[转帖]从理论到实践,异步I/O模式下NVMe SSD高性能之道
在早期NVMe的讨论话题中,常常将之AHCI协议进行对比,在支持的最大队列深度、并发进程数以及消耗时钟周期数等方面,NVMe吊打了AHCI。最直观也最权威的就是下面这张对比图片。

NVMe与AHCI协议对比(来源:sata-io.org)
SATA的发展最早可以追溯到上世纪80年代的IDE/ATA,在HDD时代是硬盘最主流的存储接口。SATA Express采用AHCI协议将硬盘映射成一个PCIe设备以提高系统性能。但是第三代SATA的带宽也只有6Gb/s,无法彻底释放闪存的性能。当SSD接口由SATA被PCIe取代之后,一个更加高效的存储接口协议诞生是必然,这就是NVMe。(更多细节可以看文末相关阅读文章)
PCIe和NVMe组合提高了SSD的性能上限,一块SATA SSD无论如何带宽也不会突破1GB/s以及稳定的微秒级延迟。是否能达到这个上限,就需要看SSD本身的软硬件设计水平了。
NVMe SSD的高性能可以直接反映到测试基准测试的结果上,需要注意的是测试NVMe SSD的特点是遇强则强,需要高压力方可看到性能效果。接下来就是用fio通过几组测试来解读NVMe SSD的性能优势。当然,这些测试也将为系统性能优化提供理论基础。
在写fio脚本之前,还需要注意同步I/O和异步I/O的概念,这也是本文测试压力模型中的重要变量。同步I/O是指系统的一个线程一次只能发出一个I/O,等待内核处理完成才返回结果,系统再发下一个I/O。异步I/O模式是系统的线程不停的发I/O直到达到设置的队列深度上限,此期间,线程SSD通知会通过中断或者轮询等方式告诉CPU,CPU来调用该命令的回调函数来处理结果。原生的异步I/O技术以Linux下的libaio和Windows下的windowsaio最为常见。
测试软件:fio
NVMe SSD:PBlaze5 910 7.68TB
依据同步I/O和异步I/O的原理,我们可以总结出几个结论。
第一:同步模式下增加I/O队列深度并不能得到更高的性能,因为其机制只能1次发1个I/O。而通过增加线程数才可以获得更大的压力;
第二:异步I/O模式可以通过调整队列深度提升压力,例如同步模式下32个线程并发和异步I/O模式下1个线程32队列深度的测试结果应当相同,而且通过提高线程数异步I/O模式可以进一步提高压力;
第三,对于高性能的NVMe SSD,使用异步I/O模式更容易获得高性能收益。
使用fio可以方便的选择I/O引擎并对并发进程数和队列深度等参数进行设置。接下来就是验证上面的三个观点。验证测试前,我们需要先进行预处理,全盘顺序写2遍然后随机写4个小时,命令如下:
fio --ioengine=libaio --direct=1 --thread --norandommap --filename=/dev/nvme1n1 --name=init_seq2 --output=init_seq2.log --rw=write --bs=128k --numjobs=1 --iodepth=128 --loops=2
fio --ioengine=libaio --direct=1 --thread --norandommap --filename=/dev/nvme1n1 --name=init_rand --output=init_rand.log --rw=randwrite --bs=4k --numjobs=8 --iodepth=64 --ramp_time=60 --runtime=14400
1、 使用同步io模式,我们测出了一组数据,并取得了IOPS的值。如下:
fio --ioengine=psync --randrepeat=0 --norandommap --thread --direct=1 --group_reporting --name=mytest --ramp_time=1 --runtime=432 --time_based --numjobs=8 --iodepth=1 --filename=/dev/nvme0n1 --rw=randread --bs=4k
我们改变下iodepth和numjobs,测几组不同的值对比。
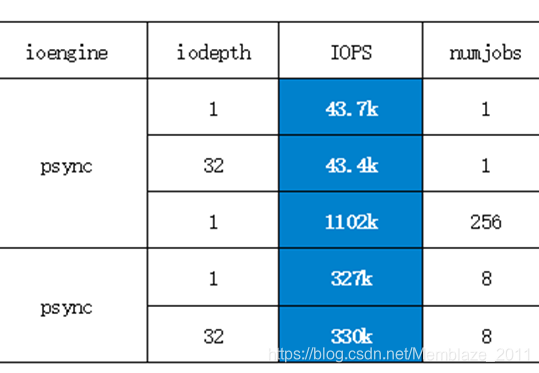
可以看到当相同的numjobs参数下,SSD的IOPS性能处于同一水平,只有改并发进程数会改变性能。这验证了我们前文中的第一个观点,接下来我们将测试的重点放在异步IO模式下的测试。
本次系列测试均为4K随机读测试,nubjobs(并发进程数)和iodepth(队列深度)是各测试的两个主要变量,可以说两者的乘积决定了各组测试的压力大小。而psync(同步IO模式)和libaio(异步IO模式)决定了大于1的iodepth是否有效。
2、 异步I/O、队列深度:64、并发线程数:8
fio --ioengine=libaio --randrepeat=0 --norandommap --thread --direct=1 --stonewall --group_reporting --name=mytest --ramp_time=60 --runtime=600 --time_based --numjobs=8 --iodepth=64 --filename=/dev/nvme1n1 --rw=randread --bs=4k --output=256-4K_randR512.log
测试结果如下(IOPS:1007.5k):
mytest: (g=0): rw=randread, bs=4K-4K/4K-4K/4K-4K, ioengine=libaio, iodepth=64
…
fio-2.2.9
Starting 8 threads
mytest: (groupid=0, jobs=8): err= 0: pid=11418: Sun May 5 17:24:27 2019
read : io=2305.1GB, bw=3935.5MB/s, iops=1007.5K, runt=600001msec
slat (usec): min=1, max=340, avg= 3.54, stdev= 1.72
clat (usec): min=21, max=2204, avg=504.18, stdev=183.15
lat (usec): min=23, max=2208, avg=507.85, stdev=183.15
clat percentiles (usec):
| 1.00th=[ 177], 5.00th=[ 233], 10.00th=[ 278], 20.00th=[ 338],
| 30.00th=[ 390], 40.00th=[ 442], 50.00th=[ 490], 60.00th=[ 540],
| 70.00th=[ 596], 80.00th=[ 660], 90.00th=[ 756], 95.00th=[ 828],
| 99.00th=[ 972], 99.50th=[ 1032], 99.90th=[ 1144], 99.95th=[ 1208],
| 99.99th=[ 1336]
bw (KB /s): min= 0, max=511944, per=12.49%, avg=503317.68, stdev=14677.46
lat (usec) : 50=0.01%, 100=0.01%, 250=6.73%, 500=45.53%, 750=37.48%
lat (usec) : 1000=9.52%
lat (msec) : 2=0.74%, 4=0.01%
cpu : usr=11.86%, sys=62.31%, ctx=194475883, majf=0, minf=17716
IO depths : 1=0.1%, 2=0.1%, 4=0.1%, 8=0.1%, 16=0.1%, 32=0.1%, >=64=109.9%
submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.1%, >=64=0.0%
issued : total=r=604477416/w=0/d=0, short=r=0/w=0/d=0, drop=r=0/w=0/d=0
latency : target=0, window=0, percentile=100.00%, depth=64
Run status group 0 (all jobs):
READ: io=2305.1GB, aggrb=3935.5MB/s, minb=3935.5MB/s, maxb=3935.5MB/s, mint=600001msec, maxt=600001msec
Disk stats (read/write):
nvme1n1: ios=664494451/0, merge=0/0, ticks=330657118/0, in_queue=18446744069786846278, util=100.00%
我们同样获取了libaio模式下的多组数据,如下表: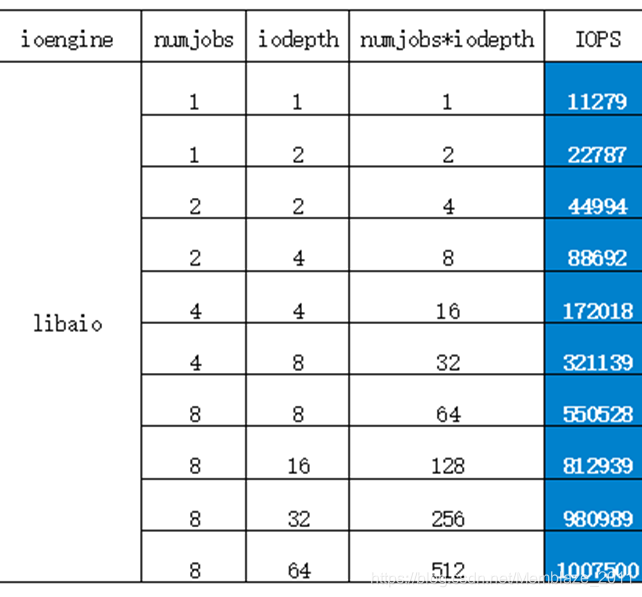
如下图可以看到,numjobs和iodepth组合下压力越大,性能也越高。最终在512(numjobs*iodepth)时达到了PBlaze5的性能峰值。
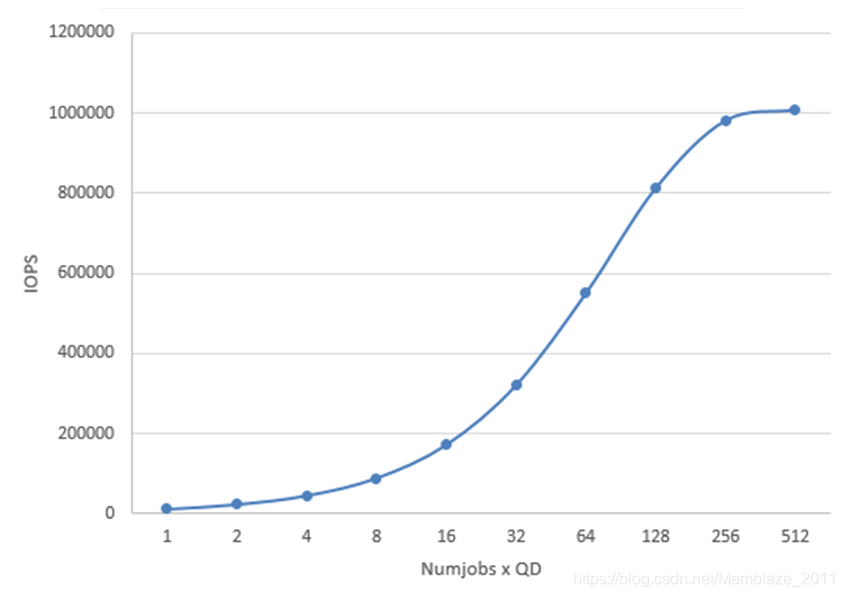
不同的介质、不同的接口和协议规范对于测试以及采购、配置、优化和升级的各项工作有着重要意义,也是以最小的成本获取最高性能的前提。Memblaze一直致力于帮助用户构建高性能、高能源效率的存储系统,针对数据库等典型应用场景还有着更为定制化的方案。
参考
fio howto
</article>
[转帖]从理论到实践,异步I/O模式下NVMe SSD高性能之道的更多相关文章
- 【C#代码实战】群蚁算法理论与实践全攻略——旅行商等路径优化问题的新方法
若干年前读研的时候,学院有一个教授,专门做群蚁算法的,很厉害,偶尔了解了一点点.感觉也是生物智能的一个体现,和遗传算法.神经网络有异曲同工之妙.只不过当时没有实际需求学习,所以没去研究.最近有一个这样 ...
- Java 理论与实践: 处理 InterruptedException
捕捉到它,然后怎么处理它? 很多 Java™ 语言方法,例如 Thread.sleep() 和 Object.wait(),都可以抛出InterruptedException.您不能忽略这个异常,因为 ...
- Java 理论与实践: 非阻塞算法简介——看吧,没有锁定!(转载)
简介: Java™ 5.0 第一次让使用 Java 语言开发非阻塞算法成为可能,java.util.concurrent 包充分地利用了这个功能.非阻塞算法属于并发算法,它们可以安全地派生它们的线程, ...
- Java 理论与实践: 流行的原子——新原子类是 java.util.concurrent 的隐藏精华(转载)
简介: 在 JDK 5.0 之前,如果不使用本机代码,就不能用 Java 语言编写无等待.无锁定的算法.在 java.util.concurrent 中添加原子变量类之后,这种情况发生了变化.请跟随并 ...
- Java 理论和实践: 了解泛型
转载自 : http://www.ibm.com/developerworks/cn/java/j-jtp01255.html 表面上看起来,无论语法还是应用的环境(比如容器类),泛型类型(或者泛型) ...
- Java 理论与实践: 处理 InterruptedException(转)
很多 Java™ 语言方法,例如 Thread.sleep() 和 Object.wait(),都可以抛出InterruptedException.您不能忽略这个异常,因为它是一个检查异常(check ...
- DDD(领域驱动设计)理论结合实践
DDD(领域驱动设计)理论结合实践 写在前面 插一句:本人超爱落网-<平凡的世界>这一期,分享给大家. 阅读目录: 关于DDD 前期分析 框架搭建 代码实现 开源-发布 后记 第一次听 ...
- Java 理论与实践: 并发集合类
Java 理论与实践: 并发集合类 DougLea的 util.concurrent 包除了包含许多其他有用的并发构造块之外,还包含了一些主要集合类型 List 和 Map 的高性能的.线程安全的实现 ...
- 浅读《视觉SLAM十四讲:从理论到实践》--操作1--初识SLAM
下载<视觉SLAM十四讲:从理论到实践>源码:https://github.com/gaoxiang12/slambook 第二讲:初识SLAM 2.4.2 Hello SLAM(书本P2 ...
- Oozie分布式工作流——从理论和实践分析使用节点间的参数传递
Oozie支持Java Action,因此可以自定义很多的功能.本篇就从理论和实践两方面介绍下Java Action的妙用,另外还涉及到oozie中action之间的参数传递. 本文大致分为以下几个部 ...
随机推荐
- .NET Conf China 2023分享-.NET应用国际化-AIGC智能翻译+代码生成
今年.NET Conf China 2023技术大会,我给大家分享了 .NET应用国际化-AIGC智能翻译+代码生成的议题,今天整理成博客,分享给所有人. 随着疫情的消退,越来越多的企业开始向海外拓展 ...
- JavaScript回调函数的高手指南
摘要:本文将会解释回调函数的概念,同时帮你区分两种回调:同步和异步. 回调函数是每个前端程序员都应该知道的概念之一.回调可用于数组.计时器函数.promise.事件处理中. 本文将会解释回调函数的概念 ...
- 华为云发布CodeArts Req需求管理工具,让需求管理化繁为简
摘要:华为云正式发布CodeArts Req,这是一款自主研发的软件研发管理与团队协作工具,旨在助力企业大规模研发转型成功,释放组织生产力. 本文分享自华为云社区<华为云发布CodeArts R ...
- Open Serverless Benchmark Initiative: 华为云联合上海交大发布ServerlessBench 2.0
Key Takeaways 华为云联合上海交大,首次提出 Open Serverless Benchmark Initiative (OSBI) ,推动Serverless基准测评规范化.标准化: O ...
- YoloV5实战:手把手教物体检测
摘要:YOLOv5并不是一个单独的模型,而是一个模型家族,包括了YOLOv5s.YOLOv5m.YOLO... 本文分享自华为云社区<YoloV5实战:手把手教物体检测--YoloV5> ...
- coredump文件生成,以及GDB工具使用
一.core dump文件生成 Core文件其实就是内存的映像,当程序崩溃时,存储内存的相应信息,主用用于对程序进行调试.当程序崩溃时便会产生core文件,其实准确的应该说是core dump 文件, ...
- Navigation的用法
一.Navigation的诞生 单个Activity嵌套多个Fragment的UI架构模式,已经被大多数的Android工程师所接受和采用.但是,对Fragment的管理一直是一件比较麻烦的事情.我们 ...
- SELinux 入门 pt.2
哈喽大家好,我是咸鱼 在<SELinux 入门 pt.1>中,咸鱼向各位小伙伴介绍了 SELinux 所使用的 MAC 模型.以及几个重要的概念(主体.目标.策略.安全上下文) 我们还讲到 ...
- HDU-3032--Nim or not Nim?(博弈+SG打表)
题目分析: 这是一个经典的Multi-SG游戏的问题. 相较于普通的Nim游戏,该游戏仅仅是多了拆成两堆这样的一个状态.即多了一个SG(x+y)的过程. 而根据SG定理,SG(x+y)这个游戏的结果可 ...
- vue学习笔记 一、环境搭建
系列导航 vue学习笔记 一.环境搭建 vue学习笔记 二.环境搭建+项目创建 vue学习笔记 三.文件和目录结构 vue学习笔记 四.定义组件(组件基本结构) vue学习笔记 五.创建子组件实例 v ...