EDA(Exploratory Data Analysis)数据探索性分析
EDA目的:通过了解数据集的分布情况,数据之间的关系,来帮我们更好的后期进行特征工程和建立模型。
本文主要是一个根据coco数据集格式的json文件,来分析数据集中图片尺寸,宽高比,bbox尺寸,宽高比,以及每张图片中bbox数量的分布情况。
分析的数据集来自:零基础入门CV - 街景字符编码识别赛题与数据-天池大赛-阿里云天池 (aliyun.com) ,主要是分析训练集,一共有三万张图片。
instances_train2017.json,是我们通过将数据集json文件转换后符合coco数据集标准的json文件。
import json
import os
import matplotlib.pyplot as plt
import seaborn as sns
root_path = os.getcwd()
json_filepath = os.path.join(root_path, 'instances_train2017.json')
data = json.load(open(json_filepath, 'r'))
EDA_dir = './EDA/'
if not os.path.exists(EDA_dir):
# shutil.rmtree(EDA_dir)
os.makedirs(EDA_dir)
# 准备图片数据
images = data[
'images'] # [{"license": 0, "url": null, "file_name": "0.jpg", "height": 350, "width": 741, "date_captured": null, "id": 0}, , , , , ]
annotations = data[
'annotations'] # [{"id": 0, "image_id": 0, "category_id": 1, "area": 17739, "bbox": [246, 77, 81, 219], "iscrowd": 0}, , , , ]
images_height = []
images_width = []
images_aspect_ratio = [] # 图片的宽高比
bboxes_height = []
bboxes_width = []
bboxes_aspect_ratio = [] # bboxes的宽高比
bboxes_num_per_image = [] # 每个图片的bbox数量
for i in images:
images_width.append(i['width'])
images_height.append(i['height'])
width_height = i['width'] / i['height']
images_aspect_ratio.append(width_height)
for i in annotations:
bboxes_width.append(i['bbox'][2])
bboxes_height.append(i['bbox'][3])
width_height = i['bbox'][2] / i['bbox'][3]
bboxes_aspect_ratio.append(width_height)
temp_num = 0
images_id = []
for i in annotations:
if i['image_id'] not in images_id:
images_id.append(i['image_id'])
if temp_num > 0:
bboxes_num_per_image.append(temp_num)
temp_num = 1
else:
temp_num = temp_num + 1
# 配置绘图的参数
sns.set_style("whitegrid")
# 绘制图片宽高的分布
plt.title('Images width and height distribution')
sns.kdeplot(images_width, images_height, shade=True)
plt.savefig(EDA_dir + 'images_width_height_distribution.png', dpi=600)
plt.show()
# 绘制图片宽高比分布
plt.title('Images aspect ratio distribution')
sns.distplot(images_aspect_ratio, kde=False)
plt.savefig(EDA_dir + 'images_aspect_ratio.png', dpi=600)
plt.show()
# 绘制图片宽度比分布
plt.title('Images width distribution')
sns.distplot(images_width, kde=False)
plt.savefig(EDA_dir + 'images_width_distribution', dpi=600)
plt.show()
# 绘制图片高度比分布
plt.title('Images height distribution')
sns.distplot(images_height, kde=False)
plt.savefig(EDA_dir + 'images_height_distribution.png', dpi=600)
plt.show()
# 绘制bboxes宽高的分布
plt.title('Bboxes width and height distribution')
sns.kdeplot(bboxes_width, bboxes_height, shade=True)
plt.savefig(EDA_dir + 'bboxes_width_height_distribution.png', dpi=600)
plt.show()
# 绘制bboxes宽高比分布
plt.title('Bboxes aspect ratio distribution')
sns.distplot(bboxes_aspect_ratio, kde=False)
plt.savefig(EDA_dir + 'bboxes_aspect_ratio .png', dpi=600)
plt.show()
# 绘制bboxes宽度比分布
plt.title('Bboxes width distribution')
sns.distplot(bboxes_width, kde=False)
plt.savefig(EDA_dir + 'bboxes_width_distribution', dpi=600)
plt.show()
# 绘制bboxes高度比分布
plt.title('Bboxes height distribution')
sns.distplot(bboxes_height, kde=False)
plt.savefig(EDA_dir + 'bboxes_height_distribution.png', dpi=600)
plt.show()
# 绘制每张图片bboxes个数的分布情况
plt.title('Distribution of the number of BBoxes in each image')
sns.distplot(bboxes_num_per_image, kde=False)
plt.savefig(EDA_dir + 'bboxes_per_image_distribution.png', dpi=600)
plt.show()
生成的结果都保存到 ./EDA/ 文件夹中。
结果展示:
 图片的宽度分布情况 图片的宽度分布情况 |
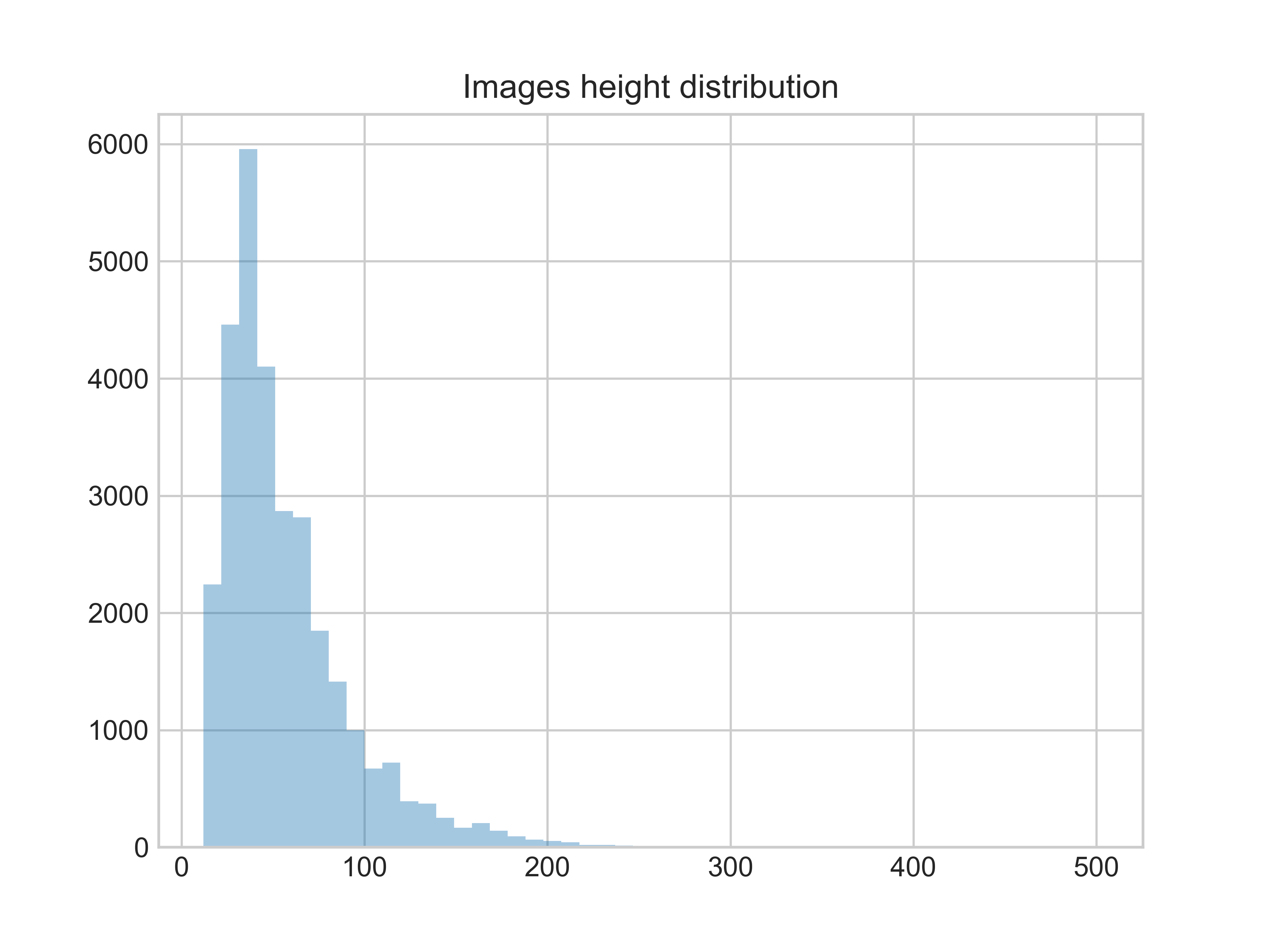 图片的高度分布情况 图片的高度分布情况 |
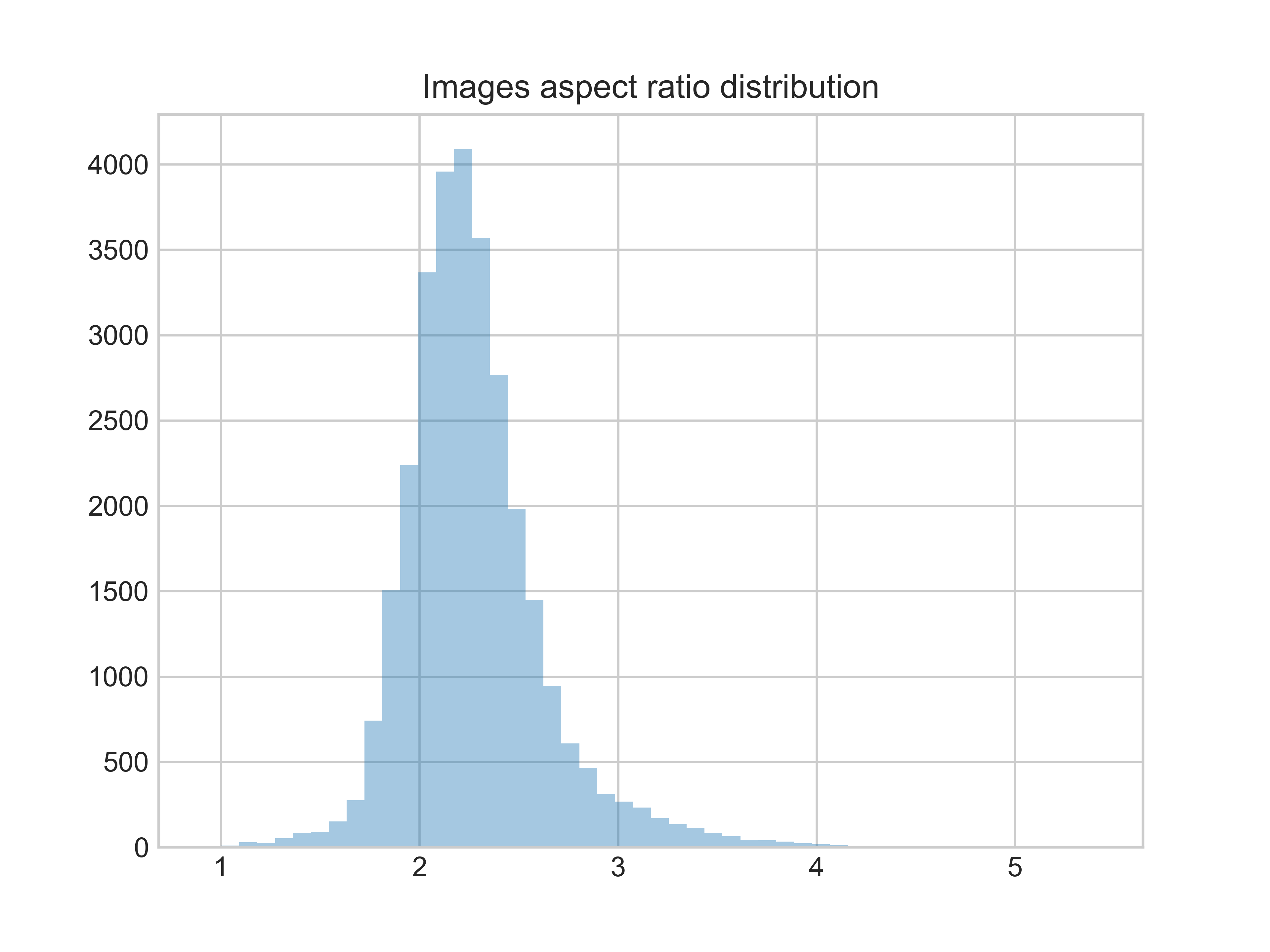 图片的宽高比分布情况 图片的宽高比分布情况 |
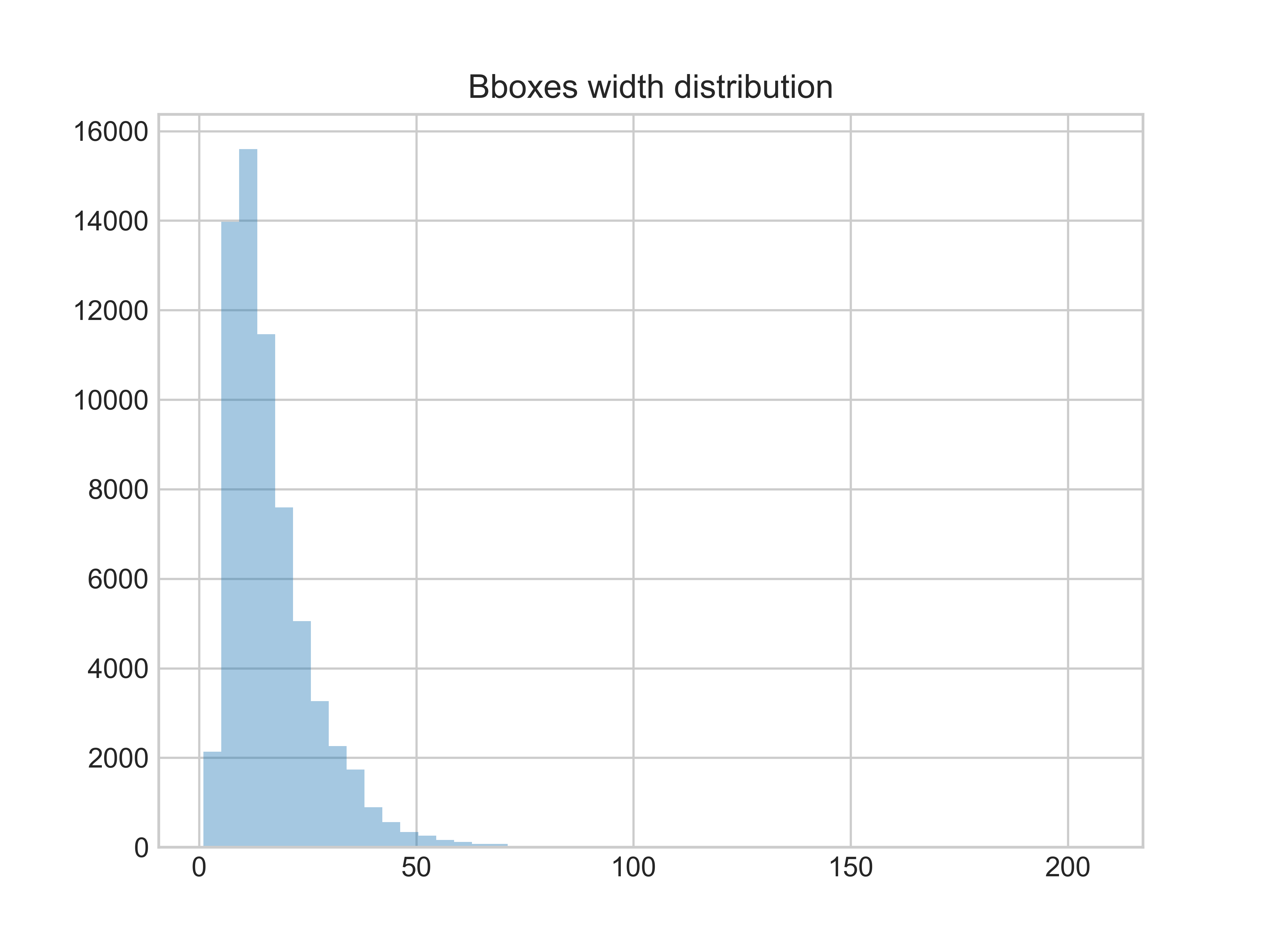 bbox的宽度分布情况 bbox的宽度分布情况 |
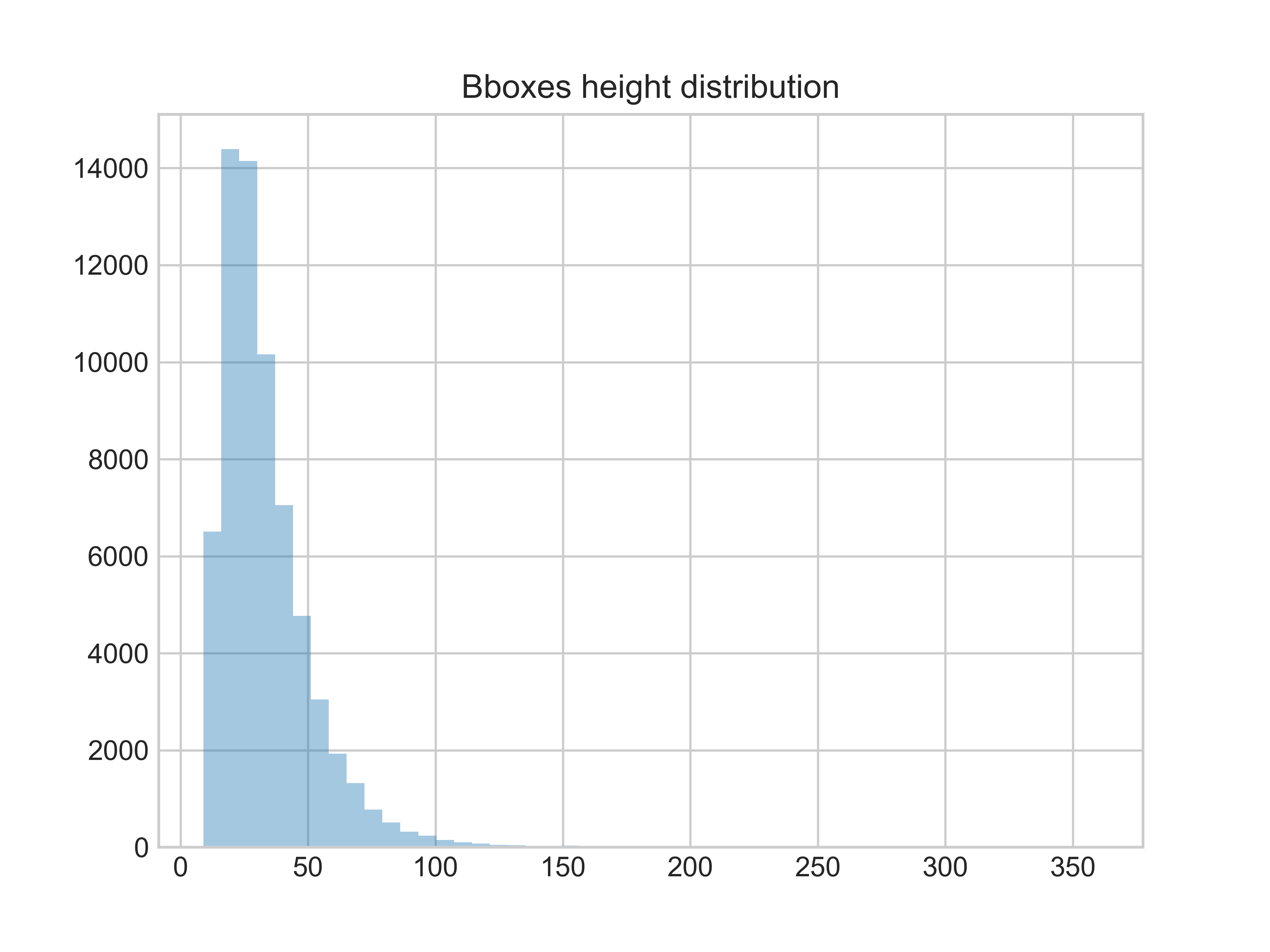 bbox的高度分布情况 bbox的高度分布情况 |
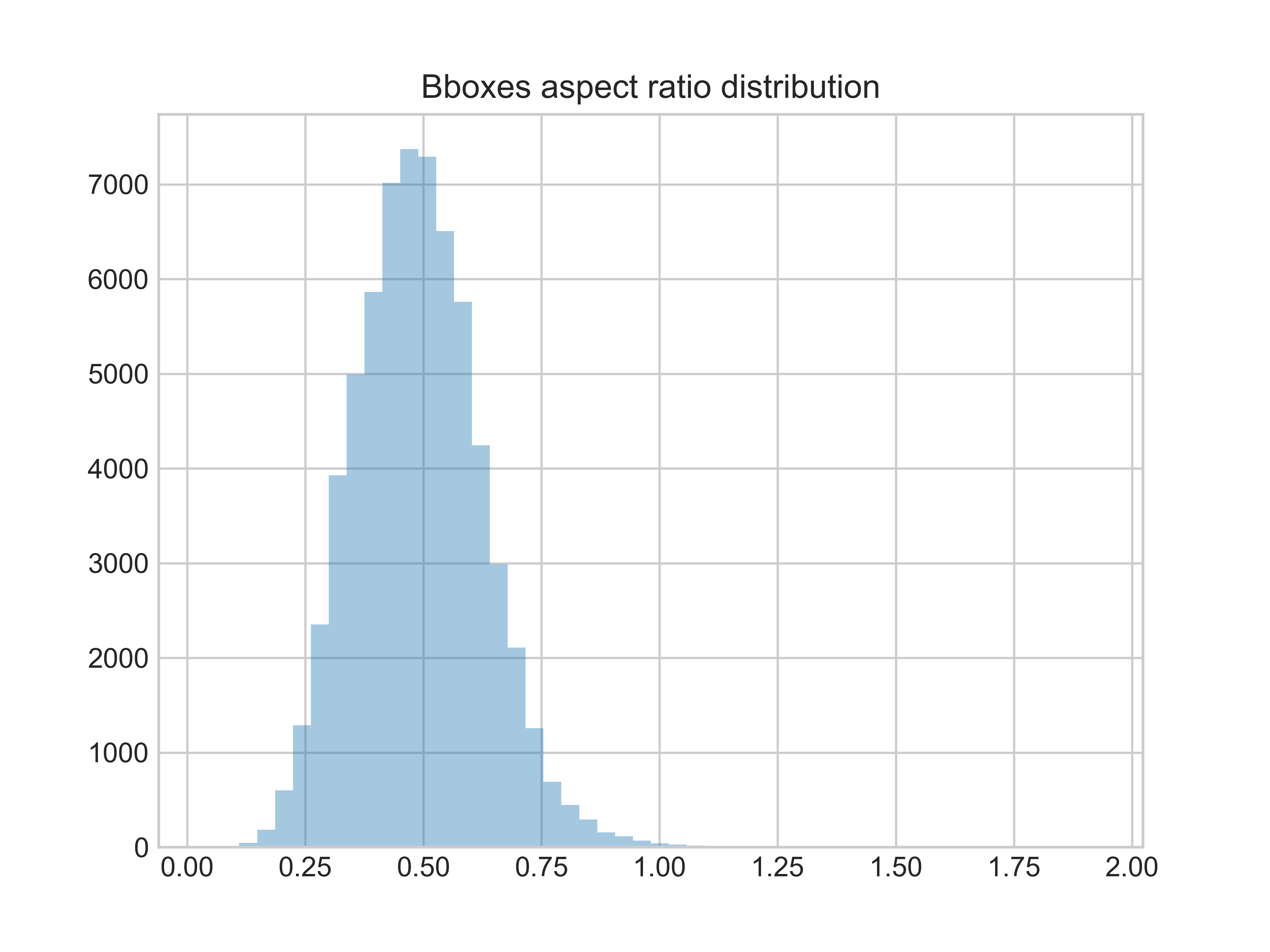 bbox的宽高比分布情况 bbox的宽高比分布情况 |
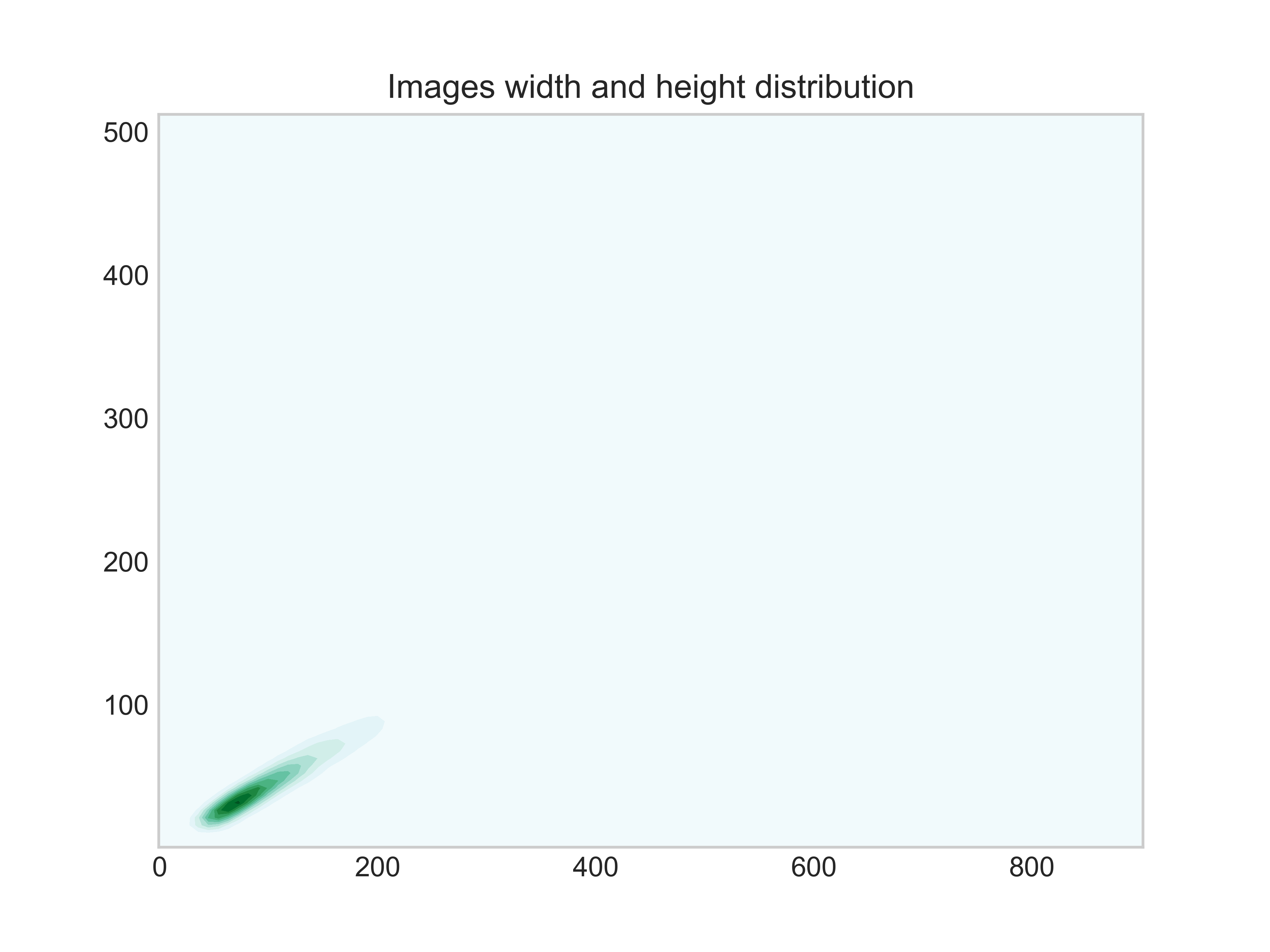 图片宽度和高度的分布情况 图片宽度和高度的分布情况 |
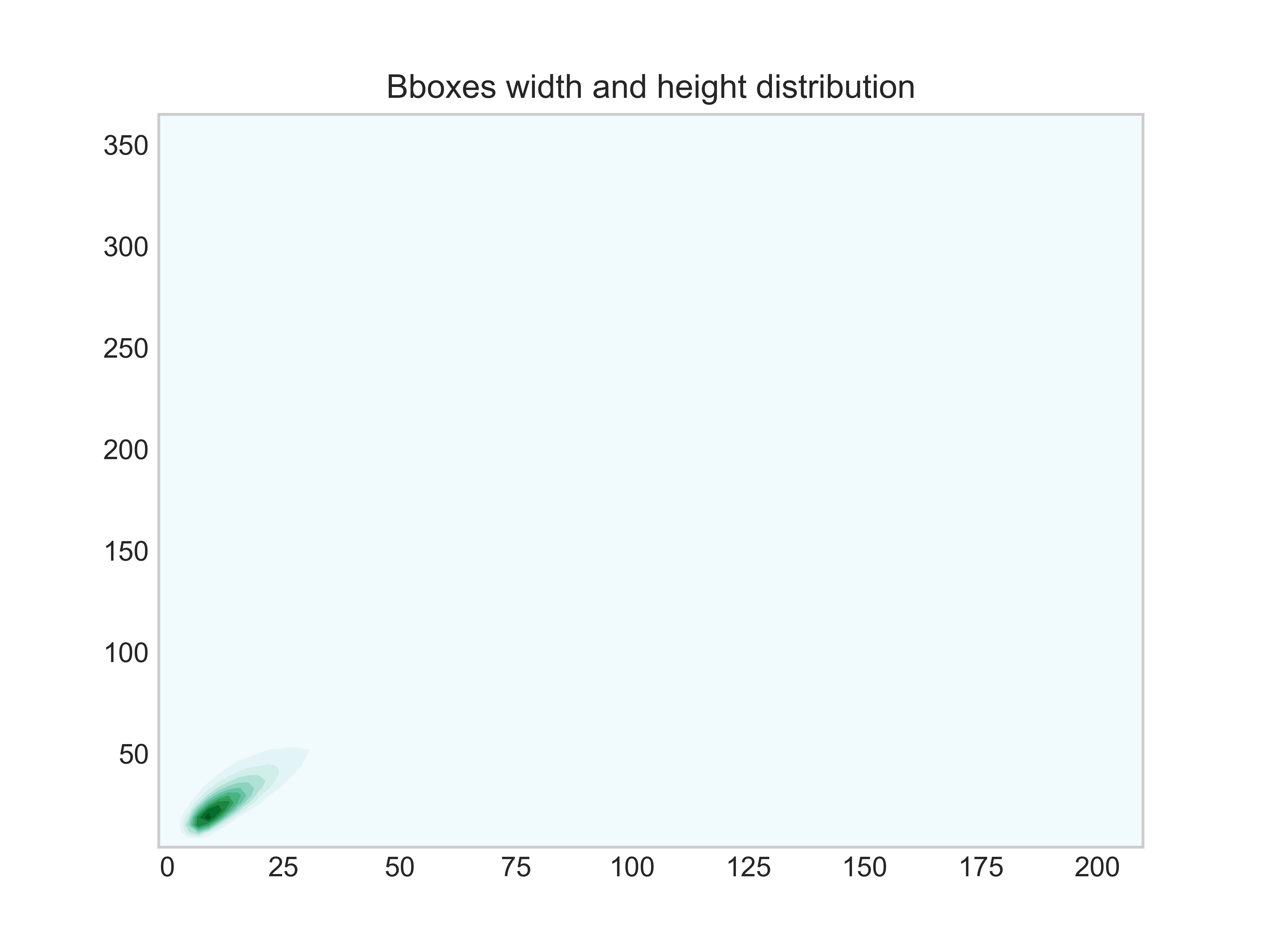 bbox宽度和高度的分布情况 bbox宽度和高度的分布情况 |
 每张图片中bbox数量的分布情况 每张图片中bbox数量的分布情况 |
通过EDA分析,我们可以得出:
图片的宽度大部分处于0~200,小部分处于200~400之间,极少数>400。
图片的高度大部分处于0~100,小部分处于100~200之间,极少数>200。
图片的宽高比大部分处于1.7~3之间。
bbox的宽度大部分处于0~50。
bbox的高度大部分处于0~50,小部分处于50~100。
bbox的宽高比大部分处于0.25~0.75。
每张图片中bbox数量大部分是1,2,3,小部分有4个bbox,极少数有5,6个bbox。
EDA(Exploratory Data Analysis)数据探索性分析的更多相关文章
- 探索性数据分析(Exploratory Data Analysis,EDA)
探索性数据分析(Exploratory Data Analysis,EDA)主要的工作是:对数据进行清洗,对数据进行描述(描述统计量,图表),查看数据的分布,比较数据之间的关系,培养对数据的直觉,对数 ...
- 1.探索性数据分析(EDA,Exploratory Data Analysis)
一.数据探索 1.数据读取 遍历文件夹,读取文件夹下各个文件的名字:os.listdir() 方法:用于返回指定的文件夹包含的文件或文件夹的名字的列表.这个列表以字母顺序. 它不包括 '.' 和'.. ...
- 学习笔记之Data analysis
Data analysis - Wikipedia https://en.wikipedia.org/wiki/Data_analysis Data analysis is a process of ...
- How to use data analysis for machine learning (example, part 1)
In my last article, I stated that for practitioners (as opposed to theorists), the real prerequisite ...
- 数据挖掘(data mining),机器学习(machine learning),和人工智能(AI)的区别是什么? 数据科学(data science)和商业分析(business analytics)之间有什么关系?
本来我以为不需要解释这个问题的,到底数据挖掘(data mining),机器学习(machine learning),和人工智能(AI)有什么区别,但是前几天因为有个学弟问我,我想了想发现我竟然也回答 ...
- 《python for data analysis》第九章,数据聚合与分组运算
# -*- coding:utf-8 -*-# <python for data analysis>第九章# 数据聚合与分组运算import pandas as pdimport nump ...
- 转录组分析综述A survey of best practices for RNA-seq data analysis
转录组分析综述 转录组 文献解读 Trinity cufflinks 转录组研究综述文章解读 今天介绍下小编最近阅读的关于RNA-seq分析的文章,文章发在Genome Biology 上的A sur ...
- 深入浅出数据分析 Head First Data Analysis Code 数据与代码
<深入浅出数据分析>英文名为Head First Data Analysis Code, 这本书中提供了学习使用的数据和程序,原书链接由于某些原因不 能打开,这里在提供一个下载的链接.去下 ...
- 《python for data analysis》第七章,数据规整化
<利用Python进行数据分析>第七章的代码. # -*- coding:utf-8 -*-# <python for data analysis>第七章, 数据规整化 imp ...
- 《利用Python进行数据分析: Python for Data Analysis 》学习随笔
NoteBook of <Data Analysis with Python> 3.IPython基础 Tab自动补齐 变量名 变量方法 路径 解释 ?解释, ??显示函数源码 ?搜索命名 ...
随机推荐
- python AI 应用开发编程实战 大模型实战基础(一)
自从 由美国主导openAi公司开发的gpt大模型问世以来,人工智能技术一直在推动整个科技行业发展,所以当下全球大公司都在布局Ai产品应用,这是这二年出了好几千个Ai产品应用,全球大大小小甚至超出近上 ...
- ElasticSearch - 基础概念和映射
前言 写这篇东西,是因为官方文档看着太痛苦,于是乎想用大白话来聊聊 ElasticSearc (下面都简称ES).所以下文对于 ES 一些概念的表述可能会与官方有出入,所以需要准确的表述和详细定义的, ...
- 记录--浏览器渲染15M文本导致崩溃怎么办
这里给大家分享我在网上总结出来的一些知识,希望对大家有所帮助 最近,我刚刚完成了一个阅读器的txt文件阅读功能,但在处理大文件时,遇到了文本内容过多导致浏览器崩溃的问题. 一般情况下,没有任何样式渲染 ...
- R语言数据质量分析
数据质量分析是数据预处理的前提,也是数据分析结论有效性和准确性的基础. 数据质量分析的主要任务是检查原始数据中是否存在脏数据. 脏数据一般包括: 缺失值分析 缺失值产生的原因.影响 原因: 部分信息难 ...
- c# WPF制作百度网盘资源搜索工具
界面如下 1.搜索中 2.搜索成功 源码地址:https://github.com/BruceQiu1996/BaiduDiskSearcher 希望有用的学到的或者对此感兴趣的可以给一个star,谢 ...
- 一键解决App应用分发下载问题
本文深入分析了App应用分发下载失败的常见原因,并提供了针对网络连接问题.服务器故障.设备存储空间不足.文件大小和格式不受支持等方面的解决方法.此外,还附带了一个在线证书制作工具的案例演示,旨在帮助开 ...
- python批量发邮箱
1.首先登录邮箱中开启服务 2.获取到授权码后复制下来,放入如下含授权码的引号中: 1 smtp_obj.login("**********@qq.com", "授权码& ...
- Java AES CBC模式 加密和解密
import org.apache.tomcat.util.codec.binary.Base64; import javax.crypto.Cipher; import javax.crypto.s ...
- parameter常数及常数函数的使用
模型功能 常数在verilog设计中具备特殊的含义 一个可以由编译器进行处理的数 和C语言中常数一个不变的变量的作用不同 在verilog中,常数更多地作为预编译变量以提高设计的灵活性 在上一篇文章中 ...
- Collation 差异导致 KingbaseES 与 Oracle 查询结果不同
问题引入 前端提了个问题,说是KingbaseES 返回的结果与 Oracle 返回的结果不一样.具体问题如下: oracle 执行结果:oracle 有结果返回. SQL> create ta ...