骚操作!曾经爱过!用 Python 清理收藏夹里已失效的网站
前言
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理。
作者: 小詹&有乔木
PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行获取
http://note.youdao.com/noteshare?id=3054cce4add8a909e784ad934f956cef
失效的书签们
我们日常浏览网站的时候,时不时会遇到些新奇的东西( 你懂的.jpg ),于是我们就默默的点了个收藏或者加书签。然而当我们面对成百上千的书签和收藏夹的时候,总会头疼不已…… 
尤其是昨天还在更新的程序设计博客,今天就挂了永不更新。或者是昨天看的起劲的电影网站,今天直接404。失效页面这么多,每次我打开才知道失效了,并且需要手动删除,这能是一个程序员干的事情吗?
可是无论是Google浏览器还是国内浏览器,最多也就提供一个对于收藏夹的备份服务,那只能Python走起了。
Python支持的收藏夹文件格式
对于收藏夹提供的支持很少,主要还是因为收藏夹藏在浏览器里面,我们只能手动导出htm文件进行管理

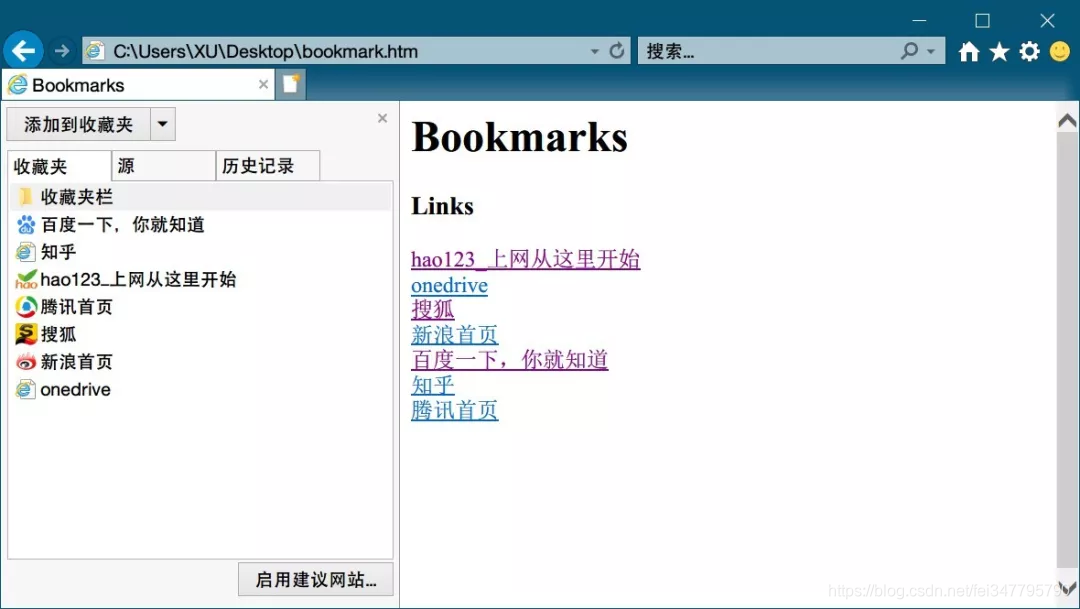
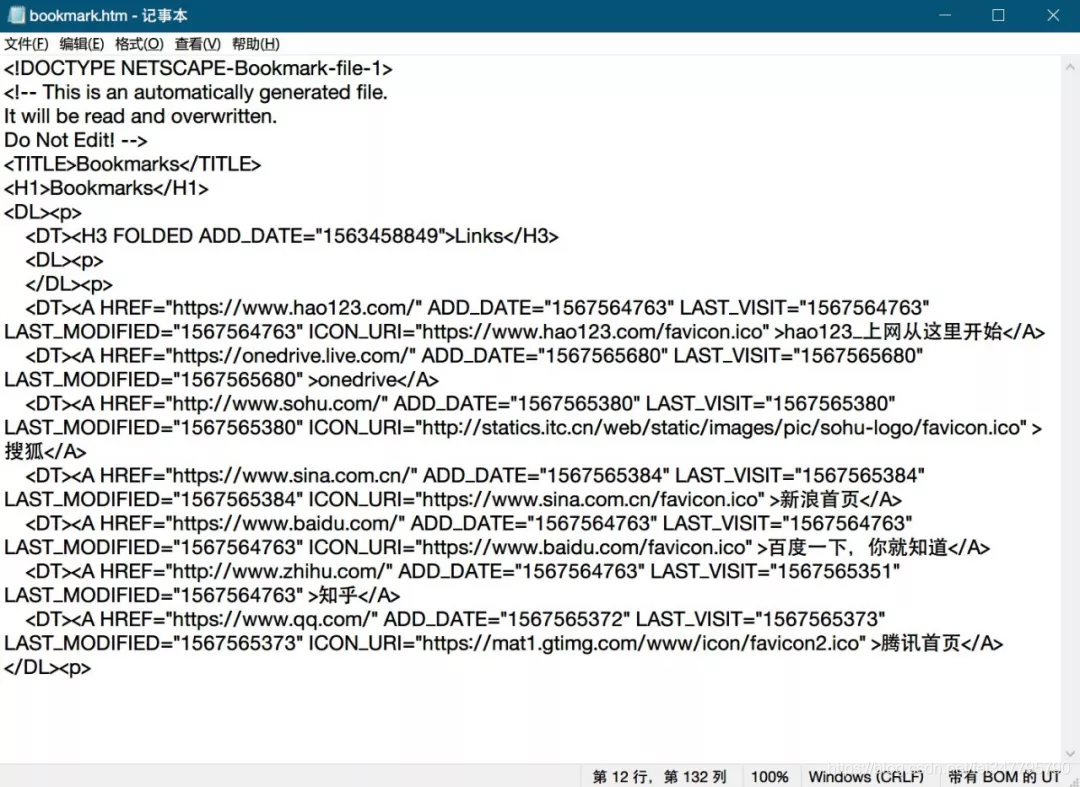
内容比较简单,对前端没什么了解的我,也可以很明显看出其中的树形结构和内在逻辑。 固定格式 网址 固定格式 页面名 固定格式
很简单的想到了正则匹配,其中有两个子串。提取出来再挨个访问,看看哪个失效了,就删除,就能获得清理后的收藏夹了。
读取收藏夹文件
path = "C:\\Users\\XU\\Desktop"
fname = "bookmarks.html"
os.chdir(path)
bookmarks_f = open(fname, "r+" ,encoding='UTF-8')
booklists = bookmarks_f.readlines()
bookmarks_f.close()
因为对于前端的不熟悉,这个导出的收藏夹可以抽象的分
结构代码
保存网页书签的关键代码
其中结构代码我们不能动,要原封不动的保留,而保存网页书签的关键代码,我们要提取内容并且进行判断保留和删除。
所以这里采用readlines函数,每行读取,单独判断。
正则匹配
pattern = r'HREF="(.*?)" .*?>(.*?)</A>'
while len(booklists)>0:
bookmark = booklists.pop(0)
detail = re.search(pattern, bookmark)
如果是关键代码:提取出的子串在 detail.group(1) 和 detail.group(2) 里面
而如果是结构代码:detail == None
访问页面
import requests
r = requests.get(detail.group(1),timeout=500)
编代码尝试之后发现会有这四种情况
r.status_code == requests.codes.ok
r.status_code==404
r.status_code!=404 && 无法访问 (可能是屏蔽爬虫,建议保留)
requests.exceptions.ConnectionError
类似知乎、简书基本都反爬了,所以简单的get还不能有效访问,细节不值得大费周章,直接保留就好。而error,直接用try抛出异常就好,不然程序会停止运行。
添加逻辑后:(代码可左右拖动)
while len(booklists)>0:
bookmark = booklists.pop(0)
detail = re.search(pattern, bookmark)
if detail:
#print(detail.group(1) +"----"+ detail.group(2))
try:
#访问
r = requests.get(detail.group(1),timeout=500)
#如果可则添加
if r.status_code == requests.codes.ok:
new_lists.append(bookmark)
print( "ok------ 保留:"+ detail.group(1)+" "+ detail.group(2))
else:
if(r.status_code==404):
print("不可访问 删除:"+ detail.group(1)+" "+ detail.group(2) +'错误码 '+str(r.status_code))
else:
print("其他原因 保留:"+ detail.group(1)+" "+ detail.group(2) +'错误码 '+str(r.status_code))
new_lists.append(bookmark)
except:
print( "不可访问 删除:"+ detail.group(1)+" "+ detail.group(2))
#new_lists.append(bookmark)
else:#没匹配到是结构语句
new_lists.append(bookmark)
程序执行情况
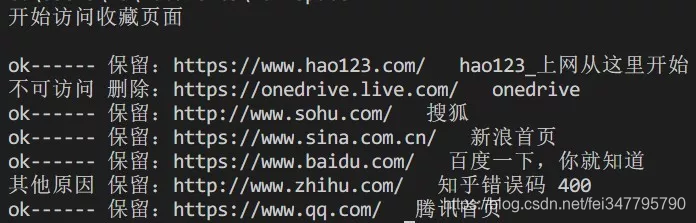
导出htm
bookmarks_f = open('new_'+fname, "w+" ,encoding='UTF-8')
bookmarks_f.writelines(new_lists)
bookmarks_f.close()
导入浏览器
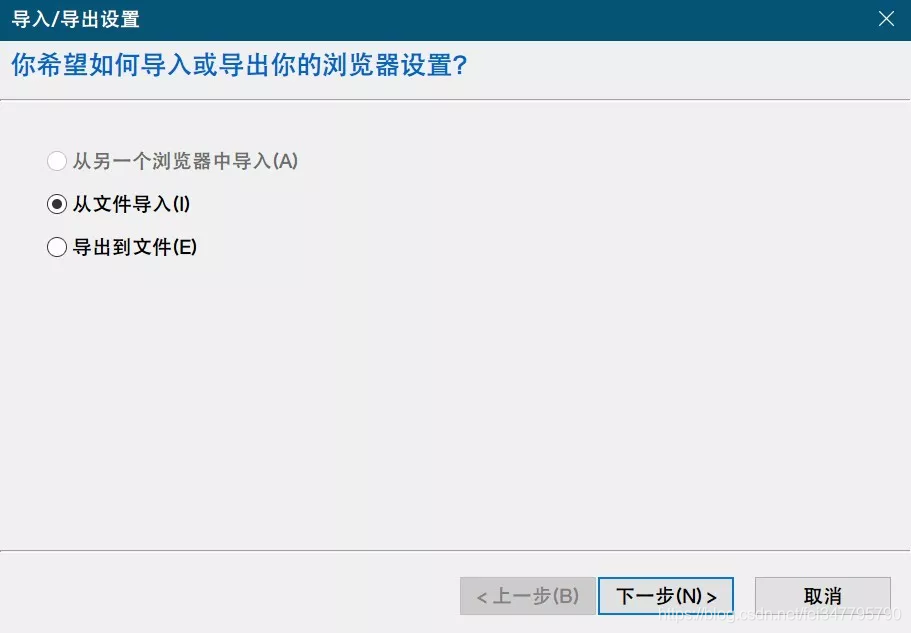
实际应用于我的浏览器
。
骚操作!曾经爱过!用 Python 清理收藏夹里已失效的网站的更多相关文章
- 清理收藏夹中的json
1.json的字符串与对象转换 $.parseJson(str)与JSON.parse(str) 返回值是true.另:json对象和字符串的相互转换 JSON.stringify(obj) 将JSO ...
- SQL优化:清理生产环境中已失效字段基本步骤
1.统计相应字段的数据情况(如:几年没更新,无数据等情况) 2.确认产品逻辑已无效(产品经理邮件确认) 3.数据备份 4.将数据清空(置为0或空) 5.测试环境中删除引用页面 6.修改定时程序,存储过 ...
- 清理收藏夹中的CSS
1.去掉元素的属性, 例如宽度 #blog-calendar { width: initial !important; }
- python 计算文件夹里所有内容的大小总和
计算文件夹里所有内容的大小总和 递归方法 '''计算文件夹的大小''' import os def dir_file_size(path): if os.path.isdir(path): file_ ...
- python骚操作---Print函数用法
---恢复内容开始--- python骚操作---Print函数用法 在 Python 中,print 可以打印所有变量数据,包括自定义类型. 在 3.x 中是个内置函数,并且拥有更丰富的功能. 参数 ...
- Python小白需要知道的 20 个骚操作!
Python小白需要知道的 20 个骚操作! Python 是一个解释型语言,可读性与易用性让它越来越热门.正如 Python 之禅中所述: 优美胜于丑陋,明了胜于晦涩. 在你的日常编码中,以下技巧可 ...
- Python中对 文件 的各种骚操作
Python中对 文件 的各种骚操作 python中对文件.文件夹(文件操作函数)的操作需要涉及到os模块和shutil模块. 得到当前工作目录,即当前Python脚本工作的目录路径: os.getc ...
- Python骚操作从列表推导和生成器表达式开始
序列 序列是指一组数据,按存放类型分为容器序列与扁平序列,按能否被修改分为不可变序列与可变序列. 容器序列与扁平序列 容器序列存放的是对象的引用,包括list.tuple.collections.de ...
- python带你采集不可言说网站数据,并带你多重骚操作~
前言 嗨喽,大佬们好鸭!这里是小熊猫~ 今天我们采集国内知名的shipin弹幕网站! 这里有及时的动漫新番,活跃的ACG氛围,有创意的Up主. 大家可以在这里找到许多欢乐. 目录(可根据个人情况点击你 ...
随机推荐
- php获取本机ip
最近在写个东西时,需要获取本机的IP,但是由于php本身不带这样的功能,在网上找了好久也没有一个好办法,突然想到一个好办法,如下代码 <?=gethostbyname($_ENV['COMPUT ...
- Python3字典update()方法
描述 Python字典update()函数把字典参数dict2的key/value(键/值)对更新到字典dict里. update()方法语法: dict.update(dict2) 参数 dict2 ...
- koa2 从入门到进阶之路 (六)
之前的文章我们介绍了一下 koa post提交数据及 koa-bodyparser中间件,本篇文章我们来看一下 koa-static静态资源中间件. 我们在之前的目录想引入外部的 js,css,img ...
- Java面试基础 -- Docker篇
1.什么是Docker? Docker是一个容器化平台,它以容器的形式将您的应用程序及其所有依赖项打包在一起,以确保您的应用程序在任何环境中无缝运行. 2.什么是Docker镜像? Docker镜像是 ...
- 【单条记录锁】select single for update
示例: DATA: wa_t001 type t001. select single for update * into wa_t001 from t001 where bukrs = '1000'. ...
- ENDIAN的由来及BIG-EDIAN 和LITTLE-ENDIAN(转)
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明. 本文链接:https://blog.csdn.net/kingmax54212008/arti ...
- 【React Native】react-native之集成支付宝支付、微信支付
一.在使用支付宝支付.微信支付之前导入桥接好的头文件 github地址:https://github.com/xujianfu/react-native-pay 二.集成支付宝支付流程 RN支付宝需要 ...
- Go语言交叉编译工具gox
基本介绍 交叉编译是为了在不同平台编译出其他平台的程序,比如在Linux编译出Windows程序,在Windows能编译出Linux程序,32位系统下编译出64位程序,今天介绍的gox就是其中一款交叉 ...
- 对比keep-alive路由缓存设置的2种方式
方式有两种 .路由元信息(2.1.0版本之前) .属性方式(2.1.0版本之后新增) Vue2.1.0之前: 想实现类似的操作,你可以: 配置一下路由元信息 创建两个keep-alive标签 使用v- ...
- cf 之lis+贪心+思维+并查集
https://codeforces.com/contest/1257/problem/E 题意:有三个集合集合里面的数字可以随意变换位置,不同集合的数字,如从第一个A集合取一个数字到B集合那操作数+ ...