机器学习中的误差 Where does error come from?
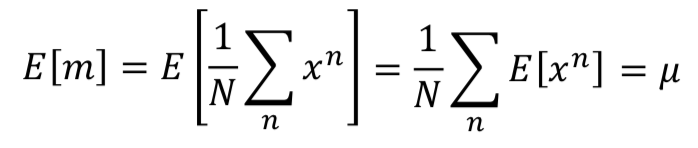 ,所以对随机变量 X 的均值的估计是无偏的。
,所以对随机变量 X 的均值的估计是无偏的。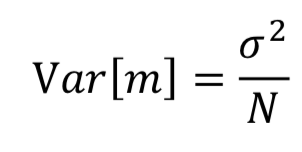
接下来,如何构造 σ2 的 estimator?=> 按照定义应该是对 s2 求期望:
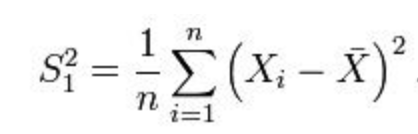
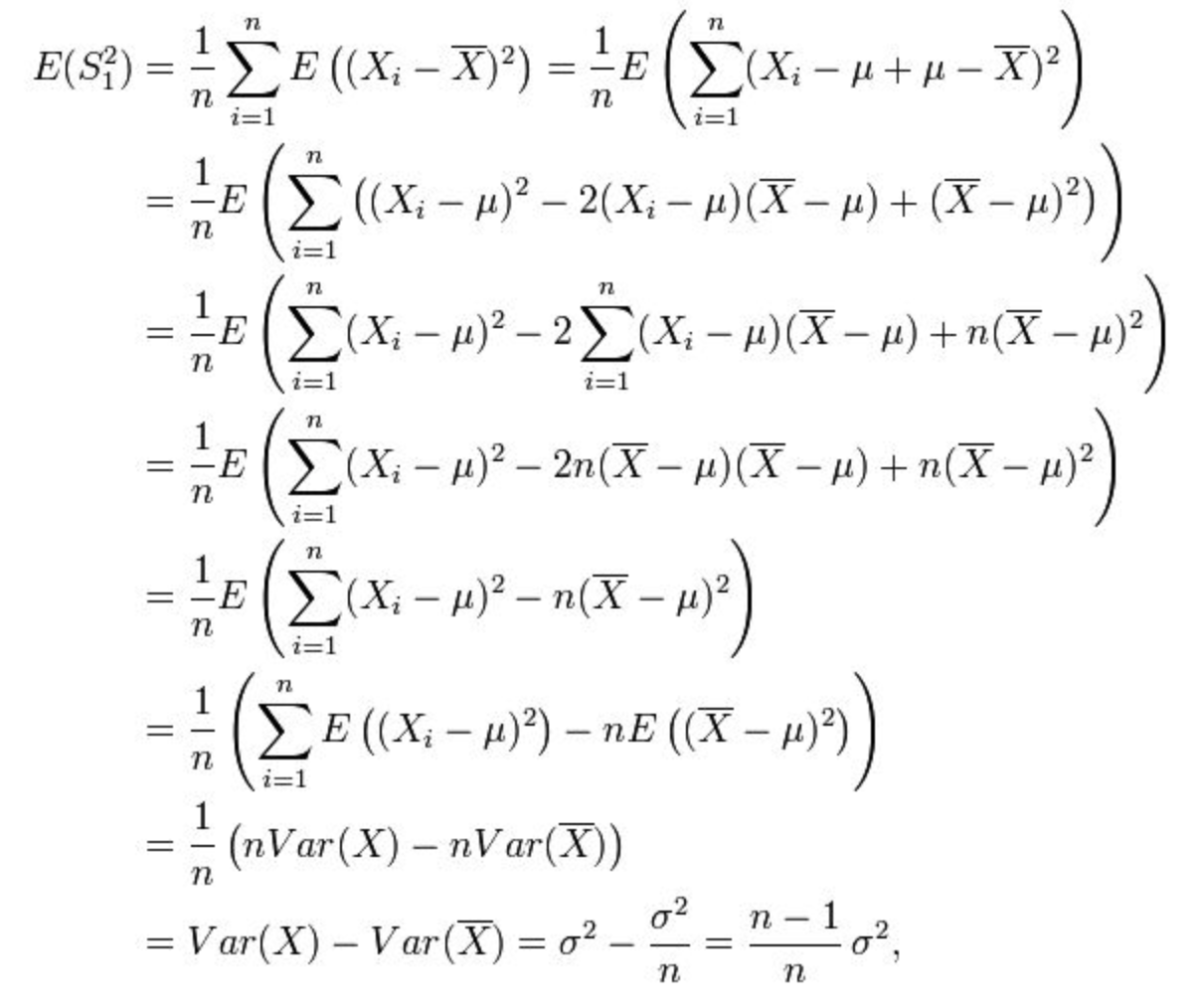
可以发现这个估计是有偏的,修正:
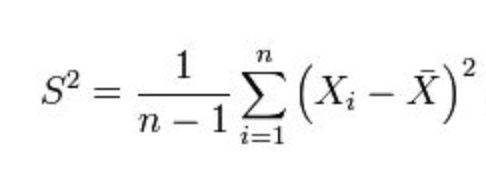
回到机器学习的误差问题上,以 linear regression 为例:
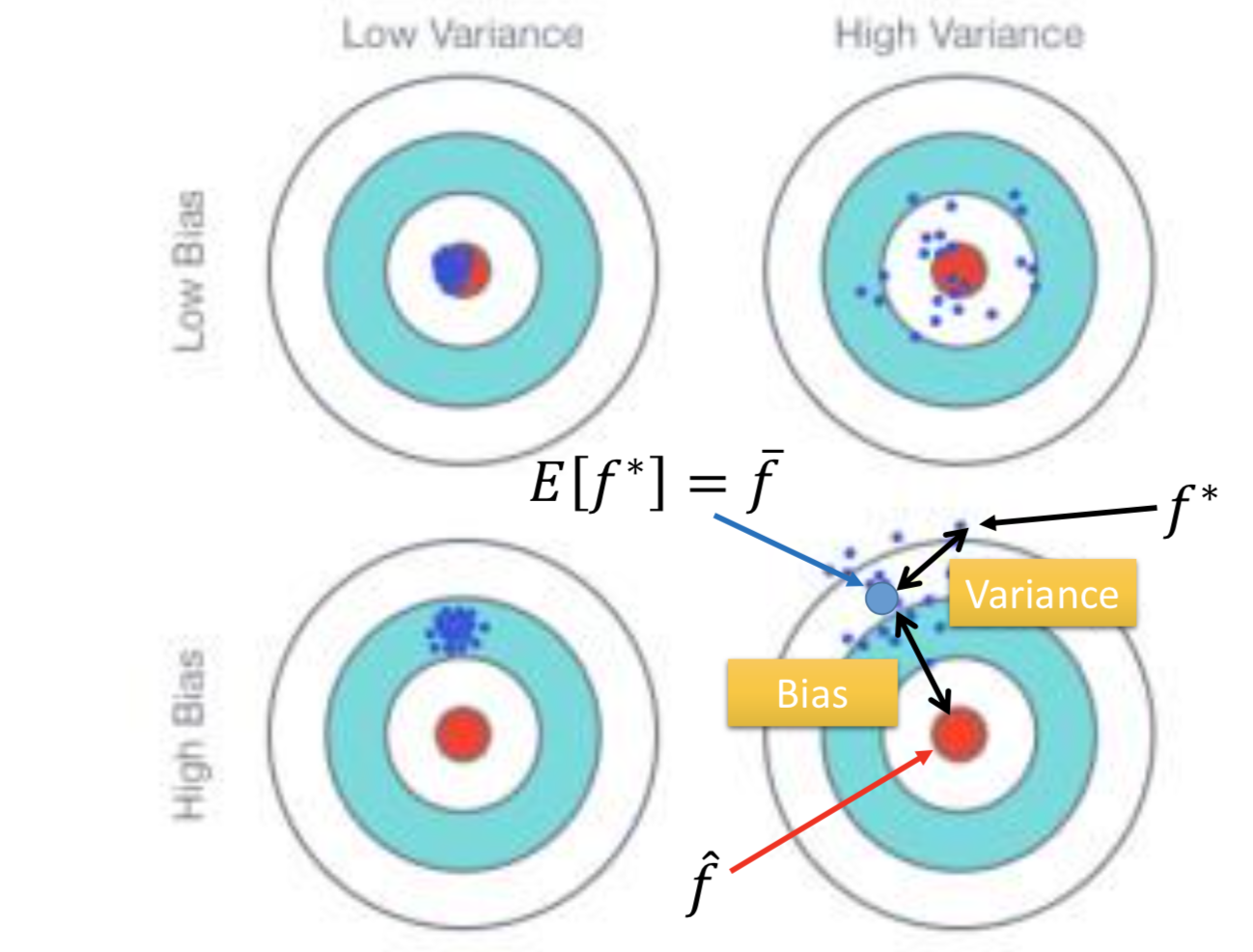
同一个模型,怎么找很多个 f* 呢?——做很多次实验就好了。

underfitting: Large bias, Small variance
overfitting: Large variance, Small bias
机器学习中的误差 Where does error come from?的更多相关文章
- 机器学习中的Bias(偏差),Error(误差),和Variance(方差)有什么区别和联系?
前几天搜狗的一道笔试题,大意是在随机森林上增加一棵树,variance和bias如何变化呢? 参考知乎上的讨论:https://www.zhihu.com/question/27068705 另外可参 ...
- paper 126:[转载] 机器学习中的范数规则化之(一)L0、L1与L2范数
机器学习中的范数规则化之(一)L0.L1与L2范数 zouxy09@qq.com http://blog.csdn.net/zouxy09 今天我们聊聊机器学习中出现的非常频繁的问题:过拟合与规则化. ...
- 机器学习中的范数规则化之(一)L0、L1与L2范数(转)
http://blog.csdn.net/zouxy09/article/details/24971995 机器学习中的范数规则化之(一)L0.L1与L2范数 zouxy09@qq.com http: ...
- 机器学习中的范数规则化之(一)L0、L1与L2范数 非常好,必看
机器学习中的范数规则化之(一)L0.L1与L2范数 zouxy09@qq.com http://blog.csdn.net/zouxy09 今天我们聊聊机器学习中出现的非常频繁的问题:过拟合与规则化. ...
- 机器学习中的K-means算法的python实现
<机器学习实战>kMeans算法(K均值聚类算法) 机器学习中有两类的大问题,一个是分类,一个是聚类.分类是根据一些给定的已知类别标号的样本,训练某种学习机器,使它能够对未知类别的样本进行 ...
- 机器学习中的范数规则化-L0,L1和L2范式(转载)
机器学习中的范数规则化之(一)L0.L1与L2范数 zouxy09@qq.com http://blog.csdn.net/zouxy09 今天我们聊聊机器学习中出现的非常频繁的问题:过拟合与规则化. ...
- 机器学习中模型泛化能力和过拟合现象(overfitting)的矛盾、以及其主要缓解方法正则化技术原理初探
1. 偏差与方差 - 机器学习算法泛化性能分析 在一个项目中,我们通过设计和训练得到了一个model,该model的泛化可能很好,也可能不尽如人意,其背后的决定因素是什么呢?或者说我们可以从哪些方面去 ...
- 偏差(Bias)和方差(Variance)——机器学习中的模型选择zz
模型性能的度量 在监督学习中,已知样本 ,要求拟合出一个模型(函数),其预测值与样本实际值的误差最小. 考虑到样本数据其实是采样,并不是真实值本身,假设真实模型(函数)是,则采样值,其中代表噪音,其均 ...
- 机器学习中的规则化范数(L0, L1, L2, 核范数)
目录: 一.L0,L1范数 二.L2范数 三.核范数 今天我们聊聊机器学习中出现的非常频繁的问题:过拟合与规则化.我们先简单的来理解下常用的L0.L1.L2和核范数规则化.最后聊下规则化项参数的选择问 ...
随机推荐
- input的值为浅淡样式(点击值消失)
<input type="text" id="leftSearchValue" value="" placeholder=" ...
- svn unable to connect to a repository url 计算机积极拒绝
网上应该说启动server服务,首先找不到这个服务,后来下载个软件有了,启动还是不行.clear了所有saved data之后也是不行. 解决方法:Network中 Enable proxy Serv ...
- C++中 / 和 % 在分离各位时的妙用
在学习c++的过程中,我们一般用 / 和 % 来分解数字的各个位 取整 (/) 比如1234 / 10 等于 123.4,这相当于把前三位分解出来了 取余(%) 比如 12345 的分解方法 个位:1 ...
- .Net Core 学习新建Core MVC 项目
一.新建空的Core web项目 二.在Startup文件中添加如下配置 1. 在ConfigureServices 方法中添加 services.AddMvc();MVC服务 2. app.Use ...
- leetcode的Hot100系列--3. 无重复字符的最长子串--滑动窗口
可以先想下这两个问题: 1.怎样使用滑动窗口? 2.如何快速的解决字符查重问题? 滑动窗口 可以想象一下有两个指针,一个叫begin,一个叫now 这两个指针就指定了当前正在比较无重复的字符串,当再往 ...
- DRF + react 实现TodoList
在web项目构建中有很多框架可供选择,开发人员对项目的使用选择,有很多的影响因素,其中之一就是框架在定义该项目的单独任务时的复杂性. 简介 本文有如下几个部分: 准备 配置后端 配置APIs 配置前端 ...
- HDU5521 Meeting(dijkstra+巧妙建图)
HDU5521 Meeting 题意: 给你n个点,它们组成了m个团,第i个团内有si个点,且每个团内的点互相之间距离为ti,问如果同时从点1和点n出发,最短耗时多少相遇 很明显题目给出的是个无负环的 ...
- springboot-多模块构建
1. 场景描述 先介绍下背景,项目为什么需要用多模块?springmvc难道还不够? (1)设计模式真言:"高内聚.低耦合",springmvc项目,一般会把项目分成多个包:con ...
- +p解决vim粘贴自动缩进。 数字gg跳到vim指定行。 vim查找到后,enter键修改
+p解决vim粘贴自动缩进. 数字gg跳到vim指定行. vim查找到后,enter键修改
- Asp.Net Core SwaggerUI 接入
Asp.Net Core SwaggerUI 接入 简单了解 swagger的目的简单来说就是,不用为每个接口手动写接口文档,因为它是根据接口自动生成的,接口更改时文档也同步更新,减少了手动更新的麻烦 ...