EDA(Exploratory Data Analysis)数据探索性分析
EDA目的:通过了解数据集的分布情况,数据之间的关系,来帮我们更好的后期进行特征工程和建立模型。
本文主要是一个根据coco数据集格式的json文件,来分析数据集中图片尺寸,宽高比,bbox尺寸,宽高比,以及每张图片中bbox数量的分布情况。
分析的数据集来自:零基础入门CV - 街景字符编码识别赛题与数据-天池大赛-阿里云天池 (aliyun.com) ,主要是分析训练集,一共有三万张图片。
instances_train2017.json,是我们通过将数据集json文件转换后符合coco数据集标准的json文件。
import json
import os
import matplotlib.pyplot as plt
import seaborn as sns
root_path = os.getcwd()
json_filepath = os.path.join(root_path, 'instances_train2017.json')
data = json.load(open(json_filepath, 'r'))
EDA_dir = './EDA/'
if not os.path.exists(EDA_dir):
# shutil.rmtree(EDA_dir)
os.makedirs(EDA_dir)
# 准备图片数据
images = data[
'images'] # [{"license": 0, "url": null, "file_name": "0.jpg", "height": 350, "width": 741, "date_captured": null, "id": 0}, , , , , ]
annotations = data[
'annotations'] # [{"id": 0, "image_id": 0, "category_id": 1, "area": 17739, "bbox": [246, 77, 81, 219], "iscrowd": 0}, , , , ]
images_height = []
images_width = []
images_aspect_ratio = [] # 图片的宽高比
bboxes_height = []
bboxes_width = []
bboxes_aspect_ratio = [] # bboxes的宽高比
bboxes_num_per_image = [] # 每个图片的bbox数量
for i in images:
images_width.append(i['width'])
images_height.append(i['height'])
width_height = i['width'] / i['height']
images_aspect_ratio.append(width_height)
for i in annotations:
bboxes_width.append(i['bbox'][2])
bboxes_height.append(i['bbox'][3])
width_height = i['bbox'][2] / i['bbox'][3]
bboxes_aspect_ratio.append(width_height)
temp_num = 0
images_id = []
for i in annotations:
if i['image_id'] not in images_id:
images_id.append(i['image_id'])
if temp_num > 0:
bboxes_num_per_image.append(temp_num)
temp_num = 1
else:
temp_num = temp_num + 1
# 配置绘图的参数
sns.set_style("whitegrid")
# 绘制图片宽高的分布
plt.title('Images width and height distribution')
sns.kdeplot(images_width, images_height, shade=True)
plt.savefig(EDA_dir + 'images_width_height_distribution.png', dpi=600)
plt.show()
# 绘制图片宽高比分布
plt.title('Images aspect ratio distribution')
sns.distplot(images_aspect_ratio, kde=False)
plt.savefig(EDA_dir + 'images_aspect_ratio.png', dpi=600)
plt.show()
# 绘制图片宽度比分布
plt.title('Images width distribution')
sns.distplot(images_width, kde=False)
plt.savefig(EDA_dir + 'images_width_distribution', dpi=600)
plt.show()
# 绘制图片高度比分布
plt.title('Images height distribution')
sns.distplot(images_height, kde=False)
plt.savefig(EDA_dir + 'images_height_distribution.png', dpi=600)
plt.show()
# 绘制bboxes宽高的分布
plt.title('Bboxes width and height distribution')
sns.kdeplot(bboxes_width, bboxes_height, shade=True)
plt.savefig(EDA_dir + 'bboxes_width_height_distribution.png', dpi=600)
plt.show()
# 绘制bboxes宽高比分布
plt.title('Bboxes aspect ratio distribution')
sns.distplot(bboxes_aspect_ratio, kde=False)
plt.savefig(EDA_dir + 'bboxes_aspect_ratio .png', dpi=600)
plt.show()
# 绘制bboxes宽度比分布
plt.title('Bboxes width distribution')
sns.distplot(bboxes_width, kde=False)
plt.savefig(EDA_dir + 'bboxes_width_distribution', dpi=600)
plt.show()
# 绘制bboxes高度比分布
plt.title('Bboxes height distribution')
sns.distplot(bboxes_height, kde=False)
plt.savefig(EDA_dir + 'bboxes_height_distribution.png', dpi=600)
plt.show()
# 绘制每张图片bboxes个数的分布情况
plt.title('Distribution of the number of BBoxes in each image')
sns.distplot(bboxes_num_per_image, kde=False)
plt.savefig(EDA_dir + 'bboxes_per_image_distribution.png', dpi=600)
plt.show()
生成的结果都保存到 ./EDA/ 文件夹中。
结果展示:
 图片的宽度分布情况 图片的宽度分布情况 |
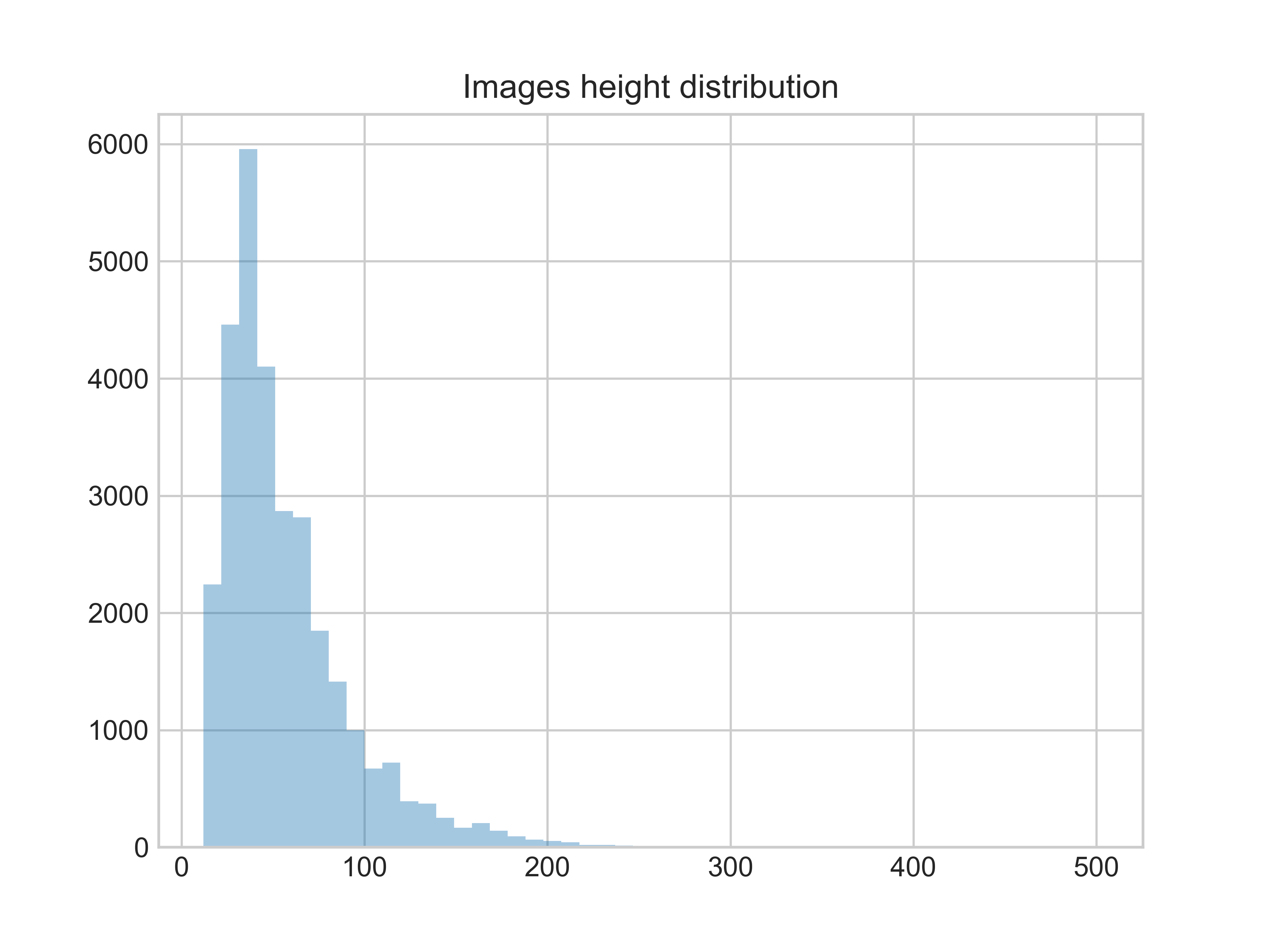 图片的高度分布情况 图片的高度分布情况 |
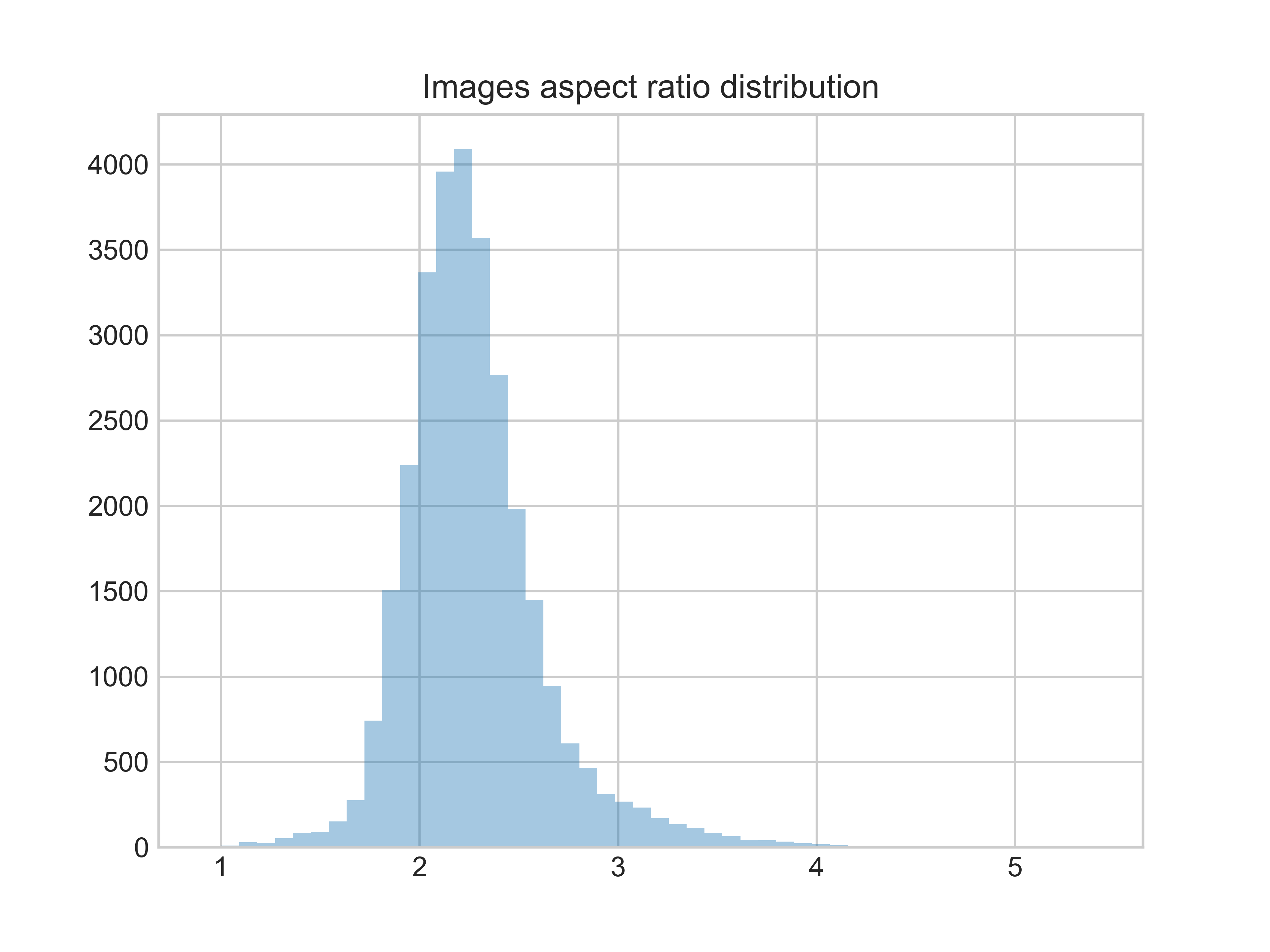 图片的宽高比分布情况 图片的宽高比分布情况 |
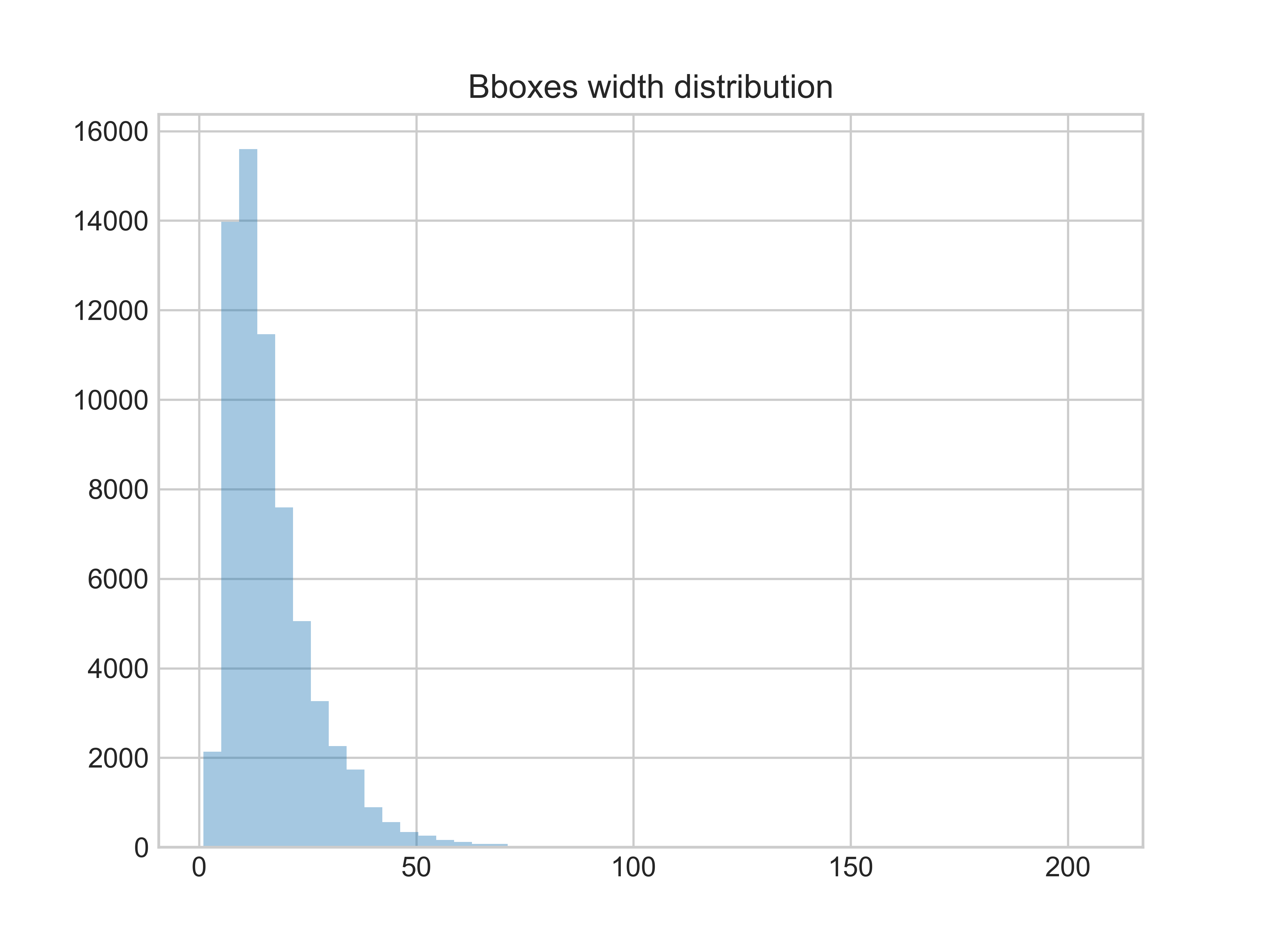 bbox的宽度分布情况 bbox的宽度分布情况 |
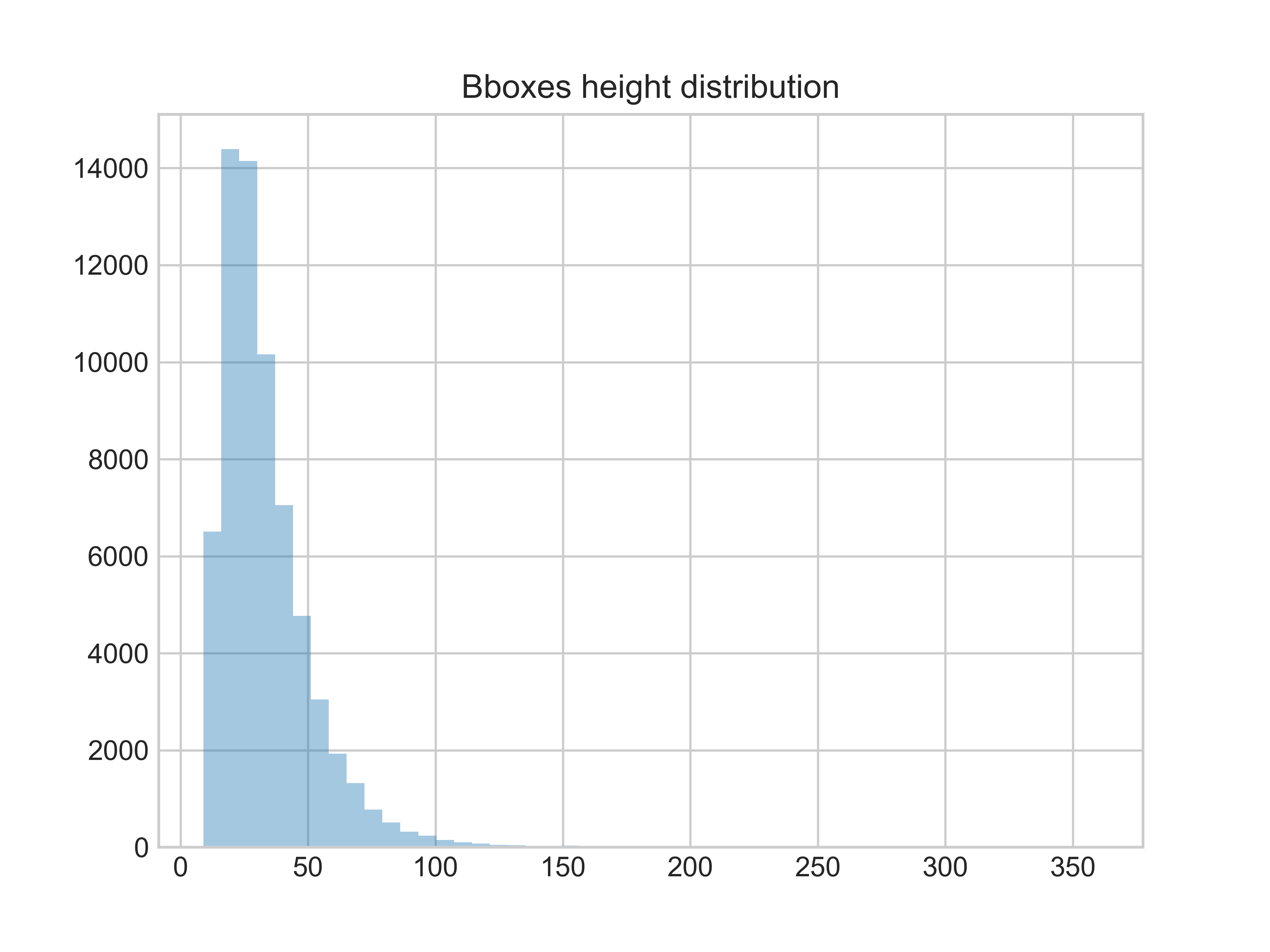 bbox的高度分布情况 bbox的高度分布情况 |
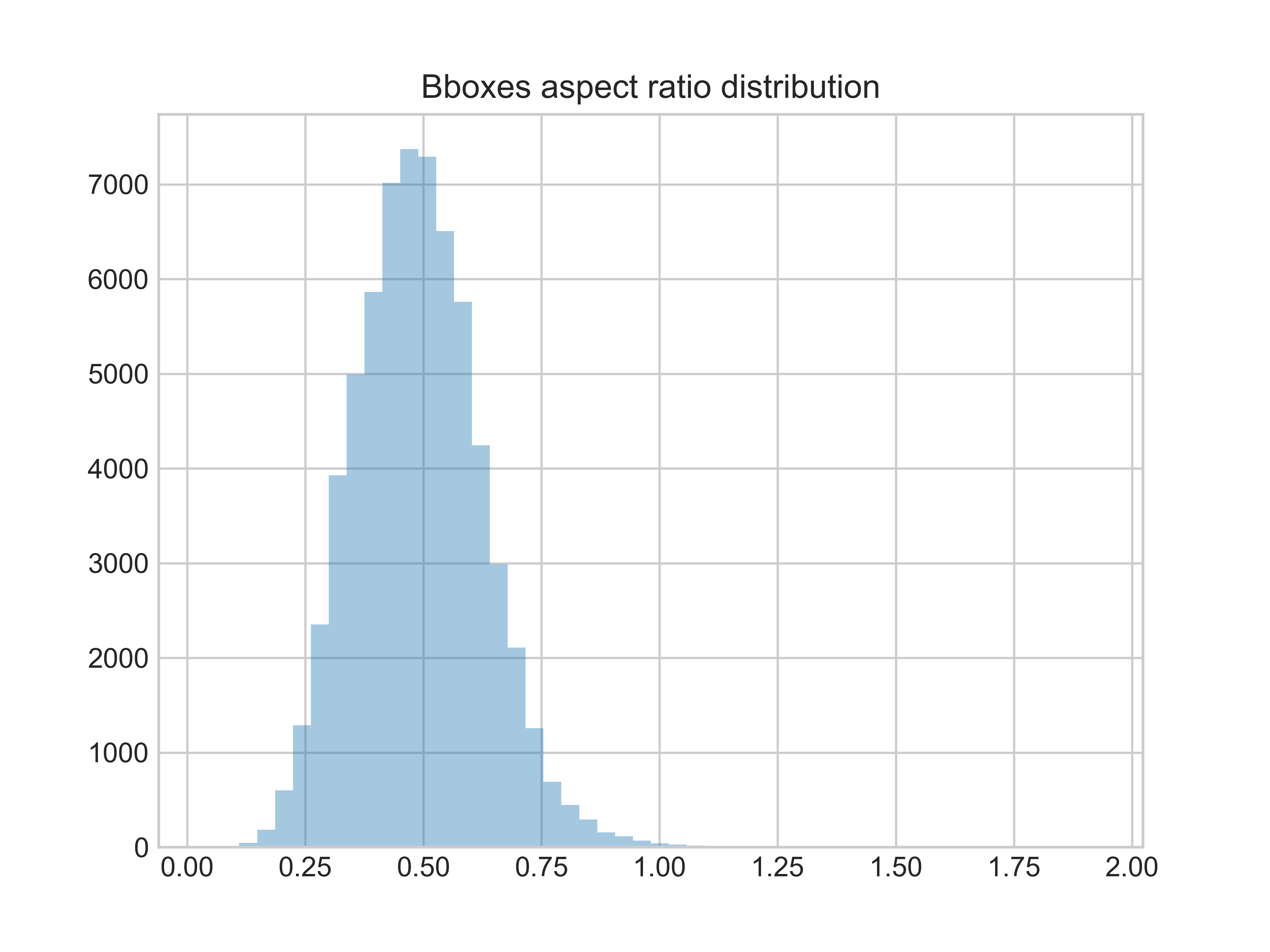 bbox的宽高比分布情况 bbox的宽高比分布情况 |
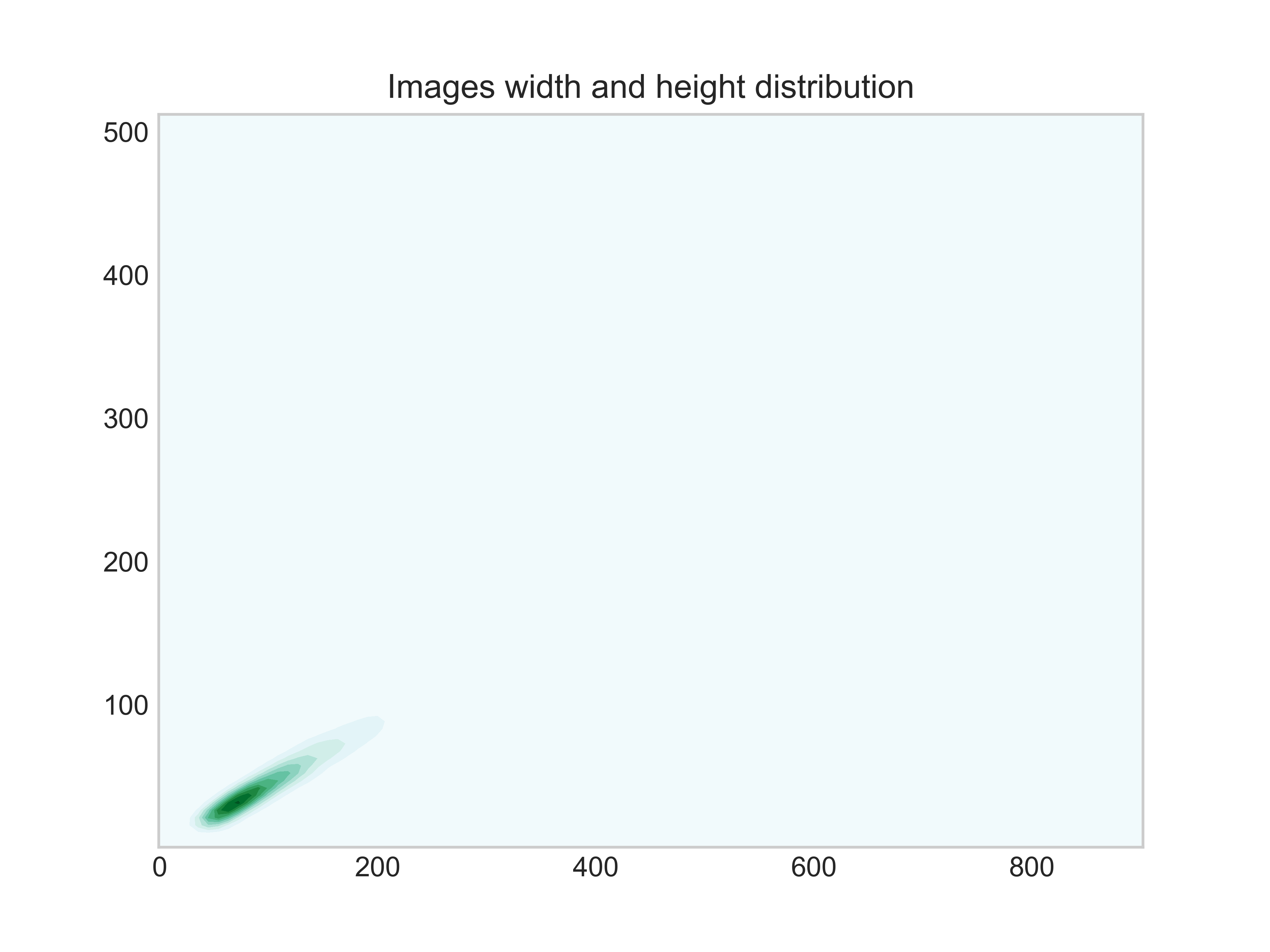 图片宽度和高度的分布情况 图片宽度和高度的分布情况 |
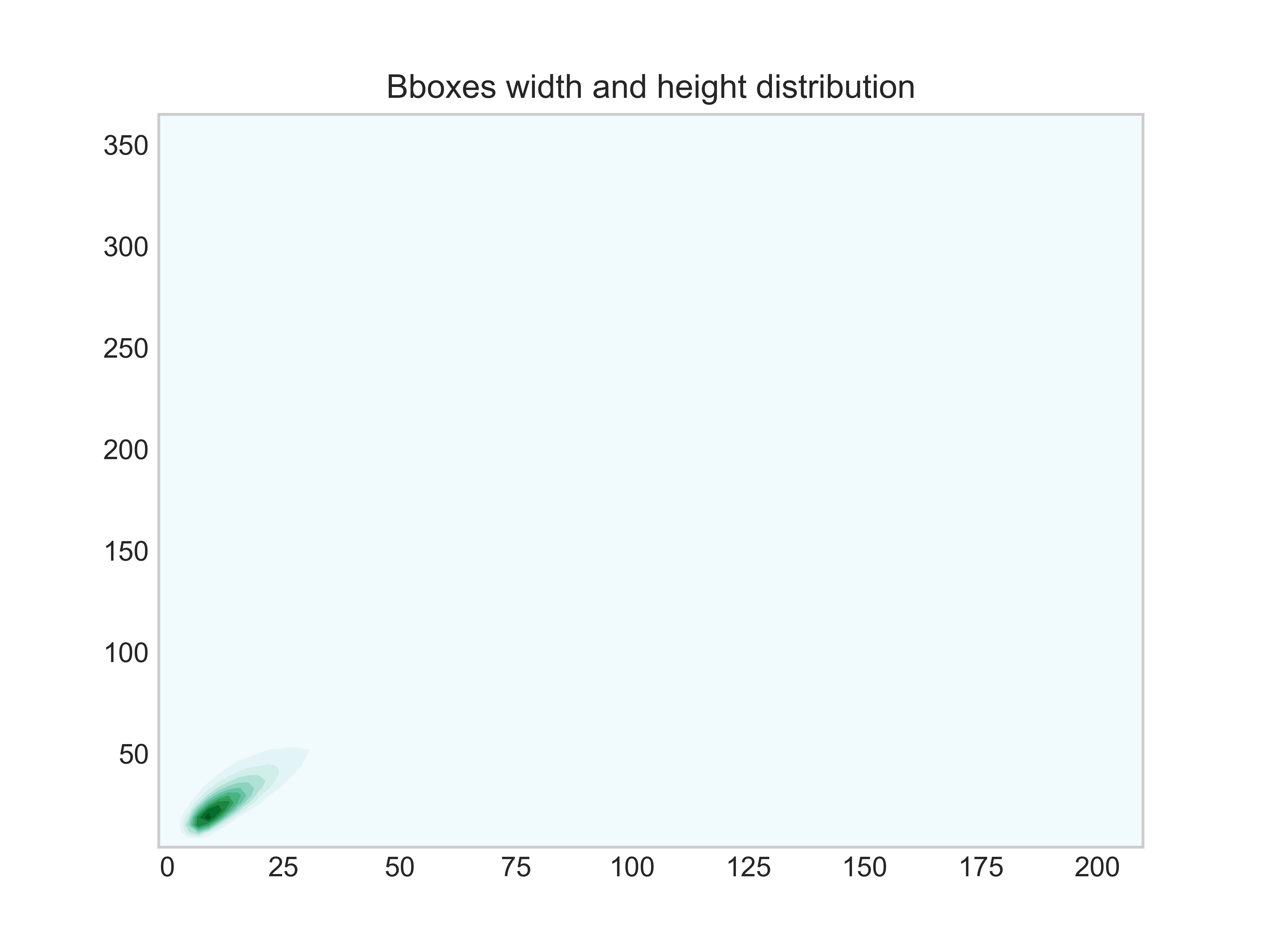 bbox宽度和高度的分布情况 bbox宽度和高度的分布情况 |
 每张图片中bbox数量的分布情况 每张图片中bbox数量的分布情况 |
通过EDA分析,我们可以得出:
图片的宽度大部分处于0~200,小部分处于200~400之间,极少数>400。
图片的高度大部分处于0~100,小部分处于100~200之间,极少数>200。
图片的宽高比大部分处于1.7~3之间。
bbox的宽度大部分处于0~50。
bbox的高度大部分处于0~50,小部分处于50~100。
bbox的宽高比大部分处于0.25~0.75。
每张图片中bbox数量大部分是1,2,3,小部分有4个bbox,极少数有5,6个bbox。
EDA(Exploratory Data Analysis)数据探索性分析的更多相关文章
- 探索性数据分析(Exploratory Data Analysis,EDA)
探索性数据分析(Exploratory Data Analysis,EDA)主要的工作是:对数据进行清洗,对数据进行描述(描述统计量,图表),查看数据的分布,比较数据之间的关系,培养对数据的直觉,对数 ...
- 1.探索性数据分析(EDA,Exploratory Data Analysis)
一.数据探索 1.数据读取 遍历文件夹,读取文件夹下各个文件的名字:os.listdir() 方法:用于返回指定的文件夹包含的文件或文件夹的名字的列表.这个列表以字母顺序. 它不包括 '.' 和'.. ...
- 学习笔记之Data analysis
Data analysis - Wikipedia https://en.wikipedia.org/wiki/Data_analysis Data analysis is a process of ...
- How to use data analysis for machine learning (example, part 1)
In my last article, I stated that for practitioners (as opposed to theorists), the real prerequisite ...
- 数据挖掘(data mining),机器学习(machine learning),和人工智能(AI)的区别是什么? 数据科学(data science)和商业分析(business analytics)之间有什么关系?
本来我以为不需要解释这个问题的,到底数据挖掘(data mining),机器学习(machine learning),和人工智能(AI)有什么区别,但是前几天因为有个学弟问我,我想了想发现我竟然也回答 ...
- 《python for data analysis》第九章,数据聚合与分组运算
# -*- coding:utf-8 -*-# <python for data analysis>第九章# 数据聚合与分组运算import pandas as pdimport nump ...
- 转录组分析综述A survey of best practices for RNA-seq data analysis
转录组分析综述 转录组 文献解读 Trinity cufflinks 转录组研究综述文章解读 今天介绍下小编最近阅读的关于RNA-seq分析的文章,文章发在Genome Biology 上的A sur ...
- 深入浅出数据分析 Head First Data Analysis Code 数据与代码
<深入浅出数据分析>英文名为Head First Data Analysis Code, 这本书中提供了学习使用的数据和程序,原书链接由于某些原因不 能打开,这里在提供一个下载的链接.去下 ...
- 《python for data analysis》第七章,数据规整化
<利用Python进行数据分析>第七章的代码. # -*- coding:utf-8 -*-# <python for data analysis>第七章, 数据规整化 imp ...
- 《利用Python进行数据分析: Python for Data Analysis 》学习随笔
NoteBook of <Data Analysis with Python> 3.IPython基础 Tab自动补齐 变量名 变量方法 路径 解释 ?解释, ??显示函数源码 ?搜索命名 ...
随机推荐
- Python回顾面向对象
[一]面向过程开发和面向对象开发 [1]面向过程包括函数和面条 包括面条版本一条线从头穿到尾 学习函数后开始对程序进行分模块,分功能开发 学习模块化开发,我们就可以对我们的功能进行分类开发 建一个功能 ...
- 【Azure Power BI】Power BI获取SharePoint List列表后,如何展开List/Table中的字段,以及使用逗号拼接为一个字符串
问题描述 Power BI获取SharePoint List列表作为数据源.但是在数据源中,有Table属性值,有List属性值.如果直接展开,则会形成"笛卡尔"集的效果,变成N多 ...
- 单词本z ambition 雄心 amb = ab = about = around = 环绕
ambition 雄心 amb = ab = about = around = 环绕 it = go = 走 ion 名词 重点是 amb 环绕 这里是抽象含义 表示内心向外扩展 所以是雄心 ambu ...
- 制作B站直播简介
本文只用于个人总结备份,如果对你有帮助就更好了. 准备工作 准备好简介要用的的背景图.头像图,上传到图床生成图片链接. 简介的内容可分为主播简介.直播时间.直播内容.联系方式,内容根据实际需要修改,需 ...
- k8s资源管理中request和limit的区别
在 Kubernetes(K8s)中,request和limit是两个重要的概念,用于控制和管理容器的资源使用. Request(请求): request定义了容器启动时需要保证的最小资源量.这表示K ...
- linux控制显示器的亮度
我使用的manjaro yay -S redshift -b 白天:晚上 要应用的屏幕亮度(在 0.1 和 1.0 之间) -c 文件 从指定的配置文件加载设置 -g R:G:B 要应用的其他伽马校正 ...
- Android 发布aar远程依赖出现扩展方法无法找到问题
原文: Android 发布aar远程依赖出现扩展方法无法找到问题-Stars-One的杂货小窝 起因 最近在整合自己的工具类库,偶然发现之前写的扩展方法使用远程依赖却是提示找不到 但我有个aar库却 ...
- openssl 版本兼容问题 备忘录
第三方依赖openssl,但openssl却有版本不同符号不兼容的问题,由于条件限制不得不使用固定版本的openssl,又或者同时有两个第三方依赖不同版本的openssl,只能靠手动,为了备忘. 1. ...
- C++保证线程安全的方式
1.互斥量 可以确保同一时间只有一个线程访问临界区,防止出现竞态条件. 2.原子操作 std::atomic<int> mutex(1); 对原子变量的操作是线程安全的. 3.读写锁 st ...
- 两个int变量交换
两个变量int a,int b,不用临时变量过渡,两种方法: 第一种: a= a+b; b= a-b; a= a-b; 第二种:异或的方法,也就是位运算,两个相同的数异或是为0的. a= a^b; b ...