python requests、xpath爬虫增加博客访问量
这是一个分析IP代理网站,通过代理网站提供的ip去访问CSDN博客,达到以不同ip访同一博客的目的,以娱乐为主,大家可以去玩一下。
首先,准备工作,设置User-Agent:
#1.headers
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:68.0) Gecko/20100101 Firefox/68.0'}
然后百度一个IP代理网站,我选用的是https://www.kuaidaili.com/free,解析网页,提取其中的ip、端口、类型,并以list保存:
#1.获取IP地址
html=requests.get('https://www.kuaidaili.com/free').content.decode('utf8')
tree = etree.HTML(html)
ip = tree.xpath("//td[@data-title='IP']/text()")
port=tree.xpath("//td[@data-title='PORT']/text()")
model=tree.xpath("//td[@data-title='类型']/text()")
接着分析个人博客下的各篇文章的url地址,以list保存
#2.获取CSDN文章url地址 ChildrenUrl[]
url='https://blog.csdn.net/weixin_43576564'
response=requests.get(url,headers=headers)
Home=response.content.decode('utf8')
Home=etree.HTML(Home)
urls=Home.xpath("//div[@class='article-item-box csdn-tracking-statistics']/h4/a/@href")
ChildrenUrl=[]
然后通过代理ip去访问个人博客的各篇文章,通过for循环,一个ip将所有文章访问一遍,通过解析"我的博客"网页,获取总浏览量,实时监控浏览量是否发生变化,设置任务数,实时显示任务进度,通过random.randint()设置sleep时间,使得spider更加安全。全代码如下:
import os
import time
import random
import requests
from lxml import etree
#准备部分
#1.headers
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:68.0) Gecko/20100101 Firefox/68.0'} #1.获取IP地址
html=requests.get('https://www.kuaidaili.com/free').content.decode('utf8')
tree = etree.HTML(html)
ip = tree.xpath("//td[@data-title='IP']/text()")
port=tree.xpath("//td[@data-title='PORT']/text()")
model=tree.xpath("//td[@data-title='类型']/text()") #2.获取CSDN文章url地址 ChildrenUrl[]
url='https://blog.csdn.net/weixin_43576564'
response=requests.get(url,headers=headers)
Home=response.content.decode('utf8')
Home=etree.HTML(Home)
urls=Home.xpath("//div[@class='article-item-box csdn-tracking-statistics']/h4/a/@href")
ChildrenUrl=[]
for i in range(1,len(urls)):
ChildrenUrl.append(urls[i]) oldtime=time.gmtime() browses=int(input("输入需要访问次数:"))
browse=0
#3.循环伪装ip并爬取文章
for i in range(1,len(model)):
#设计代理ip
proxies={model[i]:'{}{}'.format(ip[i],port[i])}
for Curl in ChildrenUrl:
try:
browse += 1
print("进度:{}/{}".format(browse,browses),end="\t")
#遍历文章
response=requests.get(Curl,headers=headers,proxies=proxies)
#获取访问人数
look=etree.HTML(response.content)
Nuwmunber=look.xpath("//div[@class='grade-box clearfix']/dl[2]/dd/text()")
count=Nuwmunber[0].strip()
print("总浏览量:{}".format(count),end="\t")
''' 重新实现 #每个IP进行一次查询
if Curl==ChildrenUrl[5]:
ipUrl='http://www.ip138.com/'
response=requests.get(ipUrl,proxies=proxies)
iphtml=response.content
ipHtmlTree=etree.HTML(iphtml)
ipaddress=ipHtmlTree.xpath("//p[@class='result']/text()")
print(ip[i],ipaddress)
'''
i = random.randint(5, 30)
print("间隔{}秒".format(i),end="\t")
time.sleep(i)
print("当前浏览文章地址:{}".format(Curl))
if browse == browses:
print("已完成爬取任务,共消耗{}秒".format(int(time.perf_counter())))
os._exit(0) except:
print('error')
os._exit(0) #打印当前代理ip
print(proxies)
实际运行效果图: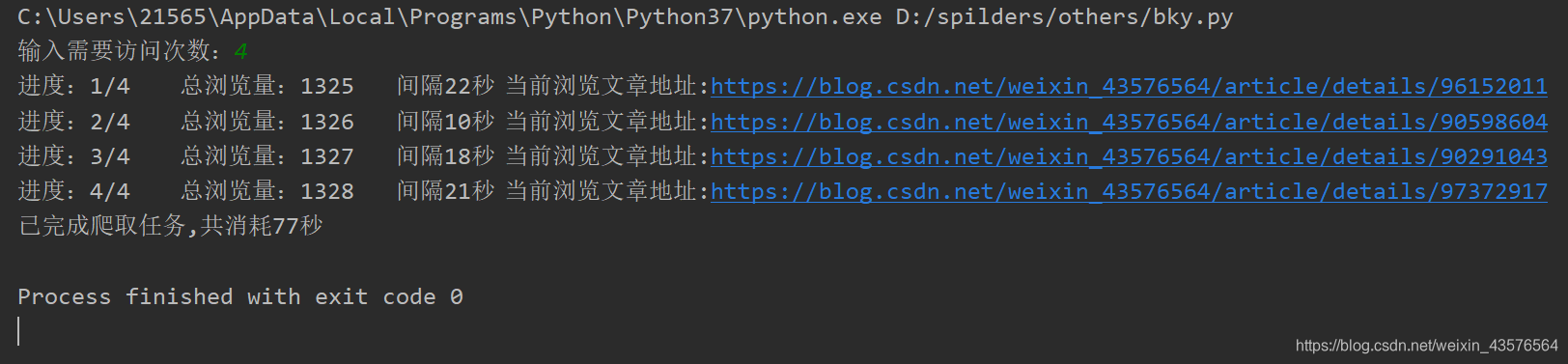
python requests、xpath爬虫增加博客访问量的更多相关文章
- Python爬虫小实践:爬取任意CSDN博客所有文章的文字内容(或可改写为保存其他的元素),间接增加博客访问量
Python并不是我的主业,当初学Python主要是为了学爬虫,以为自己觉得能够从网上爬东西是一件非常神奇又是一件非常有用的事情,因为我们可以获取一些方面的数据或者其他的东西,反正各有用处. 这两天闲 ...
- python之刷博客访问量
通过写刷访问量学习正则匹配 说明信息 说明:仅仅是为了熟悉正则表达式以及网页结构,并不赞成刷访问量操作. 1.刷访问量第一版 1.1 确定网页url结构,构造匹配模式串 首先是要确定刷的网页.第一版实 ...
- python编写的自动获取代理IP列表的爬虫-chinaboywg-ChinaUnix博客
python编写的自动获取代理IP列表的爬虫-chinaboywg-ChinaUnix博客 undefined Python多线程抓取代理服务器 | Linux运维笔记 undefined java如 ...
- 用Python和Django实现多用户博客系统(二)——UUBlog
这次又更新了一大部分功能,这次以app的形式来开发. 增加博客分类功能:博客关注.推荐功能(ajax实现) 增加二级频道功能 更多功能看截图及源码,现在还不完善,大家先将就着看.如果大家有哪些功能觉的 ...
- Orchard官方文档翻译(八) 为站点增加博客
原文地址:http://docs.orchardproject.net/Documentation/Adding-a-blog-to-your-site 想要查看文档目录请用力点击这里 最近想要学习了 ...
- 这几天有django和python做了一个多用户博客系统(可选择模板)
这几天有django和python做了一个多用户博客系统(可选择模板) 没完成,先分享下 断断续续2周时间吧,用django做了一个多用户博客系统,现在还没有做完,做分享下,以后等完善了再慢慢说 做的 ...
- python环境变量配置 - CSDN博客
一.下载: 1.官网下载python3.0系列(https://www.python.org/) 2.下载后图标为: 二.安装: Window下: 1.安装路径: 默认安装路径:C:\python35 ...
- (最新)使用爬虫刷CSDN博客访问量——亲测有效
说明:该篇博客是博主一字一码编写的,实属不易,请尊重原创,谢谢大家! 1.概述 前言:前两天刚写了第一篇博客https://blog.csdn.net/qq_41782425/article/deta ...
- Python网络数据采集(1):博客访问量统计
前言 Python中能够爬虫的包还有很多,但requests号称是“让HTTP服务人类”...口气不小,但的确也很好用. 本文是博客里爬虫的第一篇,实现一个很简单的功能:获取自己博客主页里的访问量. ...
随机推荐
- shell多线程之进程间通信
# 这是一个简单的并发程序,有如下要求: # .有两个程序a和b,希望他们能并发执行,以节约时间 # .a和b都是按照日期顺序执行,但b每日程序的前提条件是当日a的程序已经执行完毕 #解决方案: # ...
- Spark之json数据处理
-- 默认情况下,SparkContext对象在spark-shell启动时用namesc初始化.使用以下命令创建SQLContext. val sqlcontext = new org.apache ...
- What?Tomcat-竟然也算中间件?
关于 MyCat 的铺垫文章已经写了两篇了: MySQL 只能做小项目?松哥要说几句公道话! 北冥有 Data,其名为鲲,鲲之大,一个 MySQL 放不下! 今天是最后一次铺垫,后面就可以迎接大 Bo ...
- win10安装docker
配置首先需要Hyper-v和容器,这样就可以运行Linux的镜像了 如果是win10home版或者是其他版本就需要安装visulbox了, 然后去官网https://www.docker.com/pr ...
- SLAM方向公众号、知乎、博客上有哪些大V可以关注?
一.公众号 泡泡机器人:泡泡机器人由一帮热爱探索并立志推广机器人同时定位与地图构建(SLAM)技术的极客创办而成,通过原创文章.公开课等方式分享SLAM领域的数学理论.编程实践和学术前沿. 经典文 ...
- Unity Shader 屏幕后效果——边缘检测
关于屏幕后效果的控制类详细见之前写的另一篇博客: https://www.cnblogs.com/koshio0219/p/11131619.html 这篇主要是基于之前的控制类,实现另一种常见的屏幕 ...
- 关于Lombok和自动生成get set方法
在Java开发的项目里面免不了要用很多的get set 以及toString之类的方法,有时候确实是很繁琐而且做着重复共同工作,我们有没有办法来简化这个过程呢,当然有. Lombok就可以很好的解决这 ...
- 配置Python虚拟环境
最小化安装的centos7中并没有安装python3 1.安装python3 1)下载安装包: wget https://www.python.org/ftp/python/3.6.2/Python- ...
- VS2008 专业版试用到期破解 【转】
对于在win7内核下的vs2008破解,和在xp内核系统下的破解是不同的.传统(XP)的破解方式: 一.先安装试用版,然后在“添加或删除程序”里找到VS2008,点“更改/删除”就会看到一个输入序列号 ...
- 读取ClassPath下resource文件的正确姿势
1.前言 为什么要写这篇文章?身为Java程序员你有没有过每次需要读取 ClassPath 下的资源文件的时候,都要去百度一下,然后看到下面的这种答案: Thread.currentThread(). ...