Python 爬取豆瓣TOP250实战
学习爬虫之路,必经的一个小项目就是爬取豆瓣的TOP250了,首先我们进入TOP250的界面看看。
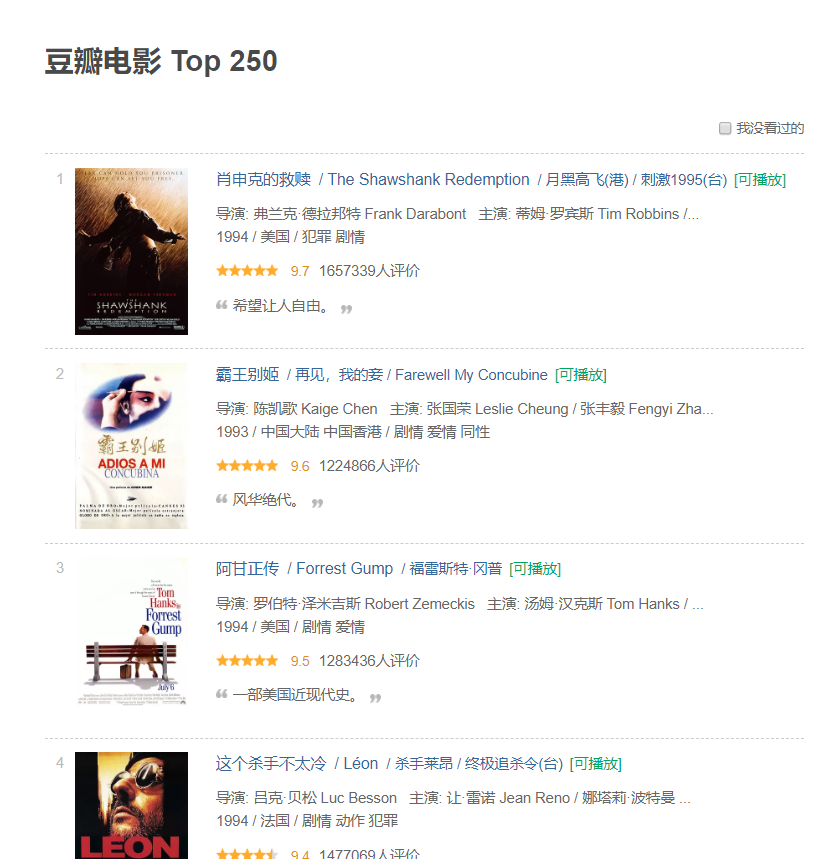
可以看到每部电影都有比较全面的简介。其中包括电影名、导演、评分等。
接下来,我们就爬取这些数据,并将这些数据制成EXCEL表格方便查看。
首先,我们用requests库请求一下该网页,并返回他的text格式。
请求并返回成功!
接下来,我们提取我们所需要的网页元素。
点击“肖申克救赎”的检查元素。
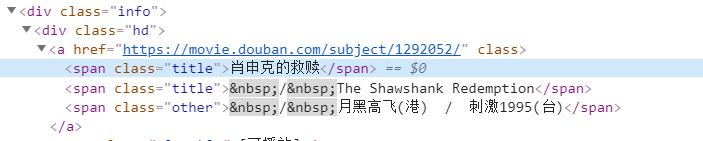
发现它在div class = "hd" -> span class = "title"里,所以我们import beautifulsoup,来定位该元素。
同时,用相同的方法定位电影的评价人数和评分以及短评。
代码如下:
soup = BeautifulSoup(res.text, 'html.parser')
names = []
scores = []
comments = []
result = []
#获取电影的所有名字
res_name = soup.find_all('div',class_="hd")
for i in res_name:
a=i.a.span.text
names.append(a)
#获取电影的评分
res_scores = soup.find_all('span',class_='rating_num')
for i in res_scores:
a=i.get_text()
scores.append(a)
#获取电影的短评
ol = soup.find('ol', class_='grid_view')
for i in ol.find_all('li'):
info = i.find('span', attrs={'class': 'inq'}) # 短评
if info:
comments.append(info.get_text())
else:
comments.append("无")
return names,scores,comments
Ok,现在,我们所需要的数据都存在三个列表里面,names,scores,comments。
我们将这三个列表存入EXCEL文件里,方便查看。
调用WorkBook方法
wb = Workbook()
filename = 'top250.xlsx'
ws1 = wb.active
ws1.title = 'TOP250'
for (i, m, o) in zip(names,scores,comments):
col_A = 'A%s' % (names.index(i) + 1)
col_B = 'B%s' % (names.index(i) + 1)
col_C = 'C%s' % (names.index(i) + 1)
ws1[col_A] = i
ws1[col_B] = m
ws1[col_C] = o
wb.save(filename=filename)
运行结束后,会生成一个.xlsx的文件,我们来看看效果:
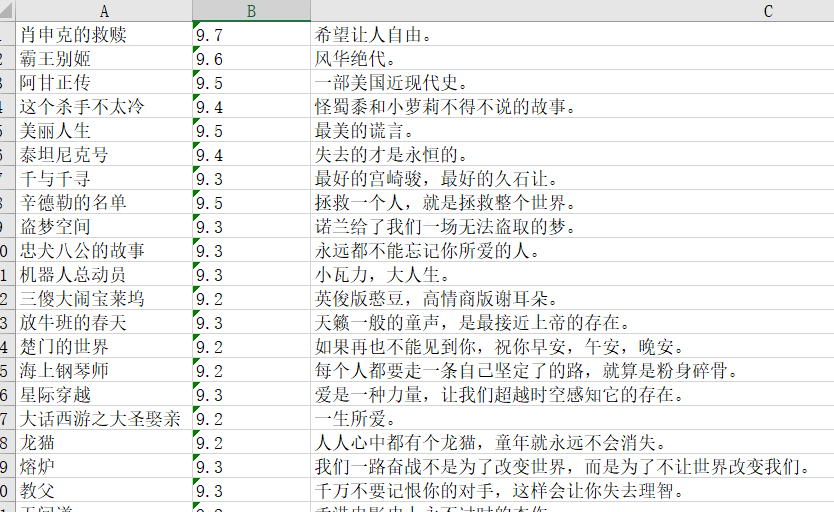
Very Beatuful! 以后想学习之余想放松一下看看好的电影,就可以在上面直接查找啦。
以下是我的源代码:
import requests
from bs4 import BeautifulSoup
from openpyxl import Workbook def open_url(url):
res = requests.get(url)
return res def get_movie(res):
soup = BeautifulSoup(res.text, 'html.parser') names = []
scores = []
comments = []
result = []
#获取电影的所有名字
res_name = soup.find_all('div',class_="hd")
for i in res_name:
a=i.a.span.text
names.append(a) #获取电影的评分
res_scores = soup.find_all('span',class_='rating_num')
for i in res_scores:
a=i.get_text()
scores.append(a) #获取电影的短评
ol = soup.find('ol', class_='grid_view')
for i in ol.find_all('li'): info = i.find('span', attrs={'class': 'inq'}) # 短评
if info:
comments.append(info.get_text())
else:
comments.append("无") return names,scores,comments def get_page(res):
soup = BeautifulSoup(res.text,'html.parser')
#获取页数
page_num = soup.find('span',class_ ='next').previous_sibling.previous_sibling.text
return int(page_num) def main():
host = 'https://movie.douban.com/top250'
res = open_url(host)
pages = get_page(res)
#print(pages)
names =[]
scores = []
comments = []
for i in range(pages):
url = host + '?start='+ str(25*i)+'&filter='
#print(url)
result = open_url(url)
#print(result)
a,b,c = get_movie(result)
#print(a,b,c)
names.extend(a)
scores.extend(b)
comments.extend(c)
# print(names)
# print(scores)
# print(comments)
wb = Workbook()
filename = 'top250.xlsx'
ws1 = wb.active
ws1.title = 'TOP250'
for (i, m, o) in zip(names,scores,comments):
col_A = 'A%s' % (names.index(i) + 1)
col_B = 'B%s' % (names.index(i) + 1)
col_C = 'C%s' % (names.index(i) + 1)
ws1[col_A] = i
ws1[col_B] = m
ws1[col_C] = o
wb.save(filename=filename) if __name__ == '__main__':
main()
生成EXCEL文件还有很多种方法,下次分享Pandas生成EXCEL文件的方法~
Python 爬取豆瓣TOP250实战的更多相关文章
- python爬取豆瓣top250的电影数据并存入excle
爬取网址: https://movie.douban.com/top250 一:爬取思路(新手可以看一下) : 1:定义两个函数,一个get_page函数爬取数据,一个save函数保存数据,mian中 ...
- Python爬取豆瓣音乐存储MongoDB数据库(Python爬虫实战1)
1. 爬虫设计的技术 1)数据获取,通过http获取网站的数据,如urllib,urllib2,requests等模块: 2)数据提取,将web站点所获取的数据进行处理,获取所需要的数据,常使用的技 ...
- 零基础爬虫----python爬取豆瓣电影top250的信息(转)
今天利用xpath写了一个小爬虫,比较适合一些爬虫新手来学习.话不多说,开始今天的正题,我会利用一个案例来介绍下xpath如何对网页进行解析的,以及如何对信息进行提取的. python环境:pytho ...
- python爬取豆瓣电影Top250(附完整源代码)
初学爬虫,学习一下三方库的使用以及简单静态网页的分析.就跟着视频写了一个爬取豆瓣Top250排行榜的爬虫. 网页分析 我个人感觉写爬虫最重要的就是分析网页,找到网页的规律,找到自己需要内容所在的地方, ...
- Python爬取豆瓣电影top
Python爬取豆瓣电影top250 下面以四种方法去解析数据,前面三种以插件库来解析,第四种以正则表达式去解析. xpath pyquery beaufifulsoup re 爬取信息:名称 评分 ...
- Python爬取豆瓣指定书籍的短评
Python爬取豆瓣指定书籍的短评 #!/usr/bin/python # coding=utf-8 import re import sys import time import random im ...
- 利用Python爬取豆瓣电影
目标:使用Python爬取豆瓣电影并保存MongoDB数据库中 我们先来看一下通过浏览器的方式来筛选某些特定的电影: 我们把URL来复制出来分析分析: https://movie.douban.com ...
- 基础爬虫,谁学谁会,用requests、正则表达式爬取豆瓣Top250电影数据!
爬取豆瓣Top250电影的评分.海报.影评等数据! 本项目是爬虫中最基础的,最简单的一例: 后面会有利用爬虫框架来完成更高级.自动化的爬虫程序. 此项目过程是运用requests请求库来获取h ...
- Python爬取豆瓣《复仇者联盟3》评论并生成乖萌的格鲁特
代码地址如下:http://www.demodashi.com/demo/13257.html 1. 需求说明 本项目基于Python爬虫,爬取豆瓣电影上关于复仇者联盟3的所有影评,并保存至本地文件. ...
随机推荐
- 控制执行流程之break和continue
1.在任何迭代语句的主体部分,都可以用break和continue来控制程序执行流程. 2.注意: break:用于强行退出循环, 不执行循环中剩余的语句:continue:停止当前的循环,执行下一次 ...
- Day 25 网络基础
1:网络的重要性: 所有的系统都有网络! 我们的生活已经离不开网络. 运维生涯50%的生产故障都是网络故障! 2:教室这么多的电脑如何上网的? 网卡(mac地址) 有线(双绞线传播电信号)双向,同时收 ...
- SQL手工注入进阶篇
0.前言 上一篇我们介绍了SQL手工注入的流程以及步骤,但在实际的安全问题以及CTF题目中,查询语句多种多样,而且是肯定会对用户的输入进行一个安全过滤的,而这些过滤并不一定是百分百安全的,如何利用一些 ...
- Java String 对象,你真的了解了吗?
String 对象的实现 String对象是 Java 中使用最频繁的对象之一,所以 Java 公司也在不断的对String对象的实现进行优化,以便提升String对象的性能,看下面这张图,一起了解一 ...
- [Full-stack] 一切皆在云上 - AWS
一元课程:https://edu.51cto.com/center/course/lesson/index?id=181407[非常好] Based on AWS Lambda. 包含:DevOps ...
- 线上CPU飙升100%问题排查,一篇足矣
一.引子 对于互联网公司,线上CPU飙升的问题很常见(例如某个活动开始,流量突然飙升时),按照本文的步骤排查,基本1分钟即可搞定!特此整理排查方法一篇,供大家参考讨论提高. 二.问题复现 线上系统突然 ...
- 浅谈HDFS(一)
产生背景及定义 HDFS:分布式文件系统,用于存储文件,主要特点在于其分布式,即有很多服务器联合起来实现其功能,集群中的服务器各有各的角色 随着数据量越来越大,一个操作系统存不下所有的数据,那么就分配 ...
- 【Django】ajax(多对多表单)
1.前后端交互 <div class="shade hide"></div> <!--遮罩层,全屏--> <div class=" ...
- 浅谈JavaScript的闭包原理
在一般的教程里,都谈到子作用域可以访问到父级作用域,进而访问到父级作用域中的变量,具体是如何实现的,就不得不提及到函数堆栈和执行上下文. 举个例子,一个简单的闭包: 首先,我们可以知道,examp ...
- CSS 换行
默认情况下,元素的属性是 white-space:normal:自动换行:(不把单词截断,会把单词看作一个整体) -----但是但是但是但是..当元素中的内容是一对没有空格的字符/数字时,超过容器宽度 ...