C++面试八股文:std::vector和std::list,如何选择?
某日二师兄参加XXX科技公司的C++工程师开发岗位第24面:
面试官:
list用过吗?二师兄:嗯,用过。
面试官:请讲一下
list的实现原理。二师兄:
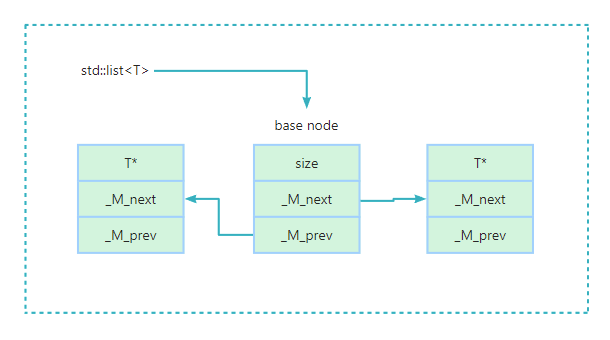
std::list被称为双向链表,和C中手写双向链表本质上没有大的区别。list对象中有两个指针,一个指向上一个节点(node),一个指向下一个节点(node)。二师兄:与手写双向链表不同的是,
list中有一个base node,此node并不存储数据,从C++11开始,此node中包含一个size_t类型的成员变量,用来记录list的长度。二师兄:所以说从C++11开始,
size()的时间复杂度是O(1),在此之前是O(N)。面试官:是每个
node都包含一个记录长度的成员变量吗?二师兄:不是,GCC中的实现只有在
header node上记录了长度信息,其他node并没有记录。
struct _List_node_base
{
_List_node_base* _M_next;
_List_node_base* _M_prev;
...
};
struct _List_node_header : public _List_node_base
{
#if _GLIBCXX_USE_CXX11_ABI
std::size_t _M_size;
#endif
...
};
面试官:添加和删除元素会导致迭代器失效吗?
二师兄:并不会,因为在任意位置添加和删除元素只需要改变
prev/next指针指向的对象,而不需要移动元素的位置,所以不会导致迭代器失效。面试官:
list和vector相比,有哪些优势?什么情况下使用list,什么情况下使用vector?二师兄:主要有2点优势:1.
list在随机插入数据不会导致数据的搬移。2.list随机删除也不会导致数据搬移。所以在频繁的随机插入/删除的场景使用list,其他场景使用vector。面试官:你知道
std::sort和list成员函数sort有什么区别吗?二师兄:
std::sort是STL算法的一部分。它排序的容器需要有随机访问迭代器,所以只能支持vector和deque。list成员函数sort用于list排序,时间复杂度是O(N*logN)。面试官:
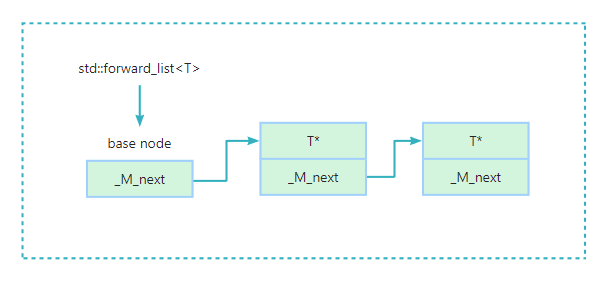
forward_list了解吗?知道如何实现的吗?二师兄:
std::forward_list是C++11引入的新容器之一。它的底层是单向链表,引入它的主要目的是为了达到手写链表的性能。同时节省了部分内存空间。(只有一根指针)
面试官:
list在pop_front/pop_back的时候需要注意哪些问题?二师兄:需要判断
list的size()不能为0,如果list为空,pop_front/pop_back会导致coredump。面试官:你知道
list的成员函数insert和forward_list的成员函数的insert_after有什么区别?二师兄:两者都可以向特定位置添加元素。不同的是
insert把元素插入到当前迭代器前,而insert_after把元素插入到当前迭代器后。面试官:以下代码的输出是什么?
#include <iostream>
#include <list>
int main(int argc, char const *argv[])
{
std::list<int> li = {1,2,3,4,5,6};
for(auto it = li.begin(); it!= li.end(); ++it)
{
if(0 == *it % 2) li.erase(it);
}
for(auto& i : li) std::cout << i << " ";
std::cout << std::endl;
}
二师兄:应该是
1 3 5。面试官:遍历两个元素数目相同的
vector和list,哪个效率高?二师兄:
vector和list的遍历效率都是O(N),效率应该是一样的。面试官:好的,回去等通知吧。
让我们看以下二师兄今日的表现:
以下代码的输出是什么?
这里实际上会输出Segmentation fault,原因是因为当从list中erase这个node,这个node的prev和next指针被清空,而++it是通过当前的node的next指针去找下一个node,解引用一个空指针,导致coredump。
erase函数返回下一个有效迭代器,所以可以把if(0 == *it % 2) li.erase(it)修改为if(0 == *it % 2) it = li.erase(it)来解决这个问题。
遍历两个元素数目相同的
vector和list,哪个效率高?
这里二师兄回答的倒是没有毛病,但是没有考虑到缓存问题。实际上因为vector底层采用数组存储数据,所以它的空间局部性更好,对缓存更友好(Cache-friendly),所以遍历vector的效率要高于遍历list。
最后多啰嗦一点,如果你没有特别的理由选择其他容器,使用vector是最好的选择。
二师兄今日的面试旅程结束了,感谢各位小伙伴的关注和点赞。为了保证面试质量,以后不一定能保证日更。文章中有任何技术性问题,请留言反馈,在此感谢!
关注我,带你21天“精通”C++!(狗头)
C++面试八股文:std::vector和std::list,如何选择?的更多相关文章
- 实战c++中的string系列--std:vector 和std:string相互转换(vector to stringstream)
string.vector 互转 string 转 vector vector vcBuf;string stBuf("Hello DaMao!!!");----- ...
- std::vector与std::list效能对比(基于c++11)
测试对象类型不同,数量级不同时,表现具有差异: 测试数据对象为std::function时: test: times(1000)vector push_back time 469 usvector e ...
- 编程杂谈——std::vector与List<T>的性能比较
昨天在比较完C++中std::vector的两个方法的性能差异并留下记录后--编程杂谈--使用emplace_back取代push_back,今日尝试在C#中测试对应功能的性能. C#中对应std:: ...
- Item 21: 比起直接使用new优先使用std::make_unique和std::make_shared
本文翻译自modern effective C++,由于水平有限,故无法保证翻译完全正确,欢迎指出错误.谢谢! 博客已经迁移到这里啦 让我们先从std::make_unique和std::make_s ...
- 使用std::map和std::list存放数据,消耗内存比实际数据大得多
使用std::map和std::list存放数据,消耗内存比实际数据大得多 场景:项目中需要存储一个结构,如下程序段中TEST_DATA_STRU,结构占24B.但是使用代码中的std::list&l ...
- c++转载系列 std::vector模板库用法介绍
来源:http://blog.csdn.net/phoebin/article/details/3864590 介绍 这篇文章的目的是为了介绍std::vector,如何恰当地使用它们的成员函数等操作 ...
- C++ 中的std::vector介绍(转)
vector是C++标准模板库中的部分内容,它是一个多功能的,能够操作多种数据结构和算法的模板类和函数库.vector之所以被认为是一个容器,是因为它能够像容器一样存放各种类型的对象,简单地说,vec ...
- std::vector介绍
vector是C++标准模板库中的部分内容,它是一个多功能的,能够操作多种数据结构和算法的模板类和函数库.vector之所以被认为是一个容器,是因为它能够像容器一样存放各种类型的对象,简单地说,vec ...
- std::vector<Channel2*> m_allChannels;容器,以及如何根据channelid的意义
std::vector<Channel2*> m_allChannels;容器,以及如何根据channelid的意义 这个容器保存了所有客户端连接的channel Channel2* Li ...
- std::vector数据复制
std::vector<boost::shared_ptr <ITEM> > srcItemList; // 数据源 std::vector<ITEM> des ...
随机推荐
- Java 框架面试题-Spring Boot自定义配置与自动配置共存
Spring Boot 是一个快速开发框架,可以简化 Spring 应用程序的开发,其中自定义配置是其中一个非常重要的特性. 在 Spring Boot 中,自定义配置允许开发者以自己的方式来配置应用 ...
- 关于Java中泛型的上界和下界理解
既然聊到了泛型的上下界问题,就先给出几个类的继承关系吧 class Fruit{}class Apple extends Fruit{}class Orange extends Fruit{}clas ...
- JS 对输入框进行限制(常用的都有)
文章来源 http://www.soso.io/article/24096.html 1.文本框只能输入数字代码(小数点也不能输入) 代码如下: <input οnkeyup="thi ...
- 颜值即正义,献礼就业季,打造多颜色多字体双飞翼布局技术简历模版(Resume)
一年好景君须记,最是橙黄橘绿时.金三银四,秣马厉兵,没有一个好看的简历模板怎么行?无论是网上随便下载还是花钱买,都是一律千篇的老式模版,平平无奇,味同嚼蜡,没错,蜡都要沿着嘴角流下来了.本次我们基于H ...
- JS执行机制--同步与异步
单线程JavaScript语言具有单线程的特点,同一个时间只能做一件事情.这是因为JavaScript脚本语言是为了处理页面中用户的交互,以及操作DOM而诞生的.如果对某个DOM元素进行添加和删除,不 ...
- ArcGIS切片服务获取切片方案xml文件(conf.xml)
在使用ArcGIS进行影像.地形等切片时,往往需要保持一致的切片方案才能够更好的加载地图服务. 本文介绍如何获取已经发布好的ArcGIS服务的切片方案xml文件. 当然切片xml文件还可以通过工具Ge ...
- 一文教你如何使用Node进程管理工具-pm2
pm2 是什么 pm2 是一个守护进程管理工具,它能帮你守护和管理你的应用程序.通常一般会在服务上线的时候使用 pm2 进行管理.pm2 能做的其实有很多,比如监听文件改动自动重启,统一管理多个进程, ...
- 2022-07-16:以下go语言代码输出什么?A:[];B:[5];C:[5 0 0 0 0];D:[0 0 0 0 0]。 package main import ( “fmt“ )
2022-07-16:以下go语言代码输出什么?A:[]:B:[5]:C:[5 0 0 0 0]:D:[0 0 0 0 0]. package main import ( "fmt" ...
- 2022-01-22:力扣411,最短独占单词缩写。 给一个字符串数组strs和一个目标字符串target。target的简写不能跟strs打架。 strs是[“abcdefg“,“ccc“],tar
2022-01-22:力扣411,最短独占单词缩写. 给一个字符串数组strs和一个目标字符串target.target的简写不能跟strs打架. strs是["abcdefg", ...
- 2021-10-26:给定一个数组arr,arr[i] = j,表示第i号试题的难度为j。给定一个非负数M。想出一张卷子,对于任何相邻的两道题目,前一题的难度不能超过后一题的难度+M。返回所有可能的卷
2021-10-26:给定一个数组arr,arr[i] = j,表示第i号试题的难度为j.给定一个非负数M.想出一张卷子,对于任何相邻的两道题目,前一题的难度不能超过后一题的难度+M.返回所有可能的卷 ...