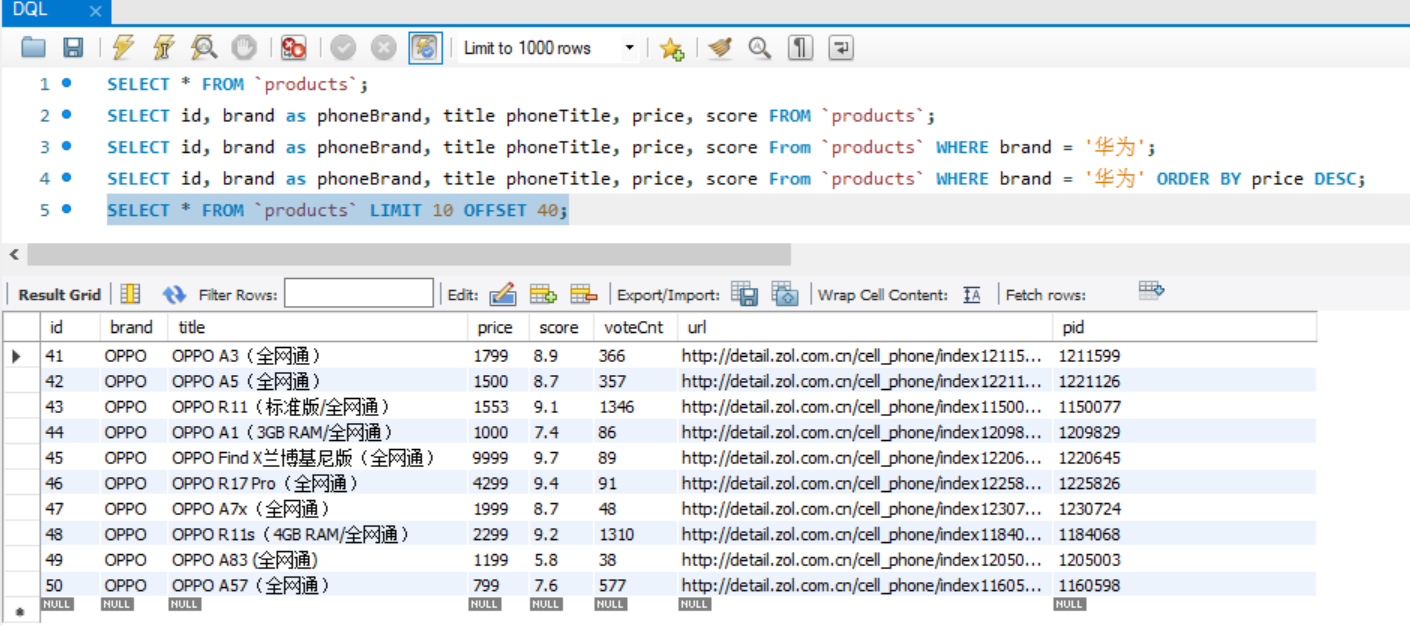
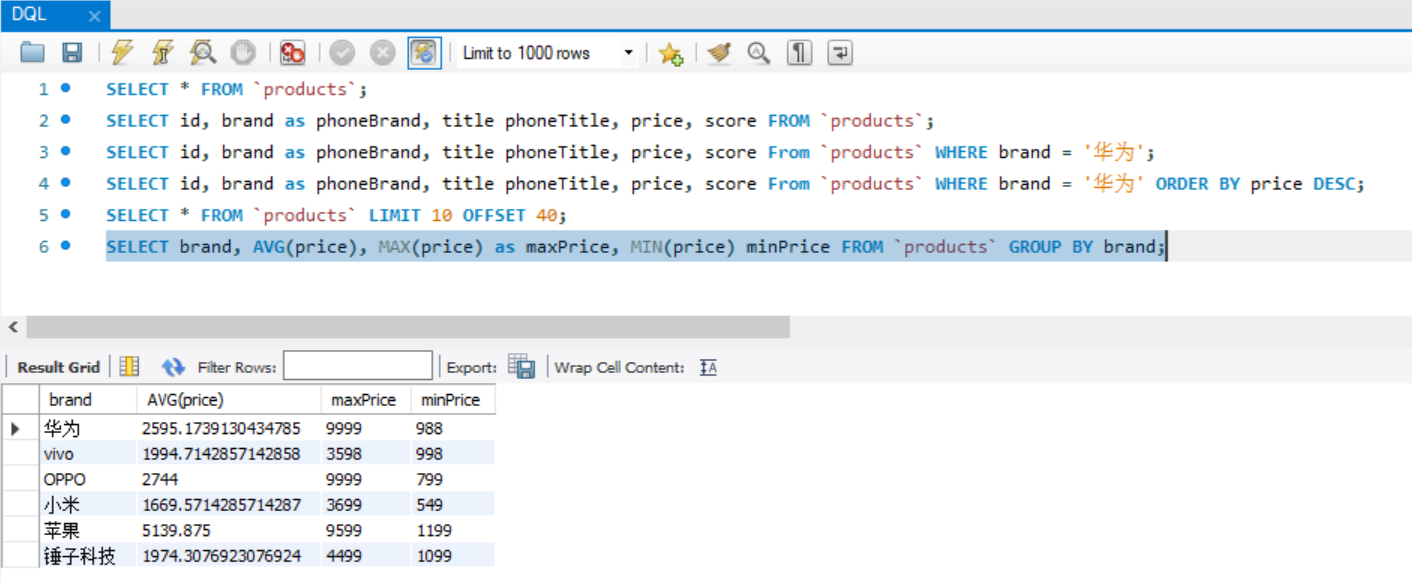
SELECT brand, AVG(price), MAX(price) as maxPrice, MIN(price) minPrice FROM `products` GROUP BY brand;
// 同样可以取别名,不取别名时展示的就是查询语句的字段名称
// 在统计出所有品牌的平均值、最大值、最小值后,只想取出价格范围在1000-5000之间的品牌
SELECT brand, AVG(price), MAX(price) as maxPrice, MIN(price) minPrice FROM `products` GROUP BY brand
HAVING maxPrice < 5000 && minPrice > 1000;
// 计算投票总数 SUM(voteCount)
// 计算所有的价格类别,去重 COUNT(DISTINCT price)
SELECT select_expr [, select_expr]...
[FROM table_references]
[WHERE where_condition]
[ORDER BY expr [ASC | DESC]]
[LIMIT {[offset,] row_count | row_count OFFSET offset}]
[GROUP BY expr] [HAVING where_condition]
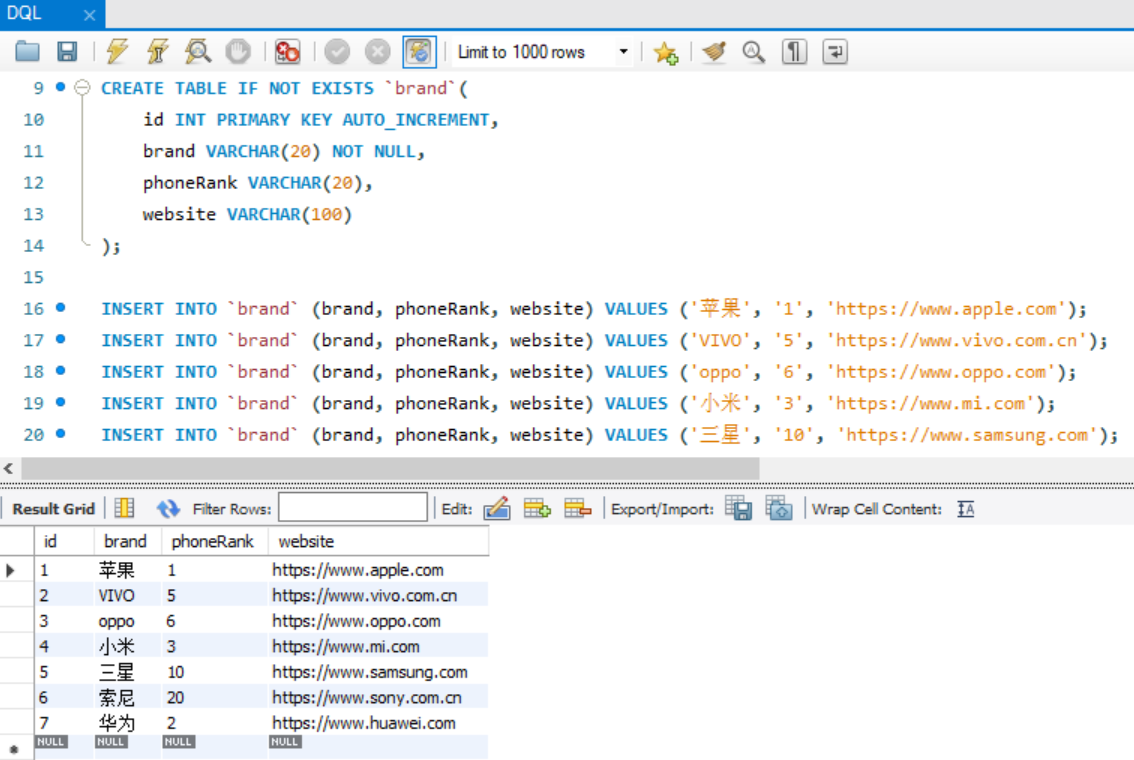
上面都是针对于一张表格来进行查询,但我们仔细观察,发现表格中的同一品牌手机的 brand 字段都是一致的,如果针对不同的品牌,要增加描述信息、官网等,那么需要在每一条数据中都重复添加,这样表格数据有大量冗余,可以考虑另建一张品牌表,放置品牌数据,这样就只用在商品表中存放品牌id,通过外键将商品和品牌关联上。
// 创建商品表
CREATE TABLE IF NOT EXISTS `brand`(
id INT PRIMARY KEY AUTO_INCREMENT,
brand VARCHAR(20) NOT NULL,
phoneRank VARCHAR(20),
website VARCHAR(100)
);
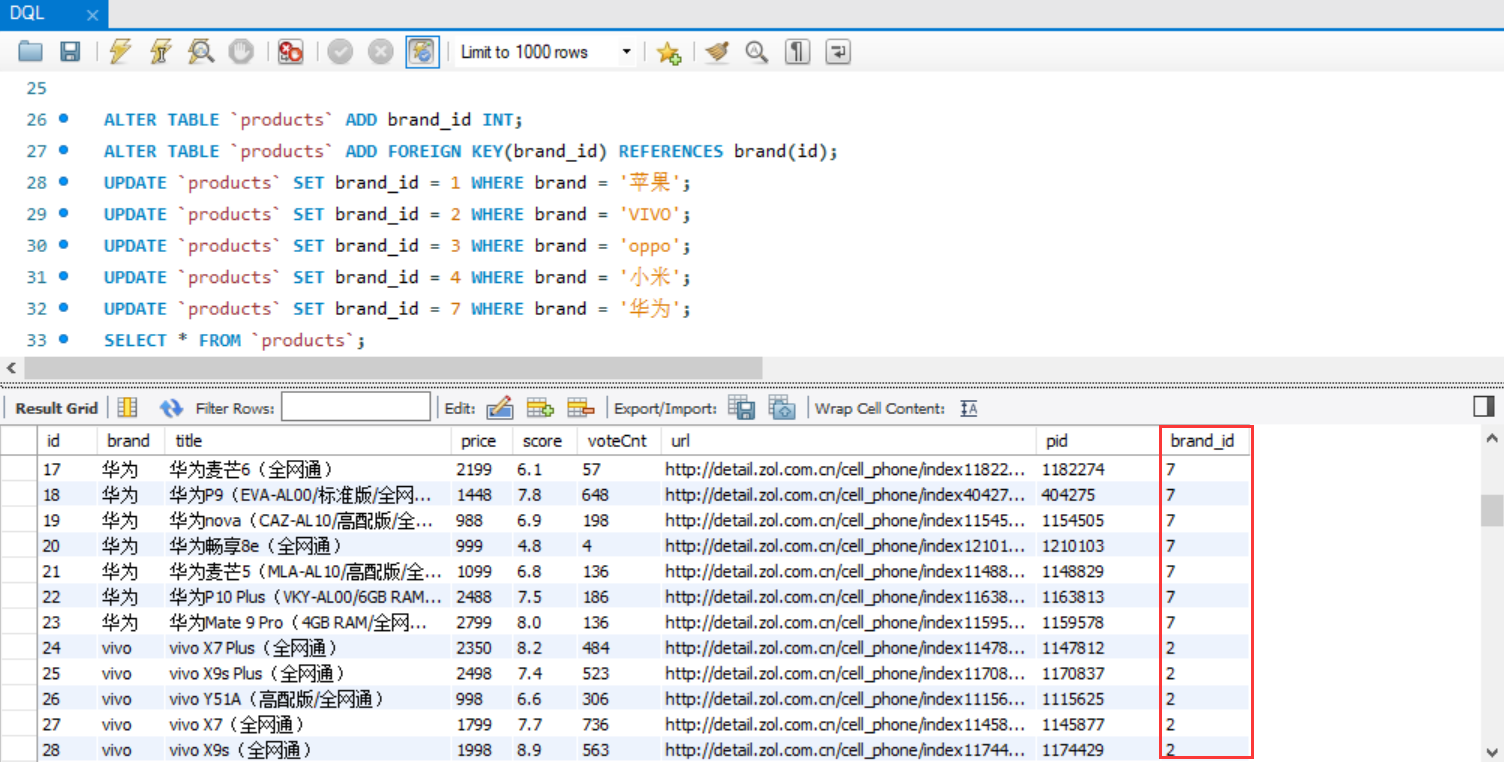
ALTER TABLE `products` ADD brand_id INT;
ALTER TABLE `products` ADD FOREIGN KEY(brand_id) REFERENCES brand(id);
UPDATE `products` SET brand_id = 1 WHERE brand = '苹果';
UPDATE `products` SET brand_id = 2 WHERE brand = 'VIVO';
UPDATE `products` SET brand_id = 3 WHERE brand = 'oppo';
UPDATE `products` SET brand_id = 4 WHERE brand = '小米';
UPDATE `products` SET brand_id = 7 WHERE brand = '华为';
SELECT * FROM `products`;
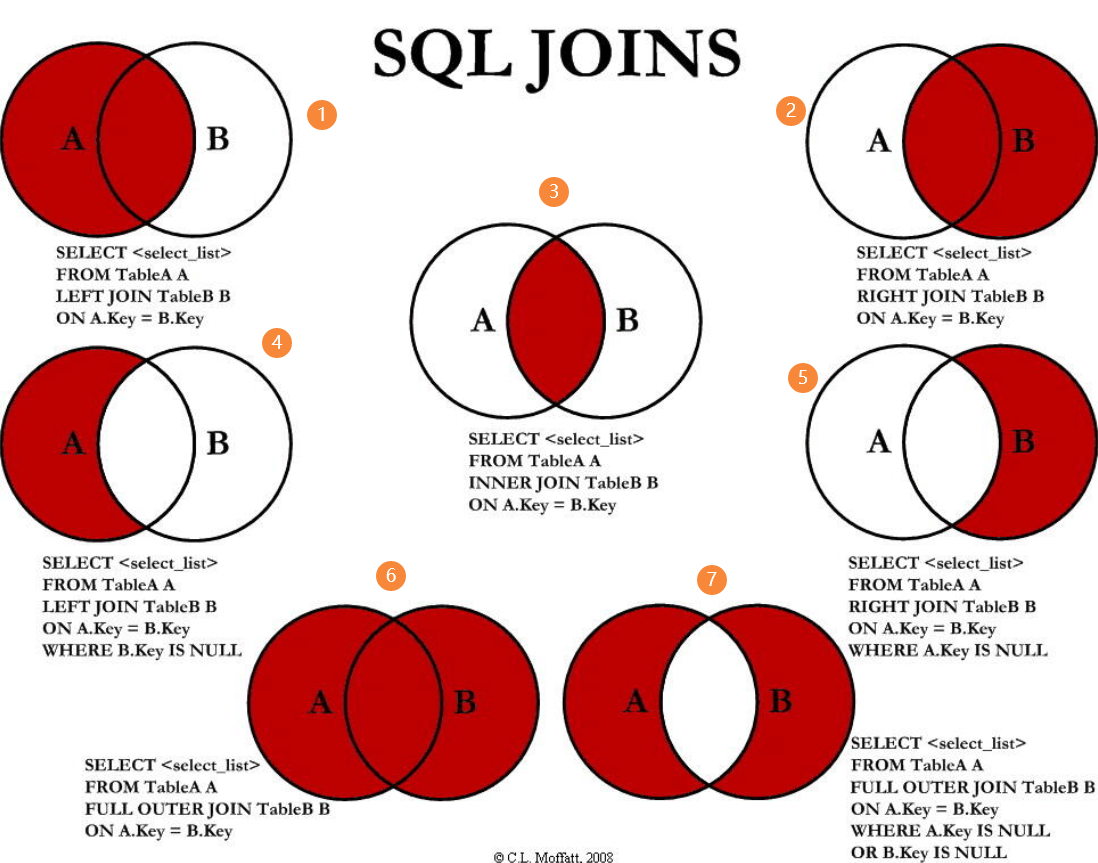
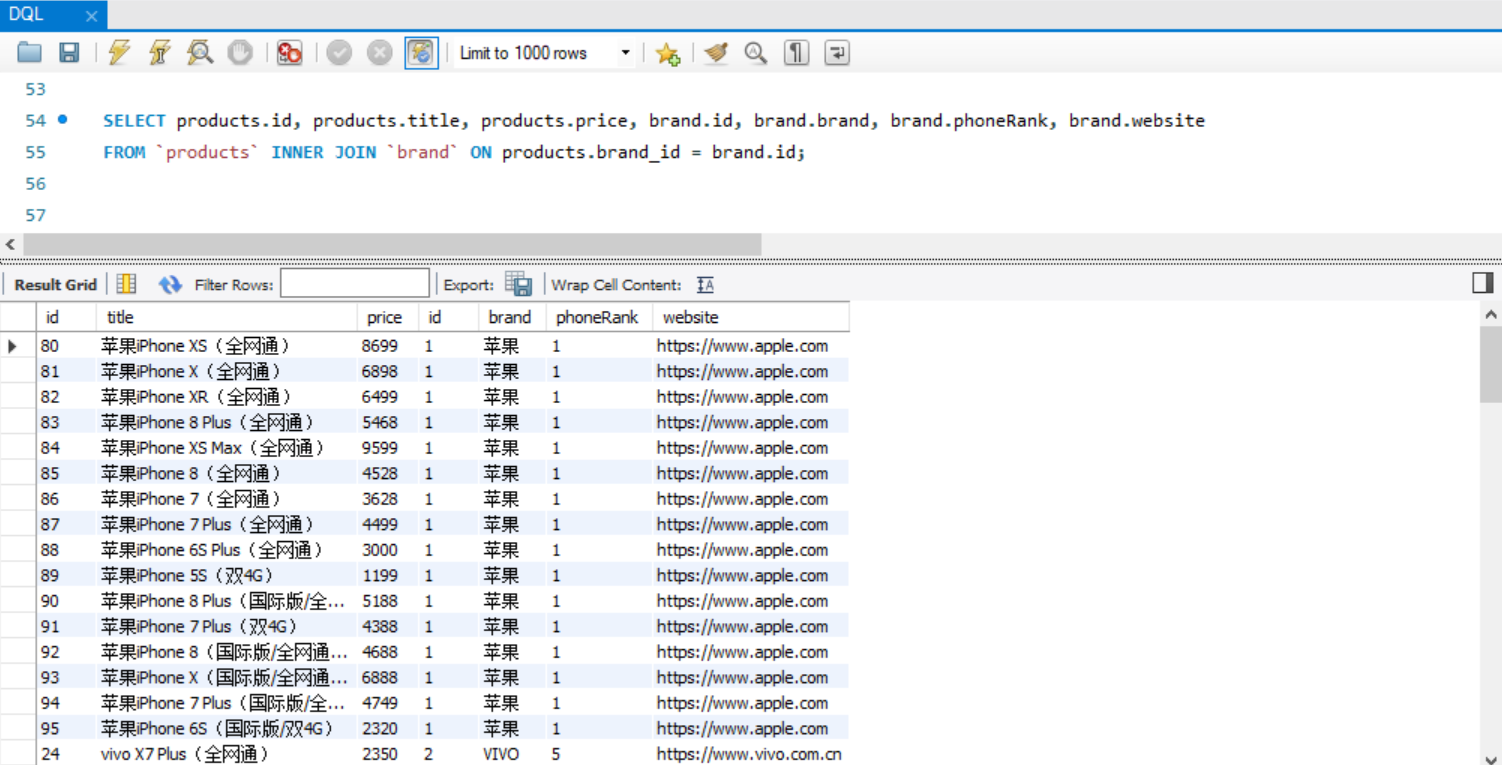
// 左连接,展示所有的商品,无论商品的品牌不在品牌表中,对应上图①
SELECT products.id, products.title, products.price, brand.id, brand.brand, brand.phoneRank, brand.website
FROM `products` LEFT JOIN `brand` ON products.brand_id = brand.id; // 内连接,展示所有有brand_id的商品,对应上图 ③
SELECT products.id, products.title, products.price, brand.id, brand.brand, brand.phoneRank, brand.website
FROM `products` INNER JOIN `brand` ON products.brand_id = brand.id; // 右连接,展示所有的品牌,无论是否存在该品牌的商品,对应上图⑤
SELECT products.id, products.title, products.price, brand.id, brand.brand, brand.phoneRank, brand.website
FROM `products` RIGHT JOIN `brand` ON products.brand_id = brand.id WHERE products.brand_id IS NULL; // 外连接,展示所有商品和所有的品牌,对应上图 ⑥
(SELECT products.id, products.title, products.price, brand.id, brand.brand, brand.phoneRank, brand.website
FROM `products` LEFT JOIN `brand` ON products.brand_id = brand.id)
UNION
(SELECT products.id, products.title, products.price, brand.id, brand.brand, brand.phoneRank, brand.website
FROM `products` RIGHT JOIN `brand` ON products.brand_id = brand.id)
// 学生表
CREATE TABLE IF NOT EXISTS `students`(
id INT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(20) NOT NULL, age INT
);
// 课程表
CREATE TABLE IF NOT EXISTS `courses`(
id INT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(20) NOT NULL,
price DOUBLE NOT NULL
);
// 学生选课关系表,设置联合主键,保证学生不会重复选课
CREATE TABLE IF NOT EXISTS `students_select_courses`(
student_id INT NOT NULL,
courses_id INT NOT NULL,
FOREIGN KEY(student_id) REFERENCES students(id) ON UPDATE CASCADE,
FOREIGN KEY(courses_id) REFERENCES courses(id) ON UPDATE CASCADE,
PRIMARY KEY(student_id, courses_id)
);
创建三张表,并添加数据后,通过 左连接、右连接、内连接等方式组合在一起查询出所需要的数据
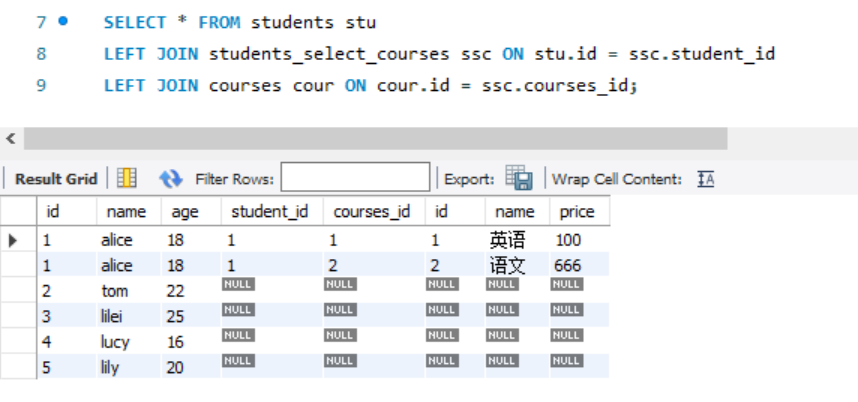
// 左连接,查询所有的学生选课情况
SELECT * FROM students stu
LEFT JOIN students_select_courses ssc ON stu.id = ssc.student_id
LEFT JOIN courses cour ON cour.id = ssc.courses_id; // 查询所有选课的学生情况
SELECT stu.name stuName, stu.age, cour.name courseName, cour.price courPrice
FROM students stu
LEFT JOIN students_select_courses ssc ON stu.id = ssc.student_id
LEFT JOIN courses cour ON cour.id = ssc.courses_id
WHERE ssc.courses_id IS NOT NULL; // 哪些课程没有被选择
SELECT stu.name stuName, stu.age, cour.name courseName, cour.price courPrice
FROM students stu
LEFT JOIN students_select_courses ssc ON stu.id = ssc.student_id
RIGHT JOIN courses cour ON cour.id = ssc.courses_id
WHERE stu.id IS NULL;
// 组装成对象
SELECT products.id as id, products.title as title,
products.price as price, products.score as score,
JSON_OBJECT('id', brand.id, 'name', brand.brand, 'rank', brand.phoneRank,
'website', brand.website) as brand FROM products
LEFT JOIN brand ON products.brand_id = brand.id; // 数据组装成数组对象
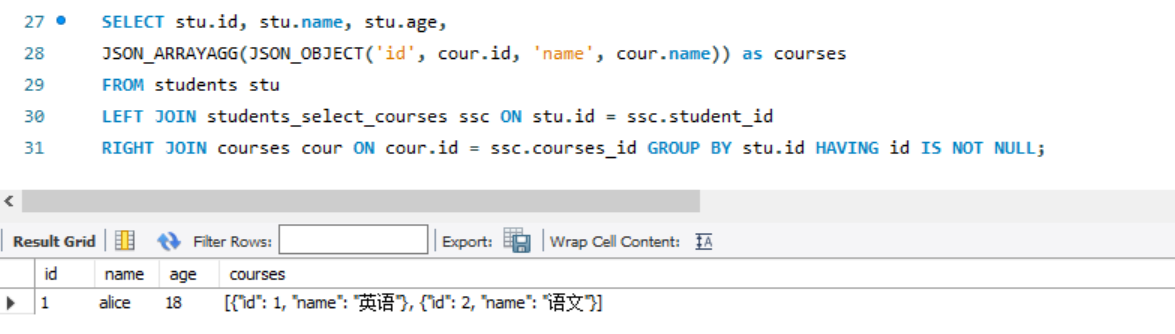
SELECT stu.id, stu.name, stu.age,
JSON_ARRAYAGG(JSON_OBJECT('id', cour.id, 'name', cour.name)) as courses
FROM students stu
LEFT JOIN students_select_courses ssc ON stu.id = ssc.student_id
RIGHT JOIN courses cour ON cour.id = ssc.courses_id GROUP BY stu.id HAVING id IS NOT NULL;
超详细的mysql总结(DQL)的更多相关文章
- 超详细讲解mysql存储过程中的in/out/inout
存储过程 大概定义:用一个别名来描述多个sql语句的执行过程. 最简单 delimiter // create PROCEDURE p1() begin select * from userinfo; ...
- 超详细,多图文使用galera cluster搭建mysql集群并介绍wsrep相关参数
超详细,多图文使用galera cluster搭建mysql集群并介绍wsrep相关参数 介绍galera cluster原理的文章已经有一大堆了,百度几篇看一看就能有相关了解,这里就不赘述了.本文主 ...
- Linux系统部署JavaWeb项目(超详细tomcat,nginx,mysql)
转载自:Linux系统部署JavaWeb项目(超详细tomcat,nginx,mysql) 我的系统是阿里云的,香港的系统,本人选择的是系统镜像:CentOS 7.3 64位. 具体步骤: 配置Jav ...
- 超强、超详细Redis数据库入门教程
这篇文章主要介绍了超强.超详细Redis入门教程,本文详细介绍了Redis数据库各个方面的知识,需要的朋友可以参考下 [本教程目录] 1.redis是什么2.redis的作者何许人也3.谁在使用red ...
- Struts2+Spring4+Hibernate4整合超详细教程
Struts2.Spring4.Hibernate4整合 超详细教程 Struts2.Spring4.Hibernate4整合实例-下载 项目目的: 整合使用最新版本的三大框架(即Struts2.Sp ...
- 超强、超详细Redis数据库入门教程(转载)
这篇文章主要介绍了超强.超详细Redis入门教程,本文详细介绍了Redis数据库各个方面的知识,需要的朋友可以参考下 [本教程目录] 1.redis是什么 2.redis的作者何许人也 3.谁在使 ...
- 详细分析MySQL事务日志(redo log和undo log)
innodb事务日志包括redo log和undo log.redo log是重做日志,提供前滚操作,undo log是回滚日志,提供回滚操作. undo log不是redo log的逆向过程,其实它 ...
- centos7安装zabbix3.0超详细步骤解析
centos7安装zabbix3.0超详细步骤解析 很详细,感谢作者 以下是我操作的history 622 java -version 623 javac -version 624 grep SELI ...
- 详细分析MySQL事务日志(redo log和undo log) 表明了为何mysql不会丢数据
innodb事务日志包括redo log和undo log.redo log是重做日志,提供前滚操作,undo log是回滚日志,提供回滚操作. undo log不是redo log的逆向过程,其实它 ...
- (转)Springboot日志配置(超详细,推荐)
Spring Boot-日志配置(超详细) 更新日志: 20170810 更新通过 application.yml传递参数到 logback 中. Spring Boot-日志配置超详细 默认日志 L ...
随机推荐
- 音视频八股文(10)-- mp4结构
介绍 mp4⽂件格式⼜被称为MPEG-4 Part 14,出⾃MPEG-4标准第14部分 .它是⼀种多媒体格式容器,⼴泛⽤于包装视频和⾳频数据流.海报.字幕和元数据等.(顺便⼀提,⽬前流⾏的视频编码格 ...
- Nginx常用基础模块
Nginx常用基础模块 目录 Nginx常用基础模块 目录索引模块 配置方式 nginx的状态模块 配置方式 nginx访问控制模块 配置方式 nginx的访问限制模块 请求限制重定向 Nginx连接 ...
- golang调用sdl2,播放yuv视频
golang调用sdl2,播放yuv视频 win10 x64下测试成功,其他操作系统下不保证成功. 采用的是syscall方式,不是cgo方式. 见地址 代码如下: package main impo ...
- AI 绘画 - 如何 0 成本在线体验 AI 绘画的魅力
要想体验 AI 绘画,比较流行的三种方式是 Midjourney.OpenAI 的 DALL·E 2 以及 Stable Diffusion.而 Midjourney 已经停止免费试用,且使用价格不太 ...
- pytorch学习笔记——timm库
当使用ChatGPT帮我们工作的时候,确实很大一部分人就会失业,当然也有很大一部分人收益其中.我今天继续使用其帮我了解新的内容,也就是timm库.毫不夸张的说,Chat GPT比百分之80的博客讲的更 ...
- 洛谷P3368 【模板】树状数组 2-(区间修改,单点查询)
题目描述 如题,已知一个数列,你需要进行下面两种操作: 将某区间每一个数加上 x: 求出某一个数的值. 输入格式 第一行包含两个整数 N.M,分别表示该数列数字的个数和操作的总个数. 第二行包含 N ...
- ubuntu18 安装单机k8s v1.18.2
背景 当我们需要对k8s进行二次开发时,k8s环境是必须的,那么在ubuntu上部署单机k8s是最方便的,便于开发调试 系统准备 本人用的是Ubuntu18,以下以此为例 部署之前,最好切换至root ...
- Not a managed type: class com.example.commonspojo.entity,公共实体类剥离,然后引入报错的问题及解决办法
最近搞springcloud项目遇到在商品服务中调用基本服务时jvm扫描不到的问题 需要加@entityscan 学习博客: (9条消息) Not a managed type: class com. ...
- CodeQl lab learn
step-3 query a function named strlen import cpp from Function f where f.getName() = "strlen&quo ...
- Java如何生成随机数?要不要了解一下!
前言 我们在学习 Java 基础时就知道可以生成随机数,可以为我们枯燥的学习增加那么一丢丢的乐趣.本文就来介绍 Java 随机数. 一.Random类介绍 在 Java 中使用 Random 工具类来 ...