提交任务到spark(以wordcount为例)
1、首先需要搭建好hadoop+spark环境,并保证服务正常。本文以wordcount为例。
2、创建源文件,即输入源。hello.txt文件,内容如下:
tom jerry
henry jim
suse lusy
注:以空格为分隔符
3、然后执行如下命令:
hadoop fs -mkdir -p /Hadoop/Input(在HDFS创建目录)
hadoop fs -put hello.txt /Hadoop/Input(将hello.txt文件上传到HDFS)
hadoop fs -ls /Hadoop/Input (查看上传的文件)
hadoop fs -text /Hadoop/Input/hello.txt (查看文件内容)
4、用spark-shell先测试一下wordcount任务。
(1)启动spark-shell,当然需要在spark的bin目录下执行,但是这里我配置了环境变量。

(2)然后直接输入scala语句:
val file=sc.textFile("hdfs://hacluster/Hadoop/Input/hello.txt")
val rdd = file.flatMap(line => line.split(" ")).map(word => (word,1)).reduceByKey(_+_)
rdd.collect()
rdd.foreach(println)
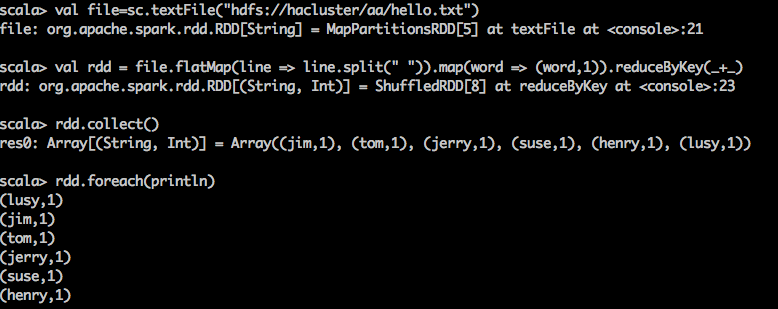
ok,测试通过。
5、Scala实现单词计数
1 package com.example.spark
2
3 /**
4 * User: hadoop
5 * Date: 2017/8/17 0010
6 * Time: 10:20
7 */
8 import org.apache.spark.SparkConf
9 import org.apache.spark.SparkContext
10 import org.apache.spark.SparkContext._
11
12 /**
13 * 统计字符出现次数
14 */
15 object ScalaWordCount {
16 def main(args: Array[String]) {
17 if (args.length < 1) {
18 System.err.println("Usage: <file>")
19 System.exit(1)
20 }
21
22 val conf = new SparkConf()
23 val sc = new SparkContext(conf)
24 val line = sc.textFile(args(0))
25
26 line.flatMap(_.split(" ")).map((_, 1)).reduceByKey(_+_).collect().foreach(println)
27
28 sc.stop()
29 }
30 }
6、用java实现wordcount
package com.example.spark; import java.util.Arrays;
import java.util.List;
import java.util.regex.Pattern; import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction; import scala.Tuple2; public final class WordCount {
private static final Pattern SPACE = Pattern.compile(" "); public static void main(String[] args) throws Exception {
if (args.length < 1) {
System.err.println("Usage: JavaWordCount <file>");
System.exit(1);
}
SparkConf conf = new SparkConf().setAppName("JavaWordCount");
JavaSparkContext sc = new JavaSparkContext(conf);
JavaRDD<String> lines = sc.textFile(args[0],1);
JavaRDD<String> words = lines.flatMap(new FlatMapFunction<String, String>() { private static final long serialVersionUID = 1L; @Override
public Iterable<String> call(String s) {
return Arrays.asList(SPACE.split(s));
}
}); JavaPairRDD<String, Integer> ones = words.mapToPair(new PairFunction<String, String, Integer>() { private static final long serialVersionUID = 1L; @Override
public Tuple2<String, Integer> call(String s) {
return new Tuple2<String, Integer>(s, 1);
}
}); JavaPairRDD<String, Integer> counts = ones.reduceByKey(new Function2<Integer, Integer, Integer>() { private static final long serialVersionUID = 1L; @Override
public Integer call(Integer i1, Integer i2) {
return i1 + i2;
}
}); List<Tuple2<String, Integer>> output = counts.collect();
for (Tuple2<?, ?> tuple : output) {
System.out.println(tuple._1() + ": " + tuple._2());
} sc.stop();
}
}
7、IDEA打包。
(1)File ---> Project Structure
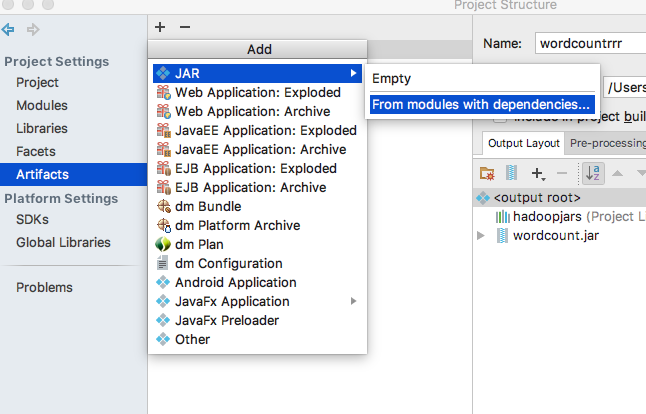
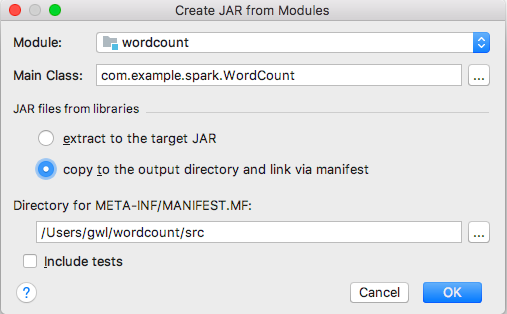
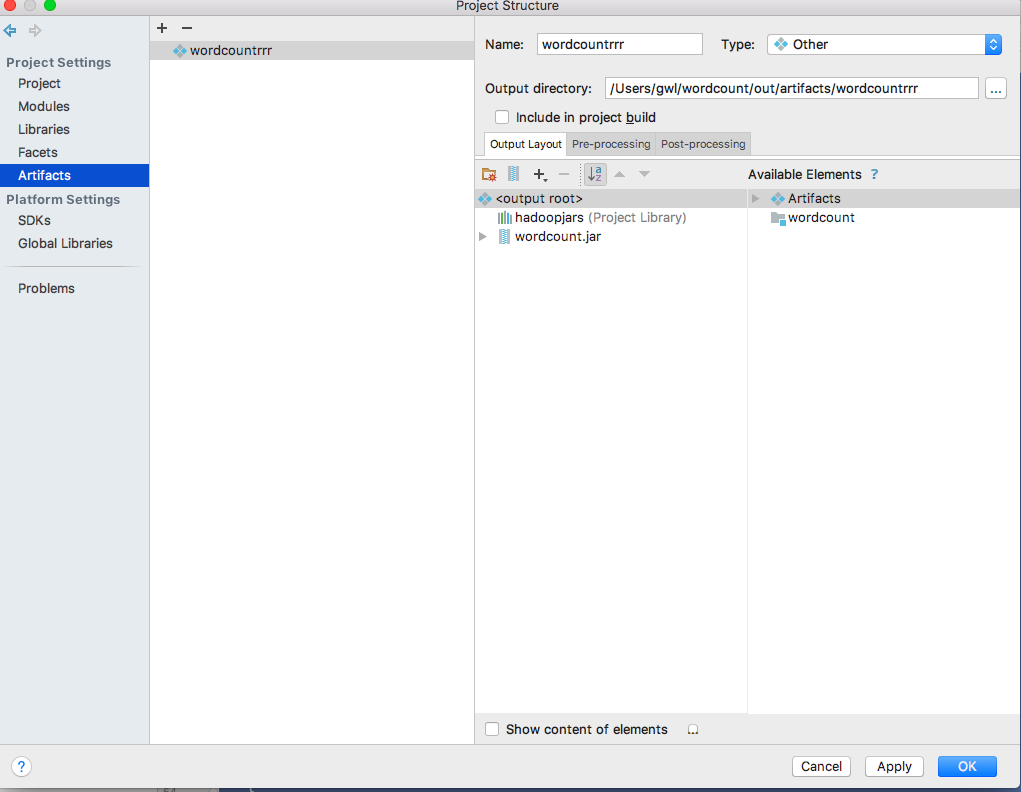
点击ok,配置完成后,在菜单栏中选择Build->Build Artifacts...,然后使用Build等命令打包。打包完成后会在状态栏中显示“Compilation completed successfully...”的信息,去jar包输出路径下查看jar包,如下所示。
将这个wordcount.jar上传到集群的节点上,scp wordcount.jar root@10.57.22.244:/opt/ 输入虚拟机root密码。
8、运行jar包。
本文以spark on yarn模式运行jar包。
执行命令运行javawordcount:spark-submit --master yarn-client --class com.example.spark.WordCount --executor-memory 1G --total-executor-cores 2 /opt/wordcount.jar hdfs://hacluster/aa/hello.txt
执行命令运行scalawordcount:spark-submit --master yarn-client --class com.example.spark.ScalaWordCount --executor-memory 1G --total-executor-cores 2 /opt/wordcount.jar hdfs://hacluster/aa/hello.txt
本文以java的wordcount为演示对象,如下图:

以上是直接以spark-submit方式提交任务,下面介绍一种以java web的方式提交。
9、以Java Web的方式提交任务到spark。
用spring boot搭建java web框架,实现代码如下:
1)新建maven项目spark-submit
2)pom.xml文件内容,这里要注意spark的依赖jar包要与scala的版本相对应,如spark-core_2.11,这后面2.11就是你安装的scala的版本
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion> <parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>1.4.1.RELEASE</version>
</parent>
<groupId>wordcount</groupId>
<artifactId>spark-submit</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<start-class>com.example.spark.SparkSubmitApplication</start-class>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<java.version>1.8</java.version>
<commons.version>3.4</commons.version>
<org.apache.spark-version>2.1.0</org.apache.spark-version>
</properties> <dependencies>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-lang3</artifactId>
<version>${commons.version}</version>
</dependency> <dependency>
<groupId>org.apache.tomcat.embed</groupId>
<artifactId>tomcat-embed-jasper</artifactId>
<scope>provided</scope>
</dependency> <dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>com.jayway.jsonpath</groupId>
<artifactId>json-path</artifactId>
</dependency> <dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
<exclusions>
<exclusion>
<artifactId>spring-boot-starter-tomcat</artifactId>
<groupId>org.springframework.boot</groupId>
</exclusion>
</exclusions>
</dependency> <dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jetty</artifactId>
<exclusions>
<exclusion>
<groupId>org.eclipse.jetty.websocket</groupId>
<artifactId>*</artifactId>
</exclusion>
</exclusions>
</dependency> <dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jetty</artifactId>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>javax.servlet</groupId>
<artifactId>jstl</artifactId>
</dependency>
<dependency>
<groupId>org.eclipse.jetty</groupId>
<artifactId>apache-jsp</artifactId>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-solr</artifactId>
</dependency> <dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency> <dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>javax.servlet</groupId>
<artifactId>jstl</artifactId>
</dependency> <dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>${org.apache.spark-version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>${org.apache.spark-version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.11</artifactId>
<version>${org.apache.spark-version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.11</artifactId>
<version>${org.apache.spark-version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.3</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka_2.11</artifactId>
<version>1.6.3</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-graphx_2.11</artifactId>
<version>${org.apache.spark-version}</version>
</dependency>
<dependency>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.0.0</version>
</dependency> <dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-core</artifactId>
<version>2.6.5</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>2.6.5</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-annotations</artifactId>
<version>2.6.5</version>
</dependency> </dependencies>
<packaging>war</packaging> <repositories>
<repository>
<id>spring-snapshots</id>
<name>Spring Snapshots</name>
<url>https://repo.spring.io/snapshot</url>
<snapshots>
<enabled>true</enabled>
</snapshots>
</repository>
<repository>
<id>spring-milestones</id>
<name>Spring Milestones</name>
<url>https://repo.spring.io/milestone</url>
<snapshots>
<enabled>false</enabled>
</snapshots>
</repository>
<repository>
<id>maven2</id>
<url>http://repo1.maven.org/maven2/</url>
</repository>
</repositories>
<pluginRepositories>
<pluginRepository>
<id>spring-snapshots</id>
<name>Spring Snapshots</name>
<url>https://repo.spring.io/snapshot</url>
<snapshots>
<enabled>true</enabled>
</snapshots>
</pluginRepository>
<pluginRepository>
<id>spring-milestones</id>
<name>Spring Milestones</name>
<url>https://repo.spring.io/milestone</url>
<snapshots>
<enabled>false</enabled>
</snapshots>
</pluginRepository>
</pluginRepositories> <build>
<plugins>
<plugin>
<artifactId>maven-war-plugin</artifactId>
<configuration>
<warSourceDirectory>src/main/webapp</warSourceDirectory>
</configuration>
</plugin> <plugin>
<groupId>org.mortbay.jetty</groupId>
<artifactId>jetty-maven-plugin</artifactId>
<configuration>
<systemProperties>
<systemProperty>
<name>spring.profiles.active</name>
<value>development</value>
</systemProperty>
<systemProperty>
<name>org.eclipse.jetty.server.Request.maxFormContentSize</name>
<!-- -1代表不作限制 -->
<value>600000</value>
</systemProperty>
</systemProperties>
<useTestClasspath>true</useTestClasspath>
<webAppConfig>
<contextPath>/</contextPath>
</webAppConfig>
<connectors>
<connector implementation="org.eclipse.jetty.server.nio.SelectChannelConnector">
<port>7080</port>
</connector>
</connectors>
</configuration>
</plugin>
</plugins> </build> </project>
(3)SubmitJobToSpark.java
package com.example.spark; import org.apache.spark.deploy.SparkSubmit; /**
* @author kevin
*
*/
public class SubmitJobToSpark { public static void submitJob() {
String[] args = new String[] { "--master", "yarn-client", "--name", "test java submit job to spark", "--class", "com.example.spark.WordCount", "/opt/wordcount.jar", "hdfs://hacluster/aa/hello.txt" };
SparkSubmit.main(args);
}
}
(4)SparkController.java
package com.example.spark.web.controller; import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse; import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.stereotype.Controller;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestMethod;
import org.springframework.web.bind.annotation.ResponseBody; import com.example.spark.SubmitJobToSpark; @Controller
@RequestMapping("spark")
public class SparkController {
private Logger logger = LoggerFactory.getLogger(SparkController.class); @RequestMapping(value = "sparkSubmit", method = { RequestMethod.GET, RequestMethod.POST })
@ResponseBody
public String sparkSubmit(HttpServletRequest request, HttpServletResponse response) {
logger.info("start submit spark tast...");
SubmitJobToSpark.submitJob();
return "hello";
} }
5)将项目spark-submit打成war包部署到Master节点tomcat上,访问如下请求:
http://10.57.22.244:9090/spark/sparkSubmit
在tomcat的log中能看到计算的结果。
提交任务到spark(以wordcount为例)的更多相关文章
- 编写Spark的WordCount程序并提交到集群运行[含scala和java两个版本]
编写Spark的WordCount程序并提交到集群运行[含scala和java两个版本] 1. 开发环境 Jdk 1.7.0_72 Maven 3.2.1 Scala 2.10.6 Spark 1.6 ...
- 提交任务到Spark
1.场景 在搭建好Hadoop+Spark环境后,现准备在此环境上提交简单的任务到Spark进行计算并输出结果.搭建过程:http://www.cnblogs.com/zengxiaoliang/p/ ...
- 提交任务到spark master -- 分布式计算系统spark学习(四)
部署暂时先用默认配置,我们来看看如何提交计算程序到spark上面. 拿官方的Python的测试程序搞一下. qpzhang@qpzhangdeMac-mini:~/project/spark-1.3. ...
- 1.spark的wordcount解析
一.Eclipse(scala IDE)开发local和cluster (一). 配置开发环境 要在本地安装好java和scala. 由于spark1.6需要scala 2.10.X版本的.推荐 2 ...
- [转] 用SBT编译Spark的WordCount程序
问题导读: 1.什么是sbt? 2.sbt项目环境如何建立? 3.如何使用sbt编译打包scala? [sbt介绍 sbt是一个代码编译工具,是scala界的mvn,可以编译scala,java等,需 ...
- Spark 实现wordcount
配置完spark之后,使用spark实现wordcount,这一部分完全参考<深入理解Spark:核心思想与源码分析> 依然使用hadoop wordcountTest的那几个txt文件 ...
- 用SBT编译Spark的WordCount程序
问题导读: 1.什么是sbt? 2.sbt项目环境如何建立? 3.如何使用sbt编译打包scala? sbt介绍 sbt是一个代码编译工具,是scala界的mvn,可以编译scala,java等,需要 ...
- spark 例子wordcount topk
spark 例子wordcount topk 例子描述: [单词计算wordcount ] [词频排序topk] 单词计算在代码方便很简单,基本大体就三个步骤 拆分字符串 以需要进行记数的单位为K,自 ...
- .Net for Spark 实现 WordCount 应用及调试入坑详解
.Net for Spark 实现WordCount应用及调试入坑详解 1. 概述 iNeuOS云端操作系统现在具备物联网.视图业务建模.机器学习的功能,但是缺少一个计算平台产品.最近在调研使用 ...
随机推荐
- Delegate,Block,Notification, KVC,KVO,Target-Action
Target-Action: 目标-动作机制,所有的UIControl及子类都是这个机制:原理:在对象产生某个事件的特定时刻,给一个对象发送一个消息:类内部target去执行action方法 Dele ...
- DNS域名解析服务及其配置
一.背景 到 20 世纪 70 年代末,ARPAnet 是一个拥有几百台主机的很小很友好的网络.仅需要一个名为 HOSTS.TXT 的文件就能容纳所有需要了解的主机信息:它包含了所有连接到 ARPAn ...
- TomatoLog-1.1.0实现ILoggerFactory
TomatoLog TomatoLog 是一个基于 .NETCore 平台的产品. The TomatoLog 是一个中间件,包含客户端.服务端,非常容易使用和部署. 客户端实现了ILoggerFac ...
- Flink的Job启动JobManager端(源码分析)
通过前面的文章了解到 Driver将用户代码转换成streamGraph再转换成Jobgraph后向Jobmanager端提交 JobManager启动以后会在Dispatcher.java起来RPC ...
- python 3.7.4下载与安装的问题
发病时间:2019 年 8 月12 日 周一 1.操作系统环境: Win10 64位 2.pyhon版本3.7.4 python官网地址:www.python.org 本机下载的文件名为:python ...
- Vue 关于多个父子组件嵌套传值
prop 是单向绑定的:当父组件的属性变化时,将传导给子组件,但是不会反过来.这是为了防止子组件无意修改了父组件的状态——这会让应用的数据流难以理解. props: { selectMember: { ...
- CAS及其ABA问题
CAS.volatile是JUC包实现同步的基础.Synchronized下的偏向锁.轻量级锁的获取.释放,lock机制下锁的获取.释放,获取失败后线程的入队等操作都是CAS操作锁标志位.state. ...
- 使用SpringSecurity保护程序安全
首先,引入依赖: <dependency> <groupId>org.springframework.boot</groupId> <artifactId&g ...
- IdentityServer3学习记录(搭建IdentityServer项目)
记录下自己尝试搭建identityServer3的过程,便于自己记录遗忘时翻看,也能便于刚接触的新手简单了解下搭建的过程. 更详细的可以参考 https://www.jianshu.com/p/792 ...
- 【selenium】- 常见浏览器的启动
本文由小编根据慕课网视频亲自整理,转载请注明出处和作者. 1. Firefox启动 webdriver自带了firefox浏览器的驱动,所以不需要设置它的驱动. 如果firefox没有安装在默认路径, ...