大数据学习——mapreduce学习topN问题
求每一个订单中成交金额最大的那一笔 top1
数据
Order_0000001,Pdt_01,222.8
Order_0000001,Pdt_05,25.8
Order_0000002,Pdt_05,325.8
Order_0000002,Pdt_03,522.8
Order_0000002,Pdt_04,122.4
Order_0000003,Pdt_01,222.8
Order_0000003,Pdt_01,322.8
pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>com.cyf</groupId>
<artifactId>MapReduceCases</artifactId>
<packaging>jar</packaging>
<version>1.0</version> <properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.6.4</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.6.4</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.6.4</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>2.6.4</version>
</dependency> <dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.1.40</version>
</dependency> <dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.36</version>
</dependency>
</dependencies> <build>
<plugins>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<appendAssemblyId>false</appendAssemblyId>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
<archive>
<manifest>
<mainClass>cn.itcast.mapreduce.top.one.TopOne</mainClass>
</manifest>
</archive>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>assembly</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build> </project>
package cn.itcast.mapreduce.top.one; import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException; import org.apache.hadoop.io.DoubleWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.WritableComparable; /**
*
*
*/
public class OrderBean implements WritableComparable<OrderBean> { private Text itemid;
private DoubleWritable amount; public OrderBean() {
} public OrderBean(Text itemid, DoubleWritable amount) {
set(itemid, amount); } public void set(Text itemid, DoubleWritable amount) { this.itemid = itemid;
this.amount = amount; } public Text getItemid() {
return itemid;
} public DoubleWritable getAmount() {
return amount;
} public int compareTo(OrderBean o) {
int cmp = this.itemid.compareTo(o.getItemid());
if (cmp == 0) { cmp = -this.amount.compareTo(o.getAmount()); }
return cmp;
} public void write(DataOutput out) throws IOException {
out.writeUTF(itemid.toString());
out.writeDouble(amount.get()); } public void readFields(DataInput in) throws IOException {
String readUTF = in.readUTF();
double readDouble = in.readDouble(); this.itemid = new Text(readUTF);
this.amount = new DoubleWritable(readDouble);
} @Override
public String toString() { return itemid.toString() + "\t" + amount.get(); } }
package cn.itcast.mapreduce.top.one; import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.io.WritableComparator; /**
*
*/
public class ItemidGroupingComparator extends WritableComparator { protected ItemidGroupingComparator() { super(OrderBean.class, true);
} @Override
public int compare(WritableComparable a, WritableComparable b) {
OrderBean abean = (OrderBean) a;
OrderBean bbean = (OrderBean) b; //��item_id��ͬ��bean����Ϊ��ͬ���Ӷ�ۺ�Ϊһ��
return abean.getItemid().compareTo(bbean.getItemid()); } }
package cn.itcast.mapreduce.top.one; import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Partitioner; public class ItemIdPartitioner extends Partitioner<OrderBean, NullWritable> { @Override
public int getPartition(OrderBean key, NullWritable value, int numPartitions) {
//ָ
return (key.getItemid().hashCode() & Integer.MAX_VALUE) % numPartitions; } }
package cn.itcast.mapreduce.top.one; import java.io.IOException; import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.DoubleWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import com.sun.xml.bind.v2.schemagen.xmlschema.List; /**
* ����secondarysort�������ÿ��item����������ļ�¼
*
* @author AllenWoon
*/
public class TopOne { static class TopOneMapper extends Mapper<LongWritable, Text, OrderBean, NullWritable> { OrderBean bean = new OrderBean(); /* Text itemid = new Text(); */ @Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String line = value.toString();
String[] fields = StringUtils.split(line, ","); bean.set(new Text(fields[0]), new DoubleWritable(Double.parseDouble(fields[2]))); context.write(bean, NullWritable.get()); } } static class TopOneReducer extends Reducer<OrderBean, NullWritable, OrderBean, NullWritable> { @Override
protected void reduce(OrderBean key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException {
context.write(key, NullWritable.get());
}
} public static void main(String[] args) throws Exception { Configuration conf = new Configuration();
Job job = Job.getInstance(conf); // job.setJarByClass(TopOne.class); //告诉框架,我们的程序所在jar包的位置
job.setJar("/root/TopOne.jar");
job.setMapperClass(TopOneMapper.class);
job.setReducerClass(TopOneReducer.class); job.setOutputKeyClass(OrderBean.class);
job.setOutputValueClass(NullWritable.class); FileInputFormat.setInputPaths(job, new Path("/top/input"));
FileOutputFormat.setOutputPath(job, new Path("/top/output1"));
// FileInputFormat.setInputPaths(job, new Path(args[0]));
// FileOutputFormat.setOutputPath(job, new Path(args[1]));
// ָ��shuffle��ʹ�õ�GroupingComparator��
job.setGroupingComparatorClass(ItemidGroupingComparator.class);
// ָ��shuffle��ʹ�õ�partitioner��
job.setPartitionerClass(ItemIdPartitioner.class); job.setNumReduceTasks(1); job.waitForCompletion(true); } }
创建文件夹
hadoop fs -mkdir -p /top/input
上传数据
hadoop fs -put top.txt /top/input
运行
hadoop jar TopOne.jar cn.itcast.mapreduce.top.one.TopOne
运行结果

topN
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>com.cyf</groupId>
<artifactId>MapReduceCases</artifactId>
<packaging>jar</packaging>
<version>1.0</version> <properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.6.4</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.6.4</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.6.4</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>2.6.4</version>
</dependency> <dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.1.40</version>
</dependency> <dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.36</version>
</dependency>
</dependencies> <build>
<plugins>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<appendAssemblyId>false</appendAssemblyId>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
<archive>
<manifest>
<mainClass>cn.itcast.mapreduce.top.n.TopN</mainClass>
</manifest>
</archive>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>assembly</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build> </project>
package cn.itcast.mapreduce.top.n; import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException; import org.apache.hadoop.io.DoubleWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.WritableComparable; /**
* ������Ϣbean��ʵ��hadoop�����л�����
*/
public class OrderBean implements WritableComparable<OrderBean> { private Text itemid;
private DoubleWritable amount; public OrderBean() {
} public OrderBean(Text itemid, DoubleWritable amount) {
set(itemid, amount); } public void set(Text itemid, DoubleWritable amount) { this.itemid = itemid;
this.amount = amount; } public Text getItemid() {
return itemid;
} public DoubleWritable getAmount() {
return amount;
} public int compareTo(OrderBean o) {
int cmp = this.itemid.compareTo(o.getItemid());
if (cmp == 0) { cmp = -this.amount.compareTo(o.getAmount()); }
return cmp;
} public void write(DataOutput out) throws IOException {
out.writeUTF(itemid.toString());
out.writeDouble(amount.get()); } public void readFields(DataInput in) throws IOException {
String readUTF = in.readUTF();
double readDouble = in.readDouble(); this.itemid = new Text(readUTF);
this.amount = new DoubleWritable(readDouble);
} @Override
public String toString() { return itemid.toString() + "\t" + amount.get(); } /*
* @Override public int hashCode() {
*
* return this.itemid.hashCode(); }
*/
@Override
public boolean equals(Object obj) {
OrderBean bean = (OrderBean) obj; return bean.getItemid().equals(this.itemid);
} }
package cn.itcast.mapreduce.top.n; import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.io.WritableComparator; /**
* ���ڿ���shuffle�����reduce�˶�kv�Եľۺ���
*/
public class ItemidGroupingComparator extends WritableComparator { protected ItemidGroupingComparator() { super(OrderBean.class, true);
} @Override
public int compare(WritableComparable a, WritableComparable b) {
OrderBean abean = (OrderBean) a;
OrderBean bbean = (OrderBean) b; //��item_id��ͬ��bean����Ϊ��ͬ���Ӷ�ۺ�Ϊһ��
return abean.getItemid().compareTo(bbean.getItemid()); } }
package cn.itcast.mapreduce.top.n; import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Partitioner; public class ItemIdPartitioner extends Partitioner<OrderBean, NullWritable> { @Override
public int getPartition(OrderBean key, NullWritable value, int numPartitions) {
//ָ��item_id��ͬ��bean������ͬ��reducer task
return (key.getItemid().hashCode() & Integer.MAX_VALUE) % numPartitions; } }
package cn.itcast.mapreduce.top.n; import java.io.IOException; import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.fs.shell.Count;
import org.apache.hadoop.io.DoubleWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import com.sun.xml.bind.v2.schemagen.xmlschema.List; /**
* ����secondarysort�������ÿ��item����������ļ�¼
*/
public class TopN { static class TopNMapper extends Mapper<LongWritable, Text, OrderBean, OrderBean> { OrderBean v = new OrderBean();
Text k = new Text(); @Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String line = value.toString();
String[] fields = StringUtils.split(line, ",");
k.set(fields[0]); v.set(new Text(fields[0]), new DoubleWritable(Double.parseDouble(fields[2]))); context.write(v, v); } } static class TopNReducer extends Reducer<OrderBean, OrderBean, NullWritable, OrderBean> {
int topn = 1;
int count = 0; @Override
protected void setup(Context context) throws IOException, InterruptedException {
Configuration conf = context.getConfiguration();
topn = Integer.parseInt(conf.get("topn"));
} @Override
protected void reduce(OrderBean key, Iterable<OrderBean> values, Context context) throws IOException, InterruptedException {
for (OrderBean bean : values) {
if ((count++) == topn) {
count = 0;
return;
}
context.write(NullWritable.get(), bean);
}
}
} public static void main(String[] args) throws Exception { Configuration conf = new Configuration();
// ָ������classpath�µ��û��Զ��������ļ�
// conf.addResource("userconfig.xml");
// System.out.println(conf.get("top.n"));
// Ҳ����ֱ���ô��������ò���ݸ�mapreduce�����ڲ�ʹ��
conf.set("topn", "2");
Job job = Job.getInstance(conf); // job.setJarByClass(TopN.class); //告诉框架,我们的程序所在jar包的位置
job.setJar("/root/TopOne.jar");
job.setMapperClass(TopNMapper.class);
job.setReducerClass(TopNReducer.class); job.setMapOutputKeyClass(OrderBean.class);
job.setMapOutputValueClass(OrderBean.class); job.setOutputKeyClass(NullWritable.class);
job.setOutputValueClass(OrderBean.class); FileInputFormat.setInputPaths(job, new Path("/top/input"));
FileOutputFormat.setOutputPath(job, new Path("/top/outputn"));
// ָ��shuffle��ʹ�õ�partitioner��
job.setPartitionerClass(ItemIdPartitioner.class);
job.setGroupingComparatorClass(ItemidGroupingComparator.class); job.setNumReduceTasks(1); job.waitForCompletion(true); } }
打包并运行

运行
hadoop jar TopN.jar cn.itcast.mapreduce.top.n.TopN
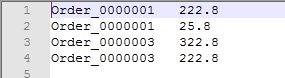
运行结果 n=2
大数据学习——mapreduce学习topN问题的更多相关文章
- 【机器学习实战】第15章 大数据与MapReduce
第15章 大数据与MapReduce 大数据 概述 大数据: 收集到的数据已经远远超出了我们的处理能力. 大数据 场景 假如你为一家网络购物商店工作,很多用户访问该网站,其中有些人会购买商品,有些人则 ...
- 大数据技术 - MapReduce的Combiner介绍
本章来简单介绍下 Hadoop MapReduce 中的 Combiner.Combiner 是为了聚合数据而出现的,那为什么要聚合数据呢?因为我们知道 Shuffle 过程是消耗网络IO 和 磁盘I ...
- 【大数据】Hive学习笔记
第1章 Hive基本概念 1.1 什么是Hive Hive:由Facebook开源用于解决海量结构化日志的数据统计. Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张表, ...
- 【大数据】Sqoop学习笔记
第1章 Sqoop简介 Sqoop是一款开源的工具,主要用于在Hadoop(Hive)与传统的数据库(mysql.postgresql...)间进行数据的传递,可以将一个关系型数据库(例如 : MyS ...
- 想转行大数据,开始学习 Hadoop?
学习大数据首先要了解大数据的学习路线,首先搞清楚先学什么,再学什么,大的学习框架知道了,剩下的就是一步一个脚印踏踏实实从最基础的开始学起. 这里给大家普及一下学习路线:hadoop生态圈——Strom ...
- 【福利】送Spark大数据平台视频学习资料
没有套路真的是送!! 大家都知道,大数据行业spark很重要,那话我就不多说了,贴心的大叔给你找了份spark的资料. 多啰嗦两句,一个好的程序猿的基本素养是学习能力和自驱力.视频给了你们,能不能 ...
- 【大数据】Scala学习笔记
第 1 章 scala的概述1 1.1 学习sdala的原因 1 1.2 Scala语言诞生小故事 1 1.3 Scala 和 Java 以及 jvm 的关系分析图 2 1.4 Scala语言的特点 ...
- 大数据-spark-hbase-hive等学习视频资料
不错的大数据spark学习资料,连接过期在评论区评论,再给你分享 https://pan.baidu.com/s/1ts6RNuFpsnc39tL3jetTkg
- 云计算、大数据、编程语言学习指南下载,100+技术课程免费学!这份诚意满满的新年技术大礼包,你Get了吗?
开发者认证.云学院.技术社群,更多精彩,尽在开发者会场 近年来,新技术发展迅速.互联网行业持续高速增长,平均薪资水平持续提升,互联网技术学习已俨然成为学生.在职人员都感兴趣的“业余项目”. 阿里云大学 ...
- Oracle大数据解决方案》学习笔记5——Oracle大数据机的配置、部署架构和监控-1(BDA Config, Deployment Arch, and Monitoring)
原创预见未来to50 发布于2018-12-05 16:18:48 阅读数 146 收藏 展开 这章的内容很多,有的学了. 1. Oracle大数据机——灵活和可扩展的架构 2. Hadoop集群的 ...
随机推荐
- hbuilder 中文乱码
这是因为HBuilder默认文件编码是UTF-8,你可以在工具-选项-常规-工作空间选项中设置默认字符编码
- [已读]JavaScript编程精解
译者汤姆大叔,应该很多人都知道,他写了一系列的关于闭包与作用域理解的文章,但是由于创建了一些我不理解的新名词,我不爱看. <JavaScript编程精解>算是买得比较早的一本书,那会大肆搜 ...
- Centos 6.5安装MySQL-Python遇到的问题--解决办法一
系统:CentOS release 6.5 (Final) MySQL版本:mysql Ver 14.14 Distrib 5.7.19, for Linux (x86_64) using Edi ...
- 启动azkaban时出现User xml file conf/azkaban-users.xml doesn't exist问题解决(图文详解)
问题详情 [hadoop@master azkaban]$ ll total drwxrwxr-x hadoop hadoop May : azkaban- drwxrwxr-x hadoop h ...
- 对js 面对对象编程的一些简单的理解
由简单开始深入: 最简单的 直接对象开始 var desen = { age:24, name:'xyf', job:'fontEnd', getName:function(){ console.lo ...
- Mysql框架---HMySql
Java 数据库框架 在我学习java数据库框架的时候,第一个用的是Hibernate,但是到现在,我可能已经快忘记它了,毕竟快两年没有碰的东西,后来一直再用MyBatis.因为它简单. 但是本文不会 ...
- Map集合的实现类
Map的继承关系: Map接口的常用实现类: 1.HashMap.Hashtable(t是小写) HashMap不是线程安全的,key.value的值都可以是null. Hashtable是线程安全的 ...
- 【转】一篇文章,教你学会Git
一篇文章,教你学会Git 在日常工作中,经常会用到Git操作.但是对于新人来讲,刚上来对Git很陌生,操作起来也很懵逼.本篇文章主要针对刚开始接触Git的新人,理解Git的基本原理,掌握常用的一些命令 ...
- T4308 数据结构判断
https://www.luogu.org/record/show?rid=2143639 题目描述 在世界的东边,有三瓶雪碧. ——laekov 黎大爷为了虐 zhx,给 zhx 出了这样一道题.黎 ...
- asp.net mvc 5 微信接入VB版 - 接入认证
微信接入官方文档是php的,网上被抄好几遍的代码是c#的,就是没vb的.今天我把这个坑填了,做vb版的接入认证. 首先是照着开发文档把微信接入的模型写好.在Models文件夹新建一个Model Pub ...