对于文本生成类4种评价指标的的计算BLEU METEOR ROUGE CIDEr
一、指标概述
这四种指标都是机器翻译的自动评价指标,对于一些生成式文本任务,也是使用这几种评价指标。
二、Bleu原理详解
BLEU是IBM于2002年提出的。我们假定人工给出的译文为reference,机器翻译的译文为candidate。
1.最早的BLEU算法
最早的BLEU算法是直接统计cadinate中的单词有多少个出现在reference中,具体的式子是:
$BLEU=\frac{出现在reference中的candinate的单词的个数}{cadinate中单词的总数}$
以下面例子为例:
candinate:the the the the the the the
reference:the cat is on the mat
cadinate中所有的单词都在reference中出现过,因此:
$BLEU=\frac{7}{7}=1$
对上面的结果显然是不合理的,而且主要是分子的统计不合理,因此对上面式子中的分子进行了改进。
2.改进的BLEU算法
针对上面不合理的结果,对分子的计算进行了改进,具体的公式变为如下:
$BLEU=\frac{Count^{clip}_{w_i}}{cadinate中单词的总数}$
$Count^{clip}_{w_i}=min(Count_{w_i},Ref-Count_{w_i})$
上面式子中:
$Count_{w_i}$ 表示单词$w_i$在candinate中出现的次数;
$Ref-Count_{w_i}$ 表示单词$w_i$在reference中出现的次数;
但一般情况下reference可能会有多个j句子,因此有:
$Count^{clip}=max(Count^{clip}_{w_i,j}),j=1,2,3......$
上面式子中:j表示第j个reference。
仍然以上面的例子为例,在candinate中只有一个单词the,因此只要计算一个$Count^{clip}$,the在reference中只出现了两次,因此:
$BLEU=\frac{2}{7}$
3.引入n-gram
在上面我们一直都是对于单个单词进行计算,单个单词可以看作时1−gram,1−gram可以描述翻译的充分性,即逐字翻译的能力,但不能关注翻译的流畅性,因此引入了n−gram,在这里一般n不大于4。引入n−gram后的表达式如下:
$p_n=\frac{\sum_{c\in candidates}\sum_{n-gram\in c}Count_{clip}(n-gram)}{\sum_{{c}'\in candidates}\sum_{{n-gram}'\in {c}'}Count({n-gram}')}$
很多时候在评价一个系统时会用多条candinate来评价,因此上面式子中引入了一个候选集合candinates。$p_n$中的n表示n-gram,$p_n$表示n-gram的精度,即1−gram时,n=1。
接下来简单的理解下上面的式子,首先来看分子:
1)第一个$\sum$描述的是各个candinate的总和,就是有多个句子
2)第二个$\sum$描述的是一条candinate中所有的n−gram的总和,就是一个句子的n-gram的个数
3)$Count_{clip}(n-gram)$表示某一个n−gram词的截断计数;
再来看分母,前两个$\sum$和分子中的含义一样,Count({n-gram}')表示n−gram′在candinate中的计数。
再进一步来看,实际上分母就是candinate中n−gram的个数,分子是出现在reference中的candinate中n−gram的个数。
举一个例子来看看实际的计算:
candinate: the cat sat on the mat
reference:the cat is on the mat
计算n−gram的精度:
$p1=\frac{5}{6}=0.83333$
$p2=\frac{3}{5}=0.6$
$p3=\frac{1}{4}=0.25$
$p4=\frac{0}{3}=0$
4.添加对句子长度的乘法因子
在翻译时,若出现译文很短的句子时往往会有较高的BLEU值,因此引入对句子长度的乘法因子,其表达式如下:
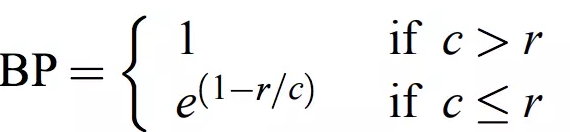
在这里c表示cadinate的长度,r表示reference的长度。
将上面的整合在一起,得到最终的表达式:
$BLEU=BPexp(\sum^N_{n=1}w_n logp_n)$
其中$exp(\sum^N_{n=1}w_n logp_n)$表示不同的n−gram的精度的对数的加权和。
三、具体实现
github下载链接:https://github.com/Maluuba/nlg-eval
将下载的文件放到工程目录,而后使用如下代码计算结果
具体的写作格式如下:
from nlgeval import NLGEval
nlgeval=NLGEval()
#对应的模型生成的句子有三句话,每句话的的标准有两句话
hyp=['this is the model generated sentence1 which seems good enough','this is sentence2 which has been generated by your model','this is sentence3 which has been generated by your model']
ref1=['this is one reference sentence for sentence1','this is a reference sentence for sentence2 which was generated by your model','this is a reference sentence for sentence3 which was generated by your model']
ref2=['this is one more reference sentence for sentence1','this is the second reference sentence for sentence2','this is a reference sentence for sentence3 which was generated by your model']
lis=[ref1,ref2]
ans=nlgeval.compute_metrics(hyp_list=hyp,ref_list=lis)
# res=compute_metrics(hypothesis='nlg-eval-master/examples/hyp.txt',
# references=['nlg-eval-master/examples/ref1.txt','nlg-eval-master/examples/ref2.txt'])
print(ans)
输出结果如下:
{'Bleu_2': 0.5079613089004589, 'Bleu_3': 0.35035098185199764, 'Bleu_1': 0.6333333333122222, 'Bleu_4': 0.25297649984340986, 'ROUGE_L': 0.5746244363308142, 'CIDEr': 1.496565428735557, 'METEOR': 0.3311277692098822}
参考链接:https://www.cnblogs.com/jiangxinyang/p/10523585.html
对于文本生成类4种评价指标的的计算BLEU METEOR ROUGE CIDEr的更多相关文章
- Texygen文本生成,交大计算机系14级的朱耀明
文本生成哪家强?上交大提出基准测试新平台 Texygen 2018-02-12 13:11测评 新智元报道 来源:arxiv 编译:Marvin [新智元导读]上海交通大学.伦敦大学学院朱耀明, 卢思 ...
- 斯坦福NLP课程 | 第15讲 - NLP文本生成任务
作者:韩信子@ShowMeAI,路遥@ShowMeAI,奇异果@ShowMeAI 教程地址:http://www.showmeai.tech/tutorials/36 本文地址:http://www. ...
- dagger2系列之生成类实例
上一节的最后,我讲到一次注入生成类实例的生成步骤.先来回顾一下: 1 Module中存在创建方法,则看此创建方法有没有参数 如果有参数,这些参数也是由Component提供的,返回步骤1逐一生成参数 ...
- 用Enterprise Architect从源码自动生成类图
http://blog.csdn.net/zhouyong0/article/details/8281192 /*references:感谢资源分享者.info:简单记录如何通过工具从源码生成类图,便 ...
- 使用 paddle来进行文本生成
paddle 简单介绍 paddle 是百度在2016年9月份开源的深度学习框架. 就我最近体验的感受来说的它具有几大优点: 1. 本身内嵌了许多和实际业务非常贴近的模型比如个性化推荐,情感分析,词向 ...
- IDEA设置生成类基本注释信息
在eclipse中我们按一下快捷键就会生成类的基本信息相关的注释,其实在IDEA中也是可以的,需要我们手动设置,之后再创建类的时候就会自动加上这些基本的信息. File-->Setting 在E ...
- Java中String类两种实例化的区别(转)
原文:http://blog.csdn.net/wangdajiao/article/details/52087302 一.String类的第一种方式 1.直接赋值 例:String str = &q ...
- Android(java)学习笔记106:Android设置文本颜色的4种方法
1. Android设置文本颜色的4种方法: (1)利用系统自带的颜色类: tv.setTextColor(android.graphics.Color.RED); (2)数字颜色表示: tv.set ...
- 信息收集渠道:文本分享类网站Paste Site
信息收集渠道:文本分享类网站Paste Site Paste Site是一种专门的文本分享的网站.用户可以将一段文本性质的内容(如代码)上传到网站,然后通过链接分享给其他用户.这一点很类似于现在的优酷 ...
随机推荐
- 【React】393 深入了解React 渲染原理及性能优化
如今的前端,框架横行,出去面试问到框架是常有的事. 我比较常用React, 这里就写了一篇 React 基础原理的内容, 面试基本上也就问这些, 分享给大家. React 是什么 React是一个专注 ...
- Nginx(二)--nginx的核心功能
反向代理 nginx反向代理的指令不需要新增额外的模块,默认自带proxy_pass指令,只需要修改配置文件就可以实现反向代理. proxy_pass 既可以是ip地址,也可以是域名,同时还可以指定端 ...
- AI行业精选日报_人工智能(12·20)
IDC:中国智能家居市场2020年十大预测 12 月 20 日消息,「IDC 咨询」官方公众号发布「中国智能家居 2020 年十大预测」.具体内容如下:互联平台加速整合.语音助手广泛赋能.智能电视显著 ...
- Java并发之synchronized关键字深度解析(三)
前言 本篇主要介绍一下synchronized的批量重偏向和批量撤销机制,属于深水区,大家提前备好氧气瓶. 上一篇说完synchronized锁的膨胀过程,下面我们再延伸一下synchronized锁 ...
- Glide只播放一次Gif以及监听播放完成的实现方案
需求: 近段时间正好有一个需求,是要实现Gif图只加载播放一次,并且要在Gif播放完毕后回调给系统的需求. 因为Glide 3系列的API与4系列还是有很大差距的,这里我们针对Glide 3.x和Gl ...
- Sqlite—修改语句(Update)
SQLite 的 UPDATE 语句用于修改表中已有的记录.可以使用带有 WHERE 子句的 UPDATE 查询来更新选定行,否则所有的行都会被更新. 基本语法:UPDATE table_name S ...
- Hive 性能测试工具 hive-testbench
下载: yum -y install gcc gcc-c++ maven 下载地址Github:https://github.com/hortonworks/hive-testbench/git cl ...
- 激光炸弹 HYSBZ - 1218
激光炸弹 HYSBZ - 1218 Time limit:10000 ms Memory limit:165888 kB OS:Linux Source:HNOI2003 一种新型的激光炸弹,可以摧毁 ...
- Java面向对象之继承(一)
目录 Java面向对象之继承 引言 继承的特点 语法格式 父子类的关系 继承要点 重写父类方法 继承中的构造器 继承中的super关键字 ... Java面向对象之继承 继承是面向对象的第二大特征,是 ...
- Java 操作Word书签(三):用文本、图片、表格替换书签
本篇文章将继续介绍通过Java来操作Word书签的方法,即替换Word中已有书签,包括用新的文本.图片.表格等替换原有书签处的内容. 使用工具:Free Spire.Doc for Java (免费版 ...