AMiner的数据质量和完善问题
最近参加到了一个国家科技项目中,这里就不吐槽这种高校承接国家科技项目是一件多么不靠谱的事情了,这里就说说我们的对标产品“AMiner”。补充一下,虽然个人对AMiner的评价不是很高,但是对于我现在参与的在研发产品是否可以赶上AMiner我还是不抱有啥信心的,换句话说我认为这种“国”字号的科技产品就不应该由高校来主导甚至是完全参与,否则就是个只得其表的肤浅产品。
找到了一个网上的多年前的报道:
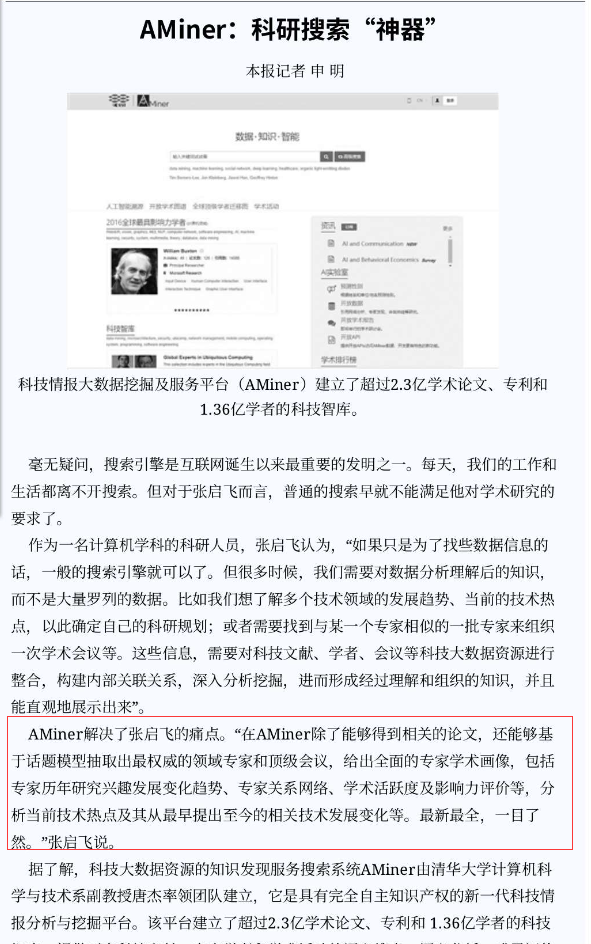
从这个方面我们可以看到,这个AMiner主要擅长于学科内顶级学者的图谱画像,这里需要注意我这里说的只是领域顶级学者而不是领域顶级刊物,为什么这么说呢,因为学科内的顶级学者一定是需要有学科内顶级刊物的学术成果才会被认定的,但是在顶级刊物上发过成果的人不一定就一定会被认定为顶级学者,而很多顶级的成果也并不是全都发表在顶级刊物上的,这里是个逻辑包含与否的关系。
可以说AMiner主要的功能就是给一个学者名,然后搜索出一个作者名单(这些名单中是否有你要找的同名作者是很难说的),你手动选择一个学者,然后给出这个学者(有单位介绍,有的还有照片)的学术发表成果表单,引用量,合作者,发表论文的相关领域。随机选了一个例子,其搜寻出的结果如下:
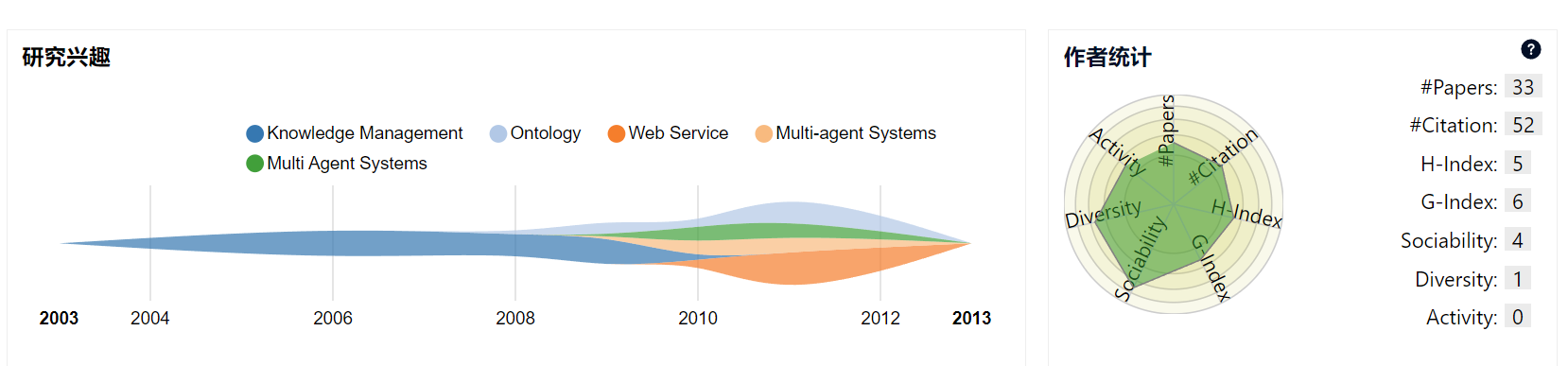
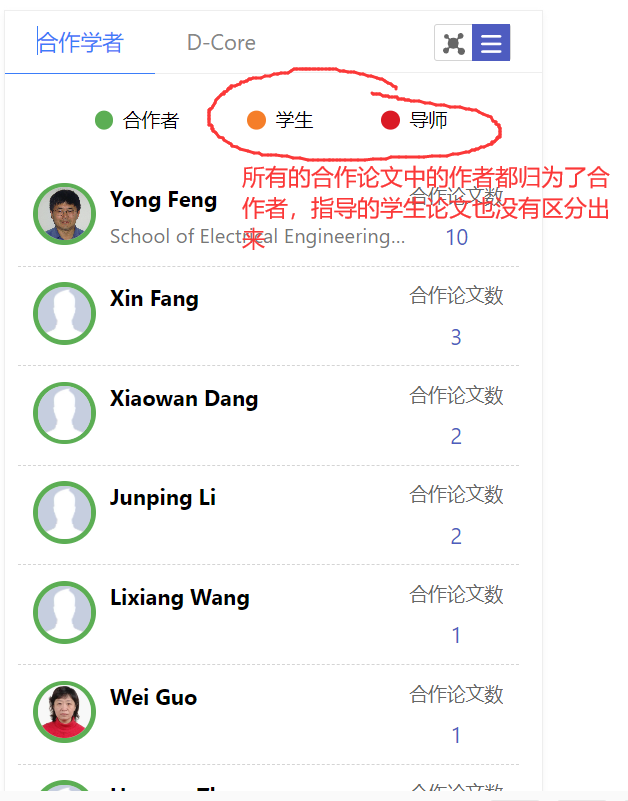
如果亲自使用这个AMiner去搜寻几个普通的学者,哪怕是985/211的教授如果不是顶级的那么估计也是很难收到较为准确和全面的结果。比较常见的问题就是对不上人,同名的作者往往被安错,不是学术成果不全,就是合作作者匹配的不准(同名的被匹配错)。可以这么说,这个AMiner的查询学者可以用,但是不咋好用,有搜索结果但是好像也不大好用,而且给出的数据也有很多不准的人员匹配,用起来也是不大放心的。而且一个作者,同名同单位的同一个人,在搜索中神奇会出现多个结果,每个结果进去都是同一个人的不同论文的发表情况,比如说一个人叫XXYY,他发了20篇论文,你用这个AMiner搜索,可能会搜索出4个XXYY,然后每个XXYY有4篇不同的论文,相当于把一个人分割了几份。而使用AMiner搜索普通学者,那么这些问题则是十分常见的。虽然这个AMiner不知道拿下了多少国家的科技奖项,拿下了多少国际的奖项、专利和学术成果,但是这东西确实好像主要是对顶级学着比较友好,普通学者好像没这么好用。但是吧,这个事情就是个悖论,对于顶级学者的搜索来说,我只需要用google scholar之类的就比较好用了,好像也不是必须使用这个AMiner的,而且说实话要不是做这个国家科技项目,我还真就没听说过这个AMiner,可能也是我孤陋寡闻了。其实如果是要查国内某学者的国内论文发表情况,我想最好用的可能还是知网,如果查这个学者的外语论文发表情况,那么使用google scholar好像也挺好用,如果说非要讲这个AMiner有好用的地方,那就是他这上有合作学者的自动跳转功能,但是这个功能虽然有但是其准确度与否还是很不好讲的,至少目前来看还是不太好用的。不得不说的是好像使用google scholar查询的效果可能是比AMiner的效果好,当然这个不带合作者的跳转功能,不过这个功能好像用处也不大,当然如果这个功能的准确度可以保证的话还是不错的,至少可以作为学者关系发现和推荐之用。
为了对这个AMiner有个更加客观的评判,我们这里使用一个科学家的姓名来进行查询:

学者:Солонін Ю.М.
中文翻译名:索洛宁·尤里·米哈伊洛维奇
英文翻译名:Solonin Yuriy M.
乌克兰国家科学院上的个人主页:
Солонін Юрій Михайлович (nas.gov.ua)
任职单位:
乌克兰国家科学院弗兰采维奇材料问题研究所
官方网址:
IPM NASU 弗兰采维奇 (materials.kiev.ua)
中文介绍地址:
乌克兰国家科学院弗兰采维奇材料问题研究所 - 知乎 (zhihu.com)
ResearchGate上的学术成果主页:Y.M. Solonin's research works | National Academy of Sciences of Ukraine, Kyiv (ISP) and other places (researchgate.net)
这位学者为乌克兰科学院院士,是欧洲最大材料研究所的所长,也是欧洲和前苏联所最为骄傲的材料研究所的leader,我们现在经常会在新闻中听到我们国家的科技被卡脖子很大程度是因为基础研究没有跟上,而实际这方面最领先的研究机构之一就是这个研究所。
在百度上知道乌克兰人的姓名特点:
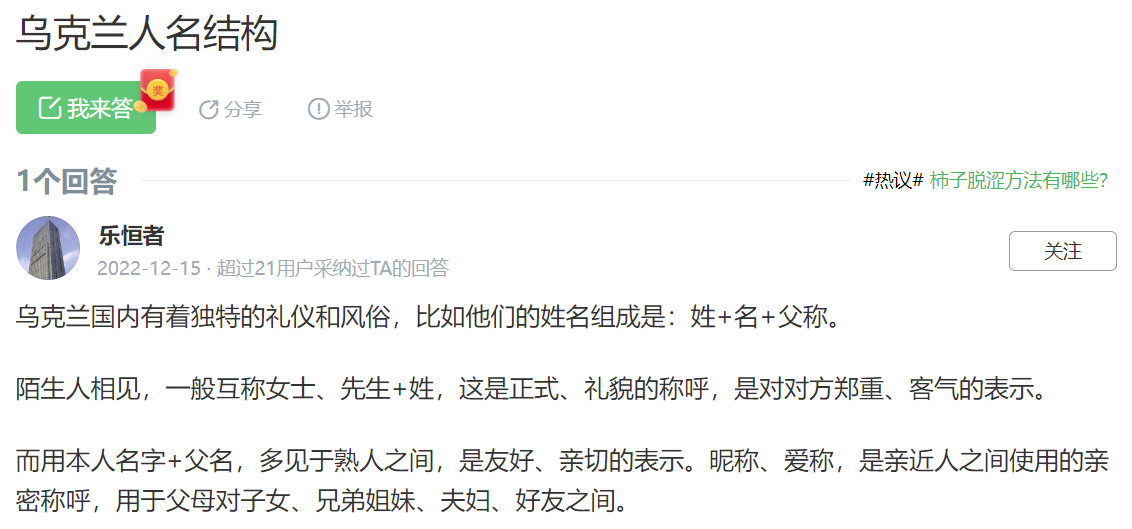
因此我们知道,这位科学家的英文直译名可以写为Solonin Y. M. ,但是如果按照英文中的first name + last name的写法规则,那么他的英文译名应该写为Y. M. Solonin,但是通过互联网搜索引擎的搜索我们知道他的姓名还有这样的形式出现过:Solonin Yuriy M. 和 Yuriy M. Solonin,也就是说不用回多大的力气就可以发现这个人的英文译名可以有这样四种形式。
在文献:https://iopscience.iop.org/article/10.1088/1742-6596/61/1/108
中我们可以看到他使用的英文名为:

但是我们在他的另一篇文章中发现他使用的英文名为:
https://www.sciencedirect.com/science/article/pii/S0925838809020817?via%3Dihub

那么我们在AMiner系统中进行检索:
1. 检索形式为:
Y.M. Solonin
可以看到检索出三个结果:
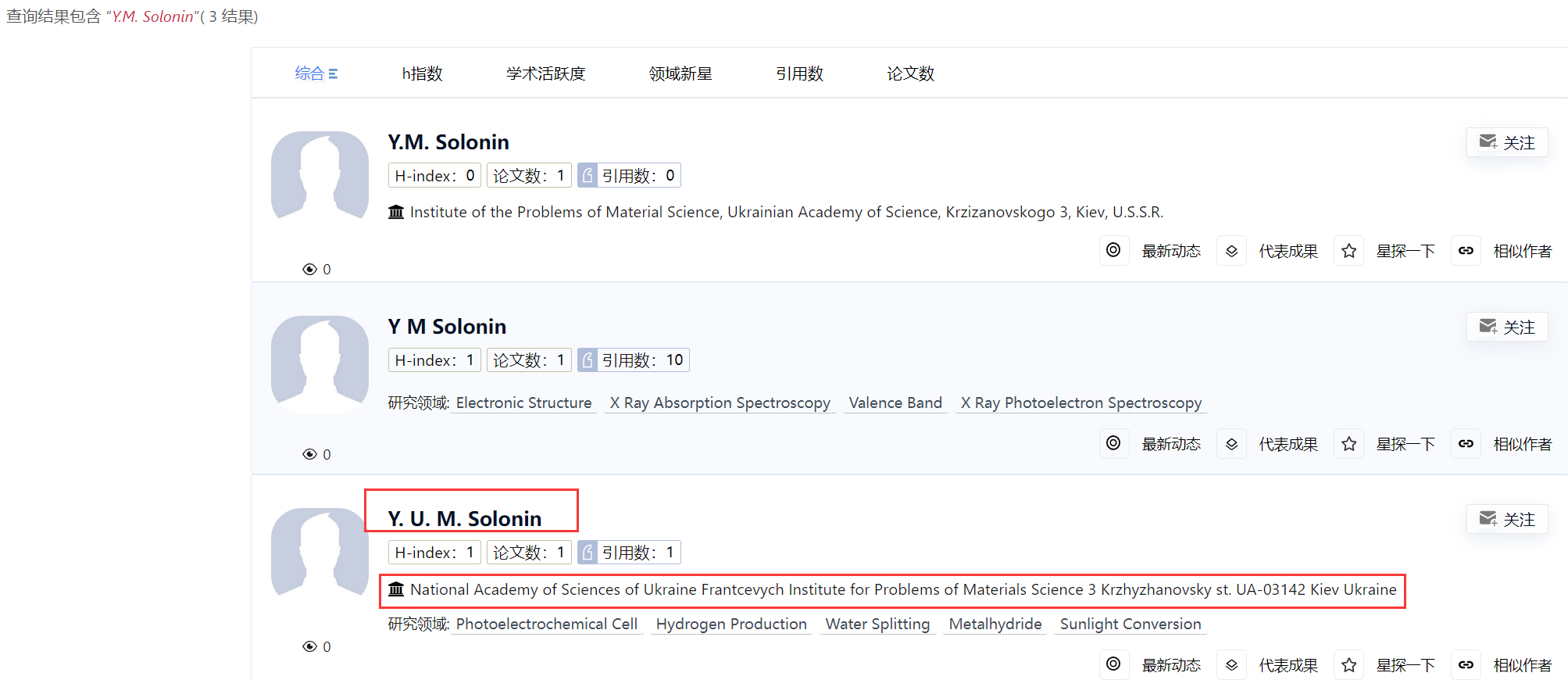
根据这三个人的标明的工作单位可以知道这三个人其实都是要指向我们的目标学者的,点进去后可以发现第一个和第二个结果虽然只有目标学者的一篇文章并且没有归为同一人但是并没有指错人,而第三个结果点进去发现虽然这个英文姓名的写法有问题但是其指向的也确实是我们的目标学者,打开第三个结果中的文献地址:https://link.springer.com/chapter/10.1007/1-4020-3498-9_19
我们神奇的发现他的第五种英文名形式:

即Yu. M. Solonin,可以说AMiner在查询时虽然是使用了模糊查询,但是其并没有把学者的不同姓名形式下的论文发表情况归为一个,说的专业一些就是没有做好学者消歧。
如果我们使用互联网上该学者出现姓名形式比较多的一种写法:Solonin Yuriy M. ,我们可以搜寻到一个发表文献更多的一个结果:
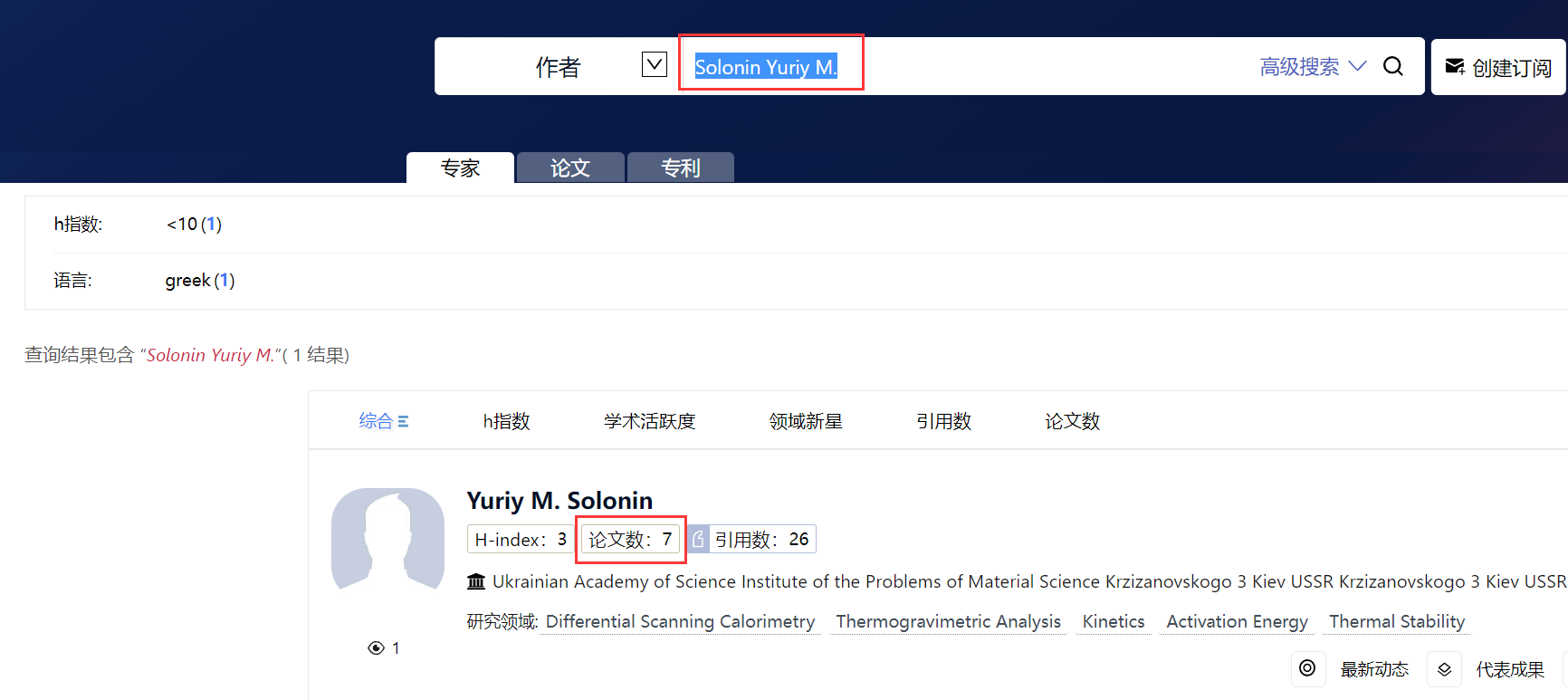
更加糟糕的是我们点击进去看下这收录的7篇文章:

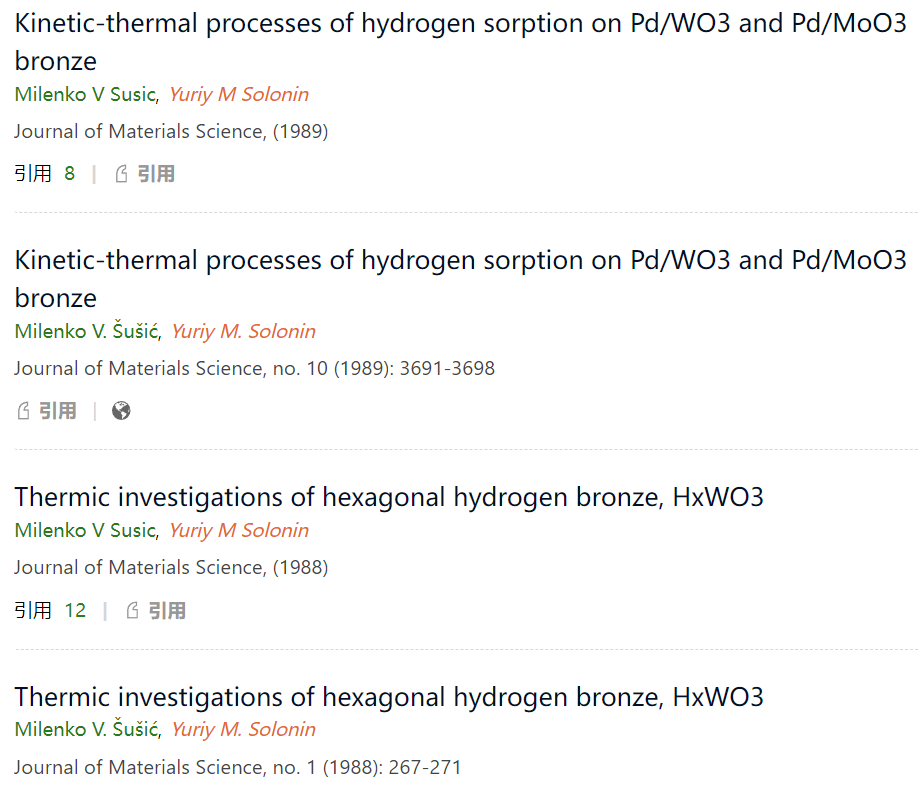
可以看到这里面有2个两两重复的文章,也就是说标明是7篇文章,实际上是5篇文章。而其中的重复论文从应用量上就可以看出其实在这个AMiner系统中是表明为不同论文的,比如:
和
从这里我们就可以看到这个AMiner不仅没有很好的做到学者消歧,也没有很好的做到学术成果消歧。
从上面的随机尝试中我们可以下个未必准确的判断,那就是这个AMiner系统并没有很好的完成他本身所宣传的学术图谱的效果,而且如果以学术引文检索的角度来看其效果远远不如google scholar,而从学术成果和学者匹配的角度来看其效果远远不如research gate,换句话说这个AMiner是国产的用于填补国内没有google sholar和research gate这样的网站的产品,虽然不是很好用,但是我们有了这个东西就解决了“没有”的问题。个人对这个AMiner的一个判断就是他应该是买了一些数据库(web of science等)的数据库的数据,然后把这些数据导入到系统中,然后进行了清洗、实体消歧、实体匹配、关系匹配等操作,估计使用的方法也都是一些常见的方法,虽然在这些所谓的方法上进行了修补后发表了各种实际顶级的期刊和会议上,但是其实际效果并不理想,通俗的说AMiner是一群大学教授搞的各种所谓的学术算法成果的产品,这个产品虽然不好用,但是这个产品所依赖的学术成果却拿了各种国际大奖,这事看起来还蛮讽刺的。
一个个人很主观的看法,这个AMiner其实并没有web of science + researchgate + google scholar + wiki + 知网,好用,如果非要说它的优点的话,那可能就是他的集成度确实很好,我们不需要使用多个学术检索产品去检索了,不过说句内心话,就冲AMiner这实际表现出的准确度和全面性我还是更加倾向于使用多种产品的检索方式,比较web of science + researchgate + google scholar + wiki + 知网,所表现出的效果要远远优于AMiner。
对于这个AMiner的质量不高的问题,除了这个本身是国家科技项目,然后由一群高校教授搞出来的原因以外,其实还有两个客观因素,第一点是现有的国际学术成果的数据都是被美国为首的国家说掌握,这部分数据并不在我们的控制范围之内,虽然可以购买一部分数据,但是这往往也只是杯水车薪,加上自己网络上爬取的资料虽然可以起到一定的扩充作用,但是不同的数据源如何进行消重、消歧本就是一个现在工业界和学界都没有很好解决的难题,至今也没有说哪个产品可以很好的handle这个问题,而这个技术上如何解决对齐、消重、消歧就是第二个客观因素。可以说即使我们有了全面的数据,跨过第一个问题,但是第二个问题所面对的技术难题也是难以解决的,对于这个校准、对齐的问题如果自动化难以解决,那么是不是人工操作可以呢,答案确实是如此,但是这里面就有存在一个难题,就是这个工作量过大,如何解决,即使这个工作量可以分担出去,但是这个质量如何保证就又是一个难题。其实这个AMiner也是给出了一些人工校对的途径的,如下:
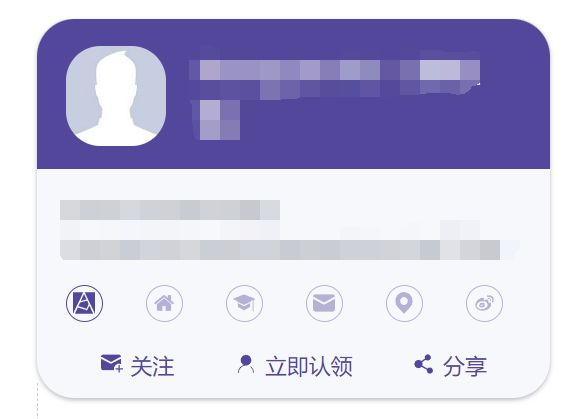
注意,个人简介是自己可以改的,估计是要用单位邮箱认证,但是会不会还检测,是不是只要这个单位的邮箱就行而不用看具体是不是这个人的邮箱,我想还是很可能是不看的。


可以说在AMiner上是提供人工校对、对齐的途径的,不过考虑到这个AMiner本身就缺少维护,而使用者更是寥寥,去手动为其校准数据的人更是不会多,本就没用户基数,再加上校准等人工操作也没有任何的奖励机制和荣誉机制,某种程度上来说AMiner的这个人工填补资料就是摆设,而且这种人工填补资料其实并不能真正的实现校准和对齐,而这些校准和对齐依旧只受计算机后台程式的设定来运行,人工的填补资料并不能有太多对AMiner提升的益处。
其实从AMiner的一些表现上就容易看出,这个AMiner主要的收录内容都是领域的大牛,对于普通学者的收录要不不全就是不准,而且他主要的收录领域其实还是计算机领域,或者说是人工智能领域,从这个角度看这个AMiner本身就带有很强的领域偏向性的。具体表现:

不过说实话,如果要查计算机或者人工智能的学术成果,我为什么不使用dblp和arxiv呢,难道这个AMiner存在的意义和价值就是为了填补国内的空虚吗,这样的产品对得起“国”号的称呼吗,这就是国家的顶级学术产品,又是国家顶级的院士和计算机教授的工作成果,这个表现也是有些差强人意了。感觉同样花个几亿RMB去找个软件公司干的都不见得比这个差,不过这也是个人的愚见罢了。
第二部分
虽然AMiner提供了部分的人工补充数据的途径,不过对于数据的校准、对齐并没有什么用,那么在技术条件无法解决的情况下是否可以使用人力来完成如此大的数据校准和对齐呢,我想是可以的,那就是数据众包以及多人协作。像一些机器学习中的图像识别的大型数据集的标注任务最初也是使用数据众包的形式来实现的,有时候对于必须人工来识别的大型任务我们往往可以使用众包的形式,这也是目前唯一可行的一条途径。
像wiki百科那样使用多人协作编辑的方式,实现数据编辑的众包化,或许是实现学术图谱检索网站的消歧和去重的最可行的非技术方案。如果wiki百科没有成功之前,那是谁也无法想象到如此疯狂的设计居然可行,而且自控和运行状况都还挺好。当然对于学术领域的学者和成果的匹配问题上往往需要较为专业的人士,这部分确实难度较大,尤其这种开源方式的编辑与最后的商业网站的运营是有所矛盾的,但是我想这也是可以解决的,同时考虑到学术匹配的专业性设置一定的审查和管理员也是需要的,而现有的学术匹配网站都是官方自己控制所有的内容编辑权限,而这部分权限在可控的前提下适当的下放或许是更好的运营模式。
而且学术匹配网站也是应该借鉴researchGate网站的,说直白些就是要构建一个学术人事进行成果展示、交流,甚至是共享的这样的一个网站,这样也能实现人人参与的目的,吸引大量的学者自发的参与进来去修正自己的页面和成果list。不论是是ResearchGate还是orcid,其基本思想就是构建一个自发的参与信息编辑、认证、交换的环境,如果能像wiki那样还能同时引入其他的学者对自己了解的学者及其成果的编辑就更能填补很大的空缺,或许只有这种我为人人,人人为我的这种开源、协作的方式才能更好的构建起一个学术匹配网络。
除了参考其他比较成功的相关网站产品,我们也可以考虑奖赏机制,如悬赏补充数据,对共享度进行量并评级,对优秀的贡献者给予一定的头衔和积分奖励等,如果奖励不好给也可以像中国知网给学位论文的稿酬一样用知网积分嘛,虽然感觉这积分不太有用,但是毕竟总是有个东西给的嘛。总之要想解决学术匹配的消重、消歧,往往是技术上难以实现的,就像imagenet数据集一样,不搞众包标注是永远无法推进的,要想在技术无法解决的情况下靠人力完成就需要有一个很好的机制,来激发和吸引人们参加,否则这东西就是难以完成的。
==================================
AMiner的数据质量和完善问题的更多相关文章
- 【转载】改善数据质量从数据剖析(Data Profiling)开始
市场研究公司Forrester副总裁Erin Kinikin曾经把低劣的数据质量做了一个形象的比喻“用更好的方法访问劣质的数据,结果类似于把已经腐烂了的桃子用更快的卡车,走更好的路线运输到达市场时,桃 ...
- FME之于规划CAD数据质量检测
最近琢磨规划CAD数据转换入库GIS方面的技术问题,看过一些前辈的文章/文献,对于使用FME WorkBench方面,有了一些了解,往往直接转换数据丢失比较严重,而且GIS对图形属性和空间拓扑比较严格 ...
- cognos开发与部署报表到广西数据质量平台
1.cognos报表的部署. 参数制作的步骤: 1.先在cognos里面把做好的报表路径拷贝,然后再拷贝陈工给的报表路径. 开始做替换,把陈工给的报表路径头拿到做好的报表路径中,如下面的链接http: ...
- TOP100summit:【分享实录-Microsoft】基于Kafka与Spark的实时大数据质量监控平台
本篇文章内容来自2016年TOP100summit Microsoft资深产品经理邢国冬的案例分享.编辑:Cynthia 邢国冬(Tony Xing):Microsoft资深产品经理.负责微软应用与服 ...
- 如何在HHDI中进行数据质量探查并获取数据剖析报告
通过执行多种数据剖析规则,对目标表(或一段SQL语句)进行数据质量探查,从而得到其数据质量情况.目前支持以下几种数据剖析类型,分别是:数字值分析.值匹配检查.字符值分析.日期值分析.布尔值分析.重复值 ...
- 数据质量控制软件Q-CHECKER(转)
随着企业信息化建设的不断深入进行,我们的企业将逐步地发展成为数字化企业.其中作为最基本构成的CATIA数模已经是产品开发制造的唯一依据,CATIA数模的质量就是加工的质量,就是制造的质量,就是生产出的 ...
- 数据质量、特征分析及一些MATLAB函数
MATLAB数据分析工具箱 MATLAB工具箱主要含有的类别有: 数学类.统计与优化类.信号处理与通信类.控制系统设计与分析类.图像处理类.测试与测量类.计算金融类.计算生物类.并行计算类.数据库访问 ...
- 数据可视化之powerBI基础(十六)PowerQuery的这个小功能,让你轻松发现数据质量问题
https://zhuanlan.zhihu.com/p/64418072 源数据常常包含各种差错值,为了进行下一步的分析,我们必须先找出并更正这些差错,做这些工作几乎不会有什么快乐感可言,但却往往需 ...
- kettle数据质量统计
1.利用Kettle的"分组","JavaScript代码","字段选择"组件,实现数据质量统计.2.熟练掌握"JavaScrip ...
- 开源数据质量解决方案——Apache Griffin入门宝典
提到格里芬-Griffin,大家想到更多的是篮球明星或者战队名,但在大数据领域Apache Griffin(以下简称Griffin)可是数据质量领域响当当的一哥.先说一句:Griffin是大数据质量监 ...
随机推荐
- wpfui:一个开源免费具有现代化设计趋势的WPF控件库
wpfui介绍 wpfui是一款开源免费(MIT协议)具有现代化设计趋势的WPF界面库.wpfui为wpf的界面开发提供了流畅的体验,提供了一个简单的方法,让使用WPF编写的应用程序跟上现代设计趋势. ...
- RestApi请求地址支持多路径访问
RestApi请求地址支持多路径访问 @RestController@RequestMapping("/test") //单路径@RequestMapping(path = {&q ...
- windows10下安装mysql8.0.25
只是安装一个练习用的库,所以基本配置没有什么好说的. # this is a config file for mysql [mysqld] # 设置3306端口 port=7799 # 设置mysql ...
- nginx 反向代理(proxy)与负载均衡(upstream)应用实践
集群介绍 集群就是指一组(若干个)相互独立的计算机,利用高速通信网络组成的一个较大的计算机服务系统,每个集群节点(即集群中的每台计算机)都是运行各自服务的独立服务器.这些服务器之间可以彼此通信,协同向 ...
- Linux 内核:设备驱动模型(5)平台设备驱动
Linux 内核:设备驱动模型(5)平台设备驱动 背景 我们已经大概熟悉了Linux Device Driver Model:知道了流程大概是怎么样的,为了加深对LDDM框架的理解,我们继续来看pla ...
- 《DNK210使用指南 -CanMV版 V1.0》第三章 CanMV简介
第三章 CanMV简介 1)实验平台:正点原子DNK210开发板 2) 章节摘自[正点原子]DNK210使用指南 - CanMV版 V1.0 3)购买链接:https://detail.tmall.c ...
- B码对时方案,基于TI AM62x异构多核工业处理器实现!
什么是IRIG-B码对时 IRIG-B(inter-range instrumentationgroup-B)码是一种时间同步标准,通常用于精确的时间测量和数据同步,广泛应用于电力.通信.航空等领域. ...
- 自己写一个 NODE/ATTR 的结构
## python 3.8 以上 from typing import Dict, List, TypeVar, Tuple, Generic, get_args import json T = Ty ...
- Unity 中使用Geomotry Shader(几何着色器)扩展点创建其他图形(并实现处理锯齿)
问题背景: 我们开发中需要有"点"对象,可以是像素的(不具备透视效果),始终等大,还有就是3D场景下的矢量点(随相机距离透视变化的). 问题解决思路: 方案1:使用GS扩充顶点,并 ...
- 本地自建KMS服务器
本地自建KMS服务器 本地自建KMS服务器 一.前期准备 下载安装以下软件.文件: VMware Github中的开源项目:vlmcsd 二.在VMware下部署KMS服务器 解压vlmcsd项目中r ...