【python爬虫案例】用python爬豆瓣电影TOP250排行榜!
一、爬虫对象-豆瓣电影TOP250
前几天,我分享了一个python爬虫案例,爬取豆瓣读书TOP250数据:【python爬虫案例】用python爬豆瓣读书TOP250排行榜!
今天,我再分享一期,python爬取豆瓣电影TOP250数据!
爬虫大体流程和豆瓣读书TOP250类似,细节之处见逻辑。
首先,打开豆瓣电影TOP250的页面:https://movie.douban.com/top250
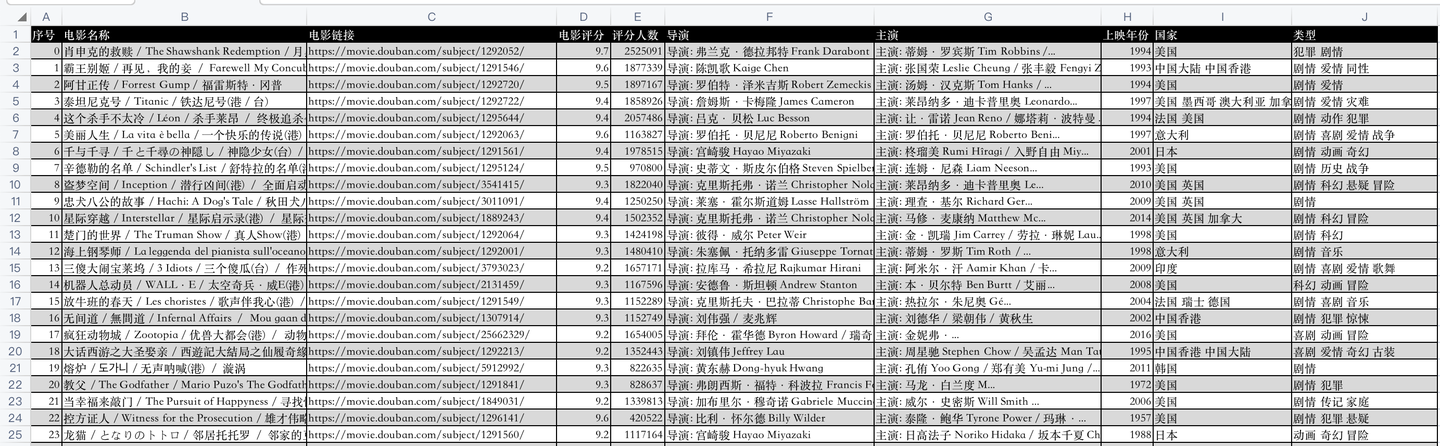
开发好python爬虫代码后,爬取成功后的csv数据,如下:
代码是怎样实现的爬取呢?下面逐一讲解python核心代码。
二、python爬虫代码讲解
首先,导入需要用到的库:
import requests # 发送请求
from bs4 import BeautifulSoup # 解析网页
import pandas as pd # 存取csv
from time import sleep # 等待时间
然后,向豆瓣电影网页发送请求:
res = requests.get(url, headers=headers)
利用BeautifulSoup库解析响应页面:
soup = BeautifulSoup(res.text, 'html.parser')
用BeautifulSoup的select函数,(css解析的方法)编写代码逻辑,部分核心代码:
for movie in soup.select('.item'):
name = movie.select('.hd a')[0].text.replace('\n', '') # 电影名称
movie_name.append(name)
url = movie.select('.hd a')[0]['href'] # 电影链接
movie_url.append(url)
star = movie.select('.rating_num')[0].text # 电影评分
movie_star.append(star)
star_people = movie.select('.star span')[3].text # 评分人数
star_people = star_people.strip().replace('人评价', '')
movie_star_people.append(star_people)
其中,需要说明的是,《大闹天宫》这部电影和其他电影页面排版不同:

它的上映年份有3个(其他电影只有1个上映年份),并且以"/"分隔,正好和国家、电影类型的分割线冲突,
所以,这里特殊处理一下:
if name == '大闹天宫 / 大闹天宫 上下集 / The Monkey King': # 大闹天宫,特殊处理
year0 = movie_infos.split('\n')[1].split('/')[0].strip()
year1 = movie_infos.split('\n')[1].split('/')[1].strip()
year2 = movie_infos.split('\n')[1].split('/')[2].strip()
year = year0 + '/' + year1 + '/' + year2
movie_year.append(year)
country = movie_infos.split('\n')[1].split('/')[3].strip()
movie_country.append(country)
type = movie_infos.split('\n')[1].split('/')[4].strip()
movie_type.append(type)
最后,将爬取到的数据保存到csv文件中:
def save_to_csv(csv_name):
"""
数据保存到csv
:return: None
"""
df = pd.DataFrame() # 初始化一个DataFrame对象
df['电影名称'] = movie_name
df['电影链接'] = movie_url
df['电影评分'] = movie_star
df['评分人数'] = movie_star_people
df['导演'] = movie_director
df['主演'] = movie_actor
df['上映年份'] = movie_year
df['国家'] = movie_country
df['类型'] = movie_type
df.to_csv(csv_name, encoding='utf_8_sig') # 将数据保存到csv文件
其中,把各个list赋值为DataFrame的各个列,就把list数据转换为了DataFrame数据,然后直接to_csv保存。
这样,爬取的数据就持久化保存下来了。
三、同步视频
同步讲解视频:【python爬虫】利用python爬虫爬取豆瓣电影TOP250的数据!
四、获取完整源码
附完整源码:【python爬虫案例】利用python爬虫爬取豆瓣电影TOP250的数据!
我是 @马哥python说 ,持续分享python源码干货中!
【python爬虫案例】用python爬豆瓣电影TOP250排行榜!的更多相关文章
- Python 爬取豆瓣电影Top250排行榜,爬虫初试
from bs4 import BeautifulSoup import openpyxl import re import urllib.request import urllib.error # ...
- python爬虫1——获取网站源代码(豆瓣图书top250信息)
# -*- coding: utf-8 -*- import requests import re import sys reload(sys) sys.setdefaultencoding('utf ...
- Scrapy爬豆瓣电影Top250并存入MySQL数据库
d:进入D盘 scrapy startproject douban创建豆瓣项目 cd douban进入项目 scrapy genspider douban_spider movie.douban.co ...
- [151116 记录] 使用Python3.5爬取豆瓣电影Top250
这一段时间,一直在折腾Python爬虫.已有的文件记录显示,折腾爬虫大概个把月了吧.但是断断续续,一会儿鼓捣python.一会学习sql儿.一会调试OpenCV,结果什么都没学好.前几天,终于耐下心来 ...
- 练习:一只豆瓣电影TOP250的爬虫
练习:一只豆瓣电影TOP250爬虫 练习:一只豆瓣电影TOP250爬虫 ①创建project ②编辑items.py import scrapyclass DoubanmovieItem(scrapy ...
- Python爬虫入门:爬取豆瓣电影TOP250
一个很简单的爬虫. 从这里学习的,解释的挺好的:https://xlzd.me/2015/12/16/python-crawler-03 分享写这个代码用到了的学习的链接: BeautifulSoup ...
- python 爬虫&爬取豆瓣电影top250
爬取豆瓣电影top250from urllib.request import * #导入所有的request,urllib相当于一个文件夹,用到它里面的方法requestfrom lxml impor ...
- python爬虫 Scrapy2-- 爬取豆瓣电影TOP250
sklearn实战-乳腺癌细胞数据挖掘(博主亲自录制视频) https://study.163.com/course/introduction.htm?courseId=1005269003& ...
- Python爬虫----抓取豆瓣电影Top250
有了上次利用python爬虫抓取糗事百科的经验,这次自己动手写了个爬虫抓取豆瓣电影Top250的简要信息. 1.观察url 首先观察一下网址的结构 http://movie.douban.com/to ...
- 【Python爬虫】:使用高性能异步多进程爬虫获取豆瓣电影Top250
在本篇博文当中,将会教会大家如何使用高性能爬虫,快速爬取并解析页面当中的信息.一般情况下,如果我们请求网页的次数太多,每次都要发出一次请求,进行串行执行的话,那么请求将会占用我们大量的时间,这样得不偿 ...
随机推荐
- KingbaseESV8R6中查看索引常用sql
前言 KingbaseES具有丰富的索引功能,对于运行一段时间的数据库,经常需要查看索引的使用大小,使用状态等. 尤其重复索引的存在,有时会因为索引过多而造成维护成本加大和减慢数据库的运行速度. 下面 ...
- KingbaseES V8R6运维案例之---wal日志解析DDL操作
案例说明: 通过sys_waldump解析DDL操作,获取DDL操作的日志条目具体内容. 适用版本: KingbaseES V8R3/R6 一.DDL事务操作对应的wal日志文件 # 查看当前on ...
- Hybrid-PSC:基于对比学习的混合网络,解决长尾图片分类 | CVPR 2021
论文提出新颖的混合网络用于解决长尾图片分类问题,该网络由用于图像特征学习的对比学习分支和用于分类器学习的交叉熵分支组成,在训练过程逐步将训练权重调整至分类器学习,达到更好的特征得出更好的分类器的思想 ...
- springboot3接入nacos
参考:https://blog.csdn.net/qinguan111/article/details/132877842(连接不上nacos) https://verytoolz.com/yaml- ...
- k8s CustomResourceDefinition invalid 错误
安装 CRD 出现这个错误,多数是版本问题,缺少openAPIV3Schema段定义. The CustomResourceDefinition "crontabs.stable.examp ...
- Android Button 点击事件
Ctrl+Alt+Space(空格键) 可以显示提示内容
- ET8.1(一)简介
此系列文章逐个内容讲解ET8.1的新特性. ET8.1 发布,带来以下新特性: 1. 多线程多进程架构,架构更加灵活强大,多线程设计详细内容请看多线程设计课程 2. 抽象出纤程(Fiber)的概念 ...
- Keycloak中授权的实现
在Keycloak中实现授权,首先需要了解与授权相关的一些概念.授权,简单地说就是某个(些)用户或者某个(些)用户组(Policy),是否具有对某个资源(Resource)具有某种操作(Scope)的 ...
- Access Single User Mode (Reset Root Password)--CentOS 修改root密码
Access Single User Mode (Reset Root Password) Published on: Wed, Sep 17, 2014 at 12:52 pm EST FAQ L ...
- MVC 下拉选项实现的几种方式
主要介绍4种方式 硬编码方式: ViewBag.hard_value = new List<SelectListItem>() { new SelectListItem(){Value=& ...