Spring Data Jpa系列教程--------实体解析和关联关系
Spring Data Jpa是基于HIbernate开发的,所以建立实体建的实体和映射关系需要好好好的去了解一下,本文有以下内容,实体管理器介绍,实体与数据库表的映射介绍,关联关系(一对多,多对多)介绍,SpringDataJpa应用分析
------实体管理器
实体管理器EntityManager是实体与数据库的桥梁(和事务一起发挥作用),相当于Hibenrtae中的session,Mybatis中的sqlSession。使用方法放个小例子吧
-
@PersistenceContext
-
private EntityManager em; // 注入实体管理器
-
@SuppressWarnings("unchecked")
-
public Page<Student> search(User user) {
-
String dataSql = "select t from User t where 1 = 1";
-
String countSql = "select count(t) from User t where 1 = 1";
-
-
if(null != user && !StringUtils.isEmpty(user.getName())) {
-
dataSql += " and t.name = ?1";
-
countSql += " and t.name = ?1";
-
}
-
-
Query dataQuery = em.createQuery(dataSql);
-
Query countQuery = em.createQuery(countSql);
-
-
if(null != user && !StringUtils.isEmpty(user.getName())) {
-
dataQuery.setParameter(1, user.getName());
-
countQuery.setParameter(1, user.getName());
-
}long totalSize = (long) countQuery.getSingleResult();
-
Page<User> page = new Page();
-
page.setTotalSize(totalSize);
-
List<User> data = dataQuery.getResultList();
-
page.setData(data);
-
return page;
-
}
由以上例子可以看出,这个EntityManager其实跟sqlSession差不多,但是为什么要叫做EntityManager(实体管理器),必然有他的道理的。
讲讲实体。实体总共有4个状态: (persist用于插入,merge用于修改或插入,remove用于删除)
新建状态(A):新建实体的时候,实体就是属于这个状态,执行persist方法后进入托管状态
托管状态(B):托管状态,实体属于这个状态就说明实体已经被entityManager管理了
删除状态(C):略
游离状态(D):游离状态和A的区别就是D的ID是有值的
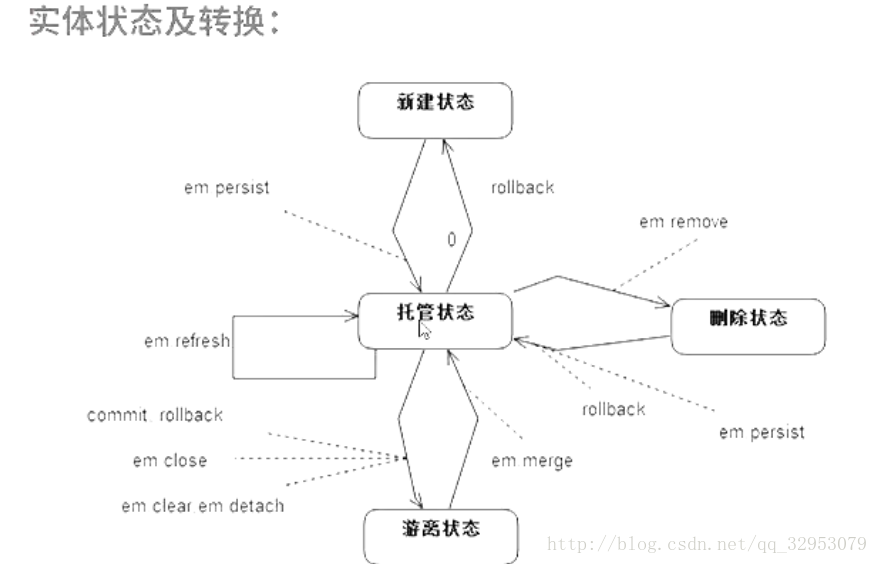
B状态是托管状态,处于B状态的对象,对他们的操作会随着事物自动提交到数据库,提交事务后,B的对象就变成了D状态,D与A的区别是D中的对象的ID是有值的。当entityManager实体管理器执行persist,rollback,refresh,merge方法是,当前对象会变成B状态。
------实体基础映射
@Entity表示这个类是一个实体类
@Table指定这个实体对应数据库的表名
-
@column(name="name",length=60,nullable=false, unique=false,insertable=false,
-
-
columnDefinition = 对应数据库字段类型)
-
-
private String name;
-
-
@column(name="big",precision = 12, scale = 2)
-
-
private BigDecimal big;
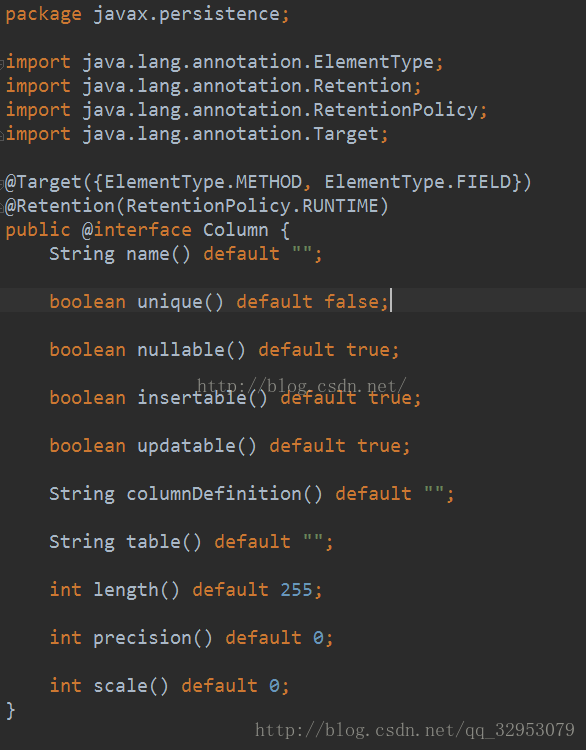
insertable,updateable表示是否允许插入或更新,
precision表示精度,当属性为double或者bigdecimal时,他表示数字的总长度,
scale表示小数的位数。
主键:
@ID
@GenerateValue 主键策略
----------AUTO 和默认的一样
----------IDENTITY 自动增长
----------SEQUENCE 序列,oracle使用
------实体高级映射
1,一对一
Persion | Address
address_id |
在persion实体中:
-
@oneToOne
-
-
@JoinColumn(name = "address_id", refreceColumnName = "aid")
-
-
private Address address;
name表示本表关联字段,refreceColumnName表示另一端关联字段名称
2,一对多和多对一
如下,是一对多和多对一的双向关联,MappedBy指的是关系由哪方来维护,维护的意思就是修改外键的能力,只有关系维护方才可以去修改外键,而被维护方就算级联保存,外键的值是空的。后面有例子说明。
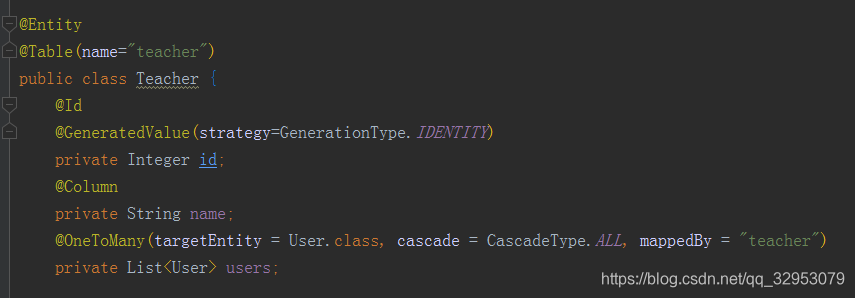
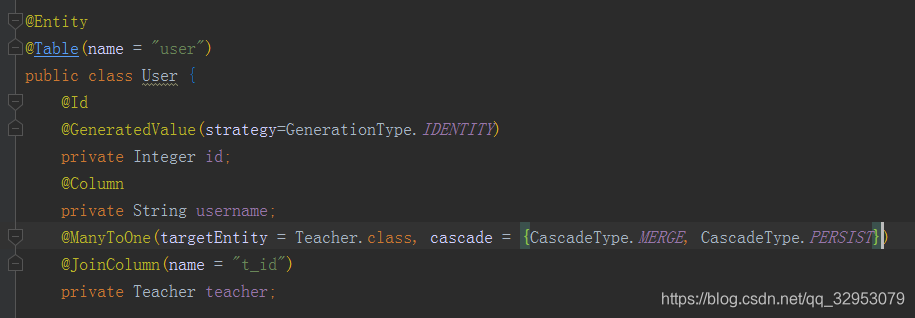
如上关系会在user表中增加一个t_id字段,@Joincolumn指的是在当前实体对应的表中增加对该属性的类型实体的外键关联,所以想在哪张表中增加字段就在那个实体里面写@Joincolumn吧,说的好通俗啊。。。。。
3,多对多
Student | 中间表student_teacher | Teacher
在Teacher实体中:
-
@ManyToMany
-
-
@JoinTable(name = "teacher_student",JoinColumns = @JoinColumn(name = "teacher_id",refreceColumnName = "tid"),inverseJoinColumns = @JoinColumn(name = "student_id",refreceColumnName="sid"))
-
-
private List<Student> students;
@JoinTable表示关联到中间表
name是中间表名字
JoinColumns表示配置关系拥有者与中间表的关联
inverseJoinColumns表示配置关系被拥有者与中间表的关联
(拥有者和被拥有者的意思是比如一对多关系中,生成一张中间表,部门Depart和员工Employee,在部门实体中配置@OneToMany,则关系拥有者是Depart,关系被拥有者是Employee)
级联:
例如
@OneToOne(cascade = {CascadeType.ALL},fetch = FetchType.LAZY)
cascade是级联操作,比如增删改,fetch是专门管理级联查询
CascadeType有如下类型:
-----REMOVE 删除当前对象,关联对象也会一起删除
-----ALL 所有操作都会关联删除
-----DETACH
-----MERGE
-----PERSIST
-----REFRESH
FetchType有两类型,默认是懒加载
-----LAZY 懒加载
-----EAGER 急加载
下面!!!!!!!!举个简单的小例子,关系如上面一对多,多对一双向关联的例子,现在做一个根据用户名,查询user及其关联的teacher的方法。如下
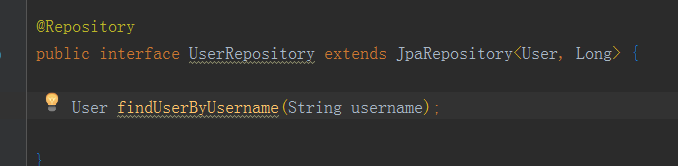
哎,真好。

上面也说了。因为jpa默认是懒加载,所以在双向关联时,又要转成json时,就会出现循环迭代,栈溢出(stackoverflow)的异常。所以方法有两个1,手动设置为Null,中断迭代;2,改成单项关联,咦~~~~~~
Spring Data Jpa 应用分析
1.实体管理器高级操作——getReference()
用于查询单记录实体,和find相似 代码如下 // 加载一个实体 T entity = entityManager.getReference(entityClass, id); 它与find的区别就是:当根据主键查询记录不存在的时候,将抛出异常EntityNotFoundException。这样我们就可以捕获异常后做一些自己的处理。
2.实体管理器高级操作——提交方式FlushModeType
提交(调用flush)分为2种方式: AUTO:自动提交,实体管理器会在适当的时机同步实际记录到数据库,也是默认的提交方式。 COMMIT:一旦一个事务完毕了,那么就立刻提交到数据库(忽略事务共享、事务传播)。 很多人建议使用默认的AUTO。
3.大量数据分批提交
有的时候我们需要循环保存数据,当保存大量数据的时候,如果到最后才提交所有数据,那么数据库的负载可能会比较大。我们可以这样做,每30个记录就提交(flush)一次。代码如下:
-
public void updateBatch(List<Z> list) {
-
for (int i = 0; i < list.size(); i++) {
-
entityManager.merge(list.get(i)); // 变成托管状态
-
if (i % 30 == 0) {
-
entityManager.flush(); // 变成持久化状态
-
entityManager.clear(); // 变成游离状态
-
}
-
}
-
}
-
-
public void saveBatch(List<Z> list) {
-
for (int i = 0; i < list.size(); i++) {
-
entityManager.persist(list.get(i)); // 变成托管状态
-
if (i % 30 == 0) {
-
entityManager.flush(); // 变成持久化状态
-
entityManager.clear(); // 变成游离状态
-
}
-
}
-
}
每到30条记录的时候就强制提交。
4.refresh()
该方法是和flush()相反,是将数据库记录重新读到实体中,这样实体也是出于持久化环境中了,处于托管状态。
5.clear()
该方法是将所有的处于上下文中的实体全部转换成游离状态,此时还没有及时flush到数据库的信息,很遗憾,将不会持久化到数据库中。不是急于释放资源的情况下,请慎用之。
Spring Data Jpa系列教程--------实体解析和关联关系的更多相关文章
- Spring Data JPA系列2:SpringBoot集成JPA详细教程,快速在项目中熟练使用JPA
大家好,又见面了. 这是Spring Data JPA系列的第2篇,在上一篇<Spring Data JPA系列1:JDBC.ORM.JPA.Spring Data JPA,傻傻分不清楚?给你个 ...
- Spring Data JPA系列5:让IDEA自动帮你写JPA实体定义代码
大家好,又见面了. 这是本系列的最后一篇文档啦,先来回顾下前面4篇: 在第1篇<Spring Data JPA系列1:JDBC.ORM.JPA.Spring Data JPA,傻傻分不清楚?给你 ...
- SpringBoot系列之Spring Data Jpa集成教程
SpringBoot系列之Spring Data Jpa集成教程 Spring Data Jpa是属于Spring Data的一个子项目,Spring data项目是一款集成了很多数据操作的项目,其下 ...
- Spring Data JPA系列3:JPA项目中核心场景与进阶用法介绍
大家好,又见面了. 到这里呢,已经是本SpringData JPA系列文档的第三篇了,先来回顾下前面两篇: 在第1篇<Spring Data JPA系列1:JDBC.ORM.JPA.Spring ...
- Spring Data JPA系列4——Spring声明式数事务处理与多数据源支持
大家好,又见面了. 到这里呢,已经是本SpringData JPA系列文档的第四篇了,先来回顾下前面三篇: 在第1篇<Spring Data JPA系列1:JDBC.ORM.JPA.Spring ...
- Spring Data JPA 多个实体类表联合视图查询
Spring Data JPA 查询数据库时,如果两个表有关联,那么就设个外键,在查询的时候用Specification创建Join 查询便可.但是只支持左连接,不支持右连接,虽说左右连接反过来就能实 ...
- 【ORM框架】Spring Data JPA(一)-- 入门
本文参考:spring Data JPA入门 [原创]纯干货,Spring-data-jpa详解,全方位介绍 Spring Data JPA系列教程--入门 一.Spring Data JPA介 ...
- Spring Boot 入门系列(二十七)使用Spring Data JPA 自定义查询如此简单,完全不需要写SQL!
前面讲了Spring Boot 整合Spring Boot JPA,实现JPA 的增.删.改.查的功能.JPA使用非常简单,只需继承JpaRepository ,无需任何数据访问层和sql语句即可实现 ...
- SpringBoot学习笔记:Spring Data Jpa的使用
更多请关注公众号 Spring Data Jpa 简介 JPA JPA(Java Persistence API)意即Java持久化API,是Sun官方在JDK5.0后提出的Java持久化规范(JSR ...
随机推荐
- ORACLE数据库的备份分为物理备份和逻辑备份两种。
物理备份是将实际组成数据库的操作系统文件从一处拷贝到另一处的备份过程,通常是从磁盘到磁带.可以使用 Oracle 的恢复管理器(Recovery Manager,RMAN)或操作系统命令进行数据库的物 ...
- String的用法——获取功能
package cn.itcast_04; /* String类获取功能 int length():获取字符的长度 char charAt(int index):获取指定索引位置的字符 int ind ...
- wget安装更新
#查看当前wget版本信息 wget -V #下载 wget https://ftp.gnu.org/gnu/wget/wget-1.19.tar.gz #解压 tar xvf wget-1.19.t ...
- phpmyadmin在linux下通过sock安装教程
当初是按照 http://www.cnblogs.com/freeweb/p/5262852.html 地址参考安装,因为疏忽,未考虑到版本差异带来的影响(自身安装的是最新版 phpMyAdmin-4 ...
- ASP.NET Eval四种绑定方式 及详解
1.1.x中的数据绑定语法 <asp:Literal id="litEval2" runat="server" Text='<%#DataBinde ...
- -webkit/IE/Firefox的一些样式
仅限于-webkit的样式特效:-webkit-overflow-scrolling:touch;滚动时回弹效果:如果出现偶尔卡住不动的情况,那么在使用该属性的元素上不设置定位或者手动设置定位为sta ...
- Vuex/Vue 练手项目 在线汇率转换器
详情请点击: https://zhuanlan.zhihu.com/p/33362758
- Discuz 页面不能加载插件的原因和解决方法
模板中,<!--{subtemplate common/headerF}-->这样就不能加载 source/class/class_template.php里65行附近代码 $header ...
- 详解 pcap_findalldevs_ex
pcap是packet capture的缩写.意为抓包. 功能:查找所有网络设备 原型:int pcap_findalldevs_ex(char* source, struct pcap_rmtau ...
- CAD嵌套打印(网页版)
当用户需要打印两个CAD控件的图纸时,可以采用嵌套打印实现.点击此处在线演示. 实现嵌套打印功能,首先将两个CAD控件放入网页中,js代码如下: <p align="center&qu ...