十一: 数据库缓冲池(buffer pool)
数据库缓冲池(buffer pool)
InnoDB 存储引擎是以页为单位来管理存储空间的,我们进行的增删改查操作其实本质上都是在访问页 面(包括读页面、写页面、创建新页面等操作)。而磁盘 I/O 需要消耗的时间很多,而在内存中进行操 作,效率则会高很多,为了能让数据表或者索引中的数据随时被我们所用,DBMS 会申请 占用内存来作为 数据缓冲池 ,在真正访问页面之前,需要把在磁盘上的页缓存到内存中的 Buffer Pool 之后才可以访 问。
这样做的好处是可以让磁盘活动最小化,从而 减少与磁盘直接进行 I/O 的时间 。要知道,这种策略对提 升 SQL 语句的查询性能来说至关重要。如果索引的数据在缓冲池里,那么访问的成本就会降低很多。
1. 缓冲池 vs 查询缓存
缓冲池和查询缓存是一个东西吗?不是。
1.1 缓冲池(Buffer Pool)
首先我们需要了解在 InnoDB 存储引擎中,缓冲池都包括了哪些。
在 InnoDB 存储引擎中有一部分数据会放到内存中,缓冲池则占了这部分内存的大部分,它用来存储各种 数据的缓存,如下图所示:
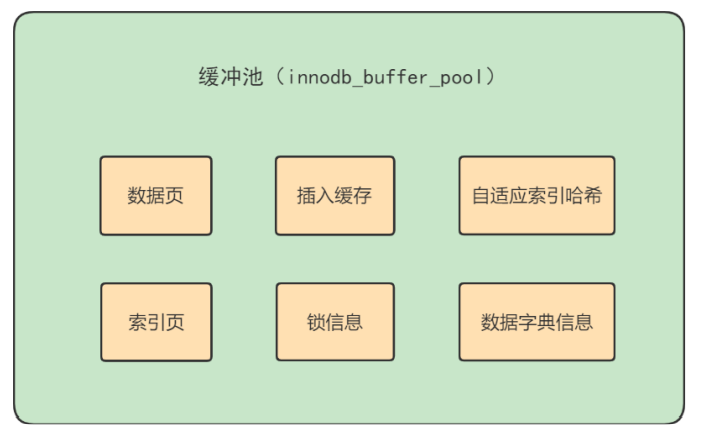
从图中,你能看到 InnoDB 缓冲池包括了数据页、索引页、插入缓冲、锁信息、自适应 Hash 和数据字典 信息等。
缓存池的重要性:
对于使用InnoDB作为存储引擎的表来说,不管是用于存储用户数据的索引(包括聚簇索引和二级索引),还是各种系统数据,都是以页的形式存放在表空间中的, 而所谓的表空间只不过是InnoDB对文件系统上一个或几个实际文件的抽象,也就是说我们的数据说到底还是存储在磁盘上的。
但是各位也都知道,磁盘的速度慢的跟乌龟一样, 怎么能配得上“快如风,疾如电”的CPU呢? 这里,缓冲池可以帮助我们消除CPU和磁盘之间的鸿沟。所以InnoDB存储引擎在处理客户端的请求时,当需要访问某个页的数据时,就会把完整的页的数据全部加载到内存中,也就是说即使我们只需要访问一个页的一条记录,那也需要先把整个页的数据加载到内存中。将整个页加载到内存中后就可以进行读写访问了,在进行完读写访问之后并不着急把该页对应的内存空间释放掉,而是将其缓存起来,这样将来有请求再次访问该页面时,就可以省去磁盘I0的开销了。
缓存原则:
“ 位置 * 频次 ”这个原则,可以帮我们对 I/O 访问效率进行优化。
首先,位置决定效率,提供缓冲池就是为了在内存中可以直接访问数据。
其次,频次决定优先级顺序。因为缓冲池的大小是有限的,比如磁盘有 200G,但是内存只有 16G,缓冲池大小只有 1G,就无法将所有数据都加载到缓冲池里,这时就涉及到优先级顺序,会 优先对使用频次高 的热数据进行加载 。
缓冲池的预读特性:
了解了缓冲池的作用之后,我们还需要了解缓冲池的另一个特性:预读。
缓冲池的作用就是提升1/0效率,而我们进行读取数据的时候存在一不“ 局部性原理”,也就是说我们使用了一些数据,大概率还会使用它周围的一些数据,因此采用“预读”的机制提前加载,可以减少未来可能的磁盘I/0操作。
1.2 查询缓存
那么什么是查询缓存呢?
查询缓存是提前把 查询结果缓存 起来,这样下次不需要执行就可以直接拿到结果。需要说明的是,在 MySQL 中的查询缓存,不是缓存查询计划,而是查询对应的结果。因为命中条件苛刻,而且只要数据表 发生变化,查询缓存就会失效,因此命中率低。
2. 缓冲池如何读取数据
缓冲池管理器会尽量将经常使用的数据保存起来,在数据库进行页面读操作的时候,首先会判断该页面 是否在缓冲池中,如果存在就直接读取,如果不存在,就会通过内存或磁盘将页面存放到缓冲池中再进 行读取。
缓存在数据库中的结构和作用如下图所示:
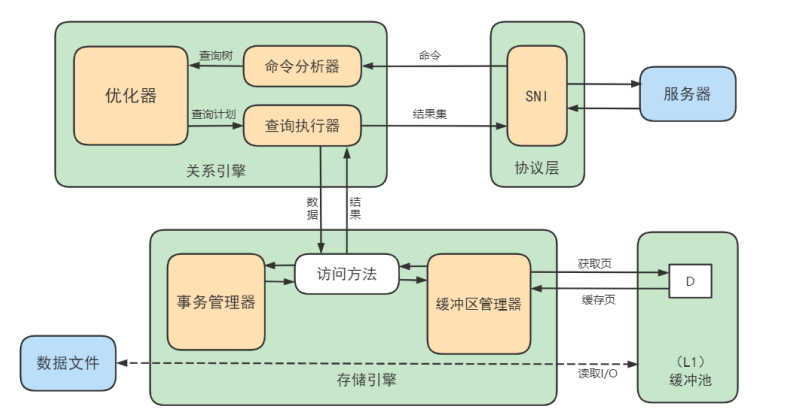
如果我们执行 SQL 语句的时候更新了缓存池中的数据,那么这些数据会马上同步到磁盘上吗?
实际上,当我们对数据库中的记录进行修改的时候,首先会修改缓冲池中页里面的记录信息, 然后数据库会以一定的频率刷新到磁盘上。注意并不是每次发生更新操作,都会立刻进行磁盘回写。缓冲池会采用一种叫做checkpoint的机制将数据回写到磁盘上,这样做的好处就是提升了数据库的整体性能。比如,当缓冲池不够用时,需要释放掉一些不常用的页,此时就可以强行采用checkpoint的方式,将不常用的脏页回写到磁盘上,然后再从缓冲池中将这些页释放掉。这里脏页(dirty page) 指的是缓冲池中被修改过的页,与磁盘上的数据页不一致。
3. 查看/设置缓冲池的大小
如果你使用的是MySQL MyISAM存储引擎,它只缓存索引,不缓存数据,对应的键缓存参数为 key_ buffer_size,你可以用它进行查看。
如果你使用的是 InnoDB 存储引擎,可以通过查看 innodb_buffer_pool_size 变量来查看缓冲池的大 小。命令如下:
show variables like 'innodb_buffer_pool_size';
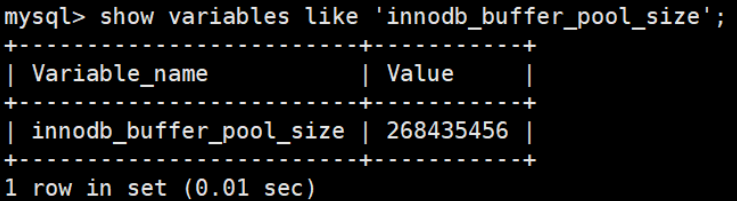
你能看到此时 InnoDB 的缓冲池大小只有 134217728/1024/1024=128MB。我们可以修改缓冲池大小,比如 改为256MB,方法如下:
set global innodb_buffer_pool_size = 268435456;

或者:
[server]
innodb_buffer_pool_size = 268435456;
然后再来看下修改后的缓冲池大小,此时已成功修改成了 256 MB:
4. 多个Buffer Pool实例
Buffer Pool本质是InnoDB向操作系统申请的一块连续的内存空间,在多线程环境下,访问Buffer Pool中的数据都需要加锁处理。在Buffer Pool特别大而且多线程并发访问特别高的情况下,单- -的Buffer Pool可能会影响请求的处理速度。所以在Buffer Pool特别大的时候,我们可以把它们拆分成若干个小的Buffer Pool ,每个Buffer Pool都称为一个实例,它们都是独立的,独立的去申请内存空间,独立的管理各种链表。所以在多线程并发访问时并不会相互影响,从而提高并发处理能力。
我们可以在服务器启动的时候通过设置innodb_ buffer_ pool_ instances 的值来修改Buffer Pool实例的个数,
比方说这样:
[server]
innodb_buffer_pool_instances = 2
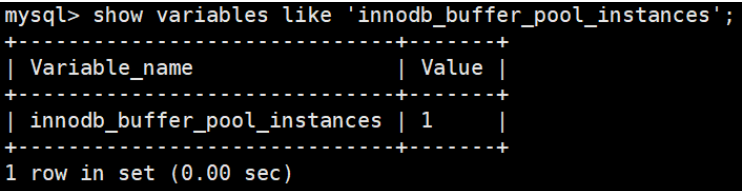
这样就表明我们要创建2个 Buffer Pool 实例。 我们看下如何查看缓冲池的个数,使用命令:
show variables like 'innodb_buffer_pool_instances';
那每个 Buffer Pool 实例实际占多少内存空间呢?其实使用这个公式算出来的:
innodb_buffer_pool_size/innodb_buffer_pool_instances
也就是总共的大小除以实例的个数,结果就是每个 Buffer Pool 实例占用的大小。
不过也不是说Buffer Pool实例创建的越多越好,分别管理各个Buffer Pool也是需要性能开销的, InnoDB规定:当 innodb_buffer_pool_size的值小于1G的时候设置多个实例是无效的,
InnoDB默认把 innodb_buffer_pool_instances 的值修改为1。而我们鼓励在Buffer Pool大于或等于1G的时候设置多个Buffer Pool实
例。
5. 引申出的问题
Buffer Pool是MySQL内存结构中十分核心的一个组成,你可以先把它想象成一个黑盒子。
黑盒下的更新数据流程
当我们查询数据的时候,会先去Buffer Pool中查询。如果Buffer Pool中不存在,存储弓|擎会先将数据从磁盘加载到Buffer Pool中,然后将数据返回给客户端;同理,当我们更新某个数据的时候,如果这个数据不存在于BufferPool,同样会先数据加载进来,然后修改修改内存的数据。被修改过的数据会在之后统一刷入磁盘。
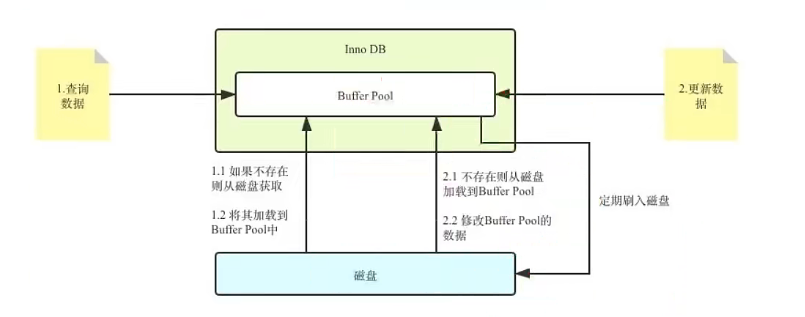
这个过程看似没啥问题,实则是有问题的。假设我们修改Buffer Pool中的数据成功,但是还没来得及将数据刷入磁盘MySQL就挂了怎么办?按照上图的逻辑,此时更新之后的数据只存在于Buffer Pool中,如果此时MySQL宕机了,这部分数据将会永久地丢失;
再者,我更新到一半突然发生错误了,想要回滚到更新之前的版本,该怎么办?连数据持久化的保证、事务回滚都做不到还谈什么崩溃恢复?
答案:Redo Log & Undo Log
十一: 数据库缓冲池(buffer pool)的更多相关文章
- MySql 缓冲池(buffer pool) 和 写缓存(change buffer) 转
应用系统分层架构,为了加速数据访问,会把最常访问的数据,放在缓存(cache)里,避免每次都去访问数据库. 操作系统,会有缓冲池(buffer pool)机制,避免每次访问磁盘,以加速数据的访问. M ...
- 【大白话系统】MySQL 学习总结 之 缓冲池(Buffer Pool) 的设计原理和管理机制
一.缓冲池(Buffer Pool)的地位 在<MySQL 学习总结 之 InnoDB 存储引擎的架构设计>中,我们就讲到,缓冲池是 InnoDB 存储引擎中最重要的组件.因为为了提高 M ...
- 【大白话系统】MySQL 学习总结 之 缓冲池(Buffer Pool) 如何支撑高并发和动态调整
如果大家对我的 [大白话系列]MySQL 学习总结系列 感兴趣的话,可以点击关注一波. 一.上节回顾 在上节< 缓冲池(Buffer Pool) 的设计原理和管理机制>中,介绍了缓冲池整体 ...
- InnoDB 中的缓冲池(Buffer Pool)
本文主要说明 InnoDB Buffer Pool 的内部执行原理,其生效的前提是使用到了索引,如果没有用到索引会进行全表扫描. 结构 在 InnoDB 存储引擎层维护着一个缓冲池,通过其可以避免对磁 ...
- mysql内核源代码深度解析 缓冲池 buffer pool 整体概述
http://blog.csdn.net/cjcl99/article/details/51063078
- innodb buffer pool小解
INNODB维护了一个缓存数据和索引信息到内存的存储区叫做buffer pool,他会将最近访问的数据缓存到缓冲区.通过配置各个buffer pool的参数,我们可以显著提高MySQL的性能. INN ...
- Innodb buffer pool/redo log_buffer 相关
InnoDB存储引擎是基于磁盘存储的,并将其中的记录按照页的方式进行管理.在数据库系统中,由于CPU速度和磁盘速度之前的鸿沟,通常使用缓冲池技术来提高数据库的整体性能. 1. Innodb_buffe ...
- MySQL buffer pool中的三种链
三种page.三种list.LRU控制调优 一.innodb buffer pool中的三种页 1.free page:从未用过的页 2.clean page:干净的页,数据页的数据和磁盘一致 3.d ...
- InnoDB Buffer Pool改进LRU页面置换
由于硬盘和内存的造价差异,一台主机实例的硬盘容量通常会远超于内存容量.对于数据库等应用而言,为了保证更快的查询效率,通常会将使用过的数据放在内存中进行加速读取. 数据页与索引页的LRU 数据页和索引页 ...
- 【MySQL】mysql buffer pool结构分析
转自:http://blog.csdn.net/wyzxg/article/details/7700394 MySQL官网配置说明地址:http://dev.mysql.com/doc/refman/ ...
随机推荐
- elementUI封装 el-dialog
讲解 // 讲解: @close="$emit('update:show1', false)"是子组件跟新父组件中的某值show1,将值变为false // :visible.sy ...
- 【笔记】VictoriaMetrics中,对大量的pull模式的targets进行分片
作者:张富春(ahfuzhang),转载时请注明作者和引用链接,谢谢! cnblogs博客 zhihu Github 公众号:一本正经的瞎扯 配置的方法请看这里:https://docs.victor ...
- (数据科学学习手札113)Python+Dash快速web应用开发——表单控件篇(下)
本文示例代码已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 由我开源的先进Dash组件库feffery-antd-co ...
- c#时间格式转换汉字大写
把时间转换为汉字大写 public class DateTimeConvert { public static string ConvertToChineseCapital(DateTime date ...
- 4.1 C++ Boost 字符串处理库
Boost 库是一个由C/C++语言的开发者创建并更新维护的开源类库,其提供了许多功能强大的程序库和工具,用于开发高质量.可移植.高效的C应用程序.Boost库可以作为标准C库的后备,通常被称为准标准 ...
- C# 中的函数与方法
在C#中,函数和方法都是一段可重用的代码块,用于实现特定的功能.函数是C#中的基本代码块之一,用于完成特定的任务和返回一个值.函数可以具有零个或多个参数,并且可以使用关键字来指定函数的访问级别和返回类 ...
- .NET NativeAOT 指南
.NET NativeAOT 指南 随着 .NET 8 的发布,一种新的"时尚"应用模型 NativeAOT 开始在各种真实世界的应用中广泛使用. 除了对 NativeAOT 工具 ...
- Visual Studio 2017高级编程(第7版)中文版
发布一个Visual Studio 2017的编程书籍: 链接:https://pan.baidu.com/s/1-RL9wkNYXwvQOdWrnAsSZQ 提取码:ig0c
- 深入浅出Java多线程(九):synchronized与锁
引言 大家好,我是你们的老伙计秀才!今天带来的是[深入浅出Java多线程]系列的第九篇内容:synchronized与锁.大家觉得有用请点赞,喜欢请关注!秀才在此谢过大家了!!! 在现代软件开发中,多 ...
- Flink-SQL数据去重
Flink去重语句 您可以通过多种方式实现去重需求,例如FIRST_VALUE.LAST_VALUE和DISTINCT等.本文为您介绍如何使用TopN方法实现去重,以及使用过程中的注意事项. 去重的方 ...