实战案例丨GaussDB for DWS如何识别坏味道的SQL
摘要:SQL中的坏味道,你知道吗?
SQL语言是关系型数据库(RDB)的标准语言,其作用是将使用者的意图翻译成数据库能够理解的语言来执行。人类之间进行交流时,同样的意思用不同的措辞会产生不同的效果。
类似地,人类与数据库交流信息时,同样的操作用不同的SQL语句来表达,也会导致不同的效率。而有时同样的SQL语句,数据库采用不同的方式来执行,效率也会不同。那些会导致执行效率低下的SQL语句及其执行方式,我们称之为SQL中的“坏味道”。
下面这个简单的例子,可以说明什么是SQL中的坏味道。

图1-a 用union合并集合
在上面的查询语句中,由于使用了union来合并两个结果集,在合并后需要排序和去重,增加了开销。实际上符合dept_id = 1和dept_id > 2的结果间不会有重叠,所以完全可以用union all来合并,如下图所示。

图1-b 用union all合并集合
而更高效的做法是用or条件,在扫描的时候直接过滤出所需的结果,不但节省了运算,也节省了保存中间结果所需的内存开销,如下图所示。

图1-c 用or条件来过滤结果
可见完成同样的操作,用不同的SQL语句,效率却大相径庭。前两条SQL语句都不同程度地存在着“坏味道”。
对于这种简单的例子,用户可以很容易发现问题并选出最佳方案。但对于一些复杂的SQL语句,其性能缺陷可能很隐蔽,需要深入分析才有可能挖掘出来。这对数据库的使用者提出了很高的要求。即便是资深的数据库专家,有时也很难找出性能劣化的原因。
GaussDB在执行SQL语句时,会对其性能表现进行分析和记录,通过视图和函数等手段呈现给用户。本文将简要介绍如何利用GaussDB提供的这些“第一手”数据,分析和定位SQL语句中存在的性能问题,识别和消除SQL中的“坏味道”。
◆ 识别SQL坏味道之自诊断视图
GaussDB在执行SQL时,会对执行计划以及执行过程中的资源消耗进行记录和分析,如果发现异常情况还会记录告警信息,用于对原因进行“自诊断”。用户可以通过下面的视图查询这些信息:
• gs_wlm_session_info
• pgxc_wlm_session_info
• gs_wlm_session_history
• pgxc_wlm_session_history
其中gs_wlm_session_info是基本表,其余3个都是视图。gs_开头的用于查看当前CN节点上收集的信息,pgxc_开头的则包含集群中所有CN收集的信息。各表格和视图的定义基本相同,如下表所示。

表1-1 自诊断表格&函数字段定义
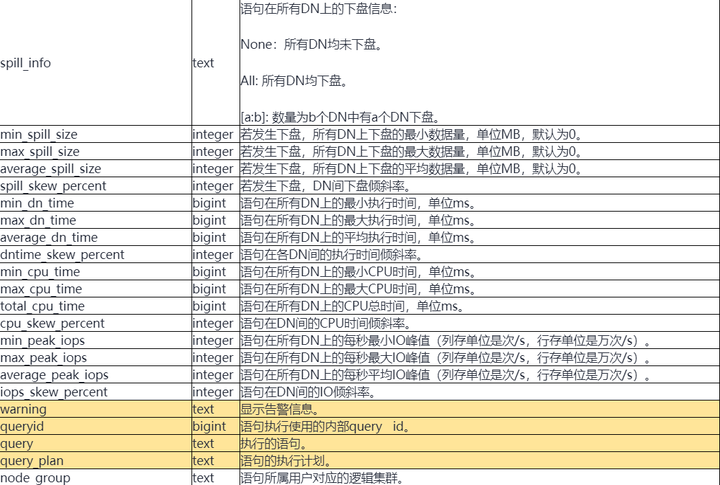
表1-2 自诊断表格&函数字段定义
其中的query字段就是执行的SQL语句。通过分析每个query对应的各字段,例如执行时间,内存,IO,下盘量和倾斜率等等,可以发现疑似有问题的SQL语句,然后结合query_plan(执行计划)字段,进一步地加以分析。特别地,对于一些在执行过程中发现的异常情况,warning字段还会以human-readable的形式给出告警信息。目前能够提供的自诊断信息如下:
◇多列/单列统计信息未收集
优化器依赖于表的统计信息来生成合理的执行计划。如果没有及时对表中各列收集统计信息,可能会影响优化器的判断,从而生成较差的执行计划。如果生成计划时发现某个表的单列或多列统计信息未收集,warning字段会给出如下告警信息:
Statistic Not Collect:
schemaname.tablename(column name list)此外,如果表格的统计信息已收集过(执行过analyze),但是距离上次analyze时间较远,表格内容发生了很大变化,可能使优化器依赖的统计信息不准,无法生成最优的查询计划。针对这种情况,可以用pg_total_autovac_tuples系统函数查询表格中自从上次分析以来发生变化的元组的数量。如果数量较大,最好执行一下analyze以使优化器获得最新的统计信息。
◇SQL未下推
执行计划中的算子,如果能下推到DN节点执行,则只能在CN上执行。因为CN的数量远小于DN,大量操作堆积在CN上执行,会影响整体性能。如果遇到不能下推的函数或语法,warning字段会给出如下告警信息:
SQL is not plan-shipping, reason : %s◇Hash连接大表做内表
如果发现在进行Hash连接时使用了大表作为内表,会给出如下告警信息:
PlanNode[%d] Large Table is INNER in HashJoin \"%s\"目前“大表”的标准是平均每个DN上的行数大于100,000,并且内表行数是外表行数的10倍以上。
◇大表等值连接使用NestLoop
如果发现对大表做等值连接时使用了NestLoop方式,会给出如下告警信息:
PlanNode[%d] Large Table with Equal-Condition use Nestloop\"%s\"目前大表等值连接的判断标准是内表和外表中行数最大者大于DN的数量乘以100,000。
◇数据倾斜
数据在DN之间分布不均匀,可导致数据较多的节点成为性能瓶颈。如果发现数据倾斜严重,会给出如下告警信息:
PlanNode[%d] DataSkew:\"%s\", min_dn_tuples:%.0f, max_dn_tuples:%.0f目前数据倾斜的判断标准是DN中行数最多者是最少者的10倍以上,且最多者大于100,000。
◇代价估算不准确
GaussDB在执行SQL语句过程中会统计实际付出的代价,并与之前估计的代价比较。如果优化器对代价的估算与实际的偏差很大,则很可能生成一个非最优化的计划。如果发现代价估计不准确,会给出如下告警信息:
"PlanNode[%d] Inaccurate Estimation-Rows: \"%s\" A-Rows:%.0f, E-Rows:%.0f目前的代价由计划节点返回行数来衡量,如果平均每个DN上实际/估计返回行数大于100,000,并且二者相差10倍以上,则认定为代价估算不准。
◇Broadcast量过大
Broadcast主要适合小表。对于大表来说,通常采用Hash+重分布(Redistribute)的方式效率更高。如果发现计划中有大表被广播的环节,会给出如下告警信息:
PlanNode[%d] Large Table in Broadcast \"%s\"目前对大表广播的认定标准为平均广播到每个DN上的数据行数大于100,000。
◇索引设置不合理
如果对索引的使用不合理,比如应该采用索引扫描的地方却采用了顺序扫描,或者应该采用顺序扫描的地方却采用了索引扫描,可能会导致性能低下。
索引扫描的价值在于减少数据读取量,因此认为索引扫描过滤掉的行数越多越好。如果采用索引扫描,但输出行数/扫描总行数>1/1000,并且输出行数>10000(对于行存表)或>100(对于列存表),则会给出如下告警信息:
PlanNode[%d] Indexscan is not properly used:\"%s\", output:%.0f, filtered:%.0f, rate:%.5f顺序扫描适用于过滤的行数占总行数比例不大的情形。如果采用顺序扫描,但输出行数/扫描总行数<=1/1000,并且输出行数<=10000(对于行存表)或<=100(对于列存表),则会给出如下告警信息:
PlanNode[%d] Indexscan is ought to be used:\"%s\", output:%.0f, filtered:%.0f, rate:%.5f◇下盘量过大或过早下盘
SQL语句执行过程中,因为内存不足等原因,可能需要将中间结果的全部或一部分转储的磁盘上。下盘可能导致性能低下,应该尽量避免。如果监测到下盘量过大或过早下盘等情况,会给出如下告警信息:
• Spill file size large than 256MB
• Broadcast size large than 100MB
• Early spill
• Spill times is greater than 3
• Spill on memory adaptive
• Hash table conflict
下盘可能是因为缓冲区设置得过小,也可能是因为表的连接顺序或连接方式不合理等原因,要结合具体的SQL进行分析。可以通过改写SQL语句,或者HINT指定连接方式等手段来解决。
使用自诊断视图功能,需要将以下变量设成合适的值:
▲ use_workload_manager(设成on,默认为on)
▲ enable_resource_check(设成on,默认为on)
▲ resource_track_level(如果设成query,则收集query级别的信息,如果设成operator,则收集所有信息,如果设成none,则以用户默认的log级别为准)
▲ resource_track_cost(设成合适的正整数。为了不影响性能,只有执行代价大于resource_track_cost语句才会被收集。该值越大,收集的语句越少,对性能影响越小;反之越小,收集的语句越多,对性能的影响越大。)
执行完一条代价大于resource_track_cost后,诊断信息会存放在内存hash表中,可通过pgxc_wlm_session_history或gs_wlm_session_history视图查看。
视图中记录的有效期是3分钟,过期的记录会被系统清理。如果设置enable_resource_record=on,视图中的记录每隔3分钟会被转储到gs_wlm_session_info表中,因此3分钟之前的历史记录可以通过gs_wlm_session_info表或pgxc_wlm_session_info视图查看。
◆ 发现正在运行的SQL的坏味道
上一节提到的自诊断视图可以显示已完成SQL的信息。如果要查看正在运行的SQL的情况,可以使用下面的视图:
• gs_wlm_session_statistics
• pgxc_wlm_session_statistics
类似地,gs_开头的用于查看当前CN节点上收集的信息,pgxc_开头的则包含集群中所有CN收集的信息。两个视图的定义与上一节的自诊断视图基本相同,使用方法也基本一致。通过观察其中的字段,可以发现正在运行的SQL中存在的性能问题。
例如,通过“select queryid, duration from gs_wlm_session_statistics order by duration desc limit 10;”可以查询当前运行的SQL中,已经执行时间最长的10个SQL。如果时间过长,可能有必要分析一下原因。

图2-a 通过gs_wlm_session_statistics视图发现可能hang住SQL
查到queryid后,可以通过query_plan字段查看该SQL的执行计划,分析其中可能存在的性能瓶颈和异常点。
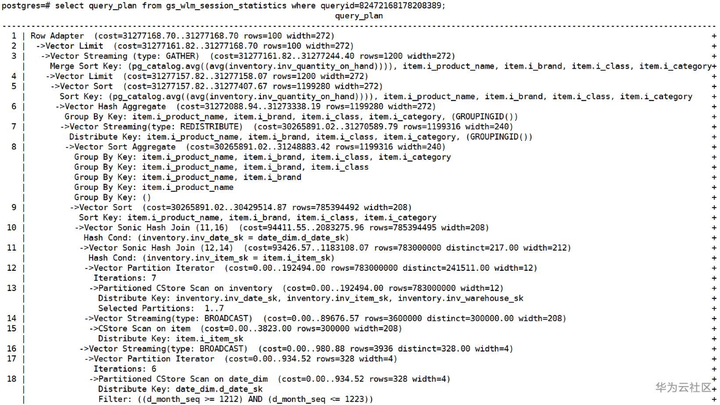
图2-b 通过gs_wlm_session_statistics视图查看当前SQL的执行计划
再下一步,可以结合等待视图等其他手段定位性能劣化的原因。
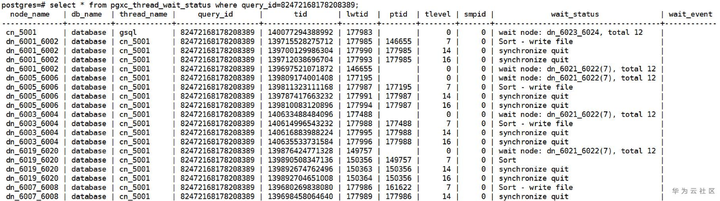
图2-c 通过gs_wlm_session_statistics视图结合等待视图定位性能问题
另外,活动视图pg_stat_activity也能提供一些当前执行SQL的信息。
◆ Top SQL——利用统计信息发现SQL坏味道
除了针对逐条SQL进行分析,还可以利用统计信息发现SQL中的坏味道。另一篇文章“Unique SQL特性原理与应用”中提到的Unique SQL特性,能够针对执行计划相同的一类SQL进行了性能统计。与自诊断视图不同的是,如果同一个SQL被多次执行,或者多个SQL语句的结构相同,只有条件中的常量值不同。这些SQL在Unique SQL视图中会合并为一条记录。因此使用Unique SQL视图能更容易看出那些类型的SQL语句存在性能问题。
利用这一特性,可以找出某一指标或者某一资源占用量最高/最差的那些SQL类型。这样的SQL被称为“Top SQL”。例如,查找占用CPU时间最长的SQL语句,可以用如下SQL:
select unique_sql_id,query,cpu_time from pgxc_instr_unique_sql order by cpu_time desc limit 10。Unique SQL的使用方式详见https://bbs.huaweicloud.com/blogs/197299。
◆ 结论
发现SQL中的坏味道是性能调优的前提。GaussDB对数据库的运行状况进行了SQL级别的监控和记录。这些打点记录的数据可以帮助用户发现可能存在的异常情况,“嗅”出潜在的坏味道。从这些数据和提示信息出发,结合其他视图和工具,可以定位出坏味道的来源,进而有针对性地进行优化。
实战案例丨GaussDB for DWS如何识别坏味道的SQL的更多相关文章
- CSS3基础——笔记+实战案例(CSS基本用法、CSS层叠性、CSS继承性)
CSS3基础——笔记 CSS是Cascading Style Sheet的缩写,翻译为"层叠样式表" 或 "级联样式表".CSS定义如何显示HTML的标签央视, ...
- 3.awk数组详解及企业实战案例
awk数组详解及企业实战案例 3.打印数组: [root@nfs-server test]# awk 'BEGIN{array[1]="zhurui";array[2]=" ...
- HTML+CSS小实战案例
HTML+CSS小实战案例 登录界面的美化,综合最近所学进行练习 网页设计先布局,搭建好大框架,然后进行填充,完成页面布局 <html> <head> <meta htt ...
- python实战案例--银行系统
stay hungry, stay foolish.求知若饥,虚心若愚. 今天和大家分享一个python的实战案例,很多人在学习过程中都希望通过一些案例来试一下,也给自己一点动力.那么下面介绍一下这次 ...
- php 网站301重定向设置代码实战案例
php 网站301重定向设置代码实战案例 301重定向就是页面永久性移走的意思,搜索引擎知道这个页面是301重定向的话,就会把旧的地址替换成重定向之后的地址. 302重定向就是页面暂时性转移,搜索引擎 ...
- 人工智能深度学习框架MXNet实战:深度神经网络的交通标志识别训练
人工智能深度学习框架MXNet实战:深度神经网络的交通标志识别训练 MXNet 是一个轻量级.可移植.灵活的分布式深度学习框架,2017 年 1 月 23 日,该项目进入 Apache 基金会,成为 ...
- 【Vue.js实战案例】- Vue.js递归组件实现组织架构树和选人功能
大家好!先上图看看本次案例的整体效果. 浪奔,浪流,万里涛涛江水永不休.如果在jq时代来实这个功能简直有些噩梦了,但是自从前端思想发展到现在的以MVVM为主流的大背景下,来实现一个这样繁杂的功能简直不 ...
- 如何从40亿整数中找到不存在的一个 webservice Asp.Net Core 轻松学-10分钟使用EFCore连接MSSQL数据库 WPF实战案例-打印 RabbitMQ与.net core(五) topic类型 与 headers类型 的Exchange
如何从40亿整数中找到不存在的一个 前言 给定一个最多包含40亿个随机排列的32位的顺序整数的顺序文件,找出一个不在文件中的32位整数.(在文件中至少确实一个这样的数-为什么?).在具有足够内存的情况 ...
- 阿里云云主机swap功能设置实战案例
阿里云云主机swap功能设置实战案例 阿里云提供的云服务器(Elastic Compute Service,简称 ECS),是云主机的一种,当前采用的虚拟化驱动是Xen(这一点可以通过bios ven ...
- 分布式事务之——tcc-transaction分布式TCC型事务框架搭建与实战案例(基于Dubbo/Dubbox)
转载请注明出处:http://blog.csdn.net/l1028386804/article/details/73731363 一.背景 有一定分布式开发经验的朋友都知道,产品/项目/系统最初为了 ...
随机推荐
- Linux发行版部分时间线
- 一步步带你剖析Java中的Reader类
本文分享自华为云社区<深入理解Java中的Reader类:一步步剖析>,作者:bug菌. 前言 在Java开发过程中,我们经常需要读取文件中的数据,而数据的读取需要一个合适的类进行处理.J ...
- cannot import name '_BindParamClause' from 'sqlalchemy.sql.expression'
python3.8 安装环境组件正常安装 运行 flask db init 报错 cannot import name '_BindParamClause' from 'sqlalchemy.sql. ...
- java学习内容-1
java学习内容-1 (一)jdk的使用 (二)定义标识符的规则 (三)java常用类 1.String类 2.Math类 3.Integer和Double类 4.输出 5.Scanner类 例子 ( ...
- 研读Java代码必须掌握的Eclipse快捷键
1. Ctrl+左键 和F3 这个是大多数人经常用到的,用来查看变量.方法.类的定义 跳到光标所在标识符的定义代码.当按执行流程阅读时,F3实现了大部分导航动作. 2 Ctrl+Shift+G 在工作 ...
- KubeEdge-Ianvs v0.2 发布:终身学习支持非结构化场景
本文分享自华为云社区<KubeEdge-Ianvs v0.2 发布:终身学习支持非结构化场景>,作者: 云容器大未来. 在边缘计算的浪潮中,AI是边缘云乃至分布式云中最重要的应用.随着边缘 ...
- 记录ElasticSearch分片被锁定导致无法分配处理过程
.suofang img { max-width: 100% !important; height: auto !important } 本篇文章记录最近ES做节点替换,从shard迁移过程中被锁定导 ...
- 深入了解MD5加密技术及其应用与局限
一.MD5简介 MD5(Message Digest Algorithm 5)是一种单向散列函数,由美国密码学家罗纳德·李维斯特(Ronald Linn Rivest)于1991年发明.它主要用于将任 ...
- 探索 Web API:SpeechSynthesis 与文本语言转换技术
一.引言 随着科技的不断发展,人机交互的方式也在不断演变.语音识别和合成技术在人工智能领域中具有重要地位,它们为残障人士和日常生活中的各种场景提供了便利.Web API 是 Web 应用程序接口的一种 ...
- 不要用第三方日志包了Microsoft.Extensions.Logging功能就很强大
在.NET中,Microsoft.Extensions.Logging是一个广泛使用的日志库,用于记录应用程序的日志信息.它提供了丰富的功能和灵活性,使开发人员能够轻松地记录各种类型的日志,并将其输出 ...