机器学习中的误差 Where does error come from?
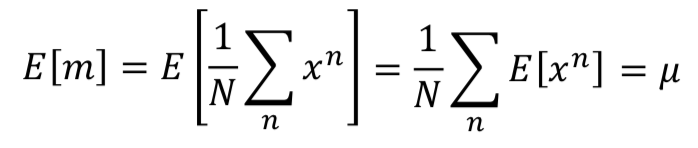 ,所以对随机变量 X 的均值的估计是无偏的。
,所以对随机变量 X 的均值的估计是无偏的。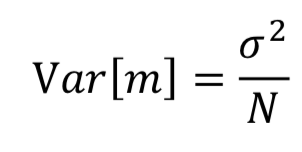
接下来,如何构造 σ2 的 estimator?=> 按照定义应该是对 s2 求期望:
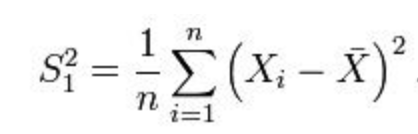
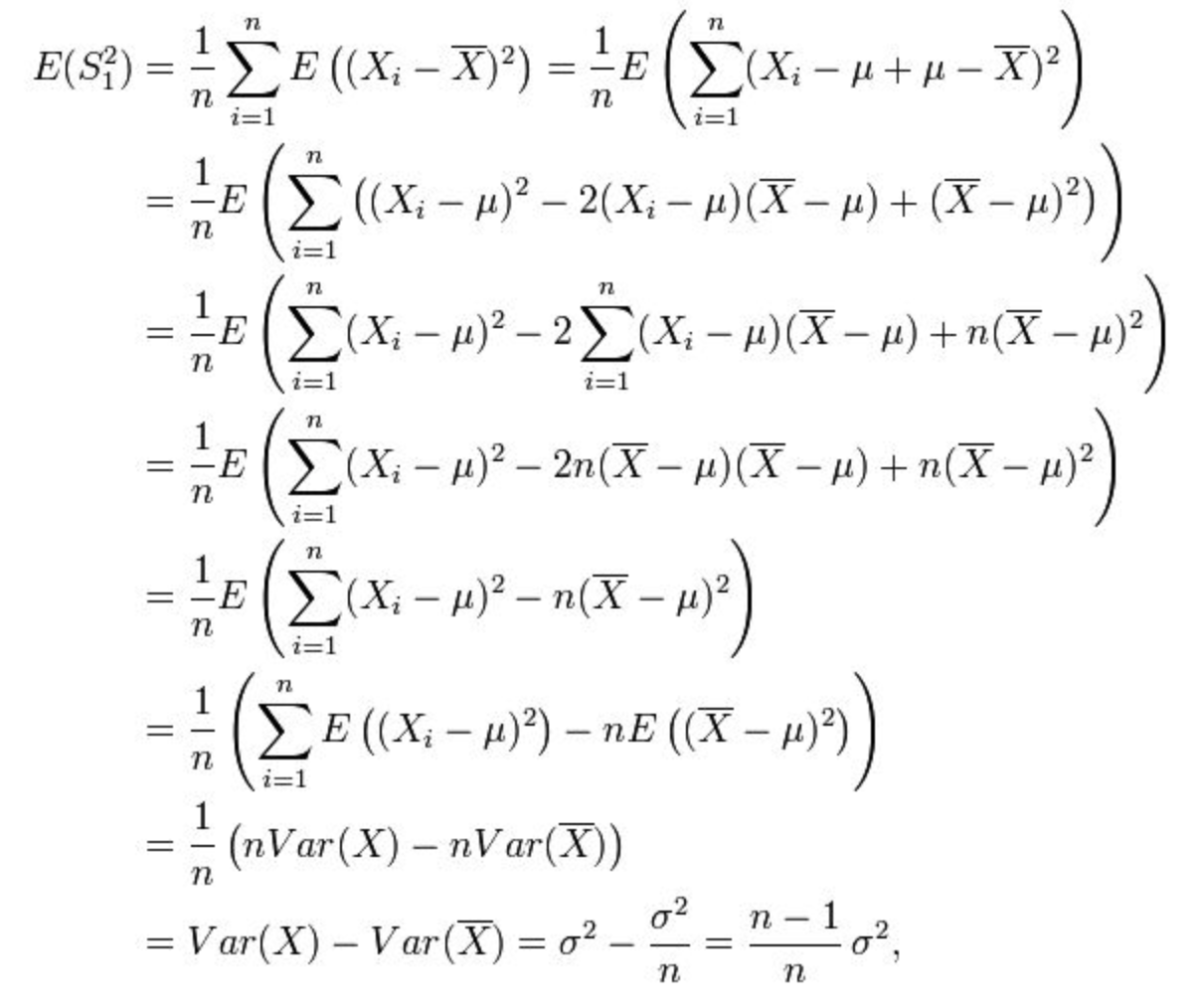
可以发现这个估计是有偏的,修正:
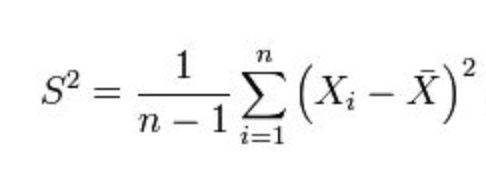
回到机器学习的误差问题上,以 linear regression 为例:
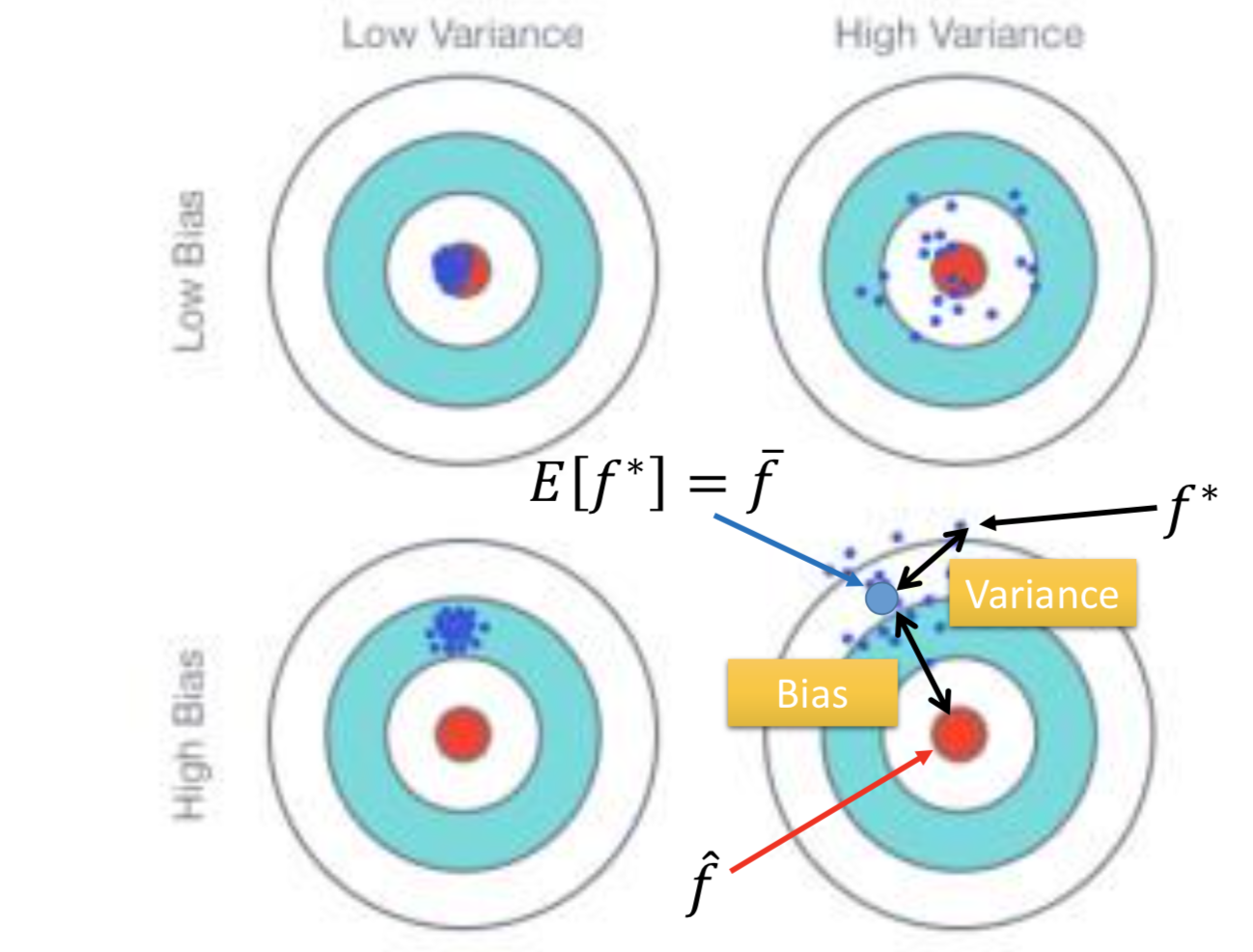
同一个模型,怎么找很多个 f* 呢?——做很多次实验就好了。

underfitting: Large bias, Small variance
overfitting: Large variance, Small bias
机器学习中的误差 Where does error come from?的更多相关文章
- 机器学习中的Bias(偏差),Error(误差),和Variance(方差)有什么区别和联系?
前几天搜狗的一道笔试题,大意是在随机森林上增加一棵树,variance和bias如何变化呢? 参考知乎上的讨论:https://www.zhihu.com/question/27068705 另外可参 ...
- paper 126:[转载] 机器学习中的范数规则化之(一)L0、L1与L2范数
机器学习中的范数规则化之(一)L0.L1与L2范数 zouxy09@qq.com http://blog.csdn.net/zouxy09 今天我们聊聊机器学习中出现的非常频繁的问题:过拟合与规则化. ...
- 机器学习中的范数规则化之(一)L0、L1与L2范数(转)
http://blog.csdn.net/zouxy09/article/details/24971995 机器学习中的范数规则化之(一)L0.L1与L2范数 zouxy09@qq.com http: ...
- 机器学习中的范数规则化之(一)L0、L1与L2范数 非常好,必看
机器学习中的范数规则化之(一)L0.L1与L2范数 zouxy09@qq.com http://blog.csdn.net/zouxy09 今天我们聊聊机器学习中出现的非常频繁的问题:过拟合与规则化. ...
- 机器学习中的K-means算法的python实现
<机器学习实战>kMeans算法(K均值聚类算法) 机器学习中有两类的大问题,一个是分类,一个是聚类.分类是根据一些给定的已知类别标号的样本,训练某种学习机器,使它能够对未知类别的样本进行 ...
- 机器学习中的范数规则化-L0,L1和L2范式(转载)
机器学习中的范数规则化之(一)L0.L1与L2范数 zouxy09@qq.com http://blog.csdn.net/zouxy09 今天我们聊聊机器学习中出现的非常频繁的问题:过拟合与规则化. ...
- 机器学习中模型泛化能力和过拟合现象(overfitting)的矛盾、以及其主要缓解方法正则化技术原理初探
1. 偏差与方差 - 机器学习算法泛化性能分析 在一个项目中,我们通过设计和训练得到了一个model,该model的泛化可能很好,也可能不尽如人意,其背后的决定因素是什么呢?或者说我们可以从哪些方面去 ...
- 偏差(Bias)和方差(Variance)——机器学习中的模型选择zz
模型性能的度量 在监督学习中,已知样本 ,要求拟合出一个模型(函数),其预测值与样本实际值的误差最小. 考虑到样本数据其实是采样,并不是真实值本身,假设真实模型(函数)是,则采样值,其中代表噪音,其均 ...
- 机器学习中的规则化范数(L0, L1, L2, 核范数)
目录: 一.L0,L1范数 二.L2范数 三.核范数 今天我们聊聊机器学习中出现的非常频繁的问题:过拟合与规则化.我们先简单的来理解下常用的L0.L1.L2和核范数规则化.最后聊下规则化项参数的选择问 ...
随机推荐
- 浅谈labviEW定时器
Labview提供了五种定时器:普通定时器3种: Tick Count (ms). Wait(ms).Wait Until Next ms Multipule(等待下一个毫秒的整数倍) API函数定 ...
- Object.toString()打印“地址”的原理
Object.toString()打印"地址"的原理 @(java) 首先,打印的绝不是地址 public native int hashCode(); public boolea ...
- python文件下载
1. 场景描述 刚好总结Java项目的web文件下载(附方案及源码配置),想起python项目也有用到文件下载,就也介绍下吧. 2. 解决方案 使用python的第三方组件Flask来实现文件下载功能 ...
- 9.5 考试 第三题 奇袭题解(codeforce 526f)
问题 C: 奇袭 时间限制: 1 Sec 内存限制: 256 MB 题目描述 由于各种原因,桐人现在被困在Under World(以下简称UW)中,而UW马上 要迎来最终的压力测试——魔界入侵. 唯 ...
- 不调用free会内存泄露吗?
内存泄露的概念大家可以自行百度下,本文不做阐述.本文要讲的是在程序中分配了内存,但是最后没有使用free()函数来释放这块内存,会导致内存泄露吗?比如有如下代码: #include <stdio ...
- py+selenium 报错NameError: name 'NoSuchElementException' is not defined【已解决】
报错:NameError: name 'NoSuchElementException' is not defined 如图 解决方法: 头部加一句:from selenium.common.exc ...
- ASP.NET Core MVC 之模型(Model)
1.模型绑定 ASP.NET Core MVC 中的模型绑定将数据从HTTP请求映射到操作方法参数.参数既可以是简单类型,也可以是复杂类型.MVC 通过抽象绑定解决了这个问题. 2.使用模型绑定 当 ...
- Excel催化剂开源第5波-任务窗格在OFFICE2013中新建文档不能同步显示问题解决
在OFFICE2013及之后,使用了单文档界面技术,不同于以往版本可以共享任务空格.功能区.所以当开发任务窗格时,需要考虑到每一个工作薄都关联一个任务窗格. 背景介绍 单文档界面摘录官方定义如下:对 ...
- 2017day1
http://www.cnblogs.com/alex3714/articles/5465198.html 四.Python安装 windows 1 2 3 4 5 6 7 1.下载安装包 h ...
- C#编程.异常处理(Exception Handling Statements)
C#语言包含结构化异常处理(Structured Exception Handling,SEH). throw The throw statement is used to signal the oc ...