spark与Scala安装过程和步骤及sparkshell命令的使用

Spark与Scala版本兼容问题:
Spark运行在Java 8 +,Python 2.7 + / 3.4 +和R 3.1+上。对于Scala API,Spark 2.4.2使用Scala 2.12。您需要使用兼容的Scala版本(2.12.x)。
请注意,自Spark 2.2.0起,对2.6.5之前的Java 7,Python 2.6和旧Hadoop版本的支持已被删除。自2.3.0起,对Scala 2.10的支持被删除。自Spark 2.4.1起,对Scala 2.11的支持已被弃用,将在Spark 3.0中删除。
https://spark.apache.org/docs/latest/index.html
1.官网下载安装Scala:scala-2.12.8.tgz
https://www.scala-lang.org/download/
2.将Scala解压到/opt/module目录下
tar -zxvf scala-2.12.8.tgz -C /opt/module
3.将scala-2.12.8改成Scala
mv scala-2.12.8 scala
4.测试scala是否安装成功
测试:scala -version
5.启动Scala命令:scala

1.官网下载安装Spark:spark-2.4.2-bin-hadoop2.7.tgz
https://www.apache.org/dyn/closer.lua/spark/spark-2.4.2/spark-2.4.2-bin-hadoop2.7.tgz
2.解压、重命名
ar -zxvf spark-2.4.2-bin-hadoop2.7.tgz -C /opt/module
mv spark-2.4.2-bin-hadoop2.7.tgz spark
3.配置环境变量
export SPARK_HOME=/opt/module/spark
export PATH=$PATH:$SPARK_HOME/bin #
使环境变量生效 :source /etc/profile
4.启动spark
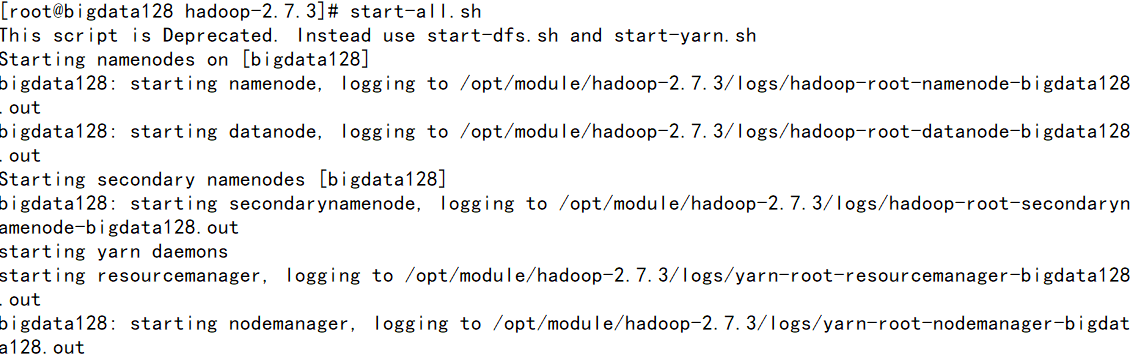
①先启动hadoop 环境
start-all.sh
②启动spark环境
进入到SPARK_HOME/sbin下运行start-all.sh
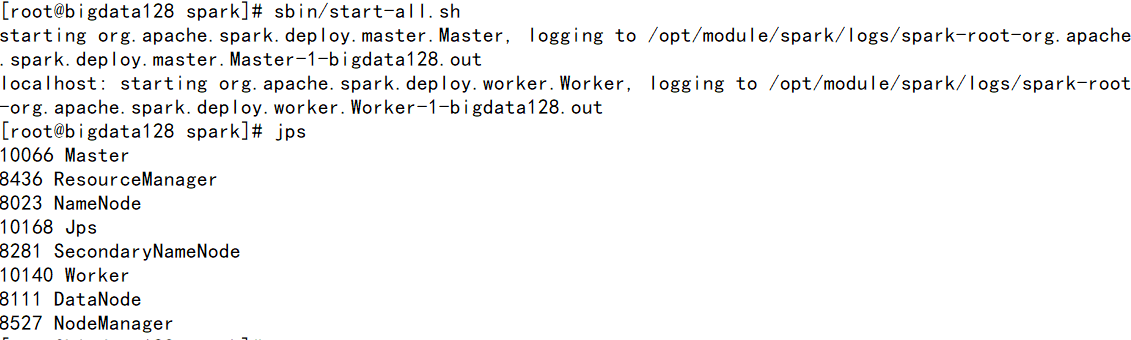
[注] 如果使用start-all.sh时候会重复启动hadoop配置,需要./在当前工作目录下执行命令
jps 观察进程 多出 worker 和 mater 两个进程。
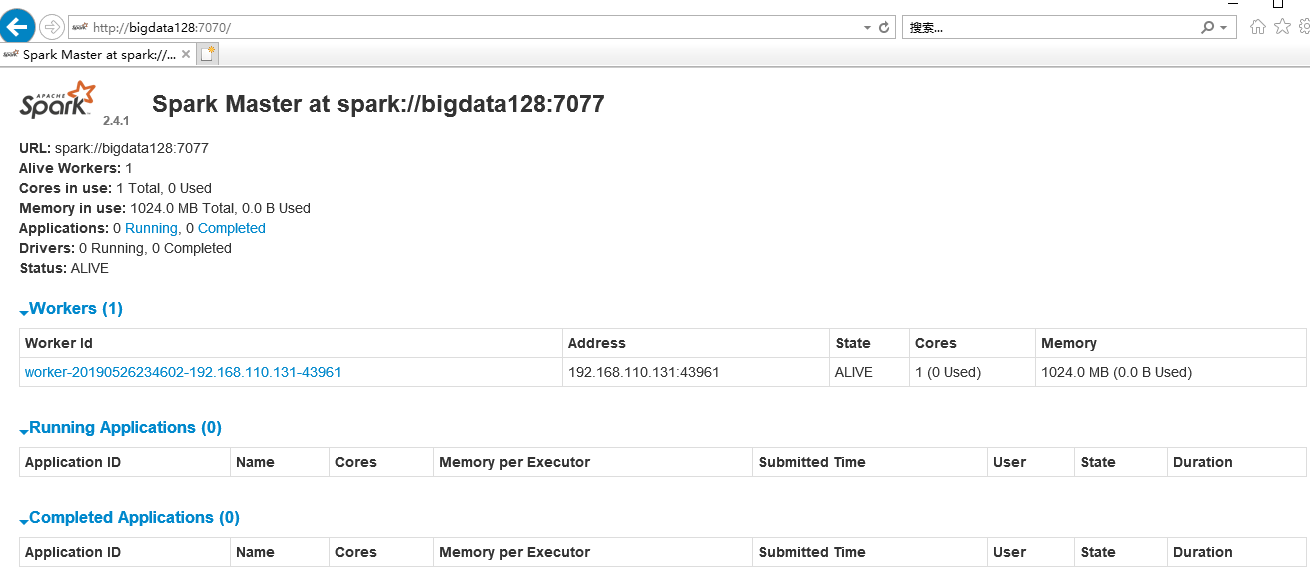
5.查看spark的web控制页面:http://bigdata128:7077/
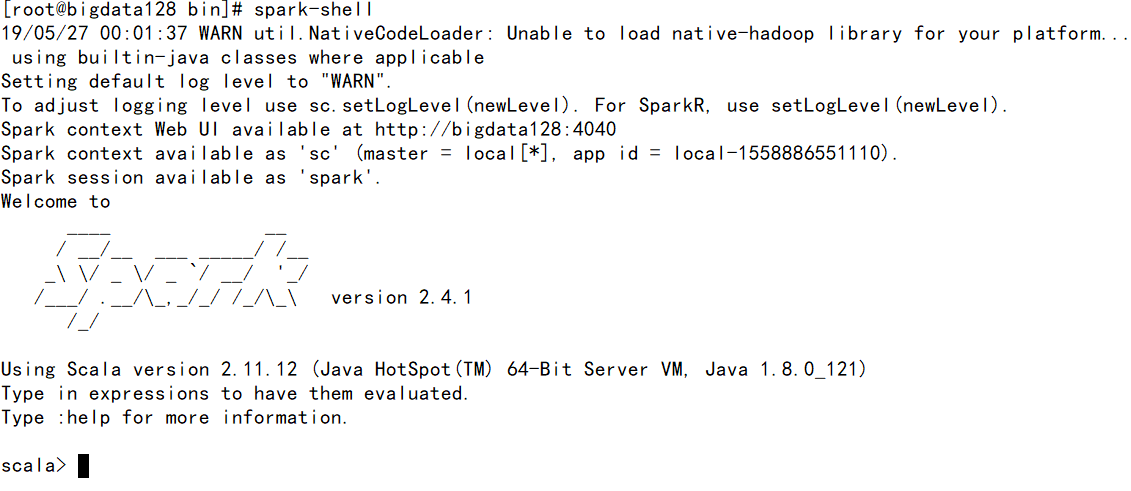
使用Spark-shell命令
此模式用于interactive programming,先进入bin文件夹后运行:spark-shell

spark与Scala安装过程和步骤及sparkshell命令的使用的更多相关文章
- Bigbluebutton安装过程
BigBlueButton安装过程(翻译) 欢迎来到BigBlueButton 1.0-beta安装指南(以下简称BigBlueButton 1.0).BigBlueButton是一个开放源代码的网络 ...
- Spark安装过程纪录
1 Scala安装 1.1 master 机器 修改 scala 目录所属用户和用户组. sudo chown -R hadoop:hadoop scala 修改环境变量文件 .bashrc , 添加 ...
- JProfiler远程监控Linux上Tomcat的安装过程细讲(步骤非常详细!!!)
JProfiler远程监控Linux上Tomcat的安装过程细讲(步骤非常详细!!!) 1.文件准备: 服务器:CentOS Linux release 7.3.1611 (Core) Apa ...
- Spark安装过程
Precondition:jdk.Scala安装,/etc/profile文件部分内容如下: JAVA_HOME=/home/Spark/husor/jdk CLASSPATH=.:$JAVA_HOM ...
- eclipse创建maven管理Spark的scala
说明,由于spark是用scala写的.因此,不管是在看源码还是在写spark有关的代码的时候,都最好是用scala.那么作为一个程序员首先是必须要把手中的宝剑给磨砺了.那就是创建好编写scala的代 ...
- Spark学习笔记——安装和WordCount
1.去清华的镜像站点下载文件spark-2.1.0-bin-without-hadoop.tgz,不要下spark-2.1.0-bin-hadoop2.7.tgz 2.把文件解压到/usr/local ...
- spark集群安装部署
通过Ambari(HDP)或者Cloudera Management (CDH)等集群管理服务安装和部署在此不多介绍,只需要在界面直接操作和配置即可,本文主要通过原生安装,熟悉安装配置流程. 1.选取 ...
- Win7 单机Spark和PySpark安装
欢呼一下先.软件环境菜鸟的我终于把单机Spark 和 Pyspark 安装成功了.加油加油!!! 1. 安装方法参考: 已安装Pycharm 和 Intellij IDEA. win7 PySpark ...
- spark集群安装配置
spark集群安装配置 一. Spark简介 Spark是一个通用的并行计算框架,由UCBerkeley的AMP实验室开发.Spark基于map reduce 算法模式实现的分布式计算,拥有Hadoo ...
随机推荐
- 20171201Jsp Jstl详细配置
Jsp Jstl详细配置 1. 下载包 http://archive.apache.org/dist/jakarta/taglibs/standard/binaries/jakarta-taglibs ...
- path.join()与path.resolve()区别
1.path.resolve([...paths]) path.resolve() 方法会把一个路径或路径片段的序列解析为一个绝对路径. 给定的路径的序列是从右往左被处理的,后面每个 path 被依次 ...
- python计算机基础(一)
什么是编程语言? 跟计算机交流的语言 什么是编程? 编程就是写代码,让计算机能够听懂的语言 为什么要编程? 让计算机为我们做事,取代人 计算机5大组成分别有什么作用? CPU:控制,判断,配作用,内存 ...
- jQuery和Vue
jQuery 概述 是js的一种函数库有美国人 John Resig编写 特点 写的少,做的多,国内用的jq1.0版本,可以兼容低版本的浏览器,支持链式编程或链式调用和隐式迭代 链式编程 $(this ...
- (转)iOS 常用宏定义
#ifndef MacroDefinition_h #define MacroDefinition_h //-------------------获取设备大小------------------- ...
- spring的自动装配,骚话@Autowired的底层工作原理
前言 开心一刻 十年前,我:我交女票了,比我大两岁.妈:不行!赶紧分! 八年前,我:我交女票了,比我小两岁,外地的.妈:你就不能让我省点心? 五年前,我:我交女票了,市长的女儿.妈:别人还能看上你?分 ...
- sql server 2008启动时:已成功与服务器建立连接,但是在登录过程中发生错误。(provider:命名管道提供程序,error:0-管道的另一端上无任何进程。)(Microsoft SQL Server,错误:233) 然后再连接:错误:18456
问题:sql server 2008启动时:已成功与服务器建立连接,但是在登录过程中发生错误.(provider:命名管道提供程序,error:0-管道的另一端上无任何进程.)(Microsoft S ...
- 九度oj 题目1159:坠落的蚂蚁
题目描述: 一根长度为1米的木棒上有若干只蚂蚁在爬动.它们的速度为每秒一厘米或静止不动,方向只有两种,向左或者向右.如果两只蚂蚁碰头,则它们立即交换速度并继续爬动.三只蚂蚁碰头,则两边的蚂蚁交换速度, ...
- 也来“玩”Metro UI之磁贴(一)
Win8出来已有一段时间了,个人是比较喜欢Metro UI的.一直以来想用Metro UI来做个自己的博客,只是都没有空闲~~今天心血来潮,突然想自己弄一个磁贴玩玩,动手……然后就有了本篇. Win8 ...
- tomcat的管理(manager)报错403
管理tomcat的时候遇到了以下问题: 1.刚开始需要用户名密码,不知道用户名和密码是什么,但是输入什么都不正确. 解决办法: 自己在tomcat-users.xml中按格式添加用户 conf文件夹里 ...