day1--大数据概念,hadoop介绍,hdfs整体运行机制
1、什么是大数据
基本概念
在互联网技术发展到现今阶段,大量日常、工作等事务产生的数据都已经信息化,人类产生的数据量相比以前有了爆炸式的增长,以前的传统的数据处理技术已经无法胜任,需求催生技术,一套用来处理海量数据的软件工具应运而生,这就是大数据!
换个角度说,大数据是:
1、有海量的数据
2、有对海量数据进行挖掘的需求
3、有对海量数据进行挖掘的软件工具(hadoop、spark、storm、flink、tez、impala......)
大数据在现实生活中的具体应用
电商推荐系统:基于海量的浏览行为、购物行为数据,进行大量的算法模型的运算,得出各类推荐结论,以供电商网站页面来为用户进行商品推荐
精准广告推送系统:基于海量的互联网用户的各类数据,统计分析,进行用户画像(得到用户的各种属性标签),然后可以为广告主进行有针对性的精准的广告投放
2、什么是hadoop
hadoop中有3个核心组件:
分布式文件系统:HDFS —— 实现将文件分布式存储在很多的服务器上
分布式运算编程框架:MAPREDUCE —— 实现在很多机器上分布式并行运算
分布式资源调度平台:YARN —— 帮用户调度大量的mapreduce程序,并合理分配运算资源
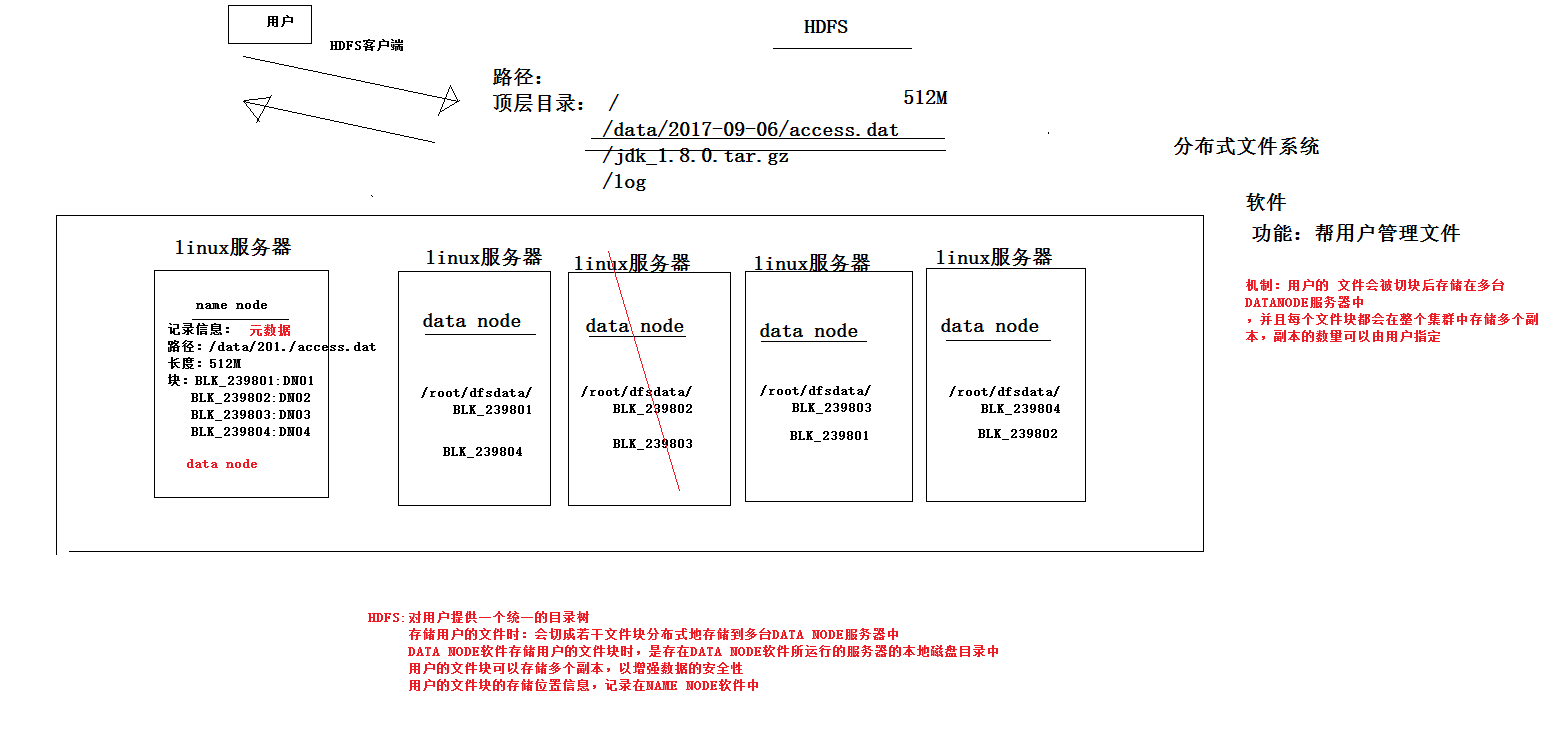
3、hdfs整体运行机制
hdfs:分布式文件系统
hdfs有着文件系统共同的特征:
1、有目录结构,顶层目录是: /
2、系统中存放的就是文件
3、系统可以提供对文件的:创建、删除、修改、查看、移动等功能
hdfs跟普通的单机文件系统有区别:
1、单机文件系统中存放的文件,是在一台机器的操作系统中
2、hdfs的文件系统会横跨N多的机器
3、单机文件系统中存放的文件,是在一台机器的磁盘上
4、hdfs文件系统中存放的文件,是落在n多机器的本地单机文件系统中(hdfs是一个基于linux本地文件系统之上的文件系统)
hdfs的工作机制:
1、客户把一个文件存入hdfs,其实hdfs会把这个文件切块后,分散存储在N台linux机器系统中(负责存储文件块的角色:data node)<准确来说:切块的行为是由客户端决定的>
2、一旦文件被切块存储,那么,hdfs中就必须有一个机制,来记录用户的每一个文件的切块信息,及每一块的具体存储机器(负责记录块信息的角色是:name node)
3、为了保证数据的安全性,hdfs可以将每一个文件块在集群中存放多个副本(到底存几个副本,是由当时存入该文件的客户端指定的)
综述:一个hdfs系统,由一台运行了namenode的服务器,和N台运行了datanode的服务器组成!

day1--大数据概念,hadoop介绍,hdfs整体运行机制的更多相关文章
- 大数据笔记04:大数据之Hadoop的HDFS(基本概念)
1.HDFS是什么? Hadoop分布式文件系统(HDFS),被设计成适合运行在通用硬件(commodity hardware)上的分布式文件系统.它和现有的分布式文件系统有很多共同点. 2.HDFS ...
- 大数据:Hadoop(HDFS 的设计思路、设计目标、架构、副本机制、副本存放策略)
一.HDFS 的设计思路 1)思路 切分数据,并进行多副本存储: 2)如果文件只以多副本进行存储,而不进行切分,会有什么问题 缺点 不管文件多大,都存储在一个节点上,在进行数据处理的时候很难进行并行处 ...
- 大数据笔记07:大数据之Hadoop的HDFS(特点)
1. HDFS的特点: (1)数据冗余,硬件容错 (2)流式的数据访问(写一次读多次,不能直接修改已写入的数据,只能删除之后再去写入) (3)存储大文件 2. HDFS适用性和局限性 适用性:(1)适 ...
- 大数据:Hadoop(HDFS 读写数据流程及优缺点)
一.HDFS 写数据流程 写的过程: CLIENT(客户端):用来发起读写请求,并拆分文件成多个 Block: NAMENODE:全局的协调和把控所有的请求,提供 Block 存放在 DataNode ...
- 大数据笔记05:大数据之Hadoop的HDFS(数据管理策略)
HDFS中数据管理与容错 1.数据块的放置 每个数据块3个副本,就像上面的数据库A一样,这是因为数据在传输过程中任何一个节点都有可能出现故障(没有办法,廉价机器就是这样的) ...
- 大数据笔记06:大数据之Hadoop的HDFS(文件的读写操作)
1. 首先我们看一看文件读取: (1)客户端(java程序.命令行等等)向NameNode发送文件读取请求,请求中包含文件名和文件路径,让NameNode查询元数据. (2)接着,NameNode返回 ...
- 大数据笔记09:大数据之Hadoop的HDFS使用
1. HDFS使用: HDFS内部中提供了Shell接口,所以我们可以以命令行的形式操作HDFS
- 大数据学习之路-hdfs
1.什么是hadoop hadoop中有3个核心组件: 分布式文件系统:HDFS —— 实现将文件分布式存储在很多的服务器上 分布式运算编程框架:MAPREDUCE —— 实现在很多机器上分布式并行运 ...
- 大数据和Hadoop平台介绍
大数据和Hadoop平台介绍 定义 大数据是指其大小和复杂性无法通过现有常用的工具软件,以合理的成本,在可接受的时限内对其进行捕获.管理和处理的数据集.这些困难包括数据的收入.存储.搜索.共享.分析和 ...
随机推荐
- mfc 菜单
创建一个基于对话框的工程,工程名为CreateMenu 为该对话框增加一个文件菜单项和测试菜单项,如下图所示 测试菜单项至少要有一个子菜单项 在对话框属性中关联该菜单 在resource.h中增加 ...
- OpenCV2:应用篇 QT+OpenCV实现图片编辑器
一.简介 做完会放在Github上
- 面试之Linux
Linux的体系结构 体系结构主要分为用户态(用户上层活动)和内核态 内核:本质是一段管理计算机硬件设备的程序 系统调用:内核的访问接口,是一种不能再简化的操作 公用函数库:系统调用的组合拳 Shel ...
- eclipse修改xml文件默认的打开方式为XML Editor
1.菜单:Window -> Preferences -> General -> Editors -> File Associations ...
- 【MSSQL】MDF、NDF、LDF文件的含义
[MSSQL]MDF.NDF.LDF文件的含义 2012-09-03 15:32:56| 分类: SQL数据库|举报|字号 订阅 MDF是 primary data file 的缩写:NDF ...
- zeng studio的项目窗口PHP Explorer
恢复zeng studio的项目窗口PHP Explorer方法: Windows>show view >PHP Explorer
- oracle调用存储过程和函数返回结果集
在程序开发中,常用到返回结果集的存储过程,这个在mysql和sql server 里比较好处理,直接返回查询结果就可以了,但在oracle里面 要 out 出去,就多了一个步骤,对于不熟悉的兄弟们还得 ...
- 诊断:MRP0: Background Media Recovery terminated with error 1111
表现: 灾备环境,无法继续应用日志. 日志: MRP0: Background Media Recovery terminated with error 1111 Fri Jan 18 15:55:2 ...
- CentO7-使用plantuml绘制UML类图
准备工作 到PlantUml官网(http://plantuml.com/download)下载plantuml.jar.官网上还有一个在线的demof服务.plantuml的官网真的很挫! 到官网下 ...
- [bzoj2806][Ctsc2012]Cheat(后缀自动机(SAM)+二分答案+单调队列优化dp)
偷懒直接把bzoj的网页内容ctrlcv过来了 2806: [Ctsc2012]Cheat Time Limit: 20 Sec Memory Limit: 256 MBSubmit: 1943 ...