postgres SQL编译过程
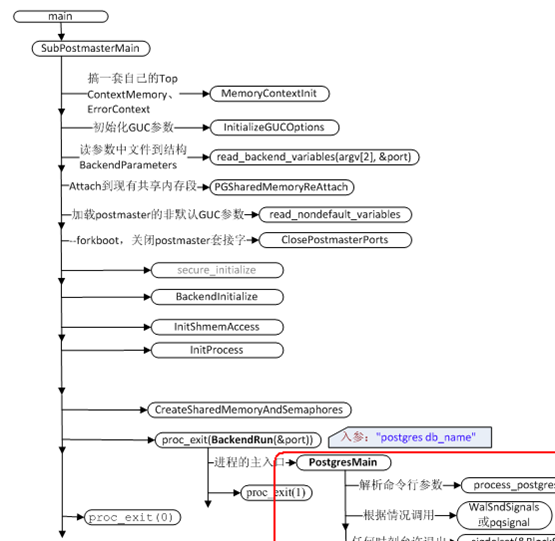

PG启动首先完成主进程和后台进程的启动,启动时完成数据库文件的打开,共享内存的建立等。接着,所有SQL都会启动1个单独的进程处理SQL的执行过程。
新的进程首先是进行自身的初始化,最主要的是初始化内存上下文,准备好SQL处理过程。
进入PostgresMain后,解析客户端命令行参数dbname;做文件、存储、缓存的初始化;设置合适的信号处理句柄;调用InitPostgres方法给portgres服务进程做相关初始化,这个方法里初始化了relcache和catcache,初始化了执行查询计划的portal的管理器,填充本进程PGPROC结构相关部分成员等。进入无限循环,检查并处理任何请求或者最近收到的信号。然后再接着循环。
循环一直在ReadCommand。 进入无限循环后,切换到内存上下文"MessageContext"并清理干净该内存上下文;读取客户端命令;根据客户端各种命令分别进行处理。

客户端发起请求,pg服务器为该请求启动一个postgres访问进程为该客户端通过访问,建立了连接。这个postgres访问进程进入无限循环,等待客户端请求并为其通过服务,直到进程终止,连接断口。
当客户端给服务器端发出查询SQL后,建立连接时已经启动且进入无限循环的服务器端的postgres服务进程处理步骤如下:
(1)调用MemoryContextSwitchTo切换内存上下文到"MessageContext"。
(2)调用MemoryContextResetAndDeleteChildren清理上次为相同连接服务时"MessageContext"内存上下文里遗留的对象。
(3)调用ReadCommand读取客户端的请求。
(4)根据客户端请求判断要提供何种服务,进入相应分支。
从源码的角度分析sql编译过程:
对于一个简单SQL查询,主要的处理过程是先调用start_xact_command方法开启一个事务,再用pg_parse_query方法用词法语法解析工具把查询命令解析为解析树parsetree,根据需要调用PushActiveSnapshot方法搞一个快照,调用pg_analyze_and_rewrite方法分析、根据规则重写解析树为查询树querytree,调用pg_plan_queries方法把查询树转换到执行计划树plantree,在调用相应方法创建portal和在postal中执行执行计划树并给客户端发回结果。然后退出当前事务,清理内存。
src/backend/parser下,scan.l为词法定义,gram.y为语法定义。
postgres SQL编译过程的更多相关文章
- Hive SQL 编译过程
转自:http://www.open-open.com/lib/view/open1400644430159.html Hive跟Impala貌似都是公司或者研究所常用的系统,前者更稳定点,实现方式是 ...
- Hive SQL编译过程(转)
转自:https://www.cnblogs.com/zhzhang/p/5691997.html Hive是基于Hadoop的一个数据仓库系统,在各大公司都有广泛的应用.美团数据仓库也是基于Hive ...
- 【转】Hive SQL的编译过程
Hive是基于Hadoop的一个数据仓库系统,在各大公司都有广泛的应用.美团数据仓库也是基于Hive搭建,每天执行近万次的Hive ETL计算流程,负责每天数百GB的数据存储和分析.Hive的稳定性和 ...
- Hive SQL的编译过程
文章转自:http://tech.meituan.com/hive-sql-to-mapreduce.html Hive是基于Hadoop的一个数据仓库系统,在各大公司都有广泛的应用.美团数据仓库也是 ...
- 转:Hive SQL的编译过程
Hive是基于Hadoop的一个数据仓库系统,在各大公司都有广泛的应用.美团数据仓库也是基于Hive搭建,每天执行近万次的Hive ETL计算流程,负责每天数百GB的数据存储和分析.Hive的稳定性和 ...
- Hive SQL的编译过程[转载自https://tech.meituan.com/hive-sql-to-mapreduce.html]
https://tech.meituan.com/hive-sql-to-mapreduce.html Hive是基于Hadoop的一个数据仓库系统,在各大公司都有广泛的应用.美团数据仓库也是基于Hi ...
- Hive SQL的底层编译过程详解
本文结构采用宏观着眼,微观入手,从整体到细节的方式剖析 Hive SQL 底层原理.第一节先介绍 Hive 底层的整体执行流程,然后第二节介绍执行流程中的 SQL 编译成 MapReduce 的过程, ...
- 对MySql查询缓存及SQL Server过程缓存的理解及总结
一.MySql的Query Cache 1.Query Cache MySQL Query Cache是用来缓存我们所执行的SELECT语句以及该语句的结果集.MySql在实现Query Cache的 ...
- Spark源码的编译过程详细解读(各版本)
说在前面的话 重新试多几次.编译过程中会出现下载某个包的时间太久,这是由于连接网站的过程中会出现假死,按ctrl+c,重新运行编译命令. 如果出现缺少了某个文件的情况,则要先清理maven(使用命 ...
随机推荐
- PHP cannoy modify header information - headers already sent by ....
我采用的是MVC模式的写法,代码和html分离的写法 <?php require '../mysql_connect.php'; require('../model/functions.php' ...
- HDU 5016 Mart Master II
Mart Master II Time Limit: 6000ms Memory Limit: 65536KB This problem will be judged on HDU. Original ...
- 算法复习——序列分治(ssoj光荣的梦想)
题目: 题目描述 Prince对他在这片大陆上维护的秩序感到满意,于是决定启程离开艾泽拉斯.在他动身之前,Prince决定赋予King_Bette最强大的能量以守护世界.保卫这里的平衡与和谐.在那个时 ...
- 【bzoj2751】[HAOI2012]容易题(easy) 数论,简单题
Description 为了使得大家高兴,小Q特意出个自认为的简单题(easy)来满足大家,这道简单题是描述如下:有一个数列A已知对于所有的A[i]都是1~n的自然数,并且知道对于一些A[i]不能取哪 ...
- JSP学习笔记(七十八):struts2中s:select标签的使用
1.第一个例子: <s:select list="{'aa','bb','cc'}" theme="simple" headerKey="00& ...
- [NOIP2009] 提高组 洛谷P1072 Hankson 的趣味题
题目描述 Hanks 博士是 BT (Bio-Tech,生物技术) 领域的知名专家,他的儿子名叫 Hankson.现 在,刚刚放学回家的 Hankson 正在思考一个有趣的问题. 今天在课堂上,老师讲 ...
- springboot收集
Spring Boot实战:拦截器与过滤器 参考:https://blog.csdn.net/m0_37106742/article/details/64438892 https://www.ibm. ...
- 【C++】DLL内共享数据区在进程间共享数据(重要)
因项目需要,需要在DLL中共享数据,即DLL中某一变量只执行一次,在运行DLL中其他函数时该变量值不改变:刚开始想法理解错误,搜到了DLL进程间共享数据段,后面发现直接在DLL中定义全局变量就行,当时 ...
- android开启线程,异步处理数据实例
package com.example.sywang2; import com.zds.os.R; import android.os.Bundle; import android.os.Handle ...
- UTF-8 编码的文件在处理时要注意 BOM 文件头问题
最近在给项目团队开发一个基于 Java 的通用的 XML 分析器时,设计了一个方法,能够读取现成的 XML 文件进行分析处理,当然 XML 都是采用 UTF-8 进行编码的.但是在用 UltraEdi ...