机器学习-决策树系列-决策树-ID3算法 -C4.5算法-26
1. 决策树
决策树是属于有监督机器学习的一种,起源非常早,符合直觉并且非常直观,
模型生成:通过大量数据生成一颗非常好的树,用这棵树来预测新来的数据
预测:来一条新数据,按照生成好的树的标准,落到某一个叶子节点上
决策树的数学表达,递归 自己调用自己
决策树的生成本质
就是数据不断分裂的递归过程,每一次分裂,尽可能让类别一样的数据在树的一边,当树的叶子节点的数据都是一类的时候,则停止分裂。
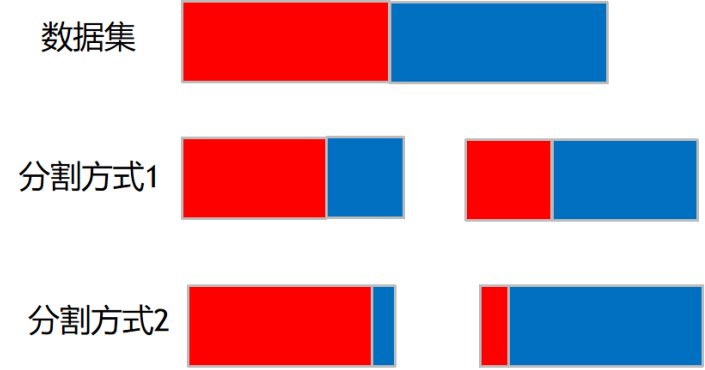
分裂好坏的评判的指标:基尼系数
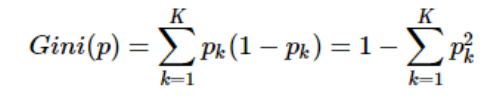
Gini系数越小,代表D集合中的数据越纯,所有我们可以计算分裂前的值
二分的场景:
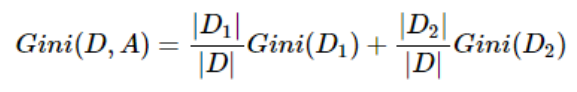
按照某个维度对数据集进行划分,然后可以去计算多个节点的Gini系数
分裂好坏的评判的指标:信息熵
在信息论里熵叫作信息量,即熵是对不确定性的度量。从控制论的角度来看,应叫不确定性。信息论的创始人香农在其著作《通信的数学理论》中提出了建立在概率统计模型上的信息度量。他把信息定义为“用来消除不确定性的东西”。在信息世界,熵越高,则能传输越多的信息,熵越低,则意味着传输的信息越少。
举例说明,假设Kathy在买衣服的时候有颜色,尺寸,款式以及设计年份四种要求,而North只有颜色和尺寸的要求,那么在购买衣服这个层面上Kathy由于选择更多因而不确定性因素更大,最终Kathy所获取的信息更多,也就是熵更大。所以信息量=熵=不确定性,通俗易懂。在叙述决策树时我们用熵表示不纯度(Impurity)。
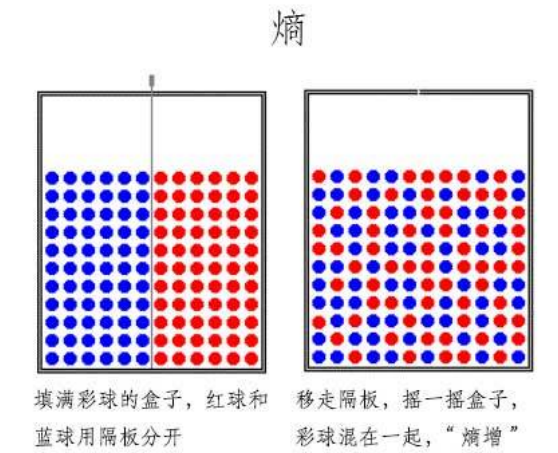
生命的本质在于 抵抗熵增
打扫房间:让你周围的世界变得有序
吃饭:让你体内的分子变得有序 那可不可以这样认为食物里面的熵更低 -->食物里面的更低的熵(更有序的分子排列)是谁实现的 从哪里来的?-->植物的光合作用 -->分子的有序排列是需要消耗能量的
有序 到 无序的过程 能量的耗散过程
无序 到 有序 需要吸收能量 才能实现
息论中熵的概念,熵度量了事物的不确定性,越不确定的事物,它的熵就越大。具体的,随机变量X的熵的表达式如下:

举个例子,比如X有2个可能的取值,而这两个取值各为1/2时X的熵最大,此时X具有最大的不确定性: ,
,
如果一个值概率大于1/2,另一个值概率小于1/2,则不确定性减少,对应的熵也会减少。比如一个概率1/3,一个概率2/3,则对应熵为: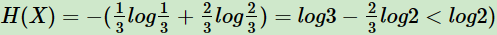
2. 举个例子 计算信息增益
信息增益:分裂前的信息熵 减去 分裂后的信息熵一个分裂导致的信息增益越大,代表这次分裂提升的纯度越高
分裂前的 减去分裂后的。

根节点 没有分裂的时候:

根据性别 分叉

性别这个维度分叉得到的信息增益:
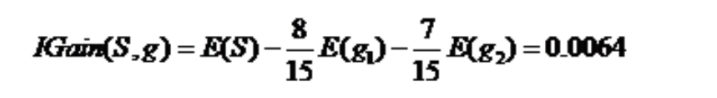
根据活跃度 分裂:
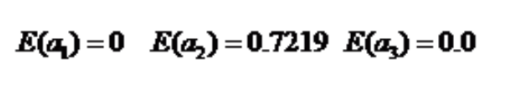
对应的信息增益:
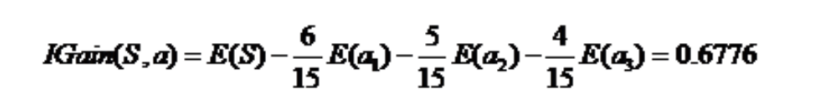
因此, 根据活跃度 来分叉 是更优的
信息熵与Gini指数关系
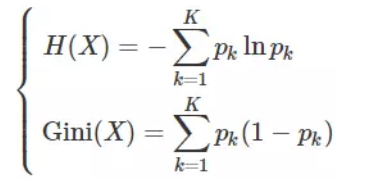
将 f(x) = −lnx 在 x = 1 处进行一阶泰勒展开
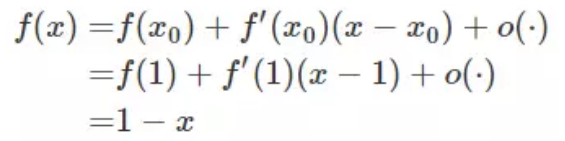

计算信息熵涉及log计算 效率会慢很多 因此很多时候是用gini系数去计算
以上方法叫做 决策树ID3 其缺点:
ID3采用信息增益大的特征优先建立决策树的节点。很快就被人发现,在相同条件下,取值比较多的特征比取值少的特征信息增益大。比如一个变量有2个值,各为1/2,另一个变量为3个值,各为1/3,其实他们都是完全不确定的变量,但是取3个值的比取2个值的信息增益大。如何校正这个问题呢?没有考虑过拟合的问题
ID3 算法的作者昆兰基于上述不足,对ID3算法做了改进,这就是C4.5算法
3. C4.5算法
ID3不足:一是不能处理连续特征,第二个就是用信息增益作为标准容易偏向于取值较多的特征,最后两个是缺失值处理的问和过拟合问题
息增益作为标准容易偏向于取值较多的特征的问题。我们引入一个信息增益比的变量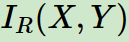
信息增益和特征熵的比值:
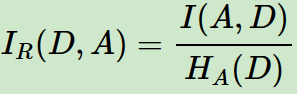
特征熵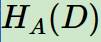 :
:

特征数越多的特征对应的特征熵越大,它作为分母,得到的信息增益比就会更小,校正信息增益容易偏向于取值较多的特征的问题。
C4.5虽然改进或者改善了ID3算法的几个主要的问题,仍然有优化的空间。
由于决策树算法非常容易过拟合,对于生成的决策树必须要进行剪枝。剪枝的算法有非常多,C4.5的剪枝方法有优化的空间。一种是预剪枝,另一个是后剪枝,即先生成决策树,再通过交叉验证来剪枝
C4.5由于使用了熵模型,里面有大量的耗时的对数运算,如果是连续值还有大量的排序运算。
在CART树里面加以了改进,在普通的决策树算法里,CART算法算是比较优的算法了。
机器学习-决策树系列-决策树-ID3算法 -C4.5算法-26的更多相关文章
- 机器学习总结(八)决策树ID3,C4.5算法,CART算法
本文主要总结决策树中的ID3,C4.5和CART算法,各种算法的特点,并对比了各种算法的不同点. 决策树:是一种基本的分类和回归方法.在分类问题中,是基于特征对实例进行分类.既可以认为是if-then ...
- 《机器学习实战》学习笔记第三章 —— 决策树之ID3、C4.5算法
主要内容: 一.决策树模型 二.信息与熵 三.信息增益与ID3算法 四.信息增益比与C4.5算法 五.决策树的剪枝 一.决策树模型 1.所谓决策树,就是根据实例的特征对实例进行划分的树形结构.其中有两 ...
- 小啃机器学习(1)-----ID3和C4.5决策树
第一部分:简介 ID3和C4.5算法都是被Quinlan提出的,用于分类模型,也被叫做决策树.我们给一组数据,每一行数据都含有相同的结构,包含了一系列的attribute/value对. 其中一个属性 ...
- 机器学习之决策树(ID3 、C4.5算法)
声明:本篇博文是学习<机器学习实战>一书的方式路程,系原创,若转载请标明来源. 1 决策树的基础概念 决策树分为分类树和回归树两种,分类树对离散变量做决策树 ,回归树对连续变量做决策树.决 ...
- 决策树:ID3与C4.5算法
1.基本概念 1)定义: 决策树是一个预测模型:他代表的是对象属性与对象值之间的一种映射关系,树中每个节点代表的某个可能的属性值. 2)表示方法: 通过把实例从根结点排列到某个叶子结点来分类实例,叶子 ...
- 决策树系列(四)——C4.5
预备知识:决策树.ID3 如上一篇文章所述,ID3方法主要有几个缺点:一是采用信息增益进行数据分裂,准确性不如信息增益率:二是不能对连续数据进行处理,只能通过连续数据离散化进行处理:三是没有采用剪枝的 ...
- 机器学习Sklearn系列:(五)聚类算法
K-means 原理 首先随机选择k个初始点作为质心 1. 对每一个样本点,计算得到距离其最近的质心,将其类别标记为该质心对应的类别 2. 使用归类好的样本点,重新计算K个类别的质心 3. 重复上述过 ...
- 数据挖掘领域经典分类算法 —— C4.5算法(附python实现代码)
目录 理论介绍 什么是分类 分类的步骤 什么是决策树 决策树归纳 信息增益 相关理论基础 计算公式 ID3 C4.5 python实现 参考资料 理论介绍 什么是分类 分类属于机器学习中监督学习的一种 ...
- 决策树之ID3、C4.5
决策树是一种类似于流程图的树结构,其中,每个内部节点(非树叶节点)表示一个属性上的测试,每个分枝代表该测试的一个输出,而每个树叶节点(或终端节点存放一个类标号).树的最顶层节点是根节点.下图是一个典型 ...
- 决策树(ID3、C4.5、CART)
ID3决策树 ID3决策树分类的根据是样本集分类前后的信息增益. 假设我们有一个样本集,里面每个样本都有自己的分类结果. 而信息熵可以理解为:“样本集中分类结果的平均不确定性”,俗称信息的纯度. 即熵 ...
随机推荐
- JVM整理笔记
1.JVM位置 JVM是作用在操作系统之上的,它与硬件没有直接的交互 2.JVM体系结构 3.类装载器ClassLoader 类装载器:负责加载class文件,class文件在文件开头有特定的文件标示 ...
- KNN算法之KD树(K-dimension Tree)实现 K近邻查询
KD树是一种分割k维数据空间的数据结构,主要应用于多维空间关键数据的搜索,如范围搜索和最近邻搜索. KD树使用了分治的思想,对比二叉搜索树(BST),KD树解决的是多维空间内的最近点(K近点)问题.( ...
- MySQL运维13-Mycat分库分表之按月分片
一.按照月分片 使用场景为按照自然月来分片,每个自然月为一个分片,但是一年有12个月,是不是要有12个数据节点才行呢?并不是.例如我现在只有三个分片数据库,这样就可以1月在第一个数据分片中,2月在第二 ...
- flask的cookie和session会话保持
Cookie 获取请求cookie 通过请求对象中的cookies属性可以获取cookie. 实例: from flask import Flask, request @app.route(" ...
- python 实现一个简单的计算器
python 实现一个简单的计算器 本文主要整合下tkinter ,实现下简单的计算器. 代码如下: #!/usr/bin/python3 # -*- coding: UTF-8 -*- " ...
- vulntarget-c-wp
vulntarget-c 信息收集 扫开的端口有web服务 访问了web页面,发现用的是laravel框架 搜索一下历史漏洞,在gayhub上找到这个可以用,能够执行简单命令 python3 expl ...
- MySQL|主从延迟问题排查(二)
二.案例分享二 2.1 问题描述 主库执行insert select 批量写入操作,主从复制通过row模式下转换为批量的insert大事务操作,导致只读实例CPU资源以及延迟上涨 16:55-17: ...
- AI与低代码解锁无限可能
前言 近年来,人工智能(AI)和低代码开发技术逐渐成为数字化转型的重要推动力.AI作为一项具有革命性潜力的技术,正在改变我们生活的方方面面.而低代码开发则提供了一种快速构建应用程序的方法,使得开发者无 ...
- MySQL篇:第二章_初识MySQL
初始MySQL MySQL的背景 1.前身属于瑞典的一家公司,MySQL AB 2.08年被sun公司收购 3.09年sun被oracle收购 MySQL的优点 1.开源.免费.成本低 2.性能高.移 ...
- 云图说 | GPU共享型AI容器,让AI开发更普及
摘要:容器以其独特的技术优势,已经成为业界主流的AI计算框架(如Tensorflow.Caffe)的核心引擎,为了进一步解决企业在AI计算性能与成本上面临的问题,华为云量身打造了AI容器产品. 容器以 ...