Spark 系列(十一)—— Spark SQL 聚合函数 Aggregations
一、简单聚合
1.1 数据准备
// 需要导入 spark sql 内置的函数包
import org.apache.spark.sql.functions._
val spark = SparkSession.builder().appName("aggregations").master("local[2]").getOrCreate()
val empDF = spark.read.json("/usr/file/json/emp.json")
// 注册为临时视图,用于后面演示 SQL 查询
empDF.createOrReplaceTempView("emp")
empDF.show()注:emp.json 可以从本仓库的resources 目录下载。
1.2 count
// 计算员工人数
empDF.select(count("ename")).show()1.3 countDistinct
// 计算姓名不重复的员工人数
empDF.select(countDistinct("deptno")).show()1.4 approx_count_distinct
通常在使用大型数据集时,你可能关注的只是近似值而不是准确值,这时可以使用 approx_count_distinct 函数,并可以使用第二个参数指定最大允许误差。
empDF.select(approx_count_distinct ("ename",0.1)).show()1.5 first & last
获取 DataFrame 中指定列的第一个值或者最后一个值。
empDF.select(first("ename"),last("job")).show()1.6 min & max
获取 DataFrame 中指定列的最小值或者最大值。
empDF.select(min("sal"),max("sal")).show()1.7 sum & sumDistinct
求和以及求指定列所有不相同的值的和。
empDF.select(sum("sal")).show()
empDF.select(sumDistinct("sal")).show()1.8 avg
内置的求平均数的函数。
empDF.select(avg("sal")).show()1.9 数学函数
Spark SQL 中还支持多种数学聚合函数,用于通常的数学计算,以下是一些常用的例子:
// 1.计算总体方差、均方差、总体标准差、样本标准差
empDF.select(var_pop("sal"), var_samp("sal"), stddev_pop("sal"), stddev_samp("sal")).show()
// 2.计算偏度和峰度
empDF.select(skewness("sal"), kurtosis("sal")).show()
// 3. 计算两列的皮尔逊相关系数、样本协方差、总体协方差。(这里只是演示,员工编号和薪资两列实际上并没有什么关联关系)
empDF.select(corr("empno", "sal"), covar_samp("empno", "sal"),covar_pop("empno", "sal")).show()1.10 聚合数据到集合
scala> empDF.agg(collect_set("job"), collect_list("ename")).show()
输出:
+--------------------+--------------------+
| collect_set(job)| collect_list(ename)|
+--------------------+--------------------+
|[MANAGER, SALESMA...|[SMITH, ALLEN, WA...|
+--------------------+--------------------+二、分组聚合
2.1 简单分组
empDF.groupBy("deptno", "job").count().show()
//等价 SQL
spark.sql("SELECT deptno, job, count(*) FROM emp GROUP BY deptno, job").show()
输出:
+------+---------+-----+
|deptno| job|count|
+------+---------+-----+
| 10|PRESIDENT| 1|
| 30| CLERK| 1|
| 10| MANAGER| 1|
| 30| MANAGER| 1|
| 20| CLERK| 2|
| 30| SALESMAN| 4|
| 20| ANALYST| 2|
| 10| CLERK| 1|
| 20| MANAGER| 1|
+------+---------+-----+2.2 分组聚合
empDF.groupBy("deptno").agg(count("ename").alias("人数"), sum("sal").alias("总工资")).show()
// 等价语法
empDF.groupBy("deptno").agg("ename"->"count","sal"->"sum").show()
// 等价 SQL
spark.sql("SELECT deptno, count(ename) ,sum(sal) FROM emp GROUP BY deptno").show()
输出:
+------+----+------+
|deptno|人数|总工资|
+------+----+------+
| 10| 3|8750.0|
| 30| 6|9400.0|
| 20| 5|9375.0|
+------+----+------+三、自定义聚合函数
Scala 提供了两种自定义聚合函数的方法,分别如下:
- 有类型的自定义聚合函数,主要适用于 DataSet;
- 无类型的自定义聚合函数,主要适用于 DataFrame。
以下分别使用两种方式来自定义一个求平均值的聚合函数,这里以计算员工平均工资为例。两种自定义方式分别如下:
3.1 有类型的自定义函数
import org.apache.spark.sql.expressions.Aggregator
import org.apache.spark.sql.{Encoder, Encoders, SparkSession, functions}
// 1.定义员工类,对于可能存在 null 值的字段需要使用 Option 进行包装
case class Emp(ename: String, comm: scala.Option[Double], deptno: Long, empno: Long,
hiredate: String, job: String, mgr: scala.Option[Long], sal: Double)
// 2.定义聚合操作的中间输出类型
case class SumAndCount(var sum: Double, var count: Long)
/* 3.自定义聚合函数
* @IN 聚合操作的输入类型
* @BUF reduction 操作输出值的类型
* @OUT 聚合操作的输出类型
*/
object MyAverage extends Aggregator[Emp, SumAndCount, Double] {
// 4.用于聚合操作的的初始零值
override def zero: SumAndCount = SumAndCount(0, 0)
// 5.同一分区中的 reduce 操作
override def reduce(avg: SumAndCount, emp: Emp): SumAndCount = {
avg.sum += emp.sal
avg.count += 1
avg
}
// 6.不同分区中的 merge 操作
override def merge(avg1: SumAndCount, avg2: SumAndCount): SumAndCount = {
avg1.sum += avg2.sum
avg1.count += avg2.count
avg1
}
// 7.定义最终的输出类型
override def finish(reduction: SumAndCount): Double = reduction.sum / reduction.count
// 8.中间类型的编码转换
override def bufferEncoder: Encoder[SumAndCount] = Encoders.product
// 9.输出类型的编码转换
override def outputEncoder: Encoder[Double] = Encoders.scalaDouble
}
object SparkSqlApp {
// 测试方法
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder().appName("Spark-SQL").master("local[2]").getOrCreate()
import spark.implicits._
val ds = spark.read.json("file/emp.json").as[Emp]
// 10.使用内置 avg() 函数和自定义函数分别进行计算,验证自定义函数是否正确
val myAvg = ds.select(MyAverage.toColumn.name("average_sal")).first()
val avg = ds.select(functions.avg(ds.col("sal"))).first().get(0)
println("自定义 average 函数 : " + myAvg)
println("内置的 average 函数 : " + avg)
}
}自定义聚合函数需要实现的方法比较多,这里以绘图的方式来演示其执行流程,以及每个方法的作用:
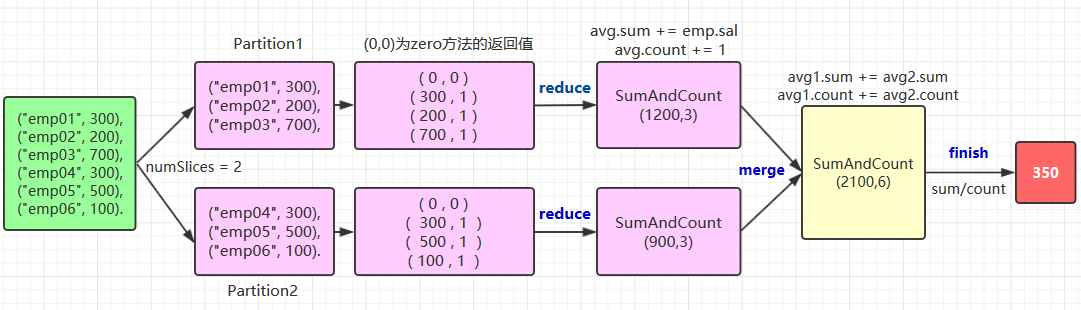
关于 zero,reduce,merge,finish 方法的作用在上图都有说明,这里解释一下中间类型和输出类型的编码转换,这个写法比较固定,基本上就是两种情况:
- 自定义类型 Case Class 或者元组就使用
Encoders.product方法; - 基本类型就使用其对应名称的方法,如
scalaByte,scalaFloat,scalaShort等,示例如下:
override def bufferEncoder: Encoder[SumAndCount] = Encoders.product
override def outputEncoder: Encoder[Double] = Encoders.scalaDouble3.2 无类型的自定义聚合函数
理解了有类型的自定义聚合函数后,无类型的定义方式也基本相同,代码如下:
import org.apache.spark.sql.expressions.{MutableAggregationBuffer, UserDefinedAggregateFunction}
import org.apache.spark.sql.types._
import org.apache.spark.sql.{Row, SparkSession}
object MyAverage extends UserDefinedAggregateFunction {
// 1.聚合操作输入参数的类型,字段名称可以自定义
def inputSchema: StructType = StructType(StructField("MyInputColumn", LongType) :: Nil)
// 2.聚合操作中间值的类型,字段名称可以自定义
def bufferSchema: StructType = {
StructType(StructField("sum", LongType) :: StructField("MyCount", LongType) :: Nil)
}
// 3.聚合操作输出参数的类型
def dataType: DataType = DoubleType
// 4.此函数是否始终在相同输入上返回相同的输出,通常为 true
def deterministic: Boolean = true
// 5.定义零值
def initialize(buffer: MutableAggregationBuffer): Unit = {
buffer(0) = 0L
buffer(1) = 0L
}
// 6.同一分区中的 reduce 操作
def update(buffer: MutableAggregationBuffer, input: Row): Unit = {
if (!input.isNullAt(0)) {
buffer(0) = buffer.getLong(0) + input.getLong(0)
buffer(1) = buffer.getLong(1) + 1
}
}
// 7.不同分区中的 merge 操作
def merge(buffer1: MutableAggregationBuffer, buffer2: Row): Unit = {
buffer1(0) = buffer1.getLong(0) + buffer2.getLong(0)
buffer1(1) = buffer1.getLong(1) + buffer2.getLong(1)
}
// 8.计算最终的输出值
def evaluate(buffer: Row): Double = buffer.getLong(0).toDouble / buffer.getLong(1)
}
object SparkSqlApp {
// 测试方法
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder().appName("Spark-SQL").master("local[2]").getOrCreate()
// 9.注册自定义的聚合函数
spark.udf.register("myAverage", MyAverage)
val df = spark.read.json("file/emp.json")
df.createOrReplaceTempView("emp")
// 10.使用自定义函数和内置函数分别进行计算
val myAvg = spark.sql("SELECT myAverage(sal) as avg_sal FROM emp").first()
val avg = spark.sql("SELECT avg(sal) as avg_sal FROM emp").first()
println("自定义 average 函数 : " + myAvg)
println("内置的 average 函数 : " + avg)
}
}参考资料
- Matei Zaharia, Bill Chambers . Spark: The Definitive Guide[M] . 2018-02
更多大数据系列文章可以参见 GitHub 开源项目: 大数据入门指南
Spark 系列(十一)—— Spark SQL 聚合函数 Aggregations的更多相关文章
- Spark学习之路(十一)—— Spark SQL 聚合函数 Aggregations
一.简单聚合 1.1 数据准备 // 需要导入spark sql内置的函数包 import org.apache.spark.sql.functions._ val spark = SparkSess ...
- Spark踩坑填坑-聚合函数-序列化异常
Spark踩坑填坑-聚合函数-序列化异常 一.Spark聚合函数特殊场景 二.spark sql group by 三.Spark Caused by: java.io.NotSerializable ...
- SQL 聚合函数
SQL聚合函数 MAX---最大值 MIN--最小值 AVG--平均值 SUM--求和 COUNT--记录的条数 EXample: --从MyStudent表中查询最大年龄,最小年龄,平均年龄,年龄的 ...
- SQL Server数据库--》top关键字,order by排序,distinct去除重复记录,sql聚合函数,模糊查询,通配符,空值处理。。。。
top关键字:写在select后面 字段的前面 比如你要显示查询的前5条记录,如下所示: select top 5 * from Student 一般情况下,top是和order by连用的 orde ...
- sql 聚合函数、排序方法详解
聚合函数 count,max,min,avg,sum... select count (*) from T_Employee select Max(FSalary) from T_Employee 排 ...
- C#写的SQL聚合函数
SQL Server 字符串连接聚合函数. 注册程序集: 拷贝“SqlStrConcate.dll”至<sql安装根目录>/MSSQL.1/MSSQL/Binn目录下,执行下面的SQL: ...
- Sql Server的艺术(三) SQL聚合函数的应用
SQL提供的聚合函数有求和,最大值,最小值,平均值,计数函数等. 聚合函数及其功能: 函数名称 函数功能 SUM() 返回选取结果集中所有值的总和 MAX() 返回选取结果集中所有值的最大值 MIN( ...
- sql 聚合函数用法,及执行顺序
聚合函数无法用在where子句中 , 聚合函数包括count avg sum min max 子句执行顺序from -> where -> group by -> having -& ...
- sql 聚合函数和group by 联合使用
原文 很多时候单独使用聚合函数的时候觉得很容易,求个平均值,求和,求个数等,但是和分组一起用就有点混淆了,好记性不如烂笔头,所以就记下来以后看看. 常用聚合函数罗列 1 AVG() - 返回平均值 C ...
随机推荐
- Netty-Channel架构体系源码解读
全文围绕下图,Netty-Channel的简化版架构体系图展开,从顶层Channel接口开始入手,往下递进,闲言少叙,直接开撸 概述: 从图中可以看到,从顶级接口Channel开始,在接口中定义了一套 ...
- activiti学习笔记
activiti入门 activiti官网 pom.xml文件 xml <!-- activiti --> <dependency> <groupId>org.ac ...
- How to Read a Paper丨如何阅读一篇论文
这是我在看论文时无意刷到的博客推荐的一篇文章"How to Read a Paper",教你怎么样看论文.对于研究生来说,看论文基本是日常,一篇论文十多二十页,如何高效地读论文确实 ...
- Python学习3——Python的简单推导
列表推导是一种从其他列表创建列表的方式,类似于数学中的集合推导,列表推导的工作原理非常简单,类似于for循环.(以下代码均在IDLE实现) 最简单的列表推导: >>>[x*x for ...
- JAVA面试题 线程的生命周期包括哪几个阶段?
面试官:您知道线程的生命周期包括哪几个阶段? 应聘者: 线程的生命周期包含5个阶段,包括:新建.就绪.运行.阻塞.销毁. 新建:就是刚使用new方法,new出来的线程: 就绪:就是调用的线程的star ...
- c语言进阶2-变量的作用域与无参函数
一. 什么是函数 函数是具有特定功能的模块.可以说一个完整的程序其实是由多个函数共同完成的.C语言的全部工作都是由程式各样的函数完成的,所以也把C语言称为函数式语言.使用模块化设计可能 使 ...
- Python -----函数(基础部分)
函数: 1.定义: 函数是对功能的封装 2.语法: def 函数名 函数体 函数名 函数名的命名规则和变量一样 3.函数的返回值: return,函数执行完毕,不会执行后面的 1.如果函数中不写ret ...
- 摘录C#代码片段
1.保存数据到指定文件String response = "";//数据 byte[] bytes = response.getBytes();//转化Byte string fi ...
- SSM框架实现原理图(转)
- pheatmap绘制“热图”,你需要的都在这
热图可以聚合大量的数据,并可以用一种渐进色来优雅地表现,可以很直观地展现数据的疏密程度或频率高低. 本文利用R语言 pheatmap 包从头开始绘制各种漂亮的热图.参数像积木,拼凑出你最喜欢的热图即可 ...