零基础入门学习Python(30)--文件系统:介绍一个高大上的东西
知识点
在使用os模块,需要先进行import操作:
import osos模块中关于文件/目录常用的函数使用方法
| 函数名 | 函数作用 | 示例 |
|---|---|---|
getcwd() |
返回当前工作目录 | os.getcwd()============ ’D:\\untitled’ |
chdir(path) |
改变工作目录 | os.chdir('d:/python test')os.getcwd()============ ’d:\\python test’ |
listdir(path) |
列举当前目录中的文件名 | os.listdir()============ [‘hello world.py’] os.listdir('D:/360MoveData')============ [‘FileMove.ini’, ‘Users’] |
mkdir(path) |
创建单层目录,如该目录已存在则抛出异常 | os.mkdir('d:/testa')os.mkdir('d:/testa')============ Traceback (most recent call last):File "<input>", line 1, in <module>FileExistsError: [WinError 183] 当文件已存在时,无法创建该文件。: 'd:/testa' |
makedirs(path) |
递归创建多层目录,如该目录已存在抛出异常,注意:e:\\a\\b和e:\\a\\c并不会冲突 |
os.makedirs('d:/a/b/c')os.chdir('d:/a/b/c')os.getcwd()============ 'd:\\a\\b\\c' |
remove(path) |
删除文件,如果删除目录则抛出异常PermissionError: [WinError 5] 拒绝访问 |
os.remove('d:/a/1.txt') |
rmdir(path) |
删除单层目录,如果该目录非空则抛出异常OSError: [WinError 145] 目录不是空的。 |
os.rmdir('d:/a/b/c') |
removedirs(path) |
递归删除目录,从子目录到父目录逐层尝试删除,遇到目录非空则抛出异常OSError: [WinError 145] 目录不是空的。 |
os.removedirs('d:\\a\\b\\c') |
rename(old,new) |
将文件old重命名为new | os.rename('d:/someting.txt','d:/new.txt') |
system(command) |
调用系统命令 | os.system('cmd') |
walk(top) |
遍历top路径以下所有的子目录,返回一个三元组:(路劲,[包含目录],[包含文件]) | 示例见下 |
os.walk详细介绍:
概述:
os.walk() 方法用于通过在目录树中游走输出在目录中的文件名,向上或者向下。
os.walk() 方法是一个简单易用的文件、目录遍历器,可以帮助我们高效的处理文件、目录方面的事情。
语法:
os.walk(top[, topdown=True[, onerror=None[, followlinks=False]]])
参数:
top -- 根目录下的每一个文件夹(包含它自己), 产生3-元组 (dirpath, dirnames, filenames)
【文件夹路径, 文件夹名字, 文件名】。
topdown --可选,为True或者没有指定, 一个目录的的3-元组将比它的任何子文件夹的3-元组先产生 (目录自上而下)。
如果topdown为 False, 一个目录的3-元组将比它的任何子文件夹的3-元组后产生 (目录自下而上)。
onerror -- 可选,是一个函数; 它调用时有一个参数, 一个OSError实例。报告这错误后,继续walk,
或者抛出exception终止walk。
示例1:
import os
os.chdir('d://testfolder')
for i in os.walk(os.getcwd()):
print(i)
=====输出======
('d:\\testfolder', ['subfolder1', 'subfolder2'], ['record1 - 副本 (2).txt', 'record1 - 副本.txt', 'record1.txt'])
('d:\\testfolder\\subfolder1', ['subfolder3'], ['record2.txt'])
('d:\\testfolder\\subfolder1\\subfolder3', [], ['record3.txt'])
('d:\\testfolder\\subfolder2', [], ['ces.txt', 'new.txt', 'record.txt', 'someting2.txt'])
示例2:
>>> for root,dirs,files in os.walk('d:\\walk_test'):
for name in files:
print(os.path.join(root,name))
for name in dirs:
print(os.path.join(root,name))
d:\walk_test\a
d:\walk_test\b
d:\walk_test\c
d:\walk_test\a\a1
d:\walk_test\a\a2
d:\walk_test\a\a3
d:\walk_test\a\a1\a1.docx
d:\walk_test\a\a2\a2.docx
d:\walk_test\a\a3\a3.docx
d:\walk_test\b\b1
d:\walk_test\b\b2
d:\walk_test\b\b3
d:\walk_test\b\b1\b1.docx
d:\walk_test\b\b2\b2.docx
d:\walk_test\b\b3\b3.docx
d:\walk_test\c\c1
d:\walk_test\c\c2
d:\walk_test\c\c3
d:\walk_test\c\c1\c1.docx
d:\walk_test\c\c2\c2.docx
d:\walk_test\c\c3\c3.docx
>>> for root,dirs,files in os.walk('d:\\walk_test',topdown = False):
for name in files:
print(os.path.join(root,name))
for name in dirs:
print(os.path.join(root,name))
d:\walk_test\a\a1\a1.docx
d:\walk_test\a\a2\a2.docx
d:\walk_test\a\a3\a3.docx
d:\walk_test\a\a1
d:\walk_test\a\a2
d:\walk_test\a\a3
d:\walk_test\b\b1\b1.docx
d:\walk_test\b\b2\b2.docx
d:\walk_test\b\b3\b3.docx
d:\walk_test\b\b1
d:\walk_test\b\b2
d:\walk_test\b\b3
d:\walk_test\c\c1\c1.docx
d:\walk_test\c\c2\c2.docx
d:\walk_test\c\c3\c3.docx
d:\walk_test\c\c1
d:\walk_test\c\c2
d:\walk_test\c\c3
d:\walk_test\a
d:\walk_test\b
d:\walk_test\c | 函数名 | 函数作用 | 示例 |
|---|---|---|
| 以下是支持路劲操作中常用到的一些定义,支持所有平台 | ||
os.curdir |
指代当前目录. |
os.curdir’.’ |
os.pardir |
指代上一级目录.. |
os.getcwd()’D:\\untitled’ os.chdir(os.pardir)os.getcwd()’D:\\’ |
os.sep |
输出操作系统特定的路劲分隔符(Win下位\\,Linux下位/) |
os.sep’\\’ |
os.linesep |
当前平台使用的行终止符(Win下位\r\n,Linux下位\n) |
os.linesep’\r\n’ |
os.name |
指代当前使用的操作系统(包括posix nt mac os2 ce java) |
os.name’nt’ |
os.path模块中关于路径常用的函数使用方法
| 函数名 | 函数作用 | 示例 |
|---|---|---|
basename(path) |
去掉目录路径,单独返回文件名 | os.path.basename('D:\\Reboot\\01')’01’ os.path.basename('D:\\Reboot\\01\\hello world.py')’hello world.py’ |
dirname(path) |
去掉文件名,单独返回目录路劲 | os.path.dirname('D:\\Reboot\\01\\hello world.py')’D:\Reboot\01’ os.path.dirname('D:\\Reboot\\01')’D:\Reboot’ |
join(path1[,path2[,...]]) |
将path1,path2各部分组成合成一个路径名 | os.path.join('d:\\01','Reboot')’d:\01\Reboot’ |
split(path)) |
分割文件名与路劲,返回(f_path,f_name)元组。 如果完全使用目录,它也会将最后一个目录作为文件名分离,且不会判断文件或者目录是否存在 |
os.path.split('d:/Reboot/01')(‘d:/Reboot’, ‘01’) os.path.split('d:/Reboot/01/hello world.py')(‘d:/Reboot/01’, ‘hello world.py’) |
splitext(path)) |
分离文件名与扩展名,返回(f_name,f_extension)元组 | os.path.splitext('d:/Reboot/01')(‘d:/Reboot/01’, ”) os.path.splitext('d:/Reboot/01/hello world.py')(‘d:/Reboot/01/hello world’, ‘.py’) |
getsize(file)) |
返回指定文件的尺寸,单位是字节 | os.path.getsize('d:/Reboot/01/hello world.py')80 |
getatime(file)) |
返回指定文件最近的访问时间 (浮点型秒数,可用time模块的gmtime()或localtime()函数换算) |
import timetime.localtime(os.path.getatime('d:/Reboot/01/hello world.py'))time.struct_time(tm_year=2018, tm_mon=3, tm_mday=18, tm_hour=11, tm_min=12, tm_sec=1, tm_wday=6, tm_yday=77, tm_isdst=0) |
getctime(file)) |
返回指定文件创建时间 (浮点型秒数,可用time模块的gmtime()或localtime()函数换算) |
time.localtime(os.path.getctime('d:/Reboot/01/hello world.py'))time.struct_time(tm_year=2018, tm_mon=3, tm_mday=18, tm_hour=11, tm_min=12, tm_sec=1, tm_wday=6, tm_yday=77, tm_isdst=0) |
getmtime(file) |
返回指定文件最近的修改时间 (浮点型秒数,可用time模块的gmtime()或localtime()函数换算) |
time.localtime(os.path.getmtime('d:/Reboot/01/hello world.py'))time.struct_time(tm_year=2018, tm_mon=5, tm_mday=10, tm_hour=14, tm_min=21, tm_sec=13, tm_wday=3, tm_yday=130, tm_isdst=0) |
| 以下为函数返回True或False | ||
exists(path) |
判断指定路径(目录或文件)是否存在 | os.path.exists('d:/Reboot/01')True os.path.exists('d:/Reboot/02')False |
isabs(path) |
判断指定路劲是否为绝对路径 | os.path.isabs('Reboot')False os.path.isabs('d:/Reboot')True |
isdir(path) |
判断指定路劲是否存在且是一个目录 | os.path.isdir('Reboot/01')True os.path.isdir('d:/Reboot/01/hello world.py')False |
isfile(path) |
判断指定路劲是否存在且是一个文件 | os.path.isfile('d:/Reboot/01/hello world.py')True os.path.isfile('d:/Reboot/01/hello world.py1')False |
islink(path) |
判断指定路劲是否存在且是一个符号链接 | os.path.islink('d:/Reboot/01')False |
ismount(path) |
判断指定路劲是否存在且是一个挂载点 | os.path.ismount('d:/')True os.path.ismount('d:/Reboot')False |
samefile(path1,path2) |
判断path1和path2两个路劲是否指向同一个文件 | os.path.samefile('Reboot/01','d:/Reboot/01')True |
课后习题
动动手
- 编写一个程序,统计当前目录下每个文件类型的文件数,程序实现如图:
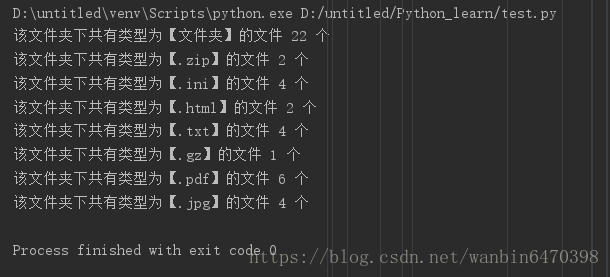
import os
file_type = dict()
count = 0
#os.chdir('d:/')
all_files = os.listdir(os.curdir)
for each_file in all_files:
if os.path.isdir(each_file):
file_type.setdefault('文件夹',0)
file_type['文件夹'] += 1
else:
ext = os.path.splitext(each_file)[1]
file_type.setdefault(ext,0)
file_type[ext] += 1
for type_file in file_type:
print('该文件夹下共有类型为【%s】的文件 %d 个' % (type_file,file_type[type_file]))- 编写一个程序,计算当前文件夹下所有文件的大小,程序实现如图:
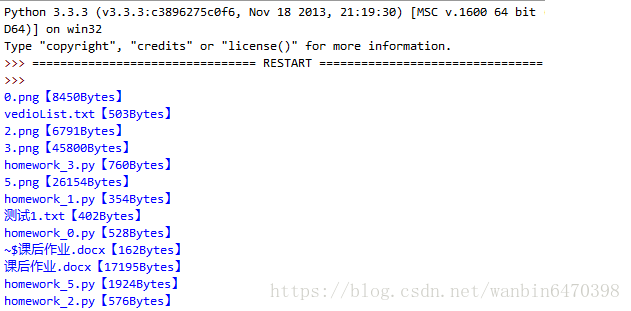
import os
file_type = dict()
count = 0
#os.chdir('d:/')
all_files = os.listdir(os.curdir)
for each_file in all_files:
if os.path.isfile(each_file):
file_type.setdefault(each_file,os.path.getsize(each_file))
for get_size in file_type:
print('文件 %s【%d Bytes】' % (get_size,file_type[get_size]))- 编写一个程序,用户输入文件名以及开始搜索的路劲,搜索该文件是否存在。如遇到文件夹,则进入文件夹继续搜索,程序实现如图:
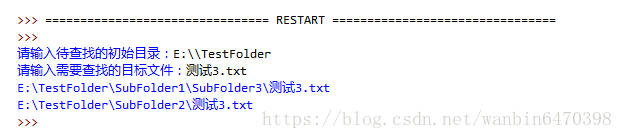
#编写一个程序,用户输入文件名以及开始搜索的路劲,搜索该文件是否存在。
#如遇到文件夹,则进入文件夹继续搜索
import os
def search_file(start_dir,target):
os.chdir(start_dir) #进入指定目录
for each_file in os.listdir(os.curdir): #在当前目录进行遍历
if each_file == target:
print(os.getcwd() + os.sep + each_file) #输出文件目录
if os.path.isdir(each_file):
search_file(each_file,target) #递归调用,进入子目录进行查找
os.chdir(os.pardir) #递归调用后切记返回上一层目录
start_dir = input('请输入待查找的初始目录:')
target = input('请输入需要查找的目标文件:')
search_file(start_dir,target)- 编写一个程序,用户输入开始搜索的路劲,查找该路劲下(包含子文件夹内)所有的视频格式文件(要求查找
MP4rmvbavi的格式即可 ),并创建一个文件vedioList.txt存放所有找到的文件的路劲,程序实现如图:
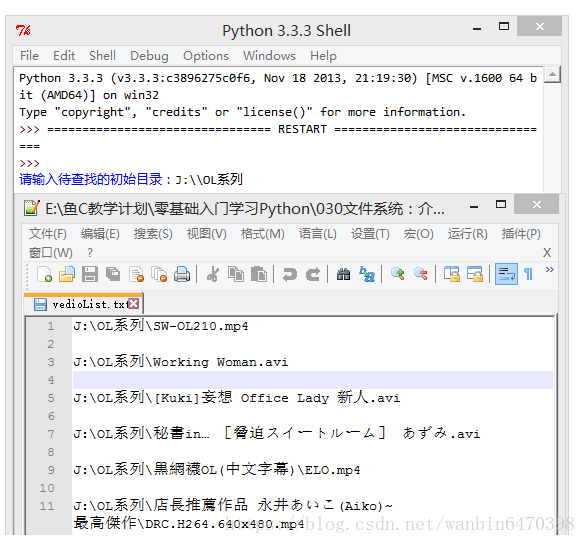
target = ['.mp4','.avi','.rmvb','.mkv','.torrent']
vedio_list = []
import os
def serach_file(start_dir,target):
os.chdir(start_dir)
for each_file in os.listdir(os.curdir):
ext = os.path.splitext(each_file)[1]
if ext in target:
vedio_list.append(os.getcwd() + os.sep +each_file + os.linesep)
if os.path.isdir(each_file):
serach_file(each_file,target)
os.chdir(os.pardir)
start_dir = input('请输入需要查找的目录:')
program_dir = os.getcwd()
serach_file(start_dir,target)
f = open(program_dir + os.sep + 'vedioList.txt','w')
f.writelines(vedio_list)
f.close()- 编写一个程序,用户输入关键字,查找当前文件夹内(如果当前文件夹内包含文件夹,则进入文件夹继续搜索)所有含有该关键字的文本文件
.txt后缀,要求显示该文件所在的位置以及关键字在文件中的具体位置第几行第几个字符,程序实现如图:
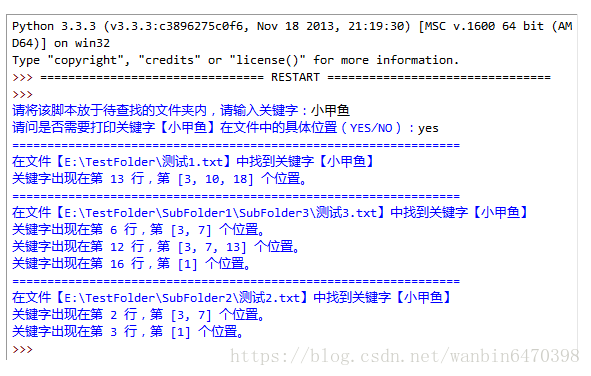
import os
def print_pos(key_dict):
keys = key_dict.keys()
keys = sorted(keys) # 由于字典是无序的,我们这里对行数进行排序
for each_key in keys:
print('关键字出现在第 %s 行,第 %s 个位置。' % (each_key, str(key_dict[each_key])))
def pos_in_line(line, key):
pos = []
begin = line.find(key)
while begin != -1:
pos.append(begin + 1) # 用户的角度是从1开始数
begin = line.find(key, begin+1) # 从下一个位置继续查找
return pos
def search_in_file(file_name, key):
f = open(file_name)
count = 0 # 记录行数
key_dict = dict() # 字典,用户存放key所在具体行数对应具体位置
for each_line in f:
count += 1
if key in each_line:
pos = pos_in_line(each_line, key) # key在每行对应的位置
key_dict[count] = pos
f.close()
return key_dict
def search_files(key, detail):
all_files = os.walk(os.getcwd())
txt_files = []
for i in all_files:
for each_file in i[2]:
if os.path.splitext(each_file)[1] == '.txt': # 根据后缀判断是否文本文件
each_file = os.path.join(i[0], each_file)
txt_files.append(each_file)
for each_txt_file in txt_files:
key_dict = search_in_file(each_txt_file, key)
if key_dict:
print('================================================================')
print('在文件【%s】中找到关键字【%s】' % (each_txt_file, key))
if detail in ['YES', 'Yes', 'yes']:
print_pos(key_dict)
key = input('请将该脚本放于待查找的文件夹内,请输入关键字:')
detail = input('请问是否需要打印关键字【%s】在文件中的具体位置(YES/NO):' % key)
search_files(key, detail)
零基础入门学习Python(30)--文件系统:介绍一个高大上的东西的更多相关文章
- 【零基础入门学习Python笔记012】一个打了激素的数组3
列表的一些经常使用操作符 比較操作符 逻辑操作符 连接操作符 反复操作符 成员关系操作符 +表示两个连接.*表示复制. list中"+"两边的类型必须一致. 演示样例: water ...
- 文件系统:介绍一个高大上的东西 - 零基础入门学习Python030
文件系统:介绍一个高大上的东西 让编程改变世界 Change the world by program 接下来我们会介绍跟Python的文件相关的一些十分有用的模块.模块是什么?不知大家对以下代码还有 ...
- 【Python教程】《零基础入门学习Python》(小甲鱼)
[Python教程]<零基础入门学习Python>(小甲鱼) 讲解通俗易懂,诙谐. 哈哈哈. https://www.bilibili.com/video/av27789609
- 《零基础入门学习Python》【第一版】视频课后答案第001讲
测试题答案: 0. Python 是什么类型的语言? Python是脚本语言 脚本语言(Scripting language)是电脑编程语言,因此也能让开发者藉以编写出让电脑听命行事的程序.以简单的方 ...
- 零基础入门学习Python(1)--我和Python的第一次亲密接触
前言 最近在学习Python编程语言,于是乎就在网上找资源.其中小甲鱼<零基础入门学习Python>试听了几节课,感觉还挺不错,里面的视频都是免费下载,小甲鱼讲话也挺幽默风趣的,所以呢,就 ...
- 学习参考《零基础入门学习Python》电子书PDF+笔记+课后题及答案
国内编写的关于python入门的书,初学者可以看看. 参考: <零基础入门学习Python>电子书PDF+笔记+课后题及答案 Python3入门必备; 小甲鱼手把手教授Python; 包含 ...
- 学习《零基础入门学习Python》电子书PDF+笔记+课后题及答案
初学python入门建议学习<零基础入门学习Python>.适合新手入门,很简单很易懂.前一半将语法,后一半讲了实际的应用. Python3入门必备,小甲鱼手把手教授Python,包含电子 ...
- 零基础入门学习Python(36)--类和对象:给大家介绍对象
知识点 Python3 面向对象 Python从设计之初就已经是一门面向对象的语言,正因为如此,在Python中创建一个类和对象是很容易的.本章节我们将详细介绍Python的面向对象编程. 如果你以前 ...
- 零基础入门学习Python(17)--函数:Python的乐高积木
前言 相信大家小时候都玩过神奇的乐高积木, 只要通过想象力和创造力我们可以拼凑很多神奇的东西,那么随着我们学习的深入,我们编写的Python代码也将日益增加,并且也越来越复杂, 所以呢,我们需要找寻一 ...
- 零基础入门学习Python(11)--列表:一个打了激素的数组(2)
前言 上节课我们介绍一个打了激素的数组,叫做列表.列表我们比作一个大仓库,你所能够具现化的东西,都可以往里面扔,它包罗万象.另外还介绍了三个往列表添加元素的方法,分别是: append(),exten ...
随机推荐
- Ubuntu 18.04 关闭蓝牙开机启动
sudo gedit /etc/rc.local 然后,加入下面一行 rfkill block bluetooth
- UTF-8格式的文本文件程序读取异常
最近在windows服务器上直接创建并手打输入配置参数,比如设置概率0.6,然后用java程序打开读取该参数,在本地linux环境下测试完全正常,但是一放到服务器上,就报NotNumber错误,查看了 ...
- django views视图函数
Django views.py视图文件 一. 创建views.py文件,在工程文件夹根目录创建views.py视图文件,其实任意文件名都可以,使用views是为了遵循传统. 注:所有的views函数都 ...
- JDK常用类解读--String
一.字符串的不变性: 文章使用的源码是jdk1.8的.(下同) 1.首先可以看到`String`是`final`类,说明该类不可继承,保证不会被子类改变语义 2.String的值实际上就是一个字符数组 ...
- iOS-UI控件之UIImageView
contentMode属性 带有scale单词的:图片有可能会拉伸 UIViewContentModeScaleToFill 将图片拉伸至填充整个imageView 图片显示的尺寸跟imageView ...
- iTOP-4412开发板全新升级支持4G全网通模块
开发板支持4G,GPS,CAN,485,WIFI蓝牙,重力加速度计,陀螺仪等模块. 核心板参数 尺寸:6cm*7cm 高度:连同连接器在内0.26cm CPU:Exynos4412,四核Cortex- ...
- leetcode_650. 2 Keys Keyboard_dp
https://leetcode.com/problems/2-keys-keyboard/ 初始一个A,两种操作,复制当前所有A,粘贴,问得到n个A最少需要多少步操作. class Solution ...
- vue2.0学习——使用webstorm创建一个vue项目
https://blog.csdn.net/weixin_40877388/article/details/80911934
- WNDCLASS和WNDCLASSEX
typedef struct { UINT cbSize; UINT style; WNDPROC lpfnWndProc; int cbClsExtra; int cbWndExtra; HINST ...
- CAD参数绘制块引用对象(com接口)
主要用到函数说明: _DMxDrawX::DrawBlockReference 绘制块引用对象.详细说明如下: 参数 说明 DOUBLE dPosX 插入点的X坐标 DOUBLE dPosY 插入点的 ...