ElasticSearch聚合入门(续)
主要理解聚合中的terms。
参考:http://www.cnblogs.com/xing901022/p/4947436.html
Terms聚合
记录有多少F,多少M
{
"size": 0,
"aggs": {
"genders": {
"terms": {
"field": "gender"
}
}
}
}
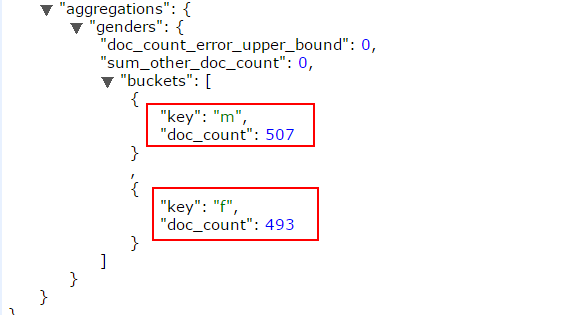
返回结果如下:m记录507条,f记录493条
数据的不确定性
使用terms聚合,结果可能带有一定的偏差与错误性。
比如:
我们想要获取name字段中出现频率最高的前5个。
此时,客户端向ES发送聚合请求,主节点接收到请求后,会向每个独立的分片发送该请求。
分片独立的计算自己分片上的前5个name,然后返回。当所有的分片结果都返回后,在主节点进行结果的合并,再求出频率最高的前5个,返回给客户端。
这样就会造成一定的误差,比如最后返回的前5个中,有一个叫A的,有50个文档;B有49。 但是由于每个分片独立的保存信息,信息的分布也是不确定的。 有可能第一个分片中B的信息有2个,但是没有排到前5,所以没有在最后合并的结果中出现。 这就导致B的总数少计算了2,本来可能排到第一位,却排到了A的后面。
size与shard_size
为了改善上面的问题,就可以使用size和shard_size参数。
- size参数规定了最后返回的term个数(默认是10个)
- shard_size参数规定了每个分片上返回的个数
- 如果shard_size小于size,那么分片也会按照size指定的个数计算
通过这两个参数,如果我们想要返回前5个,size=5;shard_size可以设置大于5,这样每个分片返回的词条信息就会增多,相应的误差几率也会减小。
order排序
order指定了最后返回结果的排序方式,默认是按照doc_count排序。
{
"aggs" : {
"genders" : {
"terms" : {
"field" : "gender",
"order" : { "_count" : "asc" }
}
}
}
}
也可以按照字典方式排序:
{
"aggs" : {
"genders" : {
"terms" : {
"field" : "gender",
"order" : { "_term" : "asc" }
}
}
}
}
当然也可以通过order指定一个单值聚合,来排序。
{
"aggs" : {
"genders" : {
"terms" : {
"field" : "gender",
"order" : { "avg_balance" : "desc" }
},
"aggs" : {
"avg_balance" : { "avg" : { "field" : "balance" } }
}
}
}
}
同时也支持多值聚合,不过要指定使用的多值字段:
{
"aggs" : {
"genders" : {
"terms" : {
"field" : "gender",
"order" : { "balance_stats.avg" : "desc" }
},
"aggs" : {
"balance_stats" : { "stats" : { "field" : "balance" } }
}
}
}
}
返回结果:

min_doc_count与shard_min_doc_count
聚合的字段可能存在一些频率很低的词条,如果这些词条数目比例很大,那么就会造成很多不必要的计算。
因此可以通过设置min_doc_count和shard_min_doc_count来规定最小的文档数目,只有满足这个参数要求的个数的词条才会被记录返回。
通过名字就可以看出:
- min_doc_count:规定了最终结果的筛选
- shard_min_doc_count:规定了分片中计算返回时的筛选
script
桶聚合也支持脚本的使用:
{
"aggs" : {
"genders" : {
"terms" : {
"script" : "doc['gender'].value"
}
}
}
}
以及外部脚本文件:
{
"aggs" : {
"genders" : {
"terms" : {
"script" : {
"file": "my_script",
"params": {
"field": "gender"
}
}
}
}
}
}
filter
filter字段提供了过滤的功能,使用两种方式:include可以匹配出包含该值的文档,exclude则排除包含该值的文档。
例如:
{
"aggs" : {
"tags" : {
"terms" : {
"field" : "tags",
"include" : ".*sport.*",
"exclude" : "water_.*"
}
}
}
}上面的例子中,最后的结果应该包含sport并且不包含water。
也支持数组的方式,定义包含与排除的信息:
{
"aggs" : {
"JapaneseCars" : {
"terms" : {
"field" : "make",
"include" : ["mazda", "honda"]
}
},
"ActiveCarManufacturers" : {
"terms" : {
"field" : "make",
"exclude" : ["rover", "jensen"]
}
}
}
}多字段聚合
通常情况,terms聚合都是仅针对于一个字段的聚合。因为该聚合是需要把词条放入一个哈希表中,如果多个字段就会造成n^2的内存消耗。
不过,对于多字段,ES也提供了下面两种方式:
- 1 使用脚本合并字段
- 2 使用copy_to方法,合并两个字段,创建出一个新的字段,对新字段执行单个字段的聚合。
collect模式
对于子聚合的计算,有两种方式:
- depth_first 直接进行子聚合的计算
- breadth_first 先计算出当前聚合的结果,针对这个结果在对子聚合进行计算。
默认情况下ES会使用深度优先,不过可以手动设置成广度优先,比如:
{
"aggs" : {
"actors" : {
"terms" : {
"field" : "actors",
"size" : 10,
"collect_mode" : "breadth_first"
},
"aggs" : {
"costars" : {
"terms" : {
"field" : "actors",
"size" : 5
}
}
}
}
}
}缺省值Missing value
缺省值指定了缺省的字段的处理方式:
{
"aggs" : {
"tags" : {
"terms" : {
"field" : "tags",
"missing": "N/A"
}
}
}
}ElasticSearch聚合入门(续)的更多相关文章
- Elasticsearch详解-续
Elasticsearch详解-续 Chandler_珏瑜 关注 7.6 2019.05.22 10:46* 字数 8366 阅读 675评论 4喜欢 25 5.3 性能调优 Elasticse ...
- ElasticSearch聚合(转)
ES之五:ElasticSearch聚合 前言 说完了ES的索引与检索,接着再介绍一个ES高级功能API – 聚合(Aggregations),聚合功能为ES注入了统计分析的血统,使用户在面对大数据提 ...
- ElasticSearch聚合分析
聚合用于分析查询结果集的统计指标,我们以观看日志分析为例,介绍各种常用的ElasticSearch聚合操作. 目录: 查询用户观看视频数和观看时长 聚合分页器 查询视频uv 单个视频uv 批量查询视频 ...
- Elasticsearch 基础入门
原文地址:Elasticsearch 基础入门 博客地址:http://www.extlight.com 一.什么是 ElasticSearch ElasticSearch是一个基于 Lucene 的 ...
- Elasticsearch聚合问题
在测试Elasticsearch聚合的时候报了一个错误.具体如下: GET /megacorp/employee/_search { "aggs": { "all_int ...
- Elasticsearch从入门到放弃:分词器初印象
Elasticsearch 系列回来了,先给因为这个系列关注我的同学说声抱歉,拖了这么久才回来,这个系列虽然叫「Elasticsearch 从入门到放弃」,但只有三篇就放弃还是有点过分的,所以还是回来 ...
- ElasticSearch聚合aggs入门
Elasticsearch是一款功能强大的开源软件,不仅可以检索排序,还可以对文档进行更复杂的操作--聚合. 1.单值聚合 Sum求和,dsl参考如下: { "size": 0, ...
- Elasticsearch 教程--入门
1.1 初识 Elasticsearch 是一个建立在全文搜索引擎 Apache Lucene(TM) 基础上的搜索引擎,可以说 Lucene 是当今最先进,最高效的全功能开源搜索引擎框架. 但是 L ...
- Elasticsearch从入门到精通-Elasticsearch是什么
作者其他ELK快速入门系列文章 logstash快速入门实战指南 Kibana从入门到精通 一.前言 驱动未来商业发展的最重要“能源”不是石油,而是数据.我们还来不及了解它,这个世界已经被它淹没.多年 ...
随机推荐
- org.springframework.beans.factory.BeanCreationException: Error creating bean with name 'requestMappingHandlerMapping' defined in class path resource
spring boot web项目运行时提示如下错误 org.springframework.beans.factory.BeanCreationException: Error creating b ...
- java 使用htmlunit模拟登录爬取新浪微博页面
mport java.io.IOException;import java.net.MalformedURLException;import com.gargoylesoftware.htmlunit ...
- POJ1077 八数码 BFS
BFS 几天的超时... A*算法不会,哪天再看去了. /* 倒搜超时, 改成顺序搜超时 然后把记录路径改成只记录当前点的操作,把上次的位置记录下AC..不完整的人生啊 */ #include < ...
- Matplotlib_常用图表
Matplotlib绘图一般用于数据可视化 1.常用的图表有: 折线图(坐标系图) 散点图/气泡图 条形图/柱状图 饼图 直方图 箱线图 热力图 折线图(坐标系图) 折线图用于显示随时间或有序类别的变 ...
- 用vscode开发vue应用[转]
https://segmentfault.com/a/1190000019055976 现在用VSCode开发Vue.js应用几乎已经是前端的标配了,但很多时候我们看到的代码混乱不堪,作为一个前端工程 ...
- CPP-STL:STL备忘
STL备忘(转) 1. string.empty() 不是用来清空字符串,而是判断string是否为空,清空使用string.clear(); 2. string.find等查找的结果要和string ...
- Codeforces Round #272 (Div. 2)-A. Dreamoon and Stairs
http://codeforces.com/contest/476/problem/A A. Dreamoon and Stairs time limit per test 1 second memo ...
- 当数据量很少的时候,tableview会显示多余的cell--iOS开发系列---项目中成长的知识二
当数据量很少的时候,tableview会显示很多的cell,而且是空白的,这样很不美观 所以使用下面的方法可以去掉多余的底部的cell 原理是:设置footerView为frame 是 CGRectZ ...
- database---many to many relationships(多对多关系型数据库)
Many to many Relationships A many-to-many relationship occurs when multiple records in a table are a ...
- RuntimeError: Failed to init API, possibly an invalid tessdata path: E:\python36\报错
OCR:光学识别符,tesserocr是python中一个OCR识别库,是对tesseract做的一个python的 API封装,所以它的核心是tesseract 在这里我安装的版本是:tessera ...