python requests、xpath爬虫增加博客访问量
这是一个分析IP代理网站,通过代理网站提供的ip去访问CSDN博客,达到以不同ip访同一博客的目的,以娱乐为主,大家可以去玩一下。
首先,准备工作,设置User-Agent:
#1.headers
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:68.0) Gecko/20100101 Firefox/68.0'}
然后百度一个IP代理网站,我选用的是https://www.kuaidaili.com/free,解析网页,提取其中的ip、端口、类型,并以list保存:
#1.获取IP地址
html=requests.get('https://www.kuaidaili.com/free').content.decode('utf8')
tree = etree.HTML(html)
ip = tree.xpath("//td[@data-title='IP']/text()")
port=tree.xpath("//td[@data-title='PORT']/text()")
model=tree.xpath("//td[@data-title='类型']/text()")
接着分析个人博客下的各篇文章的url地址,以list保存
#2.获取CSDN文章url地址 ChildrenUrl[]
url='https://blog.csdn.net/weixin_43576564'
response=requests.get(url,headers=headers)
Home=response.content.decode('utf8')
Home=etree.HTML(Home)
urls=Home.xpath("//div[@class='article-item-box csdn-tracking-statistics']/h4/a/@href")
ChildrenUrl=[]
然后通过代理ip去访问个人博客的各篇文章,通过for循环,一个ip将所有文章访问一遍,通过解析"我的博客"网页,获取总浏览量,实时监控浏览量是否发生变化,设置任务数,实时显示任务进度,通过random.randint()设置sleep时间,使得spider更加安全。全代码如下:
import os
import time
import random
import requests
from lxml import etree
#准备部分
#1.headers
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:68.0) Gecko/20100101 Firefox/68.0'} #1.获取IP地址
html=requests.get('https://www.kuaidaili.com/free').content.decode('utf8')
tree = etree.HTML(html)
ip = tree.xpath("//td[@data-title='IP']/text()")
port=tree.xpath("//td[@data-title='PORT']/text()")
model=tree.xpath("//td[@data-title='类型']/text()") #2.获取CSDN文章url地址 ChildrenUrl[]
url='https://blog.csdn.net/weixin_43576564'
response=requests.get(url,headers=headers)
Home=response.content.decode('utf8')
Home=etree.HTML(Home)
urls=Home.xpath("//div[@class='article-item-box csdn-tracking-statistics']/h4/a/@href")
ChildrenUrl=[]
for i in range(1,len(urls)):
ChildrenUrl.append(urls[i]) oldtime=time.gmtime() browses=int(input("输入需要访问次数:"))
browse=0
#3.循环伪装ip并爬取文章
for i in range(1,len(model)):
#设计代理ip
proxies={model[i]:'{}{}'.format(ip[i],port[i])}
for Curl in ChildrenUrl:
try:
browse += 1
print("进度:{}/{}".format(browse,browses),end="\t")
#遍历文章
response=requests.get(Curl,headers=headers,proxies=proxies)
#获取访问人数
look=etree.HTML(response.content)
Nuwmunber=look.xpath("//div[@class='grade-box clearfix']/dl[2]/dd/text()")
count=Nuwmunber[0].strip()
print("总浏览量:{}".format(count),end="\t")
''' 重新实现 #每个IP进行一次查询
if Curl==ChildrenUrl[5]:
ipUrl='http://www.ip138.com/'
response=requests.get(ipUrl,proxies=proxies)
iphtml=response.content
ipHtmlTree=etree.HTML(iphtml)
ipaddress=ipHtmlTree.xpath("//p[@class='result']/text()")
print(ip[i],ipaddress)
'''
i = random.randint(5, 30)
print("间隔{}秒".format(i),end="\t")
time.sleep(i)
print("当前浏览文章地址:{}".format(Curl))
if browse == browses:
print("已完成爬取任务,共消耗{}秒".format(int(time.perf_counter())))
os._exit(0) except:
print('error')
os._exit(0) #打印当前代理ip
print(proxies)
实际运行效果图: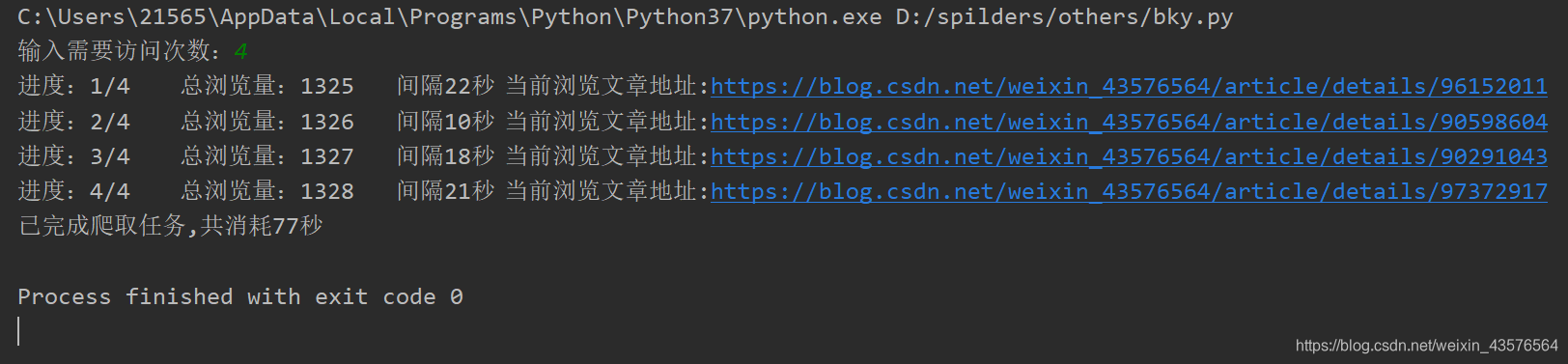
python requests、xpath爬虫增加博客访问量的更多相关文章
- Python爬虫小实践:爬取任意CSDN博客所有文章的文字内容(或可改写为保存其他的元素),间接增加博客访问量
Python并不是我的主业,当初学Python主要是为了学爬虫,以为自己觉得能够从网上爬东西是一件非常神奇又是一件非常有用的事情,因为我们可以获取一些方面的数据或者其他的东西,反正各有用处. 这两天闲 ...
- python之刷博客访问量
通过写刷访问量学习正则匹配 说明信息 说明:仅仅是为了熟悉正则表达式以及网页结构,并不赞成刷访问量操作. 1.刷访问量第一版 1.1 确定网页url结构,构造匹配模式串 首先是要确定刷的网页.第一版实 ...
- python编写的自动获取代理IP列表的爬虫-chinaboywg-ChinaUnix博客
python编写的自动获取代理IP列表的爬虫-chinaboywg-ChinaUnix博客 undefined Python多线程抓取代理服务器 | Linux运维笔记 undefined java如 ...
- 用Python和Django实现多用户博客系统(二)——UUBlog
这次又更新了一大部分功能,这次以app的形式来开发. 增加博客分类功能:博客关注.推荐功能(ajax实现) 增加二级频道功能 更多功能看截图及源码,现在还不完善,大家先将就着看.如果大家有哪些功能觉的 ...
- Orchard官方文档翻译(八) 为站点增加博客
原文地址:http://docs.orchardproject.net/Documentation/Adding-a-blog-to-your-site 想要查看文档目录请用力点击这里 最近想要学习了 ...
- 这几天有django和python做了一个多用户博客系统(可选择模板)
这几天有django和python做了一个多用户博客系统(可选择模板) 没完成,先分享下 断断续续2周时间吧,用django做了一个多用户博客系统,现在还没有做完,做分享下,以后等完善了再慢慢说 做的 ...
- python环境变量配置 - CSDN博客
一.下载: 1.官网下载python3.0系列(https://www.python.org/) 2.下载后图标为: 二.安装: Window下: 1.安装路径: 默认安装路径:C:\python35 ...
- (最新)使用爬虫刷CSDN博客访问量——亲测有效
说明:该篇博客是博主一字一码编写的,实属不易,请尊重原创,谢谢大家! 1.概述 前言:前两天刚写了第一篇博客https://blog.csdn.net/qq_41782425/article/deta ...
- Python网络数据采集(1):博客访问量统计
前言 Python中能够爬虫的包还有很多,但requests号称是“让HTTP服务人类”...口气不小,但的确也很好用. 本文是博客里爬虫的第一篇,实现一个很简单的功能:获取自己博客主页里的访问量. ...
随机推荐
- Appium+python自动化(十一)- 元素定位秘籍助你打通任督二脉 - 下卷(超详解)
简介 宏哥看你骨骼惊奇,印堂发亮,必是练武之奇才! 按照上一篇的节目预告,这一篇还是继续由宏哥给小伙伴们分享元素定位,是不是按照上一篇的秘籍修炼,是不是感觉到头顶盖好像被掀开,内气从头上冒出去,顿时觉 ...
- Storm 学习之路(二)—— Storm核心概念详解
一.Storm核心概念 1.1 Topologies(拓扑) 一个完整的Storm流处理程序被称为Storm topology(拓扑).它是一个是由Spouts 和Bolts通过Stream连接起来的 ...
- Node中的cookie的使用
1.为什么使用cookie? 因为HTTP是无状态协议.简单地说,当你浏览了一个页面,然后转到同一个网站的另一个页面,服务器无法认识到,这是同一个浏览器在访问同一个网站.每一次的访问,都是没有任何关系 ...
- Mac上使用brew update会卡住的问题
Mac上使用brew update会卡住的问题 brew默认的源是Github,会非常慢,建议换为国内的源.推荐中科大的镜像源,比较全面. 解决方案 Homebrew Homebrew源代码仓库 替换 ...
- Frameset下的frame动态隐藏
技术涉及:html+Jquery 不多说直接上图:由于是 .netcore MVC Web应用对于大家来说不一致的话可供参考哦
- sql 中 并集union和union all的使用区别
union 操作符用于合并两个或多个 SELECT 语句的结果集,并且去除重复数据,按照数据库字段的顺序进行排序. 例 SELECT NAME FROM TABLE1UNIONSELECT EMP_ ...
- epoll使用详解:epoll_create、epoll_ctl、epoll_wait、close
epoll - I/O event notification facility 在linux的网络编程中,很长的时间都在使用select来做事件触发.在linux新的内核中,有了一种替换它的机制,就是 ...
- Node.js热部署代码,实现修改代码后自动重启服务方便实时调试
写PHP等脚本语言的时候,已经习惯了修改完代码直接打开浏览器去查看最新的效果.而Node.js 只有在第一次引用时才会去解析脚本文件,以后都会直接访问内存,避免重复载入,这种设计虽然有利于提高性能,却 ...
- MyBatis从入门到精通:第一章数据库创建文件
/*创建数据库mybatis,并指定编码方式为utf8,字符比较规则为utf8_general_ci*/ CREATE DATABASE mybatis DEFAULT CHARACTER SET u ...
- vue自定义表单生成器,可根据json参数动态生成表单
介绍 form-create 是一个可以通过 JSON 生成具有动态渲染.数据收集.验证和提交功能的表单生成器.并且支持生成任何 Vue 组件.结合内置17种常用表单组件和自定义组件,再复杂的表单都可 ...