Go语言 中文分词技术使用技巧(一)
分词技术就是搜索引擎针对用户提交查询的关键词串进行的查询处理后根据用户的关键词串用各种匹配方法进行分词的一种技术。
中文分词(Chinese Word Segmentation)指的是将一个汉字序列(句子)切分成一个一个的单独的词,分词就是将连续的字序列按照一定的规则重新组合成词序列的过程。
现在分词方法大致有三种:基于字符串配置的分词方法、基于理解的分词方法和基于统计的分词方法。
今天为大家分享一个国内使用人数最多的中文分词工具GoJieba,源代码地址:GoJieba ,官方文档:GoJieba官方文档


官方介绍
- 支持多种分词方式,包括: 最大概率模式, HMM新词发现模式, 搜索引擎模式, 全模式
- 核心算法底层由C++实现,性能高效。
- 无缝集成到 Bleve 到进行搜索引擎的中文分词功能。
- 字典路径可配置,NewJieba(...string), NewExtractor(...string) 可变形参,当参数为空时使用默认词典(推荐方式)
模式扩展
- 精确模式:将句子精确切开,适合文本字符分析
- 全模式:把短语中所有的可以组成词语的部分扫描出来,速度非常快,会有歧义
- 搜索引擎模式:精确模式基础上,对长词再次切分,提升引擎召回率,适用于搜索引擎分词
主要算法
- 前缀词典实现高效的词图扫描,生成句子中汉字所有可能出现成词情况所构成的有向无环图(DAG)
- 采用动态规划查找最大概率路径,找出基于词频最大切分组合
- 对于未登录词,采用汉字成词能力的HMM模型,采用Viterbi算法计算
- 基于Viterbi算法做词性标注
- 基于TF-IDF和TextRank模型抽取关键词
编码实现
package main
import (
"fmt"
"github.com/yanyiwu/gojieba"
"strings"
)
func main() {
var seg = gojieba.NewJieba()
defer seg.Free()
var useHmm = true
var separator = "|"
var resWords []string
var sentence = "万里长城万里长"
resWords = seg.CutAll(sentence)
fmt.Printf("%s\t全模式:%s \n", sentence, strings.Join(resWords, separator))
resWords = seg.Cut(sentence, useHmm)
fmt.Printf("%s\t精确模式:%s \n", sentence, strings.Join(resWords, separator))
var addWord = "万里长"
seg.AddWord(addWord)
fmt.Printf("添加新词:%s\n", addWord)
resWords = seg.Cut(sentence, useHmm)
fmt.Printf("%s\t精确模式:%s \n", sentence, strings.Join(resWords, separator))
sentence = "北京鲜花速递"
resWords = seg.Cut(sentence, useHmm)
fmt.Printf("%s\t新词识别:%s \n", sentence, strings.Join(resWords, separator))
sentence = "北京鲜花速递"
resWords = seg.CutForSearch(sentence, useHmm)
fmt.Println(sentence, "\t搜索引擎模式:", strings.Join(resWords, separator))
sentence = "北京市朝阳公园"
resWords = seg.Tag(sentence)
fmt.Println(sentence, "\t词性标注:", strings.Join(resWords, separator))
sentence = "鲁迅先生"
resWords = seg.CutForSearch(sentence, !useHmm)
fmt.Println(sentence, "\t搜索引擎模式:", strings.Join(resWords, separator))
words := seg.Tokenize(sentence, gojieba.SearchMode, !useHmm)
fmt.Println(sentence, "\tTokenize Search Mode 搜索引擎模式:", words)
words = seg.Tokenize(sentence, gojieba.DefaultMode, !useHmm)
fmt.Println(sentence, "\tTokenize Default Mode搜索引擎模式:", words)
word2 := seg.ExtractWithWeight(sentence, 5)
fmt.Println(sentence, "\tExtract:", word2)
return
}
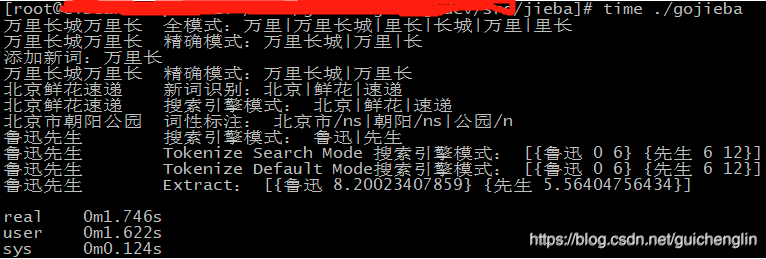
运行结果
go build -o gojieba
time ./gojieba
万里长城万里长 全模式:万里|万里长城|里长|长城|万里|里长
万里长城万里长 精确模式:万里长城|万里|长
添加新词:万里长
万里长城万里长 精确模式:万里长城|万里长
北京鲜花速递 新词识别:北京|鲜花|速递
北京鲜花速递 搜索引擎模式: 北京|鲜花|速递
北京市朝阳公园 词性标注: 北京市/ns|朝阳/ns|公园/n
鲁迅先生 搜索引擎模式: 鲁迅|先生
鲁迅先生 Tokenize Search Mode 搜索引擎模式: [{鲁迅 0 6} {先生 6 12}]
鲁迅先生 Tokenize Default Mode搜索引擎模式: [{鲁迅 0 6} {先生 6 12}]
鲁迅先生 Extract: [{鲁迅 8.20023407859} {先生 5.56404756434}]
real 0m1.746s
user 0m1.622s
sys 0m0.124s
性能评测
| 语言 | 源码 | 耗时 |
| C++版本 | CppJieba | 7.5 s |
| Golang版本 | GoJieba | 9.11 s |
| Python版本 | Jieba | 88.7 s |
计算分词过程的耗时,不包括加载词典耗时,CppJieba性能是GoJieba的1.2倍。CppJieba性能详见jieba-performance-comparison,GoJieba由于是C++开发的CppJieba,性能方面仅次于CppJieba,如果追求性能还是可以考虑的。
Go语言 中文分词技术使用技巧(一)的更多相关文章
- NLP+词法系列(二)︱中文分词技术简述、深度学习分词实践(CIPS2016、超多案例)
摘录自:CIPS2016 中文信息处理报告<第一章 词法和句法分析研究进展.现状及趋势>P4 CIPS2016 中文信息处理报告下载链接:http://cips-upload.bj.bce ...
- 深入浅出Hadoop Mahout数据挖掘实战(算法分析、项目实战、中文分词技术)
Mahout简介 Mahout 是 Apache Software Foundation(ASF) 旗下的一个开源项目, 提供一些可扩展的机器学习领域经典算法的实现,旨在帮助开发人员更加方便快捷地创建 ...
- Python 自然语言处理(1)中文分词技术
中文分词技术 中文自动分词可主要归纳为“规则分词”“统计分词”和“混合分词”,规则分词主要是通过人工设立词库,按照一定方式进行匹配切分,实现简单高效,但对新词很难进行处理,统计分词能够较好应对新词发现 ...
- R语言中文分词包jiebaR
R语言中文分词包jiebaR R的极客理想系列文章,涵盖了R的思想,使用,工具,创新等的一系列要点,以我个人的学习和体验去诠释R的强大. R语言作为统计学一门语言,一直在小众领域闪耀着光芒.直到大数据 ...
- NLP+词法系列(一)︱中文分词技术小结、几大分词引擎的介绍与比较
笔者想说:觉得英文与中文分词有很大的区别,毕竟中文的表达方式跟英语有很大区别,而且语言组合形式丰富,如果把国外的内容强行搬过来用,不一样是最好的.所以这边看到有几家大牛都在中文分词以及NLP上越走越远 ...
- NLP第3章 中文分词技术
- 11大Java开源中文分词器的使用方法和分词效果对比,当前几个主要的Lucene中文分词器的比较
本文的目标有两个: 1.学会使用11大Java开源中文分词器 2.对比分析11大Java开源中文分词器的分词效果 本文给出了11大Java开源中文分词的使用方法以及分词结果对比代码,至于效果哪个好,那 ...
- 基于Deep Learning的中文分词尝试
http://h2ex.com/1282 现有分词介绍 自然语言处理(NLP,Natural Language Processing)是一个信息时代最重要的技术之一,简单来讲,就是让计算机能够理解人类 ...
- 基于规则的中文分词 - NLP中文篇
之前在其他博客文章有提到如何对英文进行分词,也说后续会增加解释我们中文是如何分词的,我们都知道英文或者其他国家或者地区一些语言文字是词与词之间有空格(分隔符),这样子分词处理起来其实是要相对容易很多, ...
随机推荐
- Dubbo之服务暴露
前言 本文 Dubbo 使用版本2.7.5 Dubbo 通过使用dubbo:service配置或@service在解析完配置后进行服务暴露,供服务消费者消费. Dubbo 的服务暴露有两种: 远程暴露 ...
- Head First设计模式——原型模式和访问者模式
原型 原型模式:当创建给定类的过程很昂贵或很复杂时,就使用原型模式. 我们在进行游戏的时候游戏会动态创建怪,而怪时根据场景的不同而变化创建的,英雄自己也会创建一些随从.创建各式各样的怪兽实例,已经越来 ...
- 高性能-GC
带着问题去思考!大家好 相对.NET 来说.CLR去处理了,C,C++这些就需要手动去垃圾回收. GC大部分容易察觉的性能问题.其实很多问题实际是哪个都是由于对垃圾回收器的行为和预期结果理解有误.在, ...
- 大数据软件安装之Azkaban(任务调度)
一.安装部署 1.安装前准备 1)下载地址:http://azkaban.github.io/downloads.html 2)将Azkaban Web服务器.Azkaban执行服务器.Azkaban ...
- MySQL 【进阶查询】
数据类型介绍 整型 tinyint, # 占1字节,有符号:-128~127,无符号位:0~255 smallint, # 占2字节,有符号:-32768~32767,无符号位:0~65535 med ...
- 关于Quartz .NET(V3.0.7)的简要说明
目录 0. 任务调度 1. Quartz .NET 1.1 基本概念 1.2 主要接口和对象 2. 使用示例 2.0 准备工作 2.1 每间隔一定时间间隔执行一次任务 2.3 某天的固定时间点执行任务 ...
- Python GUI wxPython StaticText控件背景色透明
import wx class TransparentStaticText(wx.StaticText): """ 重写StaticText控件 "" ...
- 【原创】(六)Linux进程调度-实时调度器
背景 Read the fucking source code! --By 鲁迅 A picture is worth a thousand words. --By 高尔基 说明: Kernel版本: ...
- 安装自动化测试工具webdriver与selenium模块
webdriver是一个驱动,需要与selenium配合使用,selenium是自动化测试和爬虫的专业模块,对于不同的浏览器需要不同的webdriver,这里我用的是ubuntu19.10的系统,以p ...
- [Redis] 万字长文带你总结Redis,助你面试升级打怪
文章目录 Redis的介绍.优缺点.使用场景 Linux中的安装 常用命令 Redis各个数据类型及其使用场景 Redis字符串(String) Redis哈希(Hash) Redis列表(List) ...