spark 在yarn模式下提交作业
1、spark在yarn模式下提交作业需要启动hdfs集群和yarn,具体操作参照:hadoop 完全分布式集群搭建
2、spark需要配置yarn和hadoop的参数目录
将spark/conf/目录下的spark-env.sh.template文件复制一份,加入配置:
YARN_CONF_DIR=/opt/hadoop/hadoop-2.8.3/etc/hadoop
HADOOP_CONF_DIR=/opt/hadoop/hadoop-2.8.3/etc/hadoop
3、将spark整个目录分发到hdfs集群中每台机器上,分发命令可以参考:linux rsync
如果不想用rsync也可以直接用scp -r拷贝,测试环境下差别不大。
4、提交作业测试
bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn --deploy-mode client ./examples/jars/spark-examples_2.11-2.4.4.jar 200
正常情况下很快就能计算完成:

在yarn的UI可以监控到执行的作业:
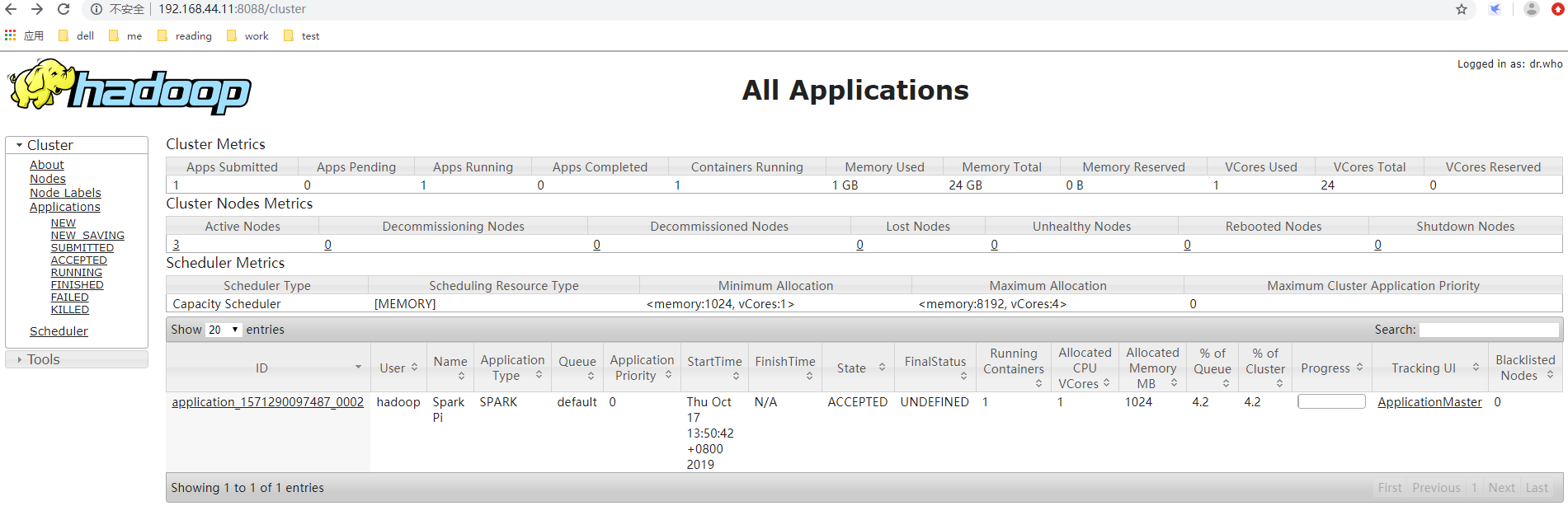
5、spark参数优先级
Spark加载属性参数的优先顺序是:
(1)直接在SparkConf设置的属性参数
(2)通过 spark-submit 或 spark-shell 方式传递的属性参数
(3)最后加载 spark-defaults.conf 配置文件的属性参数
如果在程序里指定了SparkConf的参数,则spark缺省参数以及命令行参数都将失效,如果想灵活一下,我们可以在SparkConf加载缺省配置(spark-defaults.conf),然后在命令方式下覆盖参数。
val conf: SparkConf = new SparkConf(true).setAppName("SparkWordCount")
master这个参数就可以指定local或者yarn等模式,但是name参数在命令指定是无效的,因为已经内置了。
bin/spark-submit --master yarn --name myWordCount --class com.home.spark.WordCount --executor-memory 512M ~/sparkWordCount.jar hdfs://vmhome10.com:9000/input
spark 在yarn模式下提交作业的更多相关文章
- spark on yarn模式下配置spark-sql访问hive元数据
spark on yarn模式下配置spark-sql访问hive元数据 目的:在spark on yarn模式下,执行spark-sql访问hive的元数据.并对比一下spark-sql 和hive ...
- spark on yarn模式下内存资源管理(笔记1)
问题:1. spark中yarn集群资源管理器,container资源容器与集群各节点node,spark应用(application),spark作业(job),阶段(stage),任务(task) ...
- spark on yarn模式下内存资源管理(笔记2)
1.spark 2.2内存占用计算公式 https://blog.csdn.net/lingbo229/article/details/80914283 2.spark on yarn内存分配** 本 ...
- Spark在StandAlone模式下提交任务,spark.rpc.message.maxSize太小而出错
1.错误信息org.apache.spark.SparkException: Job aborted due to stage failure:Serialized task 32:5 was 172 ...
- spark跑YARN模式或Client模式提交任务不成功(application state: ACCEPTED)
不多说,直接上干货! 问题详情 电脑8G,目前搭建3节点的spark集群,采用YARN模式. master分配2G,slave1分配1G,slave2分配1G.(在安装虚拟机时) export SPA ...
- spark跑YARN模式或Client模式提交任务不成功(application state: ACCEPTED)(转)
不多说,直接上干货! 问题详情 电脑8G,目前搭建3节点的spark集群,采用YARN模式. master分配2G,slave1分配1G,slave2分配1G.(在安装虚拟机时) export SPA ...
- flink on yarn模式下两种提交job方式
yarn集群搭建,参见hadoop 完全分布式集群搭建 通过yarn进行资源管理,flink的任务直接提交到hadoop集群 1.hadoop集群启动,yarn需要运行起来.确保配置HADOOP_HO ...
- Spark on YARN模式的安装(spark-1.6.1-bin-hadoop2.6.tgz + hadoop-2.6.0.tar.gz)(master、slave1和slave2)(博主推荐)
说白了 Spark on YARN模式的安装,它是非常的简单,只需要下载编译好Spark安装包,在一台带有Hadoop YARN客户端的的机器上运行即可. Spark on YARN简介与运行wor ...
- spark on yarn模式里需要有时手工释放linux内存
为什么要提出这个问题? spark跑YARN模式或Client模式提交任务不成功(application state: ACCEPTED) 然后执行 [spark@master spark--bin- ...
随机推荐
- kmeans均值聚类算法实现
这个算法中文名为k均值聚类算法,首先我们在二维的特殊条件下讨论其实现的过程,方便大家理解. 第一步.随机生成质心 由于这是一个无监督学习的算法,因此我们首先在一个二维的坐标轴下随机给定一堆点,并随即给 ...
- 从零开始的SpringBoot项目搭建
前言 今天是我加入博客园的第一天今天刚好学习到SpringBoot,就顺便记录一下吧 一.创建项目 1.创建工程 ① 通过File > New > Project,新建工程,选择Sprin ...
- java 读取 excel 表格内容
一.添加依赖 <dependency> <groupId>org.apache.poi</groupId> <artifactId>poi</ar ...
- linux学习(七)Shell编程中的变量
目录 shell编程的建立 shell的hello world! Shell的环境变量 使用和设置环境变量 Shell的系统变量 用户自定义变量 @(Shell编程) shell编程的建立 [root ...
- 数据结构笔记1(c++)_指针
一.数据结构概述 1.定义: 我们如何把现实中大量而复杂的问题,以特定的数据类型和特定的存储结构保存到主存储器(内存)中,以及在此基础上为实现某个功能(比如查找某个元素,删除某个元素,对所有元素进行排 ...
- 如何在mac版本的python里安装pip
mac里面python自带easy_install,在终端里面执行sudo easy_install pip.运行完可以用pip help测试一下是否安装成功,成功安装后,直接pip install ...
- [Linux] nginx记录多种响应时间
官网介绍$request_time – Full request time, starting when NGINX reads the first byte from the client and ...
- Linux部署NFS服务共享文件
NFS(网络文件系统)用于linux共享文件 第1步:配置所需要的环境 使用两台Linux主机 主机名称 操作系统 IP地址 NFS Centos7 192.168.218.139 NFSa Cent ...
- Linux下磁盘实战操作命令
企业真实场景由于硬盘常年大量读写,经常会出现坏盘,需要更换硬盘.或者由于磁盘空间不足,需添加新硬盘,新添加的硬盘需要经过格式化.分区才能被 Linux 系统所使用. 虚拟机 CentOS 7 Linu ...
- 【hdu4045】Machine scheduling(dp+第二类斯特林数)
传送门 题意: 从\(n\)个人中选\(r\)个出来,但每两个人的标号不能少于\(k\). 再将\(r\)个人分为不超过\(m\)个集合. 问有多少种方案. 思路: 直接\(dp\)预处理出从\(n\ ...