MySQL之常用函数介绍
一:函数的简介
函数可以把我们经常使用的代码封装起来,需要的时候直接调用即可。这样既提高了代码效率,又提高了可维护性。在SQL中我们也可以使用函数对检索出来的数据进行函数操作。使用这些函数,可以极大地提高用户对数据库的管理效率。
我们在使用SQL语言的时候,不是直接和这门语言打交道,而是通过它使用不同的数据库软件,即DBMS(如MySQL,Oracle,SQLServer)。DBMS之间的差异性很大,远大于同一个语言不同版本之间的差异。实际上,只有很少的函数是被DBMS同时支持的。比如,大多数 DBMS 使用(||)或者(+)来做拼接符,而在 MySQL 中的字符串拼接函数为concat()。大部分DBMS会有自己特定的函数,这就意味着采用SQL函数的代码可移植性是很差的,因此在使用函数的时候需要特别注意。
具体函数请参考:MySQL具体文档
本文使用的案例表数据:示例建表语句
二:数值函数
1:常用基本函数(重要)
1:abs(x)
-- 返回x的绝对值
2:sign(x)
-- 返回x值的符号,正数则返回 1 ,负数则返回 -1 , 0 则返回 0 ;用来对符号的判断
3:pi()
-- 返回圆周率的值:3.141593
4:ceil(x),ceiling(x)
-- 返回大于或等于某个值的最小整数,如24.1~24.9都返回25,向上取整
5:floor(x)
-- 返回小于或等于某个值的最大整数,如24.1~24.9都返回24,向下取整
6:least(e1,e2,e3...)
-- 返回列表中最小值
7:greatest(e1,e2,e3...)
-- 返回列表中最大值
8:mod(x,y)
-- 返回x除于y后的余数,如 5÷3 = 余2;注x为负数,算出来的模数就为负数
9:rand()
-- 返回0~1的随机值(16位小数的值)
10:rand(x)
-- 返回0~1的随机值,其中x的值用作种子值,相同的X值会产生相同的随机数
11:round(x)
-- 返回一个对x的值进行四舍五入后,最接近于X的整数
12:round(x,y)
-- 返回一个对x的值进行四舍五入后最接近X的值,并保留到小数点后面Y位
13:truncate(x,y)
-- 返回数字x截断为y位小数的结果,如:22.666,截取保留2位则 22.66
14:sqrt(x)
-- 返回x的平方根。当X的值为负数时,返回NULL


SELECT ABS(-22) , ABS(22) , SIGN(-10) , SIGN(10) , PI() FROM DUAL;
+----------+---------+-----------+----------+----------+
| ABS(-22) | ABS(22) | SIGN(-10) | SIGN(10) | PI() |
+----------+---------+-----------+----------+----------+
| 22 | 22 | -1 | 1 | 3.141593 |
+----------+---------+-----------+----------+----------+
SELECT CEIL(24) , CEIL(24.2) , CEIL(24.5) , CEIL(24.8) FROM DUAL;
+----------+------------+------------+------------+
| CEIL(24) | CEIL(24.2) | CEIL(24.5) | CEIL(24.8) |
+----------+------------+------------+------------+
| 24 | 25 | 25 | 25 |
+----------+------------+------------+------------+
SELECT CEILING(24) , CEILING(24.2) , CEILING(24.5) , CEILING(24.8) FROM DUAL;
+-------------+---------------+---------------+---------------+
| CEILING(24) | CEILING(24.2) | CEILING(24.5) | CEILING(24.8) |
+-------------+---------------+---------------+---------------+
| 24 | 25 | 25 | 25 |
+-------------+---------------+---------------+---------------+
SELECT FLOOR(24) , FLOOR(24.2) , FLOOR(24.5) , FLOOR(24.8) FROM DUAL;
+-----------+-------------+-------------+-------------+
| FLOOR(24) | FLOOR(24.2) | FLOOR(24.5) | FLOOR(24.8) |
+-----------+-------------+-------------+-------------+
| 24 | 24 | 24 | 24 |
+-----------+-------------+-------------+-------------+
SELECT LEAST(20.3, 22, 3, 14.6) , LEAST(3, 5, 2), GREATEST(20.3, 22, 3, 14.6) , GREATEST(3, 5, 2) FROM DUAL;
+--------------------------+----------------+-----------------------------+-------------------+
| LEAST(20.3, 22, 3, 14.6) | LEAST(3, 5, 2) | GREATEST(20.3, 22, 3, 14.6) | GREATEST(3, 5, 2) |
+--------------------------+----------------+-----------------------------+-------------------+
| 3.0 | 2 | 22.0 | 5 |
+--------------------------+----------------+-----------------------------+-------------------+
SELECT MOD(6,2) , MOD(5,2) , RAND() , RAND() , RAND(5),RAND(5) FROM DUAL;
+----------+----------+---------------------+--------------------+---------------------+---------------------+
| MOD(6,2) | MOD(5,2) | RAND() | RAND() | RAND(5) | RAND(5) |
+----------+----------+---------------------+--------------------+---------------------+---------------------+
| 0 | 1 | 0.13159177650845774 | 0.9660609271061242 | 0.40613597483014313 | 0.40613597483014313 |
+----------+----------+---------------------+--------------------+---------------------+---------------------+
SELECT ROUND(3), ROUND(3.41), ROUND(3.51), ROUND(3.555,2), ROUND(3.555,1) , ROUND(350.22,-2) FROM DUAL;
+----------+-------------+-------------+----------------+----------------+------------------+
| ROUND(3) | ROUND(3.41) | ROUND(3.51) | ROUND(3.555,2) | ROUND(3.555,1) | ROUND(350.22,-2) |
+----------+-------------+-------------+----------------+----------------+------------------+
| 3 | 3 | 4 | 3.56 | 3.6 | 400 |
+----------+-------------+-------------+----------------+----------------+------------------+
SELECT TRUNCATE(125.666,2), TRUNCATE(125.333,1), TRUNCATE(125.333,-2), SQRT(3) FROM DUAL;
+---------------------+---------------------+----------------------+--------------------+
| TRUNCATE(125.666,2) | TRUNCATE(125.333,1) | TRUNCATE(125.333,-2) | SQRT(3) |
+---------------------+---------------------+----------------------+--------------------+
| 125.66 | 125.3 | 100 | 1.7320508075688772 |
+---------------------+---------------------+----------------------+--------------------+
基本函数使用方式
2:指数与对数
1:pow(x,y),power(x,y)
-- 返回x的y次方
2:exp(x)
-- 返回e的x次方,其中e是一个常数,2.718281828459045
3:ln(x),log(x)
-- 返回以e为底的x的对数,当x <= 0 时,返回的结果为null
4:log10(x)
-- 返回以10为底的x的对数,当x <= 0 时,返回的结果为null
5:log2(x)
-- 返回以2为底的x的对数,当x <= 0 时,返回null
SELECT POW(2,5),POWER(2,4),EXP(2),LN(10),LOG10(10),LOG2(4) FROM DUAL;
+----------+------------+------------------+-------------------+-----------+---------+
| POW(2,5) | POWER(2,4) | EXP(2) | LN(10) | LOG10(10) | LOG2(4) |
+----------+------------+------------------+-------------------+-----------+---------+
| 32 | 16 | 7.38905609893065 | 2.302585092994046 | 1 | 2 |
+----------+------------+------------------+-------------------+-----------+---------+
指数与对数使用方式
3:进制间转换
1:bin(n)
-- 返回一个N的二进制值的字符串表示,其中N是一个long(BIGINT)数。这等同于CONV(N,10,2)。若N为NULL则返回为NULL
2:oct(n)
-- 返回一个N的八进制值的字符串表示,其中N是一个long(BIGINT)数。这等同于CONV(N,10,8)。若N为NULL则返回为NULL
3:hex(N_or_S)
-- 接受的值可以为字符串也可以为Long类型的数值;
-- 传Long数值后返回一个N的十六进制值的字符串表示,其中N是一个long(BIGINT)数。这等同于CONV(N,10,16)。若N为NULL则返NULL
-- 传字符串时则对每个字符进行一个转换,比如“a”转换为"61";比如“我”转换为“E68891”;比如“ab”转换为“6162”
-- 注: 在UTF8下每个汉字会被转成六个十六进制数字的十六进制字符串表示;在GBK下则四个十六进制数字。
4:conv(n,from_base,to_base)
-- 不同数之间进制转换,返回值为转换过的n的字符串表现形式,由当前的from_base进制转换为to_base进制,
-- 传null反null,自变量 n 可以被指定为一个整型的字符串或者整型数值
-- 注意:from_base和to_base进制,取值在2~36(就是我们常说的几进制转换为几进制,
-- 如果from/to_base为负数,则n被看作一个带符号数
5:unhex(str)
-- 执行HEX(str)的逆运算。它解释每对十六进制数字的参数作为数字并将其转换成由数字表示的字符。所得字符返回为二进制字符串
-- 在参数字符串中的字符必须是合法的十六进制数字:'0'~'9','A'~'F','a'~'f'
-- 注:如果UNHEX()遇到任何非十六进制数字的参数,它返回NULL
-- 关于Long数值的方式转换
SELECT CONV(10,10,16) , CONV('15',10,16), CONV('16',10,16), CONV('7',10,2) FROM DUAL;
+------------------+------------------+------------------+----------------+
| CONV('10',10,16) | CONV('15',10,16) | CONV('16',10,16) | CONV('7',10,2) |
+------------------+------------------+------------------+----------------+
| A | F | 10 | 111 |
+------------------+------------------+------------------+----------------+
SELECT BIN(10), OCT(7), OCT(8), OCT(17), OCT(9), HEX(10), HEX(15) FROM DUAL;
+---------+--------+--------+---------+--------+---------+---------+
| BIN(10) | OCT(7) | OCT(8) | OCT(17) | OCT(9) | HEX(10) | HEX(15) |
+---------+--------+--------+---------+--------+---------+---------+
| 1010 | 7 | 10 | 21 | 11 | A | F |
+---------+--------+--------+---------+--------+---------+---------+
-- 关于字符串的方式转换
SELECT HEX("abc"), HEX("我们"), UNHEX("616263"), UNHEX("E68891E4BBAC") FROM DUAL;
+------------+---------------+-----------------+-----------------------+
| HEX("abc") | HEX("我们") | UNHEX("616263") | UNHEX("E68891E4BBAC") |
+------------+---------------+-----------------+-----------------------+
| 616263 | E68891E4BBAC | abc | 我们 |
+------------+---------------+-----------------+-----------------------+
进制间转换使用方式
4:角度与弧度互转函数
1:radians(x)
-- 将角度转化为弧度,其中,参数x为角度值
2:degrees(x)
-- 将弧度转化为角度,其中,参数x为弧度值
示例:
SELECT RADIANS(30),RADIANS(60),RADIANS(90),DEGREES(2*PI()),DEGREES(RADIANS(90)) FROM DUAL;
+--------------------+--------------------+--------------------+-----------------+----------------------+
| RADIANS(30) | RADIANS(60) | RADIANS(90) | DEGREES(2*PI()) | DEGREES(RADIANS(90)) |
+--------------------+--------------------+--------------------+-----------------+----------------------+
| 0.5235987755982988 | 1.0471975511965976 | 1.5707963267948966 | 360 | 90 |
+--------------------+--------------------+--------------------+-----------------+----------------------+
5:三角函数
1:sin(x)
-- 返回x的正弦值,其中,参数x为弧度值
2:asin(x)
-- 返回x的反正弦值,即获取正弦为x的值。如果x的值不在-1到1之间,则返回null cos(x) 返回x的余弦值,其中,参数x为弧度值
3:acos(x)
-- 返回x的反余弦值,即获取余弦为x的值。如果x的值不在-1到1之间,则返回null tan(x) 返回x的正切值,其中,参数x为弧度值
4:atan(x)
-- 返回x的反正切值,即返回正切值为x的值
5:atan2(m,n)
-- 返回两个参数的反正切值
6:cot(x)
-- 返回x的余切值,其中,x为弧度值
示例:
SELECT SIN(RADIANS(30)),DEGREES(ASIN(1)),TAN(RADIANS(45)),DEGREES(ATAN(1)),DEGREES(ATAN2(1,1) )FROM DUAL;
+---------------------+------------------+--------------------+------------------+----------------------+
| SIN(RADIANS(30)) | DEGREES(ASIN(1)) | TAN(RADIANS(45)) | DEGREES(ATAN(1)) | DEGREES(ATAN2(1,1) ) |
+---------------------+------------------+--------------------+------------------+----------------------+
| 0.49999999999999994 | 90 | 0.9999999999999999 | 45 | 45 |
+---------------------+------------------+--------------------+------------------+----------------------+
三:字符串函数(重要)
1:char_length(s) / character_length(s)
-- 返回传入的字符串的字符个数,传null反null
2:length(s) / octet_length(s)
-- 返回传入的字符串的字节个数,传null反null。注:在gbk中一个汉字占2字节,utf8中一个汉字占3字节
3:concat(s1,s2,s3 ...)
-- 就是把传入的字符串拼接在一起,如果有任何一个参数为null,返回结果为null
4:concat_ws(separator,str1,str2, ...)
-- 是concat方法的增强,separator参数是指定分隔符,分隔符为null,整个结果也是null
5:insert(str,pos,len,newstr)
-- 替换指定位置的字符串,返回字符串str, 其字符串起始于pos位置和len位置中间的一部分字符串被替换为newstr。
-- 如果pos超过字符串长度,则返回值为原始字符串。 假如len的长度大于其它字符串的长度,则从位置pos开始替换。
-- 若任何一个参数为null,则返回值为NULL。如果pos起始位为0或负数则不改变原字符串
6:replace(str,from_str,to_str)
-- 返回字符串str以及所有被字符串to_str替代的字符串from_str。
-- 简单说用字符串to_str替换字符串str中所有出现的字符串from_str
-- char_length , character_length
SELECT CHAR_LENGTH("蚂蚁小哥aa"), CHARACTER_LENGTH("father"), CHAR_LENGTH(NULL), CHAR_LENGTH("") FROM DUAL;
+---------------------------+----------------------------+-------------------+-----------------+
| CHAR_LENGTH("蚂蚁小哥aa") | CHARACTER_LENGTH("father") | CHAR_LENGTH(NULL) | CHAR_LENGTH("") |
+---------------------------+----------------------------+-------------------+-----------------+
| 6 | 6 | NULL | 0 |
+---------------------------+----------------------------+-------------------+-----------------+
-- (UTF8环境下) length , octet_length
-- UTF8环境下一个汉字占3个字节,GBK环境下一个汉字占2字节
SELECT LENGTH("张三a"), OCTET_LENGTH("张三") FROM DUAL;
+-------------------+-----------------------+
| LENGTH("张三a") | OCTET_LENGTH("张三") |
+-------------------+-----------------------+
| 7 | 6 |
+-------------------+-----------------------+
-- concat,concat_ws
SELECT CONCAT("蚂蚁小哥","--","霸气") , CONCAT("abc",null) FROM DUAL;
+------------------------------------+----------------------+
| concat("蚂蚁小哥","--","霸气") | concat("abc",null) |
+------------------------------------+----------------------+
| 蚂蚁小哥--霸气 | NULL |
+------------------------------------+----------------------+
SELECT CONCAT(sname," -- ", saddress) FROM student limit 1,1;
+-------------------------------+
| CONCAT(sname," -- ", saddress)|
+-------------------------------+
| 李鑫灏 -- 安徽合肥 |
+-------------------------------+
SELECT CONCAT_WS(",","张三","王二","李四") , CONCAT("a",null,'a') FROM DUAL;
+-----------------------------------------+----------------------+
| CONCAT_WS(",","张三","王二","李四") | CONCAT("a",null,'a') |
+-----------------------------------------+----------------------+
| 张三,王二,李四 | NULL |
+-----------------------------------------+----------------------+
-- insert
SELECT INSERT("abcdef",2,4,"您好"), INSERT("abcdef",2,200,"您好"), INSERT("abcdef",-1,2,"您好")FROM DUAL;
+-----------------------------+---------------------------------+------------------------------+
| INSERT("abcdef",2,4,"您好") | INSERT("abcdef",2,200,"您好") | INSERT("abcdef",-1,2,"您好") |
+-----------------------------+---------------------------------+------------------------------+
| a您好f | a您好 | abcdef |
+-----------------------------+---------------------------------+-------------------------------+
-- replace
SELECT REPLACE("abcabcabc","a","#") FROM DUAL;
+------------------------------+
| REPLACE("abcabcabc","a","#") |
+------------------------------+
| #bc#bc#bc |
+------------------------------+
字符串函数 1~6 基本示例
7:lower(str) / lcase(str)
-- 将字符串str的所有字母转成小写字母
8:upper(str) / ucase(str)
-- 将字符串str的所有字母转成大写字母
9:left(str,len)
-- 返回字符串str从左开始的第len个字符
10:right(str,len)
-- 返回字符串str从右开始的第len个字符
11:lpad(str,len,padstr)
-- 左补齐,返回字符串 str, 其左边由字符串padstr填补到len 字符长度。假如str 的长度大于len, 则返回值被缩短至 len 字符
12:rpad(str,len,padstr)
-- 返回字符串str, 其右边被字符串padstr填补至len字符长度。假如字符串str的长度大于len,则返回值被缩短到与len字符相同长度
13:ltrim(str)
-- 去除字符串左边空格
14:rtrim(str)
-- 去除字符串右边空格
15:trim( [ remstr str from ] str)
-- 返回字符串str,其中所有remStr前缀和/或后缀都已被删除。若分类符BOTH、LEADING或TRAILING中没有一个是给定的,则假设为BOTH
-- remStr 为可选项,在未指定情况下,可删除空格。
-- remStr参数作用:
-- both 清除2边指定字符
-- leading 清除左边指定字符
-- trailing 清除右边指定字符
-- lower(str)/lcase(str),upper(str)/ucase(str)
SELECT LOWER("aBcDeF"), LCASE("aBcDeF"), UPPER("aBcDeF"), UCASE("aBcDeF") FROM DUAL;
+-----------------+-----------------+-----------------+-----------------+
| LOWER("aBcDeF") | LCASE("aBcDeF") | UPPER("aBcDeF") | UCASE("aBcDeF") |
+-----------------+-----------------+-----------------+-----------------+
| abcdef | abcdef | ABCDEF | ABCDEF |
+-----------------+-----------------+-----------------+-----------------+
-- left,right
SELECT LEFT("abcdef",3),RIGHT("abcdef",3) FROM DUAL;
+------------------+-------------------+
| LEFT("abcdef",3) | RIGHT("abcdef",3) |
+------------------+-------------------+
| abc | def |
+------------------+-------------------+
-- lpad,rpad
SELECT LPAD('abc',5,'#'), LPAD('abc',2,'#') ,RPAD('abc',5,'#'), RPAD('abc',2,'#') FROM DUAL;
+-------------------+-------------------+-------------------+-------------------+
| LPAD('abc',5,'#') | LPAD('abc',2,'#') | RPAD('abc',5,'#') | RPAD('abc',2,'#') |
+-------------------+-------------------+-------------------+-------------------+
| ##abc | ab | abc## | ab |
+-------------------+-------------------+-------------------+-------------------+
-- ltrim,rtrim
SELECT LTRIM(" 张三 "), RTRIM(" 张三 ") FROM DUAL;
+------------------------------+-------------------------------+
| LTRIM(" 张三 ") | RTRIM(" 张三 ") |
+------------------------------+-------------------------------+
| 张三 | 张三 |
+------------------------------+-------------------------------+
-- trim
SELECT TRIM(" aa ") "不写其它则代码剔除左右两边空格" ,
TRIM(LEADING '*' FROM '****aa**bb****') "LEADING左剔除",
TRIM(TRAILING '*' FROM '****aa**bb****') "TRAILING右剔除",
TRIM(BOTH '*' FROM '****aa**bb****') "自动左右两边" FROM DUAL;
+----------------------------------------+------------------+-------------------+-----------+
| 不写其它则代码剔除左右两边空格 | LEADING左剔除 | TRAILING右剔除 | 自动左右两边|
+----------------------------------------+------------------+-------------------+------------+
| aa | aa**bb**** | ****aa**bb | aa**bb |
+----------------------------------------+------------------+-------------------+------------+
字符串函数 7~15 基本示例
16:space(n)
-- 辅助函数,设置空格数量
17:strcmp(str1,str2)
-- 字符串比较 前大于后反1,后大于前反-1,一样反0
-- 说明:比较是按照字符串的一个一个字符的ASCII比对,一旦比对当前字符大则直接返回结果(WIN下不区分大小写)
18:subString(str,pos,[len]) / subStr(str,pos,[len]) / mid(str,pos,[len])
-- 字符串分割,不带有len参数的格式从字符串str返回一个子字符串,起始于位置pos。
-- 带有len参数的格式从字符串str返回一个长度同len字符相同的子字符串,起始于置pos。
-- 也可能对pos使用一个负值。假若这样,则子字符串的位置起始于字符串结尾的pos字符,而不是字符串的开头位置。
-- 注:使用FROM的格式为标准SQL语法(如subString("abc" from 2 for 1))
19:subString_index(str,delim,count)
-- 在定界符delim以及count出现前,从字符串str返回字符串。若count为正值,则返回最终定界符(从左边开始)左边的一切内容。
-- 若count为负值,则返回定界符(从右边开始)右边的一切内容。
20:locate(substr,str,[pos]) / position(substr in str)
-- 返回字符串substr在str第一次出现的位置,但是locate里面多了个pos是指定substr在str的什么位置检索
21:instr(str,substr)
-- 返回substr字符串第一次出现的位置
22:elt(n,str1,str2,str3)
-- 返回指定位置的字符串,若N小于1或大于参数的数目,则返回值为NULL
23:field(str,str1,str2,...)
-- 返回值为str1,str2,str3,……列表中的str指数(位置下标)。在找不到str的情况下,返回值为 0
-- 注意:如果所有对于FIELD() 的参数均为字符串,则所有参数均按照字符串进行比较。
-- 如果所有的参数均为数字,则按照数字进行比较。否则,参数按照双倍进行比较。
24:find_in_set(str,strlist)
-- 在strList的有逗号分隔的字符串里面匹配str的位置(strList之间逗号为英文逗号,且避免出现空格)
-- space
SELECT CONCAT("aaa", SPACE(5), "bbb") FROM DUAL;
+--------------------------------+
| CONCAT("aaa", SPACE(5), "bbb") |
+--------------------------------+
| aaa bbb |
+--------------------------------+
-- strcmp
SELECT STRCMP("abc","aac"), STRCMP("aaa","b"), STRCMP("aaa","AAA") FROM DUAL;
+---------------------+-------------------+---------------------+
| STRCMP("abc","aac") | STRCMP("aaa","b") | STRCMP("aaa","AAA") |
+---------------------+-------------------+---------------------+
| 1 | -1 | 0 |
+---------------------+-------------------+---------------------+
-- subString
SELECT SUBSTRING('abcdefg' FROM 3) "标准右偏移3",
SUBSTRING('abcdefg' FROM 3 for 3) "标准右偏移3,并取3个字符",
SUBSTRING('abcdefg', 3, 3) "右偏移3,取3个字符",
SUBSTRING('abcdefg', -4, 3) "末尾左偏移4,取右3字符",
SUBSTRING('abcdefg', -2, 5) "末尾左偏移2,取右5字符"
FROM DUAL;
+-----------+------------------------+------------------+----------------------+----------------------+
|标准右偏移3 |标准右偏移3,并取3个字符 |右偏移3,取3个字符 |末尾左偏移4,取右3字符 |末尾左偏移2,取右5字符 |
+-----------+------------------------+------------------+----------------------+----------------------+
|cdefg |cde |cde |def |fg |
+-----------+------------------------+------------------+----------------------+----------------------+
-- subString_index
SELECT SUBSTRING_INDEX('ab_cd_ef_gh','_',2) , SUBSTRING_INDEX('ab_cd_ef_gh','_',-2) FROM DUAL;
+--------------------------------------+---------------------------------------+
| SUBSTRING_INDEX('ab_cd_ef_gh','_',2) | SUBSTRING_INDEX('ab_cd_ef_gh','_',-2) |
+--------------------------------------+---------------------------------------+
| ab_cd | ef_gh |
+--------------------------------------+---------------------------------------+
-- locate position
SELECT LOCATE('ab', '**ab**cd**ab**cd**ab**cd**') '出现ab的位置下标',
POSITION('ab' IN '**ab**cd**ab**cd**ab**cd**') '出现ab的位置下标',
LOCATE('ab', '**ab**cd**ab**cd**ab**cd**',4) '从下标4开始判断ab的位置下标'
FROM DUAL;
+--------------------+-------------------+-------------------------------+
| 出现ab的位置下标 | 出现ab的位置下标 | 从下标4开始判断ab的位置下标 |
+--------------------+-------------------+-------------------------------+
| 3 | 3 | 11 |
+--------------------+----------------**-+-------------------------------+
-- instr
SELECT INSTR("鲍大莉是个霸气的程序员","霸气") "字符串 ‘霸气’ 在字符串的位置下标" FROM DUAL;
+-----------------------------------+
| 字符串 ‘霸气’ 在字符串的位置下标 |
+-----------------------------------+
| 6 |
+-----------------------------------+
-- elt
SELECT ELT(2, '手机', '电脑', '香蕉', 'ipad') FROM DUAL;
+----------------------------------------------+
| ELT(2, '手机', '电脑', '香蕉', 'ipad') |
+----------------------------------------------+
| 电脑 |
+----------------------------------------------+
-- field
SELECT FIELD(20, 2, 15, 45, 26, 20, 66, 20, 32) "第一次出现20的位置" ,
FIELD(20, 2, 15, 'ac', 26, 'av', '20', 20, 32) "第一次出现20的位置"
FROM DUAL;
+----------------------------+----------------------------+
| 第一次出现20的位置 | 第一次出现20的位置 |
+----------------------------+----------------------------+
| 5 | 6 |
+----------------------------+----------------------------+
-- find_in_set
SELECT FIND_IN_SET('我', '你,是,我,的') "'我'出现除逗号位置下标" ,
FIND_IN_SET('b', 'a,c,e,d,b,e') "‘b’出现位置"
FROM DUAL;
+----------------------------+---------------------+
| '我'出现除逗号位置下标 | ‘b’出现位置 |
+----------------------------+---------------------+
| 3 | 5 |
+----------------------------+---------------------+
字符串函数 16~24 基本示例
25:reverse(str)
-- 字符串反转
26:repeat(str,count)
-- 返回一个由重复的字符串str组成的字符串,字符串str的数目等于count。
-- 若count <= 0,则返回一个空字符串。若str或count为NULL,则返回NULL
27:format(x,d)
-- 将数字X的格式写为'#,###,###.##',以四舍五入的方式保留小数点后d位,并将结果以字符串的形式返回。
-- 若d为0, 则返回结果不带有小数点,或不含小数部分。
-- reverse
SELECT REVERSE('abcdef'), REVERSE('蚂蚁小哥在学校上课') FROM DUAL;
+-------------------+-------------------------------------+
| REVERSE('abcdef') | REVERSE('蚂蚁小哥在学校上课') |
+-------------------+-------------------------------------+
| fedcba | 课上校学在哥小蚁蚂 |
+-------------------+-------------------------------------+
-- repeat
SELECT REPEAT('蚂蚁ab',3) FROM DUAL;
+--------------------------+
| REPEAT('蚂蚁ab',3) |
+--------------------------+
| 蚂蚁ab蚂蚁ab蚂蚁ab |
+--------------------------+
-- format
SELECT FORMAT('123456.789',2), FORMAT('12.345678',2), FORMAT('12.34',0) FROM DUAL;
+------------------------+-----------------------+-------------------+
| FORMAT('123456.789',2) | FORMAT('12.345678',2) | FORMAT('12.34',0) |
+------------------------+-----------------------+-------------------+
| 123,456.79 | 12.35 | 12 |
+------------------------+-----------------------+-------------------+
字符串函数 25~27 基本示例
28:ascii(s)
-- 返回字符串s最左边第一个字符的ASCII值(0~255)
SELECT ASCII('a') , ASCII('b') , ASCII('bc') , ASCII(NULL), ASCII('烦') FROM DUAL;
+------------+------------+-------------+-------------+--------------+
| ASCII('a') | ASCII('b') | ASCII('bc') | ASCII(NULL) | ASCII('烦') |
+------------+------------+-------------+-------------+--------------+
| 97 | 98 | 98 | NULL | 231 |
+------------+------------+-------------+-------------+--------------+
因为当前在 UTF-8 环境下,所以一个汉字占3字节,所以在这里ASCII('烦')返回的是第一个字节
“烦”在UTF-8环境下的字节为(-25,-125,-90);
不过在MySQL要转换为(256-25,256-125,256-90;最终展示为:231,131,166)
我们想计算在UTF-8环境下一个汉字的字节的JAVA代码
byte[] bytes = "烦".getBytes(StandardCharsets.UTF_8);
for (int i = 0; i < bytes.length; i++) System.out.println(bytes[i]); 29:bit_length(str)
-- 返回值为二进制的字符串str长度,但是str若为null则也返回null
-- 说明:bit是计算机里最小的单位,8bit(位)才是1byte(字节),bit长度计算是根据ASCII码表的,一个ASCII字符为8
-- 但是一个汉字在UTF-8编码的数据库环境下是3个字节(24位),在GBK下则是16位
SELECT BIT_LENGTH('a'), BIT_LENGTH(NULL), BIT_LENGTH('我'), BIT_LENGTH('ab') FROM DUAL;
+-----------------+------------------+-------------------+------------------+
| BIT_LENGTH('a') | BIT_LENGTH(NULL) | BIT_LENGTH('我') | BIT_LENGTH('ab') |
+-----------------+------------------+-------------------+------------------+
| 8 | NULL | 24 | 16 |
+-----------------+------------------+-------------------+------------------+ 30:char(n,n... [ using charset ])
-- 将每个参数n传进去,会返回一个包含这些整数值的字符串表示形式,[using charset]可选参数,指定编码
-- 传null反null , n必须是整数或字符串形式数字 如传入97、'98cdf'、"99",则"98cdf"将按照97解析
SELECT CHAR(97), CHAR('98'), CHAR(97,'98',99),
CHAR(231,131,166) '因为MySSQL使用UTF8编码,所以3byte字节放在一起被解析为一个汉字'
FROM DUAL;
+---------+-----------+-----------------+--------------------------------------------------------+
| CHAR(97)| CHAR('98')| CHAR(97,'98',99)| 因为MySSQL使用UTF8编码,所以3byte字节放在一起被解析为一个汉字|
+---------+-----------+-----------------+--------------------------------------------------------+
| a | b | abc | 烦 |
+---------+-----------+-----------------+--------------------------------------------------------+
SELECT CHAR(97,'98cdf',99), CHAR(213,244 using GBK) '指定编码显示' FROM DUAL;
+---------------------+--------------------+
| CHAR(97,'98cdf',99) | 指定编码显示 |
+---------------------+--------------------+
| abc | 蒸 |
+---------------------+--------------------+ 31:ord(str)
-- 返回字符串str最左边的一个字符的ASCII,但是字符串最左边的是一个汉字则在UTF8下是3字节,则这三字节需要计算
-- 注意:如果是单字符就和ASCII(str)函数返回的一样,多字符就要计算
SELECT ORD('abc'), ORD('慌张'), CHAR(ORD('慌')) '校验‘慌’字' FROM DUAL;
+------------+---------------+--------------------+
| ORD('abc') | ORD('慌张') | 校验‘慌’字 |
+------------+---------------+--------------------+
| 97 | 15107468 | 慌 |
+------------+---------------+--------------------+
注:ORD('慌张')则计算'慌'的字节数,因为UTF8环境下占3字则需要计算
通过JAVA计算后得字节为(-26,-123,-116),计算MySQL识别的:(256-26,256-123,256-116)最终为:char(230,133,140)
为何计算为:15107468;这时候我们得有公式计算
GBK编码下计算方式:
(first byte ASCII code) * 256 + (second byte ASCII code)
UTF8编码下计算方式:
(first byte ASCII code) * 256 * 256 + (second byte ASCII code) * 256 + (thirdly byte ASCII code)
在UTF-8下如’慌‘字计算:
(230*256*256) + (133*256) + (140) = 15107468
四:日期和时间函数(重要)
1:获取日期、时间
1:curdate() / current_date()
-- 返回当前年月日的日期;返回的格式为:年-月-日 yyyy-MM-dd
-- 注:若希望返回:年月日(yyyyMMdd)格式 则需要进行一个+0
2:curtime() / current_time()
-- 返回当前时分秒的时间;返回的格式为:时:分:秒 HH:mm:ss
-- 注:若希望返回:时分秒(HHmmss)格式 则需要进行一个+0
3:now() / sysdate() / current_timestamp() / localtime() / localtimestamp()
-- 返回当前系统的 年-月-日 时:分:秒 yyyy-MM-dd HH:mm:ss格式;;推荐使用now()简便
4:utc_date()
-- 返回utc(格林尼治标准时间 0时区)日期
5:utc_time()
-- 返回utc(格林尼治标准时间 0时区)时间
6:utc_timestamp()
-- 返回utc(格林尼治标准时间 0时区)日期时间(时间戳)
-- curdate() / current_date()
SELECT CURDATE(), CURRENT_DATE(), CURDATE()+0, CURRENT_DATE()+3, CURRENT_DATE()+13 FROM DUAL;
+------------+----------------+-------------+------------------+-------------------+
| CURDATE() | CURRENT_DATE() | CURDATE()+0 | CURRENT_DATE()+3 | CURRENT_DATE()+13 |
+------------+----------------+-------------+------------------+-------------------+
| 2022-08-21 | 2022-08-21 | 20220821 | 20220824 | 20220834 |
+------------+----------------+-------------+------------------+-------------------+
注:当前年份为2022-08-21;这里的加0则变为 20220821;但后面不管加几都会当成数值进行处理
如:CURRENT_DATE()+10000 变为 20230821 ,显然不是日期进位,当数值进行加法运算
-- curtime() / current_time()
SELECT CURTIME(), CURRENT_TIME(), CURTIME()+0, CURRENT_TIME()+3, CURRENT_TIME()+13 FROM DUAL;
+-----------+----------------+-------------+------------------+-------------------+
| CURTIME() | CURRENT_TIME() | CURTIME()+0 | CURRENT_TIME()+3 | CURRENT_TIME()+13 |
+-----------+----------------+-------------+------------------+-------------------+
| 18:26:56 | 18:26:56 | 182656 | 182659 | 182669 |
+-----------+----------------+-------------+------------------+-------------------+
注:具体规则和获取当前日期一样
-- now() / sysdate() / current_timestamp() / localtime() / localtimestamp()
SELECT NOW(), SYSDATE(), LOCALTIME(), LOCALTIMESTAMP(), CURRENT_TIMESTAMP FROM DUAL;
+-------------------+-------------------+-------------------+-------------------+-------------------+
|NOW() |SYSDATE() |LOCALTIME() |LOCALTIMESTAMP() |CURRENT_TIMESTAMP |
+-------------------+-------------------+-------------------+-------------------+-------------------+
|2022-08-21 18:31:16|2022-08-21 18:31:16|2022-08-21 18:31:16|2022-08-21 18:31:16|2022-08-21 18:31:16|
+-------------------+-------------------+-------------------+-------------------+-------------------+
-- utc_date / utc_time / utc_timestamp()
SELECT UTC_DATE() '0时区日期', UTC_TIME() '0时区日期', UTC_TIMESTAMP() '0时区时间戳' FROM DUAL;
+---------------+---------------+---------------------+
| 0时区日期 | 0时区日期 | 0时区时间戳 |
+---------------+---------------+---------------------+
| 2022-08-21 | 13:12:55 | 2022-08-21 13:12:55 |
+---------------+---------------+---------------------+
获取日期时间函数基本示例
注:now() 和 sysdate()函数的区别
共同点:都是获得当前日期+时间(date + time)
区别:now()在执行开始时值就得到了日期时间,sysdate()在函数执行时动态得到值。
SELECT NOW() "第一次获取", SLEEP(3) "睡眠3秒", NOW() "第二次获取" FROM DUAL;
+---------------------+------------+---------------------+
| 第一次获取 | 睡眠3秒 | 第二次获取 |
+---------------------+------------+---------------------+
| 2022-08-28 16:03:52 | 0 | 2022-08-28 16:03:52 |
+---------------------+------------+---------------------+
SELECT SYSDATE() "第一次获取", SLEEP(3) "睡眠3秒", SYSDATE() "第二次获取" FROM DUAL;
+---------------------+------------+---------------------+
| 第一次获取 | 睡眠3秒 | 第二次获取 |
+---------------------+------------+---------------------+
| 2022-08-28 16:04:22 | 0 | 2022-08-28 16:04:25 |
+---------------------+------------+---------------------+
2:日期与时间戳的转换
1:unix_timestamp()
-- 以unix时间戳的形式返回当前时间。这种方式是时间戳的方式,如这种在JAVA中是Long类型的数值 1661088713
2:unix_timestamp(date)
-- 将时间date(这里就是我们常见的如yyyy-MM-dd HH:mm:ss等等格式)以unix时间戳的形式返回。
3:from_unixtime(timestamp)
-- 将unix时间戳的时间转换为普通格式(yyyy-MM-dd HH:mm:ss)的时间
-- unix_timestamp unix_timestamp / from_unixtime
-- 当前时间为 2022-08-21 21:32:03
SELECT UNIX_TIMESTAMP("2022-08-21 21:31:53"), UNIX_TIMESTAMP(), FROM_UNIXTIME(UNIX_TIMESTAMP()) FROM DUAL;
+---------------------------------------+------------------+---------------------------------+
| UNIX_TIMESTAMP("2022-08-21 21:31:53") | UNIX_TIMESTAMP() | FROM_UNIXTIME(UNIX_TIMESTAMP()) |
+---------------------------------------+------------------+---------------------------------+
| 1661088713 | 1661088723 | 2022-08-21 21:32:03 |
+---------------------------------------+------------------+---------------------------------+
SELECT UNIX_TIMESTAMP("2022/08/21 21:31:53") 'A种方式转换',
UNIX_TIMESTAMP("2022/08/21 21##31##53") 'B种方式转换',
UNIX_TIMESTAMP("2022/08/21 21 31 53") 'C种方式转换' FROM DUAL;
+------------------+------------------+------------------+
| A种方式转换 | B种方式转换 | C种方式转换 |
+------------------+------------------+------------------+
| 1661088713 | 1661088713 | 0.000000 |
+------------------+------------------+------------------+
注:按照我们日常写的日期转换即可,特殊的格式会转换为0.000000
日期与时间戳的转换基本示例
3:获取月份、星期、星期数、天数等函数
1:year(date) / month(date) / day(date)
-- 根据传入的日期信息返回 年、月、日信息(分别对应上面三个函数);可以使用 curdate() 函数获取当前日期
2:hour(time) / minute(time) / second(time)
-- 根据传入的时间信息返回 时、分、秒信息(分别对应上面三个函数);可以使用 curtime() 函数获取当前日期
3:monthname(date) / dayname(date)
-- 根据传入的日期信息返回英文形式的 月份、星期(分别对应上面的两个函数)
-- 一月 ~ 十二月:January,February,March,April,May,June,July,August,September,October,November,December
-- 周一 ~ 周日: Monday,Tuesday,Wednesday,Thursday,Friday,Saturday,Sunday
4:dayofyear(date)
-- 根据传入的日期返回当前所在年份的第几天
5:dayofmonth(date)
-- 根据传入的日期返回当前所在月份的第几天
6:dayofweek(date)
-- 根据传入的日期返回当前是周几,按照 周日是1、周一是2 ... 周六是7
7:weekday(date)
-- 根据传入的日期返回当前是周几,按照 周一是0、周二是1 ... 周日是6
8:week(date) / weekofyear(date)
-- 根据传入的日期返回当前是一年中的第几周
9:quarter(date)
-- 根据传入的日期返回当前是第几季度(1~4季度;1、2、3为第一季度)
10:date(expr)
-- 返回传入时间的年-月-日;比如传入年月日时分秒则返回年月日
-- year(date) / month(date) / day(date)
SELECT YEAR("2022-08-24"), MONTH("2022-08-24"), DAY("2022-08-24") FROM DUAL;
+--------------------+---------------------+-------------------+
| YEAR("2022-08-24") | MONTH("2022-08-24") | DAY("2022-08-24") |
+--------------------+---------------------+-------------------+
| 2022 | 8 | 24 |
+--------------------+---------------------+-------------------+
-- hour(time) / minute(time) / second(time)
SELECT HOUR("11:30:22"), MINUTE("11:30:22"), SECOND("11:30:22") FROM DUAL;
+------------------+--------------------+--------------------+
| HOUR("11:30:22") | MINUTE("11:30:22") | SECOND("11:30:22") |
+------------------+--------------------+--------------------+
| 11 | 30 | 22 |
+------------------+--------------------+--------------------+
-- monthname(date) / dayname(date)
SELECT MONTHNAME("2022-08-24"), DAYNAME("2022-08-24") FROM DUAL;
+-------------------------+-----------------------+
| MONTHNAME("2022-08-24") | DAYNAME("2022-08-24") |
+-------------------------+-----------------------+
| August | Wednesday |
+-------------------------+-----------------------+
-- dayofyear(date) / dayofmonth(date) / dayofweek(date)
SELECT DAYOFYEAR("2022-08-24"), DAYOFMONTH("2022-08-24"), DAYOFWEEK("2022-08-24") FROM DUAL;
+-------------------------+--------------------------+-------------------------+
| DAYOFYEAR("2022-08-24") | DAYOFMONTH("2022-08-24") | DAYOFWEEK("2022-08-24") |
+-------------------------+--------------------------+-------------------------+
| 236 | 24 | 4 |
+-------------------------+--------------------------+-------------------------+
-- quarter(date) / week(date) / weekofyear(date) / weekday(date)
SELECT QUARTER("2022-08-24"), WEEK("2022-08-24"),WEEKOFYEAR("2022-08-24"),WEEKDAY("2022-08-24") FROM DUAL;
+-----------------------+--------------------+--------------------------+-----------------------+
| QUARTER("2022-08-24") | WEEK("2022-08-24") | WEEKOFYEAR("2022-08-24") | WEEKDAY("2022-08-24") |
+-----------------------+--------------------+--------------------------+-----------------------+
| 3 | 34 | 34 | 2 |
+-----------------------+--------------------+--------------------------+-----------------------+
-- date
SELECT DATE("2022-08-12 15:53:22") FROM DUAL;
+-----------------------------+
| DATE("2022-08-12 15:53:22") |
+-----------------------------+
| 2022-08-12 |
+-----------------------------+
获取月份、星期、星期数、天数等函数基本示例
4:日期的操作函数
1:extract(type from date)
-- 根据传入的type类型和date日期返回给定的日期格式数据,type类型请参考如下表: 【类型含义】type取值 预期的EXPR格式
【微秒】MICROSECOND MICROSECONDS
【秒】SECOND SECONDS
【分】MINUTE MINUTES
【时】HOUR HOURS
【天】DAY DAYS
【周】WEEK WEEKS
【月】MONTH MONTHS
【季度】QUARTER QUARTERS
【年】YEAR YEARS
【####### 一些自动组合方式 1秒=1000毫秒=10000000微秒 #######】
【秒_微秒】SECOND_MICROSECOND SECONDS.MICROSECONDS
【分_微秒】MINUTE_MICROSECOND MINUTES.MICROSECONDS
【分_秒】MINUTE_SECOND MINUTES:SECONDS
【时_微秒】HOUR_MICROSECOND HOURS.MICROSECONDS
【时_秒】HOUR_SECOND HOURS:MINUTES:SECONDS
【时_分】HOUR_MINUTE HOURS:MINUTES
【天_微秒】DAY_MICROSECOND DAYS.MICROSECONDS
【天_秒】DAY_SECOND DAYS HOURS:MINUTES:SECONDS
【天_分】DAY_MINUTE DAYS HOURS:MINUTES
【天_时】DAY_HOUR DAYS HOURS
【年_月】YEAR_MONTH YEARS-MONTHS
SELECT EXTRACT(MINUTE_SECOND FROM '2022-08-28 10:46:28:566:2564855') '【分_秒】',
EXTRACT(HOUR_MINUTE FROM '2022-08-28 10:46:28:566:2564855') '【时_分】',
EXTRACT(DAY_MINUTE FROM '2022-08-28 10:46:28:566:2564855') '【天_分】',
EXTRACT(HOUR FROM '2022-08-28 10:46:28:566:2564855') '【时】'
FROM DUAL;
+---------------+---------------+---------------+-----------+
| 【分_秒】 | 【时_分】 | 【天_分】 | 【时】 |
+---------------+---------------+---------------+-----------+
| 4628 | 1046 | 281046 | 10 |
+---------------+---------------+---------------+-----------+
日期的操作函数基本示例
5:时间和秒数转换函数
1:time_to_sec(time)
-- 把传入的time时间转换为秒钟;计算公式:小时*3600 + 分钟*60 + 秒
2:sec_to_time(seconds)
-- 将seconds描述转化为包时分秒的时间格式
SELECT TIME_TO_SEC("2022-08-28 11:51:22") "时间转秒数", SEC_TO_TIME(120) FROM DUAL;
+-----------------+------------------+
| 时间转秒数 | SEC_TO_TIME(120) |
+-----------------+------------------+
| 42682 | 00:02:00 |
+-----------------+------------------+
时间和秒数转换的基本示例
6:计算日期和时间的函数
说明:
date:是一个datetime或者date值,用来指定起始时间
expr:是一个表达式,用来指定起始日期添加或减去的时间值间隔,它可以是一个字符串数字或者负数
type:是一个关键字,它指示了表达式被解释的方式(请参考 “日期的操作函数” 里的type取值列表)
1:date_add(date, interval expr type) / adddate(date,interval expr type)
-- 返回与给定日期时间相差interval时间段的日期时间(日期加法,在给定日期累计给定的时间)
2:date_sub(date,interval expr type) / subdate(date,interval expr type)
-- 返回与date相差interval时间间隔的日期(日期减法,在给定日期减去给定的时间)
3:period_add(month,add)
-- 返回对month做增减的操作结果,month的格式为yyMM或者yyyyMM,返回的都是yyyyMM格式的结果,add可以传负值
4:adddate(time,days)
-- 和第一个用法差不多,只是简写2个参数的在给定的日期加上指定天数
5:subdate(time,days)
-- 和第二个用法差不多,只是简写2个参数的在给定的日期减去指定天数
6:addtime(time1,time2)
-- 返回time1加上time2的时间。当time2为一个数字时,代表的是秒 ,可以为负数
7:subtime(time1,time2)
-- 返回time1减去time2后的时间。当time2为一个数字时,代表的是秒 ,可以为负数
8:datediff(date1,date2)
-- 返回date1 - date2的日期中间间隔的天数
9:timediff(time1, time2)
-- 返回time1 - time2的时间中间间隔的时间
10:period_diff(p1,p2)
-- -- 返回p1 - p2的日期中间间隔的年月分(注:p1,p2的格式为yyMM或者yyyyMM)
-- date_add / adddate / date_sub / subdate
SELECT
DATE_ADD("2022-08-28 12:03:22", INTERVAL 4 DAY) "加4天",
ADDDATE("2022-08-28 12:03:22", INTERVAL 4 MINUTE) "加4分",
DATE_SUB("2022-08-28 12:03:22", INTERVAL 1 YEAR) "减1年",
SUBDATE("2022-08-28 12:03:22",INTERVAL 20 MINUTE) "减20分"
FROM DUAL;
+---------------------+---------------------+---------------------+---------------------+
| 加4天 | 加4分 | 减1年 | 减20分 |
+---------------------+---------------------+---------------------+---------------------+
| 2022-09-01 12:03:22 | 2022-08-28 12:07:22 | 2021-08-28 12:03:22 | 2022-08-28 11:43:22 |
+---------------------+---------------------+---------------------+---------------------+
-- period_add (只能对年月进行加减,负数则代表减)
SELECT PERIOD_ADD(202208,4) "2022年8月加4月", PERIOD_ADD(202208,5) "2022年8月加5月" FROM DUAL;
+--------------------+--------------------+
| 2022年8月加4月 | 2022年8月加5月 |
+--------------------+--------------------+
| 202212 | 202301 |
+--------------------+--------------------+
-- adddate / subdate
SELECT ADDDATE("2022-08-28", 3), SUBDATE("2022-08-28",29) FROM DUAL;
+--------------------------+--------------------------+
| ADDDATE("2022-08-28", 3) | SUBDATE("2022-08-28",29) |
+--------------------------+--------------------------+
| 2022-08-31 | 2022-07-30 |
+--------------------------+--------------------------+
-- addtime / subtime
SELECT ADDTIME("2022-08-28 12:03:22", "12:30:00") "增加12个小时30分钟",
ADDTIME("2022-08-28 12:03:22", 20) "增加20秒",
SUBTIME("2022-08-28 12:03:22", "10:30:00") "减10个小时30分钟",
SUBTIME("2022-08-28 12:03:22", 24) "减24秒"
FROM DUAL;
+---------------------------+---------------------+------------------------+---------------------+
| 增加12个小时30分钟 | 增加20秒 | 减10个小时30分钟 | 减24秒 |
+---------------------------+---------------------+------------------------+---------------------+
| 2022-08-29 00:33:22 | 2022-08-28 12:03:42 | 2022-08-28 01:33:22 | 2022-08-28 12:02:58 |
+---------------------------+---------------------+------------------------+---------------------+
-- datediff / timediff
SELECT
DATEDIFF("2022-08-30" , "2022-08-28") "间隔整数",
DATEDIFF("2022-08-28" , "2022-08-29") "间隔负数",
TIMEDIFF("10:22:20" , "05:22:20") "间隔时间整数",
TIMEDIFF("10:22:20" , "11:40:40") "间隔时间负数"
FROM DUAL
+--------------+--------------+--------------------+--------------------+
| 间隔整数 | 间隔负数 | 间隔时间整数 | 间隔时间负数 |
+--------------+--------------+--------------------+--------------------+
| 2 | -1 | 05:00:00 | -01:18:20 |
+--------------+--------------+--------------------+--------------------+
-- period_diff
SELECT PERIOD_DIFF(202208,202209) , PERIOD_DIFF(202209,202201) FROM DUAL;
+----------------------------+----------------------------+
| PERIOD_DIFF(202208,202209) | PERIOD_DIFF(202209,202201) |
+----------------------------+----------------------------+
| -1 | 8 |
+----------------------------+----------------------------+
计算日期和时间函数1~10基本示例
11:from_days(n)
-- 返回从0000年1月1日起,n天以后的日期
12:to_days(date)
-- 返回日期date距离0000年1月1日的天数
13:last_day(date)
-- 返回date所在月份的最后一天的日期
14:makedate(year,dayofyear)
-- 给出年份值和要增加的天数值,返回一个日期。dayofyear必须大于 0 ,否则结果为NULL
15:maketime(hour,minute,second)
-- 返回由hour、 minute和second 参数组合得出的时间值。就是传入时分秒生成时间
-- from_days / to_days
SELECT TO_DAYS("2022-08-28"), FROM_DAYS(738760), FROM_DAYS(366) FROM DUAL;
+-----------------------+-------------------+----------------+
| TO_DAYS("2022-08-28") | FROM_DAYS(738760) | FROM_DAYS(366) |
+-----------------------+-------------------+----------------+
| 738760 | 2022-08-28 | 0001-01-01 |
+-----------------------+-------------------+----------------+
-- last_day
SELECT LAST_DAY("2022-08-28"), LAST_DAY("2022-02-28") FROM DUAL;
+------------------------+------------------------+
| LAST_DAY("2022-08-28") | LAST_DAY("2022-02-28") |
+------------------------+------------------------+
| 2022-08-31 | 2022-02-28 |
+------------------------+------------------------+
-- makedate / maketime
SELECT MAKEDATE(2022,251), MAKEDATE(2022,0), MAKETIME(13, 43, 22), MAKETIME(20, 59, 59) FROM DUAL;
+--------------------+------------------+----------------------+----------------------+
| MAKEDATE(2022,251) | MAKEDATE(2022,0) | MAKETIME(13, 43, 22) | MAKETIME(20, 59, 59) |
+--------------------+------------------+----------------------+----------------------+
| 2022-09-08 | NULL | 13:43:22 | 20:59:59 |
+--------------------+------------------+----------------------+----------------------+
计算日期和时间函数11~15基本示例
7:日期的格式化与解析
1:date_format(date,format)
-- 根据format字符串定义的格式返回指定的格式时间
2:time_format(time,format)
-- 与date_format用法相同,但是不能获取到年月日,只能获取时分秒
3:get_format({DATE|TIME|DATETIME}, {'EUR'|'USA'|'JIS'|'ISO'|'INTERNAL'})
-- 返回日期字符串的显示格式,在实际中用到机会的比较少;下面是全部的用法示例
select get_format(date,'usa') ; -- '%m.%d.%Y'
select get_format(date,'jis') ; -- '%Y-%m-%d'
select get_format(date,'iso') ; -- '%Y-%m-%d'
select get_format(date,'eur') ; -- '%d.%m.%Y'
select get_format(date,'internal') ; -- '%Y%m%d'
select get_format(datetime,'usa') ; -- '%Y-%m-%d %H.%i.%s'
select get_format(datetime,'jis') ; -- '%Y-%m-%d %H:%i:%s'
select get_format(datetime,'iso') ; -- '%Y-%m-%d %H:%i:%s'
select get_format(datetime,'eur') ; -- '%Y-%m-%d %H.%i.%s'
select get_format(datetime,'internal'); -- '%Y%m%d%H%i%s'
select get_format(time,'usa') ; -- '%h:%i:%s %p'
select get_format(time,'jis') ; -- '%H:%i:%s'
select get_format(time,'iso') ; -- '%H:%i:%s'
select get_format(time,'eur') ; -- '%H.%i.%s'
select get_format(time,'internal') ; -- '%H%i%s'
4:str_to_date(str, format)
-- 按照字符串format对str进行解析,解析为一个日期
-- 时间格式化说明符
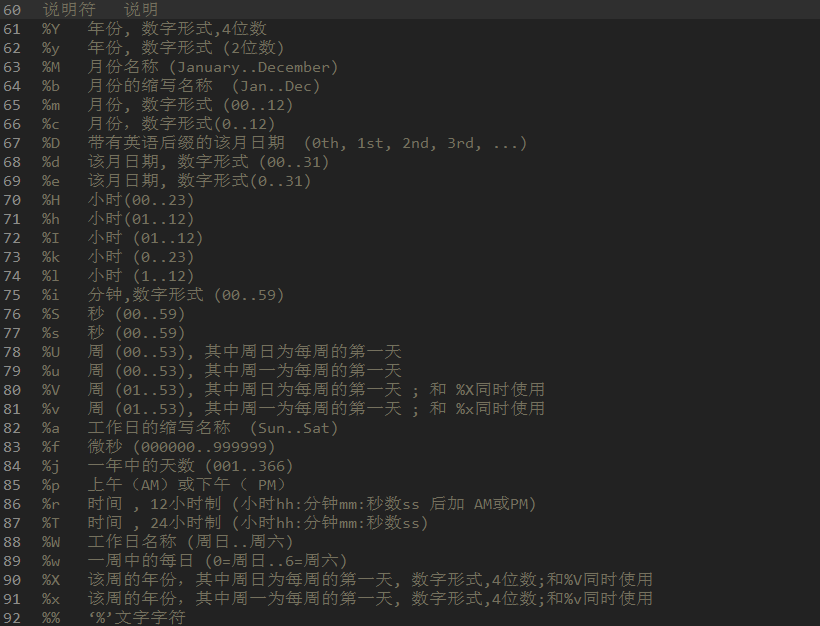
-- date_format
SELECT DATE_FORMAT("2022-08-28 15:15:25", '年份 %Y/%m/%e 时间 %r 或 %H/%i/%s 月份:%M') FROM DUAL;
+---------------------------------------------------------------------------------------+
| DATE_FORMAT("2022-08-28 15:15:25",'年份 %Y/%m/%e 时间 %r 或 %H/%i/%s 月份:%M') |
+---------------------------------------------------------------------------------------+
| 年份 2022/08/28 时间 03:15:25 PM 或 15/15/25 月份:August |
+---------------------------------------------------------------------------------------+
-- time_format
SELECT TIME_FORMAT("2022-08-28 15:15:25","年份 %Y/%m/%e 时间 %r") FROM DUAL;
+----------------------------------------------------------------+
| TIME_FORMAT("2022-08-28 15:15:25","年份 %Y/%m/%e 时间 %r") |
+----------------------------------------------------------------+
| 年份 0000/00/0 时间 03:15:25 PM |
+----------------------------------------------------------------+
-- get_format()
SELECT DATE_FORMAT(NOW(),GET_FORMAT(DATE,'USA')) FROM DUAL;
+-------------------------------------------+
| DATE_FORMAT(NOW(),GET_FORMAT(DATE,'USA')) |
+-------------------------------------------+
| 08.28.2022 |
+-------------------------------------------+
-- str_to_date
SELECT STR_TO_DATE("年份 2022/08/28 时间 03:15:25 PM","年份 %Y/%m/%e 时间 %r") FROM DUAL;
+---------------------------------------------------------------------------------+
| STR_TO_DATE("年份 2022/08/28 时间 03:15:25 PM","年份 %Y/%m/%e 时间 %r") |
+---------------------------------------------------------------------------------+
| 2022-08-28 15:15:25 |
+---------------------------------------------------------------------------------+
日期的格式化与解析基本示例
五:流程控制函数
流程处理函数可以根据不同的条件,执行不同的处理流程,可以在SQL语句中实现不同的条件选择。MySQL中的流程处理函数主要包括IF()、IFNULL()和CASE()函数。
1:if(expr1,expr2,expr3)
-- expr1是条件,满足true条件则必须(expr1 <> 0 and expr1 <> NULL),否则一律为假false,真执行expr2假执行expr3
-- 注:if()函数用于条件比较;字符串或数字非0非NULL则为真;其它字符串英文、汉字等等都为false
2:ifnull(expr1,expr2)
-- 假如expr1不为NULL,则IFNULL()的返回值为expr1; 否则其返回值为expr2。
-- 注:IFNULL()的返回值是数字或是字符串,具体情况取决于其所使用的语境。
3:nullif()
-- 如果expr1 = expr2成立,那么返回值为NULL,否则返回值为 expr1。
-- 注:这和CASE WHEN expr1 = expr2 THEN NULL ELSE expr1 END相同。
4:case函数:CASE WHEN 条件1 THEN 结果1 WHEN 条件2 THEN 结果2 .... [ELSE resultn] END
-- 相当于Java的if ... else if ... else ...
5:case函数:CASE expr WHEN 常量值1 THEN 值1 WHEN 常量值2 THEN 值2 .... [ELSE 值n] END
-- 相当于Java的switch ... case ...
-- IF测试
SELECT IF(NULL, '真', '假'), IF('1', '真', '假' ), IF('0', '真', '假'), IF(20>10, '真', '假') FROM DUAL;
+------------------------+------------------------+-----------------------+-------------------------+
| IF(NULL, '真', '假') | IF('1', '真', '假' ) | IF('0', '真', '假') | IF(20>10, '真', '假') |
+------------------------+------------------------+-----------------------+-------------------------+
| 假 | 真 | 假 | 真 |
+------------------------+------------------------+-----------------------+-------------------------+
-- 案例:查询学生表数据学分,达到60分(包含)则为达标,其余则不达标(为了测试我就limit 3)
SELECT sname,ssex,saddress,scredit '当前学分', IF(scredit>=60, '达标', '不达标') FROM student limit 3;
+------------+------+--------------+--------------+---------------------------------+
| sname | ssex | saddress | 当前学分 | IF(scredit>=60, '达标', '不达标') |
+------------+------+--------------+--------------+---------------------------------+
| 王_生安 | 男 | 安徽六安 | 19.0 | 不达标 |
| 李鑫灏 | 女 | 安徽合肥 | 3.0 | 不达标 |
| 薛佛世 | 男 | 安徽蚌埠 | 86.0 | 达标 |
+------------+------+--------------+--------------+---------------------------------+ -- IFNULL测试 注:只要不是NULL就不打印后面
SELECT IFNULL(NULL, '是NULL'), IFNULL('非NULL', '不打印'), IFNULL(0, "不打印") FROM DUAL;
-- 案例:查询学生表地址信息,若为null则置为 "未提供地址"
SELECT sname,saddress "处理前", IFNULL(saddress, '未提供地址') FROM student where saddress IS NULL;
+-----------+-----------+-------------------------------------+
| sname | 处理前 | IFNULL(saddress, '未提供地址') |
+-----------+-----------+-------------------------------------+
| 周迟蒲 | NULL | 未提供地址 |
| 张桥共 | NULL | 未提供地址 |
+-----------+-----------+-------------------------------------+ -- NULLID测试
SELECT NULLIF("真","假"), NULLIF("真","真"), NULLIF("张三","张三"), NULLIF("小红","小白") FROM DUAL;
+---------------------+---------------------+---------------------------+---------------------------+
| NULLIF("真","假") | NULLIF("真","真") | NULLIF("张三","张三") | NULLIF("小红","小白") |
+---------------------+---------------------+---------------------------+---------------------------+
| 真 | NULL | NULL | 小红 |
+---------------------+---------------------+---------------------------+---------------------------+ -- CASE函数测试
-- 第一种方式:相当于Java的if...else if...else...
## 查询ID为1,3,4的老师下的全部学生信息;
## 若是在ID为1的老师下学生学分大于等于50则零花钱加100
## 若是在ID为3的老师下学生学分大于等于30则零花钱加200
## 若是在ID为4的老师下学生学分大于等于20则零花钱加300
SELECT t.tname,t.tid,s.sname,s.ssex,s.sage,s.scredit,s.smoney '处理前零花钱',
-- CASE开始
CASE
WHEN t.tid = 1 AND s.scredit >= 50 then IFNULL(s.smoney,0)+100
WHEN t.tid = 3 AND s.scredit >= 30 then IFNULL(s.smoney,0)+200
WHEN t.tid = 4 AND s.scredit >= 20 then IFNULL(s.smoney,0)+300
ELSE '不满足条件'
END
-- CASE结束
AS '处理过后的零花钱' -- 对处理后的字段别名
FROM
teacher t LEFT JOIN student s USING ( tid )
+-----------+-----+------------+------+------+---------+--------------------+--------------------------+
| tname | tid | sname | ssex | sage | scredit | 处理前零花钱 | 处理过后的零花钱 |
+-----------+-----+------------+------+------+---------+--------------------+--------------------------+
| 张老师 | 1 | 李鑫灏 | 女 | 21 | 3.0 | 74.1 | 不满足条件 |
| 张老师 | 1 | 钱勤堃 | 女 | 23 | 8.0 | 101.7 | 不满足条件 |
| 孙老师 | 4 | 张棉党 | 女 | 23 | 32.0 | 384.4 | 684.4 |
| 孙老师 | 4 | 张 婷 | 女 | 23 | 91.0 | 36.5 | 336.5 |
| 王老师 | 3 | 萧百徽 | 女 | 22 | 98.0 | 884.6 | 1084.6 |
| 孙老师 | 4 | 路党拓 | 男 | 22 | 53.0 | 485.8 | 785.8 |
+-----------+-----+------------+------+------+---------+--------------------+--------------------------+
-- 第二种方式:相当于Java的switch...case...
## 查询老师表中全部信息,若ID为1则设置:"金牌讲师";若ID为3则设置:"银牌讲师";其它默认:"普通讲师"
SELECT tid,tname,
-- CASE开始
CASE tid
WHEN 1 then '金牌讲师'
WHEN 3 then '银牌讲师'
ELSE '普通讲师'
END
-- CASE结束
AS '讲师情况' FROM teacher;
+-----+-----------+--------------+
| tid | tname | 讲师情况 |
+-----+-----------+--------------+
| 1 | 张老师 | 金牌讲师 |
| 2 | 李老师 | 普通讲师 |
| 3 | 王老师 | 银牌讲师 |
| 4 | 孙老师 | 普通讲师 |
+-----+-----------+--------------+
流程控制函数基本示例
六:加密解密函数
加密与解密函数主要用于对数据库中的数据进行加密和解密处理,以防止数据被他人窃取。这些函数在保证数据库安全时非常有用。不过在实际的项目开发中我们并不会让数据库来对数据进行加密或解密,我们通常在后端程序就用了代码的方式对敏感信息进行加密解密了,因为在后端服务到数据库服务这中间存在Http交互,若这时的交互被窃取到则明文信息很有可能泄露。
1:password(str)
-- 返回字符串str的加密版本,41位长的字符串;加密过程是不可逆转的,常用于用户的密码加密,和UNIX密码加密使用不同的算法
2:md5(str)
-- 返回字符串str的md5加密后的值,也是一种加密方式。若参数为NULL,则会返回NULL
3:SHA(str) / SHA1(str)
-- 从原明文密码str计算并返回加密后40位长的密码字符串,当参数为NULL时,返回NULL。SHA加密算法比MD5更加安全。
4:SHA2(str,256) / SHA2(str,512)
-- 也是加密方式,分别是SHA256和SHA512加密方式,但SHA256返回64位字符串,SHA512返回128位字符串
-- 注:可以使用UNHEX(SHA2(str,256))返回32位;UNHEX(SHA2(str,512))返回64位
5:ENCRYPT(str[,salt])
-- 使用UNIX crypt()系统加密字符串,ENCRYPT()函数接收要加密的字符串str和
-- (可选的)用于加密过程的salt(一个可以唯一确定口令的字符串,就像钥匙一样),注意,windows上不支持
1:存储密码字段最好使用varchar、varbinary、binary、blob
2:使用UNHEX(SHA2("xx",256))、UNHEX(SHA2("xx",512))使用blob字段类型存储这样可以通过这个字段查询方便
###### 基本准备 ######
-- 创建表结构
CREATE TABLE `test_table` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键ID',
`name` varchar(20) DEFAULT NULL COMMENT '昵称',
`password` varchar(50) DEFAULT NULL COMMENT '密码',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
-- 添加数据(添加数据库的数据就是加密的)
INSERT INTO `test_table` (`name`,`password`)values("测试PASSWORD",PASSWORD("xiao54088"));
INSERT INTO `test_table` (`name`,`password`)values("测试MD5",MD5("xiao54088"));
INSERT INTO `test_table` (`name`,`password`)values("测试SHA",SHA("xiao54088"));
INSERT INTO `test_table` (`name`,`password`)values("测试SHA1",SHA1("xiao54088"));
-- 查询数据
SELECT * FROM test_table;
+----+----------------+-------------------------------------------+
| id | name | password |
+----+----------------+-------------------------------------------+
| 1 | 测试PASSWORD | *3509F4F18C3AA86593A78A74A87CF38DAC344737 |
| 2 | 测试MD5 | 43d229a1097e6c7b1fd1f8843f7a09f8 |
| 3 | 测试SHA | 6371b0d031a97db97e67970e02d85612c22fefb1 |
| 4 | 测试SHA1 | 6371b0d031a97db97e67970e02d85612c22fefb1 |
+----+----------------+-------------------------------------------+
#######################
基本建表语句准备
-- PASSWORD 、 MD5
SELECT * FROM test_table where password = PASSWORD("xiao54088")
SELECT * FROM test_table where password = MD5("xiao54088")
-- 因为SHA1和SHA是一样的,所有也可以查出2条
SELECT * FROM test_table where password = SHA("xiao54088")
SELECT * FROM test_table where password = SHA1("xiao54088")
加密解密函数1~5基本示例
-- 重要!!!
通常有这样的需求:需要加密保存下一些敏感数据,像密码、身份证号之类,但是又想要有方法能够还原出来。
因此就需要双向加密了,像上面学习的那5种是单纯的单向加密,无法反推加密之前的信息;下面我们将学习2组加密解密函数
-- 注:推荐使用ASE方式
1:aes_encrypt(str,key_str)
-- 使用AES加密方式;返回使用key_str作为加密的盐来加密要加密的str信息
2:aes_decrypt(crypt_str,key_str)
-- 使用AES解密方式;返回使用key_str作为解密的盐来解密被加密的crypt_str信息
3:encode(str,pass_str)
-- 返回使用pass_str作为加密密码加密str
4:decode(crypt_str,pass_str)
-- 返回使用pass_str作为加密密码解密crypt_str 注:使用上面的加密函数时不能直接把加密的密文存放在varchar类型的字段中并且字符集是UTF8的环境下,
这样会造成把取出来的信息解密后会出现NULL信息 正确使用方式:
将字段属性类型设置为varbinary、binary、四种blob类型(一个六种方式的字段类型里)
其中varbinary、binary的类型长度取决于明文的长度,此处明文较短,故只给了16。 注:但是我们还是想把数据存储在varchar、char类型种我们则必须对加密的数据使用HEX()来存入,用UNHEX()取出。
HEX()和UNHEX()函数前面说到是对传入的信息十六进制转化和反十六进制转回来
SELECT HEX(AES_ENCRYPT("xiao","#%$%^B%")) "加密",
AES_DECRYPT(UNHEX("888FD7CB0993078CA3A8C16F2248E769"),"#%$%^B%") "解密"
SELECT HEX(ENCODE("xiao","#%$%^B%")) "加密",
DECODE(UNHEX("872CF32F"),"#%$%^B%") "解密" 注:如果直接把加密后的密文存入varchar中并且是UTF8环境,不做十六进制化。那么上面说的是转化过来为NULL,
但是我们把字符集改成latin1就可以了;但可能会带来隐患
【许多加密和压缩函数返回结果可能包含任意字节值的字符串。如果要存储这些结果,请使用具有 VARBINARY 或 BLOB 二进制字
符串数据类型的列。这将避免尾随空格删除或字符集转换可能会更改数据值的潜在问题,例如,如果您使用非二进制字符串数据类型
(CHAR、VARCHAR、TEXT)可能会出现这些问题。】
-- 创建表结果和创建表数据
CREATE TABLE `test_table2` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(20) NOT NULL,
`password1` varbinary(16) NOT NULL,
`password2` binary(16) NOT NULL,
`password3` blob NOT NULL,
`password4` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=7 DEFAULT CHARSET=utf8;
INSERT INTO `test_table2` (`name`,`password1`,`password2`,`password3`) VALUES
("测试AES加密",AES_ENCRYPT("xiao","$RF%&T"),AES_ENCRYPT("xiao","$RF%&T"),AES_ENCRYPT("xiao","$RF%&T"));
INSERT INTO `test_table2` (`name`,`password1`,`password2`,`password3`) VALUES
("测试普通ENCODE加密",ENCODE("xiao","$RF%&T"),ENCODE("xiao","$RF%&T"),ENCODE("xiao","$RF%&T"));
-- 查询数据
SELECT AES_DECRYPT(password1,"$RF%&T"), AES_DECRYPT(password2,"$RF%&T"),AES_DECRYPT(password3,"$RF%&T")
FROM test_table2 WHERE name= "测试AES加密"
+---------------------------------+---------------------------------+---------------------------------+
| AES_DECRYPT(password1,"$RF%&T") | AES_DECRYPT(password2,"$RF%&T") | AES_DECRYPT(password3,"$RF%&T") |
+---------------------------------+---------------------------------+---------------------------------+
| xiao | xiao | xiao |
+---------------------------------+---------------------------------+---------------------------------+
SELECT DECODE(password1,"$RF%&T"), DECODE(password2,"$RF%&T"),DECODE(password3,"$RF%&T")
FROM test_table2 WHERE name= "测试普通ENCODE加密"
+----------------------------+----------------------------+----------------------------+
| DECODE(password1,"$RF%&T") | DECODE(password2,"$RF%&T") | DECODE(password3,"$RF%&T") |
+----------------------------+----------------------------+----------------------------+
| xiao | xiaosuÚp >ï | xiao |
+----------------------------+----------------------------+----------------------------+
-- 注:可以看出在使用binary类型的字段来存储ENCODE加密的信息可能会出现问题
加密解密使用可逆方式基本示例
public class Test {
public static void main(String[] args) {
//待加密的字符串
String str = "蚂蚁小哥 Very Good";
//消息摘要算法的功能对象
MessageDigest messageDigest;
try {
//拿到一个SHA1转换器(如果想要MD5参数换成”MD5”)
messageDigest = MessageDigest.getInstance("SHA1");
//使用我们传入的字节数组进行更新摘要。
messageDigest.update(str.getBytes());
//转换(就是加密)并返回结果,也是字节数组,包含16个元素
byte[] b_itr1 = messageDigest.digest();
//把转换(加密)的字符数组转换成字符串返回
String s_itr1 = getFormattedText(b_itr1);
System.out.println("\""+str+"\" 第一次SHA1加密结果:"+s_itr1.toUpperCase());
//二次加密 SHA1( SHA1(xxx) ) MySQL的PASSWORD(str)函数就是2次加密
//messageDigest.update(s_itr1.getBytes());
messageDigest.update(b_itr1);
byte[] b_itr2 = messageDigest.digest();
String s_itr2 = getFormattedText(b_itr2);
System.out.println("\""+str+"\" 第二次SHA1加密结果:"+s_itr2.toUpperCase());
} catch (NoSuchAlgorithmException e) {
System.out.println(e.getMessage());
}
// 执行结果
//"蚂蚁小哥 Very Good" 第一次SHA1加密结果:D651646B4DFAF82C13BF26B2F926501C2ADEBB63
//"蚂蚁小哥 Very Good" 第二次SHA1加密结果:2DF50E2D3A4B4DF5FAB532E656CC92A50FC52709
}
/***
* 使用可变字符串方式完成 StringBuilder
* @param bytes 加密后字节
* @return 返回加密后的字符串
*/
private static String getFormattedText(byte[] bytes) {
//首先初始化一个字符数组,用来存放每个16进制字符(建议使用常量)
char[] hexDigits = {'0','1','2','3','4','5','6','7','8','9','a','b','c','d','e','f'};
//创建可变字符串对象,这个就是用来组成结果字符串的
StringBuilder buf = new StringBuilder(bytes.length * 2);
// 把密文转换成十六进制的字符串形式
for (byte aByte : bytes) {
buf.append(hexDigits[(aByte >> 4) & 0x0f]);
buf.append(hexDigits[aByte & 0x0f]);
}
return buf.toString();
}
/***
* 使用字符数组方式完成 char[]
* @param bytes 加密后字节
* @return 返回加密后的字符串
*/
private static String getFormattedText2(byte[] bytes){
//首先初始化一个字符数组,用来存放每个16进制字符(建议使用常量)
char[] hexDigits = {'0','1','2','3','4','5','6','7','8','9','a','b','c','d','e','f'};
//new一个字符数组,这个就是用来组成结果字符串的
//(解释一下:一个byte是八位二进制,也就是2位十六进制字符(2的8次方等于16的2次方))
char[] charArray =new char[bytes.length * 2];
// 遍历字节数组,通过位运算(位运算效率高),转换成字符放到字符数组中去
int index = 0;
for (byte b : bytes) {
charArray[index++] = hexDigits[b>>> 4 & 0xf];
charArray[index++] = hexDigits[b& 0xf];
}
//字符数组组合成字符串返回
return new String(charArray);
}
}
使用JAVA方式实现PASSWORD(str)函数的实现
七:MySQL信息函数
MySQL中内置了一些可以查询MySQL信息的函数,这些函数主要用于帮助数据库开发或运维人员更好地对数据库进行维护工作
1:version()
-- 返回当前mysql的版本号
2:connection_id()
-- 返回当前mysql服务器的连接数
3:database() / schema()
-- 返回mysql命令行当前所在的数据库
5:user() / current_user() / system_user() / session_user()
-- 返回当前连接mysql的用户名,返回结果格式为 “主机名@用户名”
6:charset(value)
-- 返回字符串value自变量的字符集(主要看当前系统的字符集或者数据库表的字符集)
7:collation(value)
-- 返回字符串value的比较规则;因为比较字符串和数值的比较方式不同
-- version / connection_id / schema
SELECT VERSION() "当前数据库版本号", CONNECTION_ID() "当前数据库连接数",
DATABASE() "当前使用的数据库", SCHEMA() "当前使用的数据库"
FROM DUAL
+----------------------+----------------------+----------------------+----------------+
| 当前数据库版本号 | 当前数据库连接数 | 当前使用的数据库 | 当前使用的数据库 |
+----------------------+----------------------+----------------------+----------------+
| 5.7.35-log | 3 | demo_school | demo_school |
+----------------------+----------------------+----------------------+----------------+
-- user() / current_user() / system_user() / session_user()
SELECT "当前MySQL的连接用户", USER(), CURRENT_USER(), SYSTEM_USER(), SESSION_USER() FROM DUAL;
+--------------------------+----------------+----------------+----------------+----------------+
| 当前MySQL的连接用户 | USER() | CURRENT_USER() | SYSTEM_USER() | SESSION_USER() |
+--------------------------+----------------+----------------+----------------+----------------+
| 当前MySQL的连接用户 | root@localhost | root@localhost | root@localhost | root@localhost |
+--------------------------+----------------+----------------+----------------+----------------+
-- charset
SELECT CHARSET("蚂蚁小哥"),CHARSET("xiao"), CHARSET(CHAR(213,244 using GBK)) FROM DUAL;
+-------------------------+-----------------+----------------------------------+
| CHARSET("蚂蚁小哥") | CHARSET("xiao") | CHARSET(CHAR(213,244 using GBK)) |
+-------------------------+-----------------+----------------------------------+
| utf8 | utf8 | gbk |
+-------------------------+-----------------+----------------------------------+
-- collation
SELECT COLLATION("aaa"), COLLATION(25), COLLATION(25.6) FROM DUAL
+------------------+---------------+-----------------+
| COLLATION("aaa") | COLLATION(25) | COLLATION(25.6) |
+------------------+---------------+-----------------+
| utf8_general_ci | binary | binary |
+------------------+---------------+-----------------+
MySQL信息函数基本示例
八:其它函数
1:inet_aton(ipvalue)
-- 将以点分隔的ip地址转化为一个数字
-- INET_ATON(IP) 函数——把ip转为无符号整型(4-8位)
2:inet_ntoa(value)
-- 将数字形式的ip地址转化为以点分隔的ip地址
-- 注:对于IPv4地址。人们经常使用VARCHAR(15)列去存储IP地址。然而,它们实际上是32位无符号整数,不是字符串。
-- 用小数点将地址分成4段的表示方法只是为了让人们阅读容易。所以应该用无符号整数存储IP地址。
-- MySQL提供了INET_ATON()和INET_NTOA()函数在这两种表示方法之间转换。
-- MySQL 5.6 版本之后,也有了解释IPv6地址的方法,就是INET6_ATON()和INET6_NTOA()函数
-- 村到表是32位无符号整数,取出来时使用inet_ntoa包裹着IP字段并解析
4:benchmark(n,expr)
-- 函数只有两个参数,n是执行次数,expr是要测试的函数或者表达式。返回的结果始终是0,执行时间才是我们需要的结果
-- 用于测试mysql函数的性能的,注意是测试函数的性能
-- 注意:
-- BENCHMARK函数只能测量数字表达式(scalar expression)的性能,虽然说表达式可以是一个子查询,但子查询返回的只能是单个值。
-- 在BENCHMARK(10, (SELECT * FROM t)) 这个语句中,如果t表有多列或是t表中记录多于1行的话这个函数就会执行失败。
-- BENCHMARK函数在执行多次的过程中sql的解析(parser)、优化(optimizer)、锁表(table locking)等操作只会进行一次,
-- 只有运行评估(runtime evaluation)会执行count次。 利用BENCHMARK,mysql就可以自动为我们多次执行表达式计算,
-- 从而获取比较平均的计算结果。
5:convert(expr USING transcoding_name)
-- 将expr所使用的字符编码修改为transcoding_name
-- inet_aton / inet_ntoa
SELECT INET_ATON("192.168.1.9"), INET_NTOA(3232235785) FROM DUAL;
+--------------------------+-----------------------+
| INET_ATON("192.168.1.9") | INET_NTOA(3232235785) |
+--------------------------+-----------------------+
| 3232235785 | 192.168.1.9 |
+--------------------------+-----------------------+
-- benchmark
-- 查看执行1000000次MD5的性能
mysql> SELECT BENCHMARK(1000000,MD5("xiaofeng")) ;
+------------------------------------+
| BENCHMARK(1000000,MD5("xiaofeng")) |
+------------------------------------+
| 0 |
+------------------------------------+
-- 查看执行100000000的子查询性能
mysql> SELECT BENCHMARK(100000000,(SELECT sname FROM student WHERE sid=1)) FROM DUAL;
+--------------------------------------------------------------+
| BENCHMARK(100000000,(SELECT sname FROM student WHERE sid=1)) |
+--------------------------------------------------------------+
| 0 |
+--------------------------------------------------------------+
-- convert
SELECT CONVERT("张三" USING gb2312), CHARSET(CONVERT("张三" USING gb2312)) "当前字串编码" FROM DUAL;
+--------------------------------+--------------------+
| CONVERT("张三" USING gb2312) | 当前字串编码 |
+--------------------------------+--------------------+
| 张三 | gb2312 |
+--------------------------------+--------------------+
其它函数基本示例
九:聚合函数
聚合函数作用于一组数据,并对一组数据返回一个值;如计算数据表中的记录行数的总数、计算某个字段列下数据的总和,以及计算表中某个字段下的最大值、最小值或者平均值。
1:avg(): -- 计算返回某列的平均值;它计算过程中是忽略NULL值的
2:count(): -- 返回某列的行数
3:max(): -- 返回某列的最大值
4:min(): -- 返回某列的最小值
5:sum(): -- 返回某列的和 AVG()和 SUM()
可以对数值型数据使用 AVG 和 SUM 函数来求平均值和统计总和
例:统计全部学生为男生的零花钱和零花钱的平均数
SELECT SUM(smoney) "零花钱总和", AVG(IFNULL(smoney,0)) "平均零花钱", COUNT(*) "总数" FROM student WHERE ssex ="男";
-- 说明:
-- SUM()函数返回一组值的总和,SUM()函数忽略NULL值。如果找不到匹配行,则SUM()函数返回NULL值。
-- AVG()函数返回一组值的平均值,但是注意的是它会剔除NULL值,所以说有30行数据,但是smoney有一个字段为NULL,
-- 那么,它就会按照29行记录数来除于总和来得出平均;所有我上例把为NULL的字段记录数设置为0 MIN()和 MAX()
可以对一列数值型数据使用 MIN 和 MAX 函数来求最小值和最大值
例:统计学生表中学分最高和最低的两位学生
SELECT MAX(scredit) "最高分", MIN(scredit) "最低分" FROM student; COUNT(*) / COUNT(1 ~ ∞) / COUNT(字段)
统计数据表中包含的记录行的总数,或者根据查询结果返回列中包含的数据行数;不过有三种写法,后面具体优化章节说明
例:统计学生表中总记录数,并包含可能为空的字段
SELECT COUNT(*) FROM student; SELECT COUNT(1) FROM student;
例:统计学生表中零花钱不为空的学生(使用字段时会自动过滤空字段值)
SELECT COUNT(smoney) FROM student;
问题:用count(*),count(1),count(列名)谁好呢?
其实,对于MyISAM引擎的表是没有区别的。这种引擎内部有一计数器在维护着行数。
Innodb引擎的表用count(*),count(1)直接读行数,复杂度是O(n),因为innodb真的要去数一遍。但好于具体的count(列名)。
问题:能不能使用count(列名)替换count(*)?
不要使用count(列名)来替代count(*),count(*) 是SQL92定义的标准统计行数的语法,跟数据库无关,跟NULL和非NULL无关。
说明:count(*)会统计值为NULL的行,而count(列名)不会统计此列为NULL值的行。
注:如果使用的是MyISAM存储引擎,则三者效率是相同的,都是O(1);因为MySQL有个字段记录这个表的全部记录行
注:如果使用的是InnoDB存储引擎,则三者效率:COUNT(*)=COUNT(1)>COUNT(字段);推荐使用COUNT(*)
1:GROUP BY分组函数
既然是分组函数,那么就是对查询出来的数据进行一个分组,比如查询一张学生表数据,并按照学生对应的辅导员进行一个分组,并按照分组后的信息进行各自组信息的统计、求最大值、最小值等等,每个组信息统计互不干扰。
SELECT 查询列表 FROM 表1 别名 INNER JOIN 表2 别名 ON 连接条件 WHERE 筛选条件 GROUP BY 分组
HAVING 分组后筛选 ORDER BY 排序列表 LIMIT 起始条目索引,显示的条目数
执行顺序:
1:FROM 查询表是否存在
2:JOIN 多表连接查询
3:ON 多表连接后关联字段对应信息
4:WHERE 筛选出符合条件的数据
5:GROUP BY 对数据进行分组
6:HAVING 对分组好的数据进行再一次条件筛选
7:SELECT 查询指定字段到虚拟表
8:ORDER BY 对数据进行一个排序
9:LIMIT 对数据进行一个分页
基本使用(单列分组):
案例一:查询学生信息并按照辅导员信息进行学生分组,并查询每个辅导员下的学生总数
SELECT t.tname "辅导员", COUNT(*) "学生总数"
FROM teacher t LEFT JOIN student s USING(tid) GROUP BY t.tname 基本使用(多列分组):
案例二:查询学生信息并按照辅导员信息和学生性别进行学生分组,并查询每个辅导员下的男或女学生总数
SELECT t.tname "辅导员", s.ssex "学生性别", COUNT(*) "学生总数"
FROM teacher t LEFT JOIN student s USING(tid) GROUP BY t.tname,s.ssex 基本使用(GROUP BY 中使用 WITH ROLLUP)
WITH ROLLUP:在所有查询出的分组记录之后增加一条记录,该记录计算查询出的所有记录的总和,即统计记录数量。
案例三:查询学生表中全部学生,并按照学生地区进行分组,查询每个地区的零花钱总和和平均值,
并在最后一列计算分组后的零花钱总和的平均值
SELECT saddress "地区", SUM(smoney) "总和", AVG(smoney) "平均值" FROM student GROUP BY saddress WITH ROLLUP
+-------------+---------+-----------+
| 地区 | 总和 | 平均值 |
+-------------+---------+-----------+
| NULL | 782.5 | 782.50000 |
| 安徽六安 | 12870.0 | 536.25000 |
| 安徽合肥 | 8696.4 | 483.13333 |
| 安徽安庆 | 406.2 | 406.20000 |
| 安徽淮南 | 3775.2 | 539.31429 |
| 安徽蚌埠 | 4785.0 | 478.50000 |
| NULL | 31315.3 | 513.36557 |
+--------------+---------+-----------+
注:最后一行是上面全部行数据的信息总和和平均值(主要看那一列的聚合函数是哪个),至于最好一行NULL是代表分组字段不参与计算
注:第一行NULL代表当前表中有地区为NULL的信息,把NULL信息分为一组进行分组
注:当使用WITH ROLLUP时,不能同时使用ORDER BY子句进行结果排序,即WITH ROLLUP和ORDER BY是互相排斥的。 基本使用(GROUP BY 中使用 GROUP_CONCAT拼接相同组字段信息)
案例四:查询学生表中地区为"安徽淮南","安徽蚌埠"学生,并按照学生地区进行分组,并使用一个字段输出当前分组的全部学生姓名
SELECT saddress "地区",GROUP_CONCAT(sname) "拼接相同组学生姓名信息"
FROM student WHERE saddress IN("安徽淮南","安徽蚌埠") GROUP BY saddress;
+--------------+-------------------------------------------------------------------+
| 地区 | 拼接相同组学生姓名信息 |
+--------------+-------------------------------------------------------------------+
| 安徽淮南 | 张顺谷,张悌斯,章晞旺,陆丛枫,张 磊,丘耿徽,池樵霆 |
| 安徽蚌埠 | 薛佛世,张灶冲,孙生笙,饶展林,朱付流,鲁贯栾,严愚贵,龚银桓,区胄法,魏爱來 |
+--------------+-------------------------------------------------------------------+
2:HAVING过滤函数
说到指定条件,我们最先想到的往往是 WHERE 子句,但 WHERE 子句只能指定行的条件,而不能指定组(分过组的数据)的条件因此就有了 HAVING 子句,它用来指定组的条件。
案例:查询学生中每个年龄阶段的零花钱总数,并过滤出金额大于5000的信息
SELECT sage,SUM(smoney) "totalMoney" FROM student GROUP BY sage HAVING totalMoney > 5000
错误写法:
第一个是找不到`totalMoney`字段,因为WHERE执行比SELECT早,所以不存在别名
SELECT sage,SUM(smoney) "totalMoney" FROM student WHERE totalMoney > 5000 GROUP BY sage 错误!
第二个是因为在组函数中无法使用聚合函数,若未被合并为组的字段进行WHERE是可以的,
SELECT sage,SUM(smoney) "totalMoney" FROM student WHERE SUM(smoney) > 5000 GROUP BY sage 错误!
使用HAVING强制要求:
HAVING子句中能够使用三种要素:常数,聚合函数,GROUP BY子句中指定的列名(聚合键)
条件1:如果过滤条件中使用了聚合函数。则必须使用HAVING来替代WHERE,否则报错
条件2:HAVING必须声明在GROUP BY后面
条件3:正常开发中使用HAVING的前提是SQL中使用了GROUP BY,用GROUP BY时不一定有HAVING(它只是一个筛选) 案例:查询学生中年龄为21、23、24阶段的零花钱总数,并过滤出金额大于5000的信息
使用HAVING方式(这种方式不推荐)
SELECT sage,SUM(smoney) "totalMoney" FROM student GROUP BY sage HAVING totalMoney>5000 AND sage IN(21,23,24)
使用WHERE和HAVING方式(推荐)
SELECT sage,SUM(smoney) "totalMoney" FROM student WHERE sage IN(21,23,24) GROUP BY sage HAVING totalMoney>5000
总结:当过滤条件中有聚合函数,则过滤聚合后的字段条件必须声明在HAVING中
当过滤条件中没有聚合函数字段时,则过滤非聚合函数字段条件时,声明在WHERE或HAVING中都可以,但建议声明在WHERE中
使用WHERE和HAVING对比:
区别1:WHERE可以直接使用表中的字段作为筛选条件,但不能使用分组中的计算函数作为筛选条件;而 HAVING 必须要与 GROUP BY 配合使用,可以把分组计算的函数和分组字段作为筛选条件。在需要对数据进行分组统计的时候,HAVING 可以完成 WHERE 不能完成的任务。这是因为,在查询语法结构中,WHERE 在 GROUP BY 之前,所以无法对分组结果进行筛选。HAVING 在 GROUP BY 之后,可以使用分组字段和分组中的计算函数,对分组的结果集进行筛选,这个功能是 WHERE 无法完成的。另外,WHERE排除的记录不再包括在分组中。
区别2:如果需要通过连接从关联表中获取需要的数据,WHERE 是先筛选后连接,而 HAVING 是先连接后筛选。这一点,就决定了在关联查询中,WHERE 比 HAVING 更高效。因为 WHERE 可以先筛选,用一个筛选后的较小数据集和关联表进行连接,这样占用的资源比较少,执行效率也比较高。HAVING 则需要先把结果集准备好,也就是用未被筛选的数据集进行关联,然后对这个大的数据集进行筛选,这样占用的资源就比较多,执行效率也较低。
开发中的选择:WHERE 和 HAVING 也不是互相排斥的,我们可以在一个查询里面同时使用 WHERE 和 HAVING。包含分组统计函数的条件用 HAVING,普通条件用 WHERE。这样,我们就既利用了 WHERE 条件的高效快速,又发挥了 HAVING 可以使用包含分组统计函数的查询条件的优点。当数据量特别大的时候,运行效率会有很大的差别。
总结:WHERE 虽然先筛选数据再关联,执行效率高,但是不能使用分组中的计算函数进行筛选;HAVING 虽然可以使用分组中的计算函数,但是在最后的结果集中进行筛选,执行效率较低。
MySQL之常用函数介绍的更多相关文章
- MySQL常用函数介绍
MySQL常用函数介绍 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.操作符介绍 1>.操作符优先级 mysql; +----------+ | +----------+ ...
- MySQL 常用函数介绍
MySQL 基础篇 三范式 MySQL 军规 MySQL 配置 MySQL 用户管理和权限设置 MySQL 常用函数介绍 MySQL 字段类型介绍 MySQL 多列排序 MySQL 行转列 列转行 M ...
- [MFC美化] SkinMagic使用详解2- SkinMagic常用函数介绍
SkinMagic常用函数介绍 (1)InitSkinMagicLib函数:初始化SkinMagic int InitSkinMagicLib( //初始化SkinMagic工具库 HINSTANCE ...
- go语言之进阶篇字符串操作常用函数介绍
下面这些函数来自于strings包,这里介绍一些我平常经常用到的函数,更详细的请参考官方的文档. 一.字符串操作常用函数介绍 1.Contains func Contains(s, substr st ...
- MYSQL基本常用函数
MYSQL基本常用函数 一.字符的操作函数 (ps:mysql中的索引都是从1开始的.) 1.instr(param1,param2) 返回子串第一次出现的索引,若找不到则返回0. param1填写操 ...
- (转)postgis常用函数介绍(一)
http://blog.csdn.net/gisshixisheng/article/details/47701237 概述: 在进行地理信息系统开发的过程中,常用的空间数据库有esri的sde,po ...
- MySQL之常用函数
MySQL有如下常用函数需要掌握: 1.数学类函数 函数名称 作用 ABS(x) 返回x的绝对值 SQRT(x) 返回x的非负二次方根 MOD(x,Y ...
- mysql中常用函数简介(不定时更新)
常用函数version() 显示当前数据库版本database() 返回当前数据库名称user() 返回当前登录用户名inet_aton(IP) 返回IP地址的数值形式,为IP地址的数学计算做准备in ...
- SQL SERVER系统表和常用函数介绍
sysaltfiles 主数据库 保存数据库的文件 syscharsets 主数据库 字符集与排序顺序sysconfigures 主数据库 配置选项syscurconfigs 主数据库 当前配置选项s ...
- promql 常用函数介绍
Metrics类型 根据不同监控指标之间的差异,Prometheus定义了4中不同的指标类型(metric type):Counter(计数器).Gauge(仪表盘).Histogram(直方图).S ...
随机推荐
- 被冰封的 Bug:Fishhook Crash 修复纪实
作者:郝连福,业界资深计算机技术专家,现任声网Agora 首席前端架构师.先后担任过 Principal Engineer/Engineering Director(UTStarcom).Sr. ar ...
- GUI编程--3 Swing
GUI编程-3 Swing 3.1 JFrame 窗口 窗口: package com.ssl.lesson04; import javax.swing.*; import java.awt.*; p ...
- uni-app云开发入门
云函数 首先创建一个uniapp项目,创建项目时选择启用uniCloud云开发. 创建项目成功后,按照下面的步骤进行开发. 创建云函数 1.关联云服务器 2.创建云函数 一个云函数可以看成是一个后 ...
- 淘宝商品页面的爬取.py(亲测有效)
import requests def getHTMLText(url): try: r = requests.get(url,timeout=30) r.raise_for_status() #如果 ...
- react商品详情页、购物车逻辑、首页上拉加载、下滑刷新
1.回顾 2.点击列表进入产品的详情页面 设计向页面的布局结构,设计详情页面,入口导入布局文件 // index.js 入口文件 import Detail from '@/Detail'; < ...
- 二进制安装 Kubernetes(k8s)
二进制安装 Kubernetes(k8s) Kubernetes 开源不易,帮忙点个star,谢谢了 介绍 kubernetes(k8s) 二进制安装 后续尽可能第一时间更新新版本文档 1.23.3 ...
- 简单的cs修改器
目录 各个函数解析 main() GetPid() 无限子弹 无限血 无限金币 Patch() 无僵直 稳定射击 Depatch1 手枪连发 Depatch 源代码部分 各个函数解析 这是我根据b站上 ...
- 前后端分离 nginx 的配置
前端 nginx # 添加头部信息 proxy_send_timeout 30; # 后端服务器连接超时时间 proxy_read_timeout 30; # 后端服务器数据回传时间 proxy_co ...
- 中国省市区--地区SQL表
SET FOREIGN_KEY_CHECKS=0; -- ---------------------------- -- Table structure for rc_district -- ---- ...
- 活动预告 | Jax Diffusers 社区冲刺线上分享(还有北京线下活动)
我们的 Jax Diffuser 社区冲刺活动已经截止报名,全球有 200 多名参赛选手成功组成了约 70 支队伍共同参赛. 为了帮助参赛者更好的完成自己的项目,也为了与更多社区成员们分享扩散模型和生 ...