scikit-learn.datasets 机器学习库
scikit-learn是一个用于Python的机器学习库,提供了大量用于数据挖掘和数据分析的工具。以下是对这些函数和方法的简要描述:
clear_data_home: 清除数据集目录的内容。dump_svmlight_file: 将数据集保存为SVMLight格式的文件。fetch_20newsgroups: 下载20个新闻组的文本数据集。fetch_20newsgroups_vectorized: 下载并矢量化20个新闻组的文本数据集。fetch_lfw_pairs: 下载Labeled Faces in the Wild的成对图像。fetch_lfw_people: 下载Labeled Faces in the Wild的图像集。fetch_olivetti_faces: 下载Olivetti人脸数据集。fetch_species_distributions: 下载物种分布数据集。fetch_california_housing: 下载加州房价数据集。fetch_covtype: 下载Covtype数据集,这是一个用于分类土地覆盖类型的数据集。fetch_rcv1: 下载RCV1数据集,这是一个文本分类数据集。fetch_kddcup99: 下载KDD Cup '99数据集,这是一个用于网络入侵检测的数据集。fetch_openml: 从OpenML数据库中获取数据集。get_data_home: 获取或设置数据集的存储路径。load_diabetes,load_digits,load_files,load_iris,load_breast_cancer,load_linnerud,load_sample_image,load_wine: 这些函数用于加载特定内置的数据集。make_biclusters,make_circles,make_classification,make_checkerboard,make_friedman1, ...make_swiss_roll: 这些是用于生成模拟数据的函数,用于测试和验证算法。
常用的函数包括:
fetch_20newsgroups: 用于获取新闻组数据集,常用于文本分类任务。fetch_california_housing: 用于获取加州房价数据集,常用于回归任务。load_iris: 用于加载鸢尾花数据集,常用于分类任务。make_classification: 用于生成模拟的二分类或多分类数据集,常用于测试分类算法。
这些函数和方法为机器学习提供了大量的数据集,使得用户可以快速地测试和验证其算法和模型。
内置的数据集
这些函数都是来自 sklearn.datasets 模块,用于加载不同的数据集。下面是每个函数的简要描述和常用的数据集:
load_diabetes:这个函数用于加载糖尿病数据集,通常用于回归分析。这个数据集包含从1991年到1994年的糖尿病患者的信息,如年龄、性别、体重、血压等。load_digits:这个函数用于加载手写数字数据集。它包含了1797个手写数字图片,每个图片的大小为8x8像素,每个像素的灰度值在0-15之间。这个数据集通常用于图像处理和机器学习中的分类任务。load_files:这个函数用于加载文件数据集,通常用于文件存储和读取。load_iris:这个函数用于加载鸢尾花数据集。这个数据集包含了150个样本,每个样本有四个特征(花萼长度、花萼宽度、花瓣长度、花瓣宽度),用于分类三种鸢尾花。这个数据集是机器学习和数据挖掘领域中最著名的数据集之一。load_breast_cancer:这个函数用于加载乳腺癌数据集,通常用于二分类问题(良性和恶性)。这个数据集包含了683个样本,每个样本有30个特征。load_linnerud:这个函数用于加载Linnerud数据集,通常用于多变量回归分析。这个数据集包含了30个样本,每个样本有6个特征和3个目标变量。load_sample_image和load_sample_images:这两个函数用于加载样本图像数据集,通常用于图像处理和机器学习中的分类任务。load_svmlight_file和load_svmlight_files:这两个函数用于加载SVMlight格式的数据集,通常用于支持向量机分类和回归任务。load_wine:这个函数用于加载葡萄酒数据集,通常用于分类任务。这个数据集包含了178个样本,每个样本有13个特征,用于分类三种葡萄酒类型。
常用的数据集包括 load_iris, load_digits, load_wine, load_breast_cancer 等。这些数据集在机器学习和数据分析领域中非常常见,可用于演示算法、训练模型和测试模型性能等。
from sklearn import datasets
iris = datasets.load_iris()
模拟数据集
这些函数都是来自 sklearn.datasets 模块,用于生成模拟数据集。下面是对每个函数的简要解释,以及哪些是常用的:
make_biclusters:生成一个二聚类数据集。不常用。make_blobs:生成一个简单的二维聚类数据集。常用,主要用于演示聚类算法。make_circles:生成一个表示圆形的二分类数据集。不常用。make_classification:生成模拟的二分类或多分类数据集。常用,主要用于分类算法的演示。make_checkerboard:生成一个棋盘图案的数据集。不常用。make_friedman1,make_friedman2,make_friedman3:生成弗里德曼数据集,主要用于回归分析。不常用。make_gaussian_quantiles:生成高斯分布但具有不同分位数的高斯分布数据。不常用。make_hastie_10_2:生成一个10x2的二分类数据集,主要用于决策树的训练。不常用。make_low_rank_matrix:生成一个低秩矩阵,通常用于矩阵分解或低秩表示的算法。不常用。make_moons:生成半月形状的二分类数据集。不常用。make_multilabel_classification:生成多标签分类的数据集。不常用。make_regression:生成用于线性回归的仿真数据集。常用,主要用于回归分析的演示。make_s_curve:生成一个S形的二分类数据集。不常用。make_sparse_coded_signal:生成稀疏编码信号的数据集。不常用。make_sparse_spd_matrix:生成稀疏对称正定矩阵。不常用。make_sparse_uncorrelated:生成稀疏且不相关的数据集。不常用。make_spd_matrix:生成对称正定矩阵。不常用。make_swiss_roll:生成瑞士卷形状的数据集,通常用于流形学习算法的演示。不常用。
常用的有 make_blobs, make_classification, 和 make_regression,因为这些数据集经常用于基础机器学习算法的演示和验证。
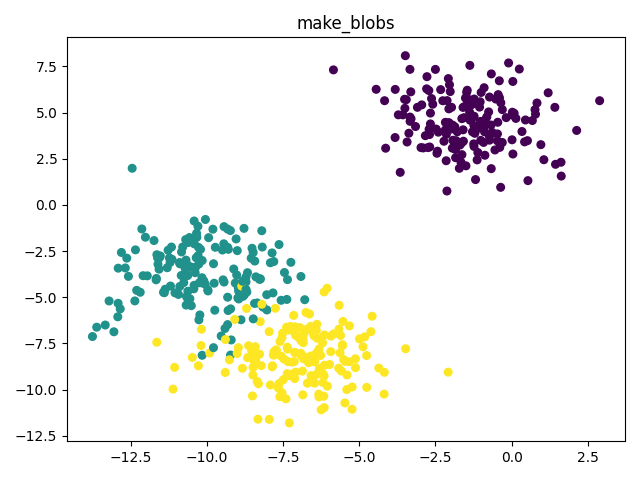
make_blobs 二维聚类数据集
sklearn.datasets.make_blobs(
n_samples=100, # 样本数量
n_features=2, # 特征数量
centers=None, # 中心个数 int,就是有几堆数据
cluster_std=1.0, # 聚簇的标准差
center_box(-10.0, 10.0), # 聚簇中心的边界框
shuffle=True, # 是否洗牌样本
random_state=None #随机种子
)
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs
import numpy as np
X, y = make_blobs(n_samples=500,
n_features=2,
centers=3,
cluster_std=1.5,
random_state=1)
plt.figure()
plt.title('make_blobs')
plt.scatter(X[:, 0], X[:, 1], marker='o', c=np.squeeze(y), s=30)
plt.show()
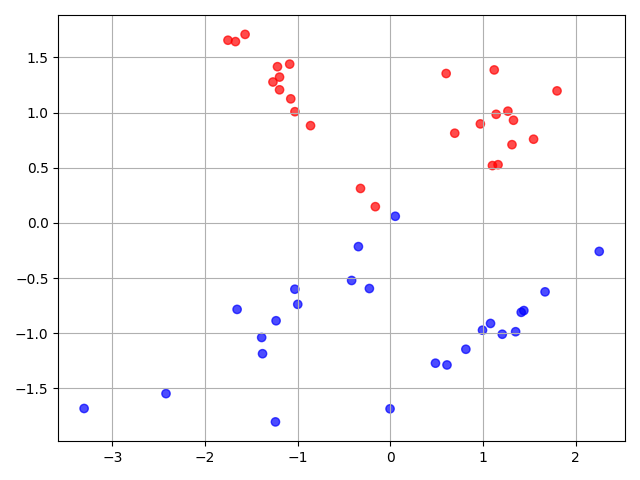
make_classification 二分类或多分类数据集
sklearn.datasets.make_classification(
n_samples=100, # 样本个数
n_features=20, # 数据的特征量数,数据是一列还是几列
n_informative=2, # 有效特征个数
n_redundant=2, # 冗余特征个数(有效特征的随机组合)
n_repeated=0, # 重复特征个数(有效特征和冗余特征的随机组合)
n_classes=2, # 分类数量,默认为2
n_clusters_per_class=2, # 蔟的个数
weights=None, # 每个类的权重 用于分配样本点
flip_y=0.01, # 随机交换样本的一段 y噪声值的比重
class_sep=1.0, # 类与类之间区分清楚的程度
hypercube=True, # 如果为True,则将簇放置在超立方体的顶点上;如果为False,则将簇放置在随机多面体的顶点上。
shift=0.0, # 将各个特征的值移动,即加上或减去某个值
scale=1.0, # 将各个特征的值乘上某个数,放大或缩小
shuffle=True, # 是否洗牌样本
random_state=None) # 随机种子
from sklearn.datasets import make_classification
import matplotlib.pyplot as plt
import matplotlib
X, y = make_classification(n_samples=50, n_features=2, n_redundant=0, random_state=0)
plt.scatter(X[:, 0], X[:, 1], c=y, cmap=matplotlib.cm.get_cmap(name="bwr"), alpha=0.7)
plt.grid(True)
plt.show()
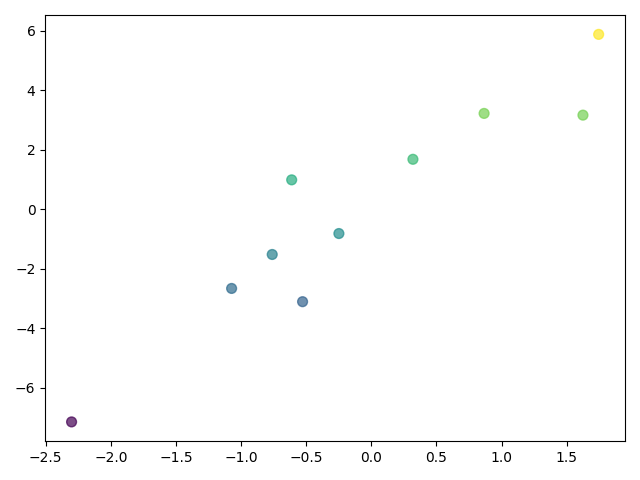
make_regression 线性回归的仿真数据集
sklearn.datasets.make_regression(
n_samples=100, #样本数
n_features=100, #特征数(自变量个数)
n_informative=10, #参与建模特征数
n_targets=1, #因变量个数
bias=0.0, #偏差(截距)
effective_rank=None,
tail_strength=0.5,
noise=0.0, #噪音
shuffle=True,
coef=False, #是否输出coef标识
random_state=None # 随机种子
)
import matplotlib.pyplot as plt
import matplotlib
from sklearn.datasets import make_regression
X, y = make_regression(n_samples=10, n_features=1, n_targets=1, noise=1.5, random_state=1)
plt.scatter(X, y, c=y, s=50, cmap=matplotlib.cm.get_cmap(name='viridis'), alpha=0.7)
plt.show()
注:随机种子
种子的取值范围通常是一个整数,其具体取值会根据不同的随机数生成方法而有所不同。在Python的 numpy 库中,RandomState 对象的种子参数通常是一个非负整数。这个种子值用于初始化随机数生成器的状态,从而确定将要生成的随机数序列。
一般来说,种子的取值范围可以是从0到任何正数的整数,但具体取值范围可能受到实现细节或特定算法的限制。如果种子值太大或太小,可能会导致生成随机数序列的质量下降或无法生成随机数。因此,在实际应用中,需要根据具体需求和算法的要求来选择合适的种子值。
确定随机数种子的大小并没有固定的规则,因为这取决于具体的应用场景和需求。以下是一些可能影响种子大小选择的因素:
- 随机性需求:如果需要更强的随机性,可以选择较大的种子值。较大的种子值可以增加随机数生成器的初始状态,从而产生更随机的随机数序列。
- 可重复性需求:如果需要实验或模拟的可重复性,可以选择较小的种子值。较小的种子值可以使随机数生成器具有较小的初始状态,从而产生更可预测的随机数序列。
- 算法和实现细节:不同的随机数生成算法和实现细节可能会有不同的种子取值范围和要求。因此,在选择种子值时,需要了解所使用的算法和实现细节的要求。
- 测试和调试:在开发和测试阶段,可能需要对不同的种子值进行测试和调试,以确定最佳的种子值。
总的来说,确定种子值的大小需要根据具体的需求和应用场景进行权衡和选择。如果需要更强的随机性,可以选择较大的种子值;如果需要实验或模拟的可重复性,可以选择较小的种子值。同时,需要考虑算法和实现细节的要求,并进行适当的测试和调试。
https://scikit-learn.org/stable/modules/classes.html#module-sklearn.datasets
scikit-learn.datasets 机器学习库的更多相关文章
- Python第三方库(模块)"scikit learn"以及其他库的安装
scikit-learn是一个用于机器学习的 Python 模块. 其主页:http://scikit-learn.org/stable/. GitHub地址: https://github.com/ ...
- Scikit Learn: 在python中机器学习
转自:http://my.oschina.net/u/175377/blog/84420#OSC_h2_23 Scikit Learn: 在python中机器学习 Warning 警告:有些没能理解的 ...
- (原创)(四)机器学习笔记之Scikit Learn的Logistic回归初探
目录 5.3 使用LogisticRegressionCV进行正则化的 Logistic Regression 参数调优 一.Scikit Learn中有关logistics回归函数的介绍 1. 交叉 ...
- (原创)(三)机器学习笔记之Scikit Learn的线性回归模型初探
一.Scikit Learn中使用estimator三部曲 1. 构造estimator 2. 训练模型:fit 3. 利用模型进行预测:predict 二.模型评价 模型训练好后,度量模型拟合效果的 ...
- [Python & Machine Learning] 学习笔记之scikit-learn机器学习库
1. scikit-learn介绍 scikit-learn是Python的一个开源机器学习模块,它建立在NumPy,SciPy和matplotlib模块之上.值得一提的是,scikit-learn最 ...
- 常用python机器学习库总结
开始学习Python,之后渐渐成为我学习工作中的第一辅助脚本语言,虽然开发语言是Java,但平时的很多文本数据处理任务都交给了Python.这些年来,接触和使用了很多Python工具包,特别是在文本处 ...
- [Python] 机器学习库资料汇总
声明:以下内容转载自平行宇宙. Python在科学计算领域,有两个重要的扩展模块:Numpy和Scipy.其中Numpy是一个用python实现的科学计算包.包括: 一个强大的N维数组对象Array: ...
- [resource]Python机器学习库
reference: http://qxde01.blog.163.com/blog/static/67335744201368101922991/ Python在科学计算领域,有两个重要的扩展模块: ...
- scikit learn 模块 调参 pipeline+girdsearch 数据举例:文档分类 (python代码)
scikit learn 模块 调参 pipeline+girdsearch 数据举例:文档分类数据集 fetch_20newsgroups #-*- coding: UTF-8 -*- import ...
- sklearn:Python语言开发的通用机器学习库
引言:深入理解机器学习并全然看懂sklearn文档,须要较深厚的理论基础.可是.要将sklearn应用于实际的项目中,仅仅须要对机器学习理论有一个主要的掌握,就能够直接调用其API来完毕各种机器学习问 ...
随机推荐
- 部署堡垒机6——配置Nginx及其他组件
Lina部署 cd /opt wget https://github.com/jumpserver/lina/releases/download/v2.28.7/lina-v2.28.7.tar.gz ...
- JavaImprove--Lesson06--正则表达式
一.正则表达式的入门 正则表达式是一些特定支付组成的,代表一个规则,简化代码,以字符的形式体现规则 正则表达式,又称规则表达式,(Regular Expression,在代码中常简写为regex.re ...
- 2021平(jia)凡(ban)的一年
0x00 刚刚把<平凡的世界>电视剧看完.也不知道什么原因,又去刷了一遍, 可能是有那么一段时间比较迷茫.加班加到怀疑人生了吧. 记得当年第一次看这本小说还是17年,好像是为了借一本什么书 ...
- 浅学GoF23种设计模式
long long ago 买了设计模式的书,一直没看,平常工作虽然涉及到,但是不够系统,工作之余抽空学习一下. 一.创建型模式 01.单例(Singleton) 02.工厂方法(Factory Me ...
- 复杂查询so easy ,GaussDB(for Cassandra)推Lucene引擎全新解决方案
摘要:复杂查询so easy!GaussDB(for Cassandra)新特性来袭. 本文分享自华为云社区<来了!GaussDB(for Cassandra)新特性亮相>,作者:Gaus ...
- 论文解读:ACL2021 NER | 基于模板的BART命名实体识别
摘要:本文是对ACL2021 NER 基于模板的BART命名实体识别这一论文工作进行初步解读. 本文分享自华为云社区<ACL2021 NER | 基于模板的BART命名实体识别>,作者: ...
- vite/storybook/rollup搭建一个自己的组件库
构建测试项目 首先vite 初始化一个项目 vue create story-book-demo ## 或者 vue create story-book-demo 然后添加storybook ,具体参 ...
- 字节跳动基于 Apache Hudi 的多流拼接实践方案
字节跳动数据湖团队在实时数仓构建宽表的业务场景中,探索实践出的一种基于 Hudi Payload 的合并机制提出的全新解决方案. 字节跳动数据湖团队在实时数仓构建宽表的业务场景中,探索实践出的一种基于 ...
- 火山引擎 DataTester:在广告投放场景下的 A/B 实验实践
更多技术交流.求职机会,欢迎关注字节跳动数据平台微信公众号,回复[1]进入官方交流群 "我知道在广告上的投资有一半是无用的,但问题是我不知道是哪一半." --零售大亨约翰·沃纳梅克 ...
- VA21 创建报价单
1.前台 报价是提供给客户交付货物或服务的一份文件,客户想要知道产品价格以及装运时间. 事务代码VA21 输入报价单类型和销售组织.分销渠道.产品组 输入售达方和行项目的物料信息,订购数量等信息 输入 ...