【深度学习】K-L 散度,JS散度,Wasserstein距离
度量两个分布之间的差异
(一)K-L 散度
K-L 散度在信息系统中称为相对熵,可以用来量化两种概率分布 P 和 Q 之间的差异,它是非对称性的度量。在概率学和统计学上,我们经常会使用一种更简单的、近似的分布来替代观察数据或太复杂的分布。K-L散度能帮助我们度量使用一个分布来近似另一个分布时所损失的信息量。一般情况下,P 表示数据的真实分布,Q 表示数据的理论分布,估计的模型分布或者 P 的近似分布。
(二)K-L 散度公式
Note:KL 散度仅当概率 \(P\) 和 \(Q\) 各自总和均为1,且对于任何 \(i\) 皆满足 \(Q(i)>0\) , \(P(i)>0\) 时,才有定义。
\[
D_{KL}(P||Q) = - \sum_i P(i) \ln \frac{Q(i)}{P(i)} = \sum_i P(i) \ln \frac{P(i)}{Q(i)}
\]
(三)使用 K-L 散度对比两种分布
假设真实分布为 \(P\),\(P\) 的两个近似分布为 \(Q_1, Q_2\),对于这两个近似分布我们应该选择哪一个?K-L 散度可以解决这个问题:如果 \(D_{KL}(P||Q_1) < D_{KL}(P||Q_2)\),那么我们选择 \(Q_1\) 作为 \(P\) 的近似分布。
(四)散度并非距离
我们不能把 K-L 散度看作是两个分布之间距离的度量。首先距离度量需要满足对称性,但是 K-L 散度不具备对称性,即:
\[
D_{KL}(P||Q) \neq D_{KL}(Q||P)
\]
(五)问答环节
Q1:信息熵,交叉熵,相对熵的区别是什么?
A1:(1)信息熵,即熵,是编码方案完美时的最短平均编码长度;(2)交叉熵,即 Cross Entropy,是编码方案不一定完美时(对概率分布的估计不一定正确)的平均编码长度,在神经网络中常用作损失函数;(3)相对熵,即 K-L 散度,是编码方案不一定完美时,平均编码长度相对于最短平均编码长度的增加值。简单推理:

Q2:为什么在深度学习中使用 Cross Entropy 损失函数,而不是 K-L 散度?
A2:首先,损失函数的功能是衡量由样本计算所得的分布与目标分布之间的差异。在分布差异计算中,K-L散度是最合适的。但在实际中,某一事件的标签是已知不变的(比如猫狗分类中,猫的标签是1,那么数据集中所有关于猫的标签都要标记为1),即目标分布的熵为常数。根据公式:K-L散度 - 目标分布熵 = 交叉熵(这里的 - 代表裁剪),所以我们不用计算K-L散度,只需计算交叉熵就可以得到模型分布与目标分布的损失值。
换句话说,通常一个标签都是设置为 one-hot 模式,即我们常说的硬分布,\(\log1=0\),所以一般都是只用交叉熵。如果标签不是这样的硬分布,而是软分布(比如有两张猫的图片,一张预测为0.6,另一张预测为0.8),K-L散度才能发挥比较好的作用。
Q3:K-L散度和JS散度存在什么问题?有什么解决方法?
A3:如果两个分布 \(P\) 和 \(Q\) 相离很远,甚至完全没有重叠,那么 K-L 散度值是没有意义的,而 JS 散度值是一个常数,意味着梯度为0,即发生了梯度消失,这在学习算法中是非常严重的问题。Wasserstein距离 (又名推土机距离)的提出就是为了解决这个问题,它的优越性在于即使两个分布没有重叠,Wasserstein 距离仍然能够反映它们的远近。以下图为例:
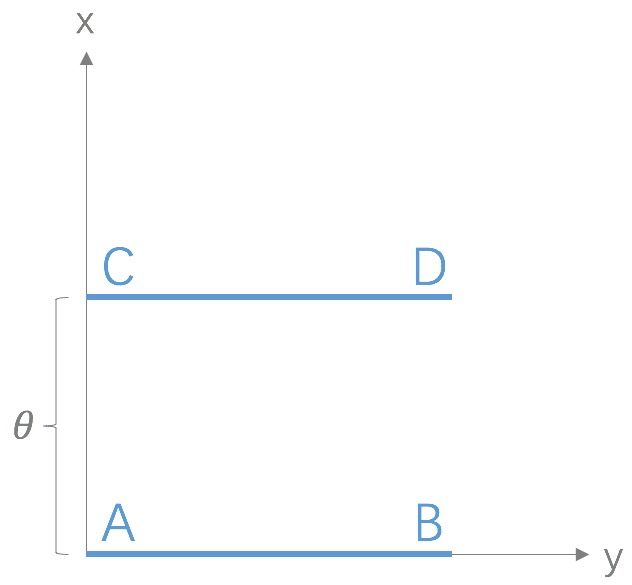
以上是二维空间中的两个分布 \(P_1\) 和 \(P_2\),\(P_1\) 在线段 AB 上均匀分布,\(P_2\) 在线段 CD 上均匀分布,通过参数 \(\theta\) 控制两个分布的距离远近,由以上公式容易得到:
K-L 散度:
\[
D_{KL}(P_1||P_2)=
\begin{cases}
+ \infin & \text{if} & \theta \neq 0 \\
0 & \text{if} & \theta = 0 \\
\end{cases}
\]
JS 散度:
\[
JS(P_1||P_2)=
\begin{cases}
\log2 & \text{if} & \theta \neq 0 \\
0 & \text{if} & \theta = 0 \\
\end{cases}
\]
Wasserstein 距离:
\[
W(P_0, P_1) = |\theta|
\]
观察以上公式可知,K-L 散度和 JS 散度取值是突变的,要么最大要么最小,Wasserstein 距离却是平滑的。如果我们要用梯度下降法优化 \(\theta\) 这个参数,前两者根本提供不了梯度,Wasserstein 距离却可以。类似地,在高维空间中如果两个分布不重叠或者重叠部分可忽略,则 KL 和 JS 既反映不了远近,也提供不了梯度,但是Wasserstein却可以提供有意义的梯度。
References:
[1] 如何理解K-L散度(相对熵)
[2] 相对熵——维基百科
【深度学习】K-L 散度,JS散度,Wasserstein距离的更多相关文章
- 【python深度学习】KS,KL,JS散度 衡量两组数据是否同分布
目录 KS(不需要两组数据相同shape) JS散度(需要两组数据同shape) KS(不需要两组数据相同shape) 奇怪之处:有的地方也叫KL KS距离,相对熵,KS散度 当P(x)和Q(x)的相 ...
- 信息论相关概念:熵 交叉熵 KL散度 JS散度
目录 机器学习基础--信息论相关概念总结以及理解 1. 信息量(熵) 2. KL散度 3. 交叉熵 4. JS散度 机器学习基础--信息论相关概念总结以及理解 摘要: 熵(entropy).KL 散度 ...
- 【GAN与NLP】GAN的原理 —— 与VAE对比及JS散度出发
0. introduction GAN模型最早由Ian Goodfellow et al于2014年提出,之后主要用于signal processing和natural document proces ...
- KL散度与JS散度
1.KL散度 KL散度( Kullback–Leibler divergence)是描述两个概率分布P和Q差异的一种测度.对于两个概率分布P.Q,二者越相似,KL散度越小. KL散度的性质:P表示真实 ...
- Python深度学习读书笔记-1.什么是深度学习
人工智能 什么是人工智能.机器学习与深度学习(见图1-1)?这三者之间有什么关系?
- KL散度、JS散度、Wasserstein距离
1. KL散度 KL散度又称为相对熵,信息散度,信息增益.KL散度是是两个概率分布 $P$ 和 $Q$ 之间差别的非对称性的度量. KL散度是用来 度量使用基于 $Q$ 的编码来编码来自 $P$ 的 ...
- 深度学习中交叉熵和KL散度和最大似然估计之间的关系
机器学习的面试题中经常会被问到交叉熵(cross entropy)和最大似然估计(MLE)或者KL散度有什么关系,查了一些资料发现优化这3个东西其实是等价的. 熵和交叉熵 提到交叉熵就需要了解下信息论 ...
- KL与JS散度学习[转载]
转自:https://www.jianshu.com/p/43318a3dc715?from=timeline&isappinstalled=0 https://blog.csdn.net/e ...
- 深度学习-Wasserstein GAN论文理解笔记
GAN存在问题 训练困难,G和D多次尝试没有稳定性,Loss无法知道能否优化,生成样本单一,改进方案靠暴力尝试 WGAN GAN的Loss函数选择不合适,使模型容易面临梯度消失,梯度不稳定,优化目标不 ...
随机推荐
- python-参数化-(2)(数据库判断是否存在并返回满足条件的数据)
1.根据python-参数化-(1),生成的数据号码 在数据库查询后判断是否存在若不存在返回手机号码,若存在返回该手机号码对应数据的信息,未封装成类或函数上代码 import pymysqlconn= ...
- 淘宝爬取图片和url
刚开始爬取了 百度图片和搜狗图片 但是图片不是很多,随后继续爬取淘宝图片,但是淘宝反爬比较厉害 之前的方法不能用 记录可行的 淘宝爬取 利用selenium爬取 https://cloud.tence ...
- BZOJ2301/LG2522 「HAOI2011」Problem B 莫比乌斯反演 数论分块
问题描述 BZOJ2301 LG2522 积性函数 若函数 \(f(x)\) 满足对于任意两个最大公约数为 \(1\) 的数 \(m,n\) ,有 \(f(mn)=f(m) \times f(n)\) ...
- java之操作集合的工具类--Collections
Collections是一个操作Set.List和Map等集合的工具类. Collections中提供了大量方法对集合元素进行排序.查询和修改等操作,还提供了对集合对象设置不可变.对集合对象实现同步控 ...
- jQuery 源码解析(二十六) 样式操作模块 样式详解
样式操作模块可用于管理DOM元素的样式.坐标和尺寸,本节讲解一下样式相关,样式操作通过jQuery实例的css方法来实现,该方法有很多的执行方法,如下: css(obj) ;参数 ...
- 一文学会JVM配置参数与工具使用
经过前面的各种分析,我们知道了关于JVM很多的知识,比如版本信息,类加载,堆,方法区,垃圾回收等,但是总觉得心里不踏实,原因是没看到实际的一些东西. 所以这在本文,咱们就好好来聊一聊关于怎么将这些内容 ...
- PHP http_response_code 网络函数
定义和用法 http_response_code - 获取/设置响应的 HTTP 状态码 版本支持 PHP4 PHP5 PHP7 不支持 支持 支持 语法 http_response_code ([ ...
- 松软科技web课堂:JavaScript 事件
HTML 事件是发生在 HTML 元素上的“事情”. 当在 HTML 页面中使用 JavaScript 时,JavaScript 能够“应对”这些事件. HTML 事件 HTML 事件可以是浏览器或用 ...
- 从华为“鸿蒙”备胎看IT项目建设
别误会啊,本文并不在讲大家在做IT项目建设的时候学华为做一个备胎系统,以防正主系统崩掉之后能够及时替换到备胎系统里面,不影响业务. 前段时间华为被美帝制裁,然后各家组织对华为各种限制.然而华为整体布局 ...
- Xcode报错:could not attach to pid:"1764"
这种错误不是什么问题,按照参考链接操作即可,亲测有效: https://www.cnblogs.com/luorende/p/6295945.html 在运行项目时出现了如下错误 (基本上重新启动项目 ...