POA:已开源,蚂蚁集团提出同时预训练多种尺寸网络的自监督范式 | ECCV 2024
论文提出一种新颖的
POA自监督学习范式,通过弹性分支设计允许同时对多种尺寸的模型进行预训练。POA可以直接从预训练teacher生成不同尺寸的模型,并且这些模型可以直接用于下游任务而无需额外的预训练。这个优势显著提高了部署灵活性,并有助于预训练的模型在各种视觉任务中取得SOTA结果。来源:晓飞的算法工程笔记 公众号
论文: POA: Pre-training Once for Models of All Sizes

Abstract
大规模自监督预训练为一个基础模型处理多种不同的视觉任务铺平了道路。大多数预训练方法在一次训练中训练一个特定大小的单一模型。然而,在现实世界的场景中,由于各种计算或存储限制,需要大量的工作来开发一系列不同大小的模型进行部署。因此,在这项研究中,我们提出了一种新颖的三分支自监督训练框架,称为POA(Pre-training Once for All),来解决上述问题。我们的方法在现代自蒸馏范式中引入了一种创新的弹性student分支。在每个预训练步骤中,我们随机从原始student中抽样一个子网络来形成弹性student,并以自蒸馏的方式训练所有分支。一旦预训练完成,POA允许提取不同大小的预训练模型用于下游任务。值得注意的是,弹性student促进了多个不同大小模型的同时预训练,同时也作为各种大小模型的额外集合,增强了表示学习。大量实验证明了我们的POA的有效性和优势,包括k最近邻、线性探测评估以及多个下游任务的评估。它使用ViT、Swin Transformer和ResNet骨干网络实现了最先进的性能,并通过一次预训练会话生成了大约一百个不同大小的模型。代码可在以下链接找到:https/github.com/Qichuzyy/POA。
Introduction
通过自监督学习在大型模型中学习可泛化的视觉表示,近年来在各种视觉任务上取得了卓越的性能。然而,当部署到现实世界的应用程序时,大型模型必须根据计算、存储、功耗等各种资源限制进行调整。例如,一个良好设计的人工智能产品通常包括一套为不同场景量身定制的模型,比如Gemini Nano、Pro和Ultra。对于一个大型预训练模型,将其部署到具有不同资源约束的多个应用场景的常见解决方案包括额外的权重修剪、知识蒸馏,甚至从头开始重新训练一个小网络,这些都需要大量的开发工作。因此,这个问题引发了一个关键问题:是否可能进行一次预训练以同时生成多个具有不同大小的模型,每个模型都提供足够好的表示。
为了解决这一挑战,论文引入了一种名为POA(Pre-training Once for All)的新型自监督学习范式。POA建立在流行的teacher-student自蒸馏框架之上,具有一个额外的创新性弹性student分支。弹性student分支通过参数共享嵌入了一系列子网络,这是基于观察到对于现代网络结构来说,较小尺寸的模型是较大尺寸模型的子网络。此外,该分支的参数与原始的或完整的studennt共享。在每个预训练步骤中,从完整student中随机抽样一部分参数,形成相应的弹性studennt。原始完整student和弹性student都被训练以模拟teacher网络的输出。teacher本身通过对student参数的指数移动平均(EMA)不断优化,包括采样的弹性student。弹性student有助于在不同参数子集上进行有效和高效的预训练,从而成功地从预训练teacher中提取出高性能子网络,用于后续的下游场景。它还作为一种训练正则化形式,通过强制teacher和各种子网络之间的输出匹配来促进稳定的训练过程。
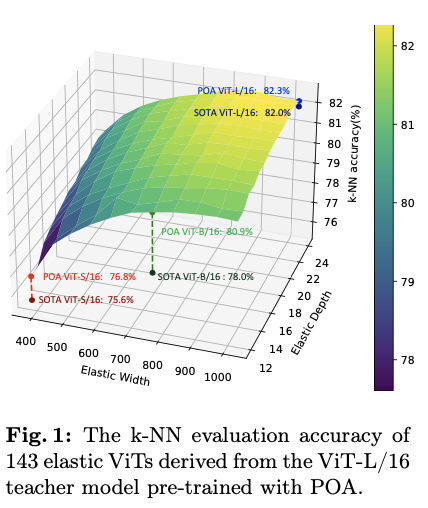
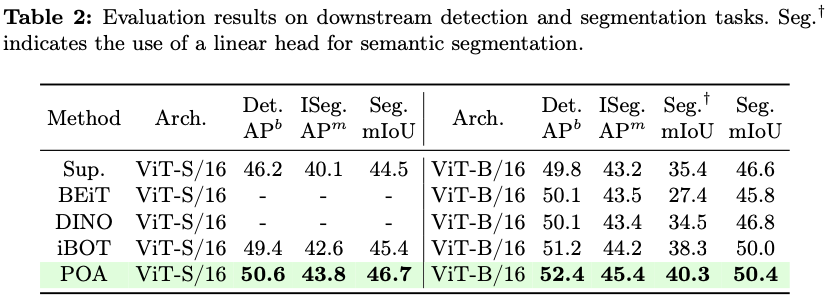
POA代表了第一个能够同时训练多个不同尺寸模型的自监督学习方法,每个模型在不需要进一步预训练的情况下,都能获得适用于不同资源约束的高质量表示。图1显示了通过POA预训练的ViT-L模型提取的143个子网络的k最近邻(k-NN)评估结果。通过选择不同的弹性宽度和深度,预训练teacher模型可以根据可用计算资源定制的适用于下游应用的合适模型,生成足够数量的候选子网络以供选择。值得注意的是,由于在同视图蒸馏上进行了精心设计,每个子网络都经过了良好训练,并表现出优越性能。特别是,ViT-S、ViT-B和ViT-L模型创造了新的基准,与那些由现有方法预训练的模型相比取得了SOTA结果。
为了严格评估方法的有效性,使用三种广泛使用的骨干架构,即ViT、Swin Transformer和ResNet,进行了大量实验。每个骨干架构都在ImageNet-1K数据集上进行了预训练,并使用k-NN和线性探测分类评估,以及在下游密集预测任务进行评估,如目标检测和语义分割。POA在单次预训练会话中跨多种模型尺寸实现了最先进的准确性。
本文的技术贡献总结如下:
POA是第一个将无监督表示学习和一次性模型生成集成到单个预训练会话中的预训练范式,解决了社区很少探讨的一次性预训练挑战。这对实际部署非常重要,因为实际部署通常需要一套模型。- 提出了一个新颖而优雅的组件,称为弹性
student(Elastic Student),具有一系列弹性算子,可以使POA与包括ViT、Swin Transformer和ResNet在内的流行骨干结构兼容,具备生成各种大小模型的能力。此外,还作为模型集成来平滑训练过程并改善学到的表示。 - 通过对
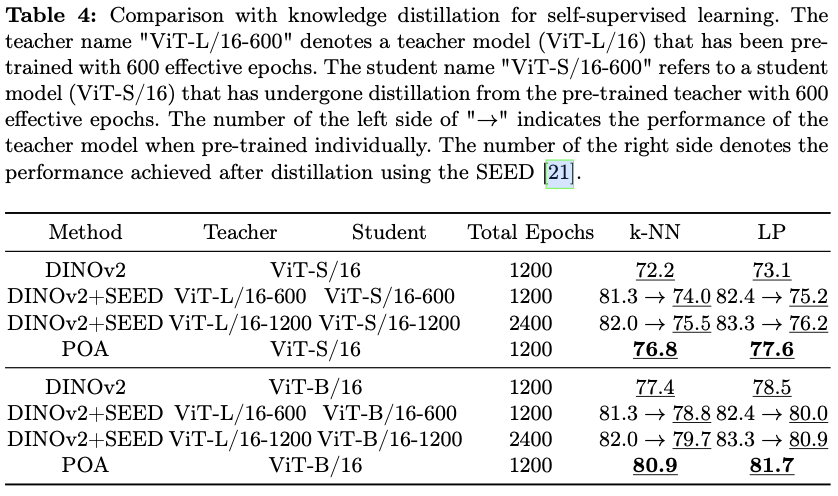
k-NN、线性探测和下游密集任务评估的彻底评估,在多个指标上展现出优于现有最先进预训练方法的性能。此外,将POA与自监督蒸馏(SEED)进行了比较,SEED是一种专为自监督学习设计的知识蒸馏方法,进一步验证了POA的有效性。
POA Self-supervised Learning Framework
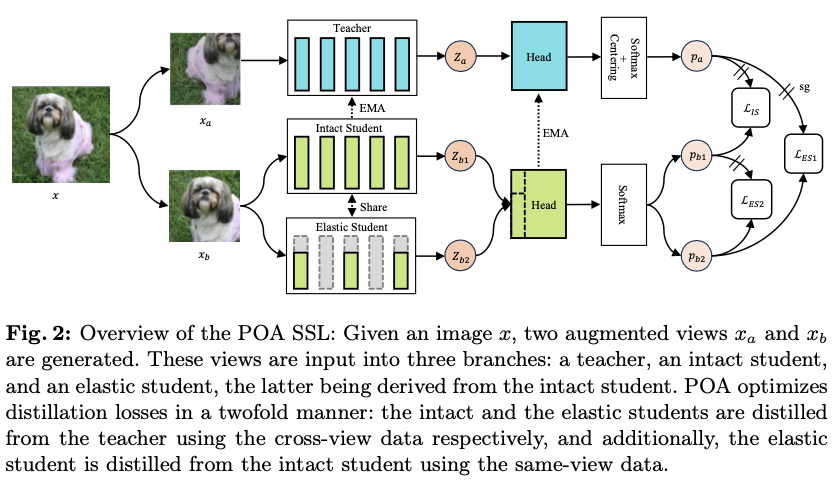
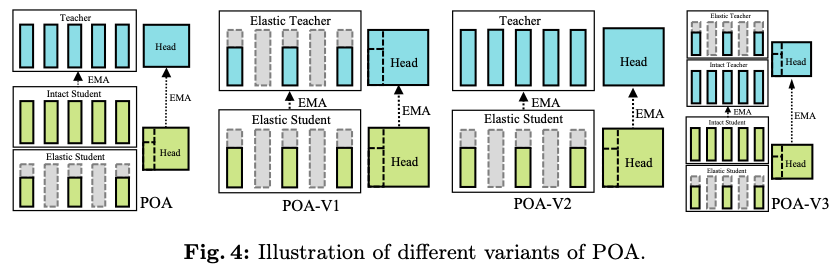
论文的主要目标是通过单次自监督预训练会话来预训练多种规模的模型,受到自蒸馏技术最新进展的启发,提出了一个名为POA的新型SSL(Self-supervised Learning)框架。POA架构如图2所示,包括一个teacher模型、一个完整的student模型、一个弹性student模型以及对应的头部。teacher模型使用student模型的指数移动平均(EMA)进行更新。弹性student模型是完整student模型的派生版本,其主干网络和头部参数是共享的。
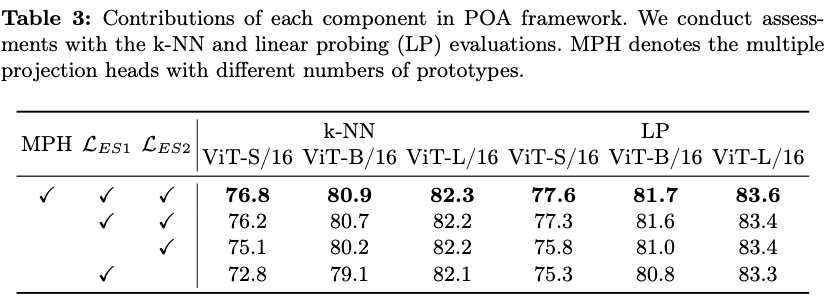
在两个方面利用蒸馏技术:完整student和弹性student都是通过使用同一图像不同视图的teacher模型进行蒸馏,而弹性student还通过使用相同视图的完整student进行学习。交叉视图蒸馏作为一种表示学习形式,如所介绍的那样。值得注意的是,除了仅使用完整student进行常规EMA更新外,弹性student在每个预训练步骤中还提供一个随机抽样的子网络,参与teacher模型的EMA优化。这个过程实际上模拟了多个子网络的集成,这在监督学习领域也被证明是有益的。同视图蒸馏是完整student和弹性student之间的标准知识蒸馏,提升了弹性student的质量。
Design of Elastic Student
弹性student是一个子网络,其参数是从完整student中提取的。在transformer主干网络的背景下,宽度指的是标记的维度,而在卷积主干网络中,宽度表示通道数。深度则定义为transformer或卷积网络中基本块的数量。给定宽度和深度的值,会产生一定的网络结构。为简单起见,论文将重点放介绍ViT的弹性设计。
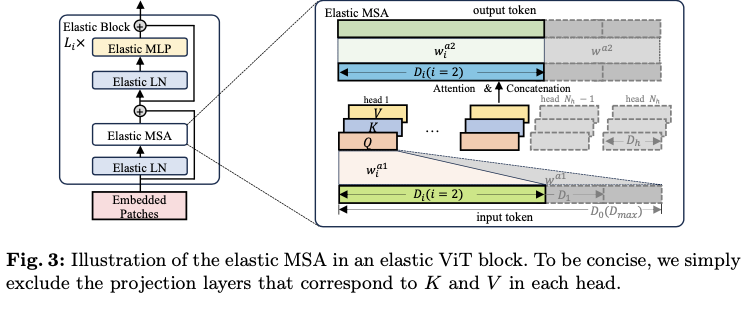
ViT的基本块主要由多头自注意力(MSA)模块和多层感知器(MLP)模块组成。在每个模块之前应用层归一化(LN),并在每个模块后使用残差连接。如图3的左侧所示,弹性块是指在ViT原始基本块中调整宽度后堆叠的弹性MSA、MLP和LN。在论文的方法中,弹性student分支是通过在每个训练迭代中组装特定数量的这些弹性块来构建的。
Elastic MSA
一个原始或完整的MSA模块由三个主要组件组成,即输入投影层,包含注意力和连接的操作符,以及输出投影层。将投影层定义为( \(w^{\ast}, b^{\ast}\) ),其中 \(w^{\ast}\) 表示线性转换权重, \(b^{\ast}\) 表示相应的偏置, \(\ast\) 表示层的名称。如图3的右侧所示,给定一个标记维度 \(D_{max}=N_h \cdot D_h\) ,其中 \(N_h\) 是注意力头的数量, \(D_h\) 是头部维度,具有长度 \(T\) 的输入序列 \(z \in \mathbb{R}^{T \times D_{max}}\) 最初被投影以形成查询 \(Q \in \mathbb{R}^{T \times D_h}\) 、键 \(K \in \mathbb{R}^{T \times D_h}\) 和值 \(V \in \mathbb{R}^{T \times D_h}\) 。为了生成弹性MSA,定义了M+1个弹性宽度,包括 \(D_{max}\) ,间隔为 \(D_h\):
D_i = (N_h - i) \cdot D_h,\quad\forall i \in \{0, 1, ..., M\},\quad
M < N_h.
\label{eq:elastic_width}
\end{equation}
\]
对于每个弹性宽度 \(D_i\) ,从完整MSA中的相应输入投影层( \(w^{a1}\) , \(b^{a1}\) )中提取生成每个头部的 \(Q\) 、 \(K\) 和 \(V\) 的权重 \(w^{a1}_i \in \mathbb{R}^{D_h \times D_i}\) 和偏置 \(b^{a1}_i \in \mathbb{R}^{D_h}\) ,如 \(w^{a1}_i = w^{a1}[:, :D_i]\cdot\alpha_i\) 和 \(b^{a1}_i = b^{a1}\) 。这里, \(\alpha_i\) 表示用于应对输入维度减少的缩放因子,计算公式为 \(\alpha_i = D_{max}/D_i\) 。随着宽度的减小,弹性MSA中的注意力头数量自然减少到 \(N_h - i\) 。类似地,对于输出投影层( \(w^{a2}\) , \(b^{a2}\) ),权重 \(w^{a2}_i \in \mathbb{R}^{D_i \times D_i}\) 和偏置 \(b^{a2}_i \in \mathbb{R}^{D_i}\) 被提取为:
w^{a2}_i = w^{a2}[:D_i, :D_i]\cdot\alpha_i ~~~~~ b^{a2}_i = b^{a2}[:D_i].
\label{eq:w_b_extract}
\end{equation}
\]
Elastic MLP
ViT块中的原始或完整MLP模块包含两个投影层。第一层( \(w^{m1}, b^{m1}\) )将嵌入维度扩展了 \(s\) 倍,通常在ViT结构中设置为4。然后,第二层( \(w^{m2}, b^{m2}\) )将其投影回原始维度。弹性MLP的两个层的参数以类似于公式2描述的方式提取,如下所示:
\begin{aligned}
& w^{m1}_i = w^{m1}[:D_i \cdot s, :D_i]\cdot\alpha_i ~~~~~ b^{m1}_i = b^{m1}[:D_i \cdot s] \\
& w^{m2}_i = w^{m2}[:D_i, :D_i \cdot s]\cdot\alpha_i ~~~~~ b^{m2}_i = b^{m2}[:D_i].
\end{aligned}
\label{eq:mlp_extract}
\end{equation}
\]
Elastic LN
对于弹性LN,直接使用原始LN内部参数的前 \(D_i\) 个元素,类似于公式2中的偏置提取。
Elastic depth
要从包含 \(L_{max}\) 个块的完整ViT中创建一个包含 \(L_i\) 个弹性块的子网络,引入了一组N+1个弹性深度,定义为 \(L_i = L_{max} - i,~~\forall i \in \{0, 1, ..., N\},~~N < L_{max}\) 。对于特定深度 \(L_i\) ,根据块ID在等间隔上选择相应的块。激活深度 \(L_i\) 的每个块ID \(BID^{L_i}_j\) 可以表示为:
BID^{L_i}_j = \left\lfloor \frac{(L_{max} - 1) \cdot j}{L_i - 1} \right\rfloor,\quad \forall j \in \{0, 1, ..., L_i - 1\}.
\label{eq:block_id_extraction}
\end{equation}
\]
因此,通过结合弹性宽度和深度,可以生成总共 \((N+1)\cdot(M+1)\) 个不同的子网络。例如,通过将弹性宽度设置为384,弹性深度设置为12,可以直接从如ViT-L的完整网络中提取一个ViT-S。在预训练的每次迭代中,随机选择其中一个子网络作为弹性student分支。
Distillation between Views
POA根据其三个分支执行蒸馏。给定输入图像 \(x\) 的一对全局增强视图,表示为 \(x_a\) 和 \(x_b\) ,teacher编码器 \(E_{T}\) 使用 \(x_a\) 作为输入提取特征 \(Z_a = E_{T}(x_a)\) 。同时, \(x_b\) 被输入到完整student编码器 \(E_{IS}\) 和弹性student编码器 \(E_{ES}\) 中,分别产生特征 \(Z_{b1} = E_{IS}(x_b)\) 和 \(Z_{b2} = E_{ES}(x_b)\) 。从teacher编码器输出的特征 \(Z_a\) 经过teacher头部 \(H_T\) 处理,然后使用Sinkhorn-Knopp(SK)算法进行居中处理,并使用温度缩放softmax进行归一化,生成概率 \(p_a\) ,如下所示:
\begin{aligned}
l_a = SK(H_T(Z_a)),~l_a \in \mathbb{R}^P ~~\quad p^i_a = \frac{\exp(l^i_a / \tau)}{\sum^{P-1}_{k=0}\exp(l^k_a / \tau)},~\forall i \in \{0, ..., P-1\},
\end{aligned}
\label{eq:prob_teacher}
\end{equation}
\]
其中 \(P\) 是原型(logits?)的数量, \(\tau > 0\) 是温度参数。类似地,通过使用student头部 \(H_{IS}\) 和 \(H_{ES}\) 处理输出来计算完整和弹性student编码器的概率 \(p^i_{b1}\) 和 \(p^i_{b2}\) 。然后,这些输出通过一个针对student量身定制的温度参数 \(\tau'\) 的温度缩放softmax函数进行处理。值得注意的是, \(H_{IS}\) 和 \(H_{ES}\) 共享相同的参数,只是 \(H_{ES}\) 的第一个投影层进行公式2的相应调整,以便对齐相应的维度。为简单起见,省略了 \(p^i_{b1}\) 和 \(p^i_{b2}\) 的显式表达式,因为它们遵循与公式5类似的计算方式。对于完整student分支,使用跨视图数据从teacher进行蒸馏如下:
\mathcal{L}^g_{IS} = -p_a \log(p_{b1}).
\label{eq:distill_is}
\end{equation}
\]
弹性student分支在POA框架中发挥着至关重要的作用。为了确保这一分支的充分训练,采用了从teacher和完整student分支进行的双重蒸馏。第一次蒸馏涉及到teacher模型,利用跨视图数据来引导表示学习。第二次是与完整student模型进行的蒸馏过程,使用同视图数据。这种同视图蒸馏负责将完整student学到的表示转移到弹性student分支。这种双重蒸馏过程的损失函数制定如下
\begin{aligned}
\mathcal{L}^g_{ES1} = - p_a \log(p_{b2}), \quad \mathcal{L}^g_{ES2} = - p_{b1} \log(p_{b2}).
\label{eq:distill_es}
\end{aligned}
\end{equation}
\]
请注意,在这两个损失函数中,对所有原型求和,以计算相应概率分布之间的交叉熵损失。
Overall Loss of POA
根据SSL方法,采用多裁剪策略从单个图像中创建各种失真视图。除了之前提到的两个全局视图外,还生成 \(v\) 个分辨率较低的局部视图 \(x_{l_1}, x_{l_2}, ..., x_{l_v}\) 。这些局部视图由两个student共同处理,以促进局部到全局的对应关系。完整和弹性student的局部蒸馏损失计算如下:
\mathcal{L}^{l}_{IS} = - \frac{1}{v}\sum^{v}_{i=1} p_a \log(p_{l_i1}),
\label{eq:local_distill_is_loss}
\end{equation}
\]
\mathcal{L}^{l}_{ES1} = - \frac{1}{v}\sum^{v}_{i=1}p_a \log(p_{l_i2}), \quad \mathcal{L}^{l}_{ES2} = - \frac{1}{v}\sum^{v}_{i=1}p_{l_i1} \log(p_{l_i2}),
\label{eq:local_distill_es_loss}
\end{equation}
\]
其中, \(p_{l_{i1}}\) 和 \(p_{l_{i2}}\) 分别是完整和弹性student分支对于局部视图 \(l_i\) 产生的概率。完整和弹性student的总蒸馏损失通过将它们与因子 \(\lambda\) 相加来计算:
\begin{aligned}
\mathcal{L_S} &= \lambda(\mathcal{L}^g_{IS} + \mathcal{L}^{l}_{IS}) + (1-\lambda)((\mathcal{L}^g_{ES1} + \mathcal{L}^{l}_{ES1}) + (\mathcal{L}^g_{ES2} + \mathcal{L}^{l}_{ES2})) \\
&= \lambda\mathcal{L}_{IS} + (1-\lambda)(\mathcal{L}_{ES1} + \mathcal{L}_{ES2}).
\end{aligned}
\label{eq:total_distill_loss}
\end{equation}
\]
为了确保弹性student的每个子网络都得到充分的训练,在主干网络之后引入了多个投影头(MPH)。每个投影头具有完全相同的结构,只是原型数量不同。对于每个投影头,根据公式10计算完整和弹性student的蒸馏损失 \(\mathcal{L_S}_i\) 。最终,在具有 \(H\) 个投影头的POA框架中,整体损失函数被表述为: \(\mathcal{L} = \frac{1}{H} \sum^H_{i=1}\mathcal{L_S}_i\) 。
Experiments
如果本文对你有帮助,麻烦点个赞或在看呗~
更多内容请关注 微信公众号【晓飞的算法工程笔记】

POA:已开源,蚂蚁集团提出同时预训练多种尺寸网络的自监督范式 | ECCV 2024的更多相关文章
- 学习TensorFlow,调用预训练好的网络(Alex, VGG, ResNet etc)
视觉问题引入深度神经网络后,针对端对端的训练和预测网络,可以看是特征的表达和任务的决策问题(分类,回归等).当我们自己的训练数据量过小时,往往借助牛人已经预训练好的网络进行特征的提取,然后在后面加上自 ...
- 最强 NLP 预训练模型库 PyTorch-Transformers 正式开源:支持 6 个预训练框架,27 个预训练模型
先上开源地址: https://github.com/huggingface/pytorch-transformers#quick-tour 官网: https://huggingface.co/py ...
- zz从Word Embedding到Bert模型—自然语言处理中的预训练技术发展史
从Word Embedding到Bert模型—自然语言处理中的预训练技术发展史 Bert最近很火,应该是最近最火爆的AI进展,网上的评价很高,那么Bert值得这么高的评价吗?我个人判断是值得.那为什么 ...
- 从Word Embedding到Bert模型—自然语言处理中的预训练技术发展史(转载)
转载 https://zhuanlan.zhihu.com/p/49271699 首发于深度学习前沿笔记 写文章 从Word Embedding到Bert模型—自然语言处理中的预训练技术发展史 张 ...
- NLP之预训练
内容是结合:https://zhuanlan.zhihu.com/p/49271699 可以直接看原文 预训练一般要从图像处理领域说起:可以先用某个训练集合比如训练集合A或者训练集合B对这个网络进行预 ...
- 自写的开发框架,胜于官方的clientAPP的实战开发。(已开源)
已开源,欢迎大家fork 小弟github地址为https://github.com/10045125/vanda 好久没写博客了,这段时间主要是要做的事情太多.如今接触android有段时间了.非常 ...
- c#与JAVA利用SOCKET实现异步通信的SanNiuSignal.DLL已开源
大家好,前段时间C#的SanNiuSignal.DLL已开源;因部分用户特需要JAVA版的SanNiuSignal;现在只能把半成品先拿出来暂时给他们用了,以后再慢慢改进; JAVA版目前已实现跟C# ...
- 基于Web的CAD一张图协同在线制图更新轻量级解决方案[示例已开源]
背景 之前相关的博文中介绍了如果在Web网页端展示CAD图形(唯杰地图云端图纸管理平台 https://vjmap.com/app/cloud),有不少朋友问,能不能实现一个协同的功能,实现不同部门不 ...
- 【中文版 | 论文原文】BERT:语言理解的深度双向变换器预训练
BERT:Pre-training of Deep Bidirectional Transformers for Language Understanding 谷歌AI语言组论文<BERT:语言 ...
- 学习AI之NLP后对预训练语言模型——心得体会总结
一.学习NLP背景介绍: 从2019年4月份开始跟着华为云ModelArts实战营同学们一起进行了6期关于图像深度学习的学习,初步了解了关于图像标注.图像分类.物体检测,图像都目标物体检测等 ...
随机推荐
- spark共享变量---广播变量和累加变量
从三个方面来分析:1.什么时候使用,2.原理是什么3.性能上有什么优化 累加变量:--(自定义累加器很重要) 使用场景:累加器的一个常见用途是在调试时对作业执行过程中的事件进行计数,如:统计日志中空行 ...
- VulnHub_DC-2渗透流程
VulnHub_DC-2 信息收集 探测目标主机IP地址 arp-scan -l nmap -sV -A -p- 192.168.157.143 得知开启80端口的http服务与7744端口开启的ss ...
- Java 集合元素排序接口Comparable
什么是Comparable public interface Comparable<T> { /** * Compares this object with the specified o ...
- apache ab.exe压力测试
ab.exe是一个性能检测工具,是apache server中的一个小组件,使用简单,方便 下载地址:http://files.cnblogs.com/files/gossip/ab.zip ...
- webpack4.15.1 学习笔记(七) — 懒加载(Lazy Loading)
懒加载或者按需加载,是一种很好的优化网页或应用的方式.实际上是先把代码在一些逻辑断点处分离开,然后在一些代码块中完成某些操作后,立即引用或引用另外一些新的代码块.这样加快了应用的初始加载速度,减轻了它 ...
- Error: Dynamic require of "path" is not supported
failed to load config from D:\BaiduSyncdisk\vue3\sys-manager\vite.config.jserror when starting dev s ...
- holiday week3
本周开始进行小学期实验报告B 上周LOL打的rank分又掉了回去 星际争霸打到了铂金段位 JAVA预备在小学期完成之后开始正式学习 现已了解雏形 本周发布了一个视频https://www.bilibi ...
- adb shell 批处理文件
adb shell 批处理文件 手机截屏,并把图片传到电脑
- Postman汉化成中文版
postman安装默认是英文版,为使用方便使用汉化包转成中文版 1.查看本地安装的postman版本:Settings->About 2.根据postman的版本下载对应的汉化包,汉化包网址 3 ...
- 大厂面经: 字节跳动 iOS开发实习生-飞书
好家伙, 线上面试,总时长1h30mins左右 整体流程: 0.自我介绍(0-2mins) 1.做的比较难的事情(15min) 我讲我之前写的一个低开平台,写了一个撤销回退功能,提了个pr,用了节流, ...