线程池-进程池-io模型
一、线程池与进程池
什么是池?简单的说就是一个容器,一个范围
在保证计算机硬件安全的情况下最大限度的充分利用计算机,
池其实是降低了程序的运行效率,但是保证了计算机硬件的安全,也是实现了一个并发的效果,现如今硬件的发展跟不上软件的更新速度
进程池与线程池
开进程开线程都需要消耗资源,只不过两者比较的情况线程消耗的资源比较少
创建进程池:multiprocess.Pool模块
导入的写法:from concurrent.futures import ThreadPoolExecutor,ProcessPoolExecutor
Pool([numprocess [,initializer [, initargs]]]):创建进程池 1 numprocess:要创建的进程数,如果省略,将默认使用cpu_count()的值
2 initializer:是每个工作进程启动时要执行的可调用对象,默认为None
3 initargs:是要传给initializer的参数组
方法有:p.apply() p.apply_async() p.colse() p.join()
内置函数 pool =ProcessPoolExecutor() # 创建进程池,不写默认为当前计算机cpu的个数
1、进程池的用法:
from concurrent.futures import ThreadPoolExecutor,ProcessPoolExecutor
import time
import os """
池子中创建的进程/线程创建一次就不会再创建了
开始到结尾都是那么几个,最初定义的
这样的话节省了反复开辟进程/线程的资源 """ #进程池的用法:
pool =ProcessPoolExecutor() # 创建进程池,不写默认为当前计算机cpu的个数 def task(n):
print(n,os.getpid()) # 查看当前的进程号
time.sleep(2)
return n**2 def call_back(n):
print("异步提交任务的返回结果:",n.result()) "异步回调机制:当异步提交的任务有返回结果之后,会自动触发回调函数的执行"
if __name__ == '__main__':
l_list = []
for i in range(20):
res = pool.submit(task,i).add_done_callback(call_back) # 异步回调
"提交任务的时候 绑定一个回调函数 一旦该任务有结果 立刻执行对于的回调函数"
l_list.append(res) >>>> 0 16128
1 41700
2 24856
3 9876
4 41128
5 40068
6 19288
7 40080
8 16128
异步提交任务的返回结果: 0
9 41700
异步提交任务的返回结果: 1
10 24856
异步提交任务的返回结果: 4
11 9876

进程池的回调机制
2、创建线程池:
线程池的用法 from concurrent.futures import ThreadPoolExecutor,ProcessPoolExecutor
import time
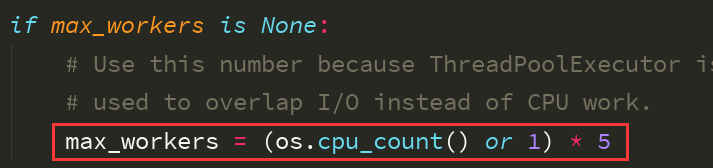
import os pool =ThreadPoolExecutor(5) # 括号内可以传参数指定线程池内的线程个数
# 也可以不传,不传就默认为当前所在技算机的cpu个数乘以5 def task(n):
print(n,os.getpid())
time.sleep(2)
return n **2 t_list=[]
for i in range(20):
res=pool.submit(task,i) # 往线程池中提交任务 异步提交
# print(res.result()) # 原地等待任务的返回结果 异步
t_list.append(res) pool.shutdown() # 关闭池子 等待池子中所有的任务执行完毕之后 才会往下运行代码
for p in t_list:
print(">>>>:",p.result()) >>>: 18 32864
19 32864
>>>>: 0
>>>>: 1
>>>>: 4
>>>>: 9
>>>>: 16
>>>>: 25
>>>>: 36
二、协程
(是程序员想象出来的,就是单线程实现并发的情况下可以称为协程)
1、单线程实现并发 在应用程序里控制多个任务的 切换+保存 的状态
优点:应用程序级别速度要远远高于操作系统的切换
缺点:多任务一旦有一个阻塞没有切,整个线程都阻塞在原地,该线程内的其他任务都不能执行了
进程:资源单位
线程:执行单位
协程:单线程下实现并发
并发的条件:多道技术:空间上的应用,时间上的复用 (切换+保存)
2、协程序的目的:
想要在单线程下实现并发
并发指的是多个任务看起来是同时运行的
并发=切换+保存状态
#串行执行
import time def func1():
for i in range(10000000):
i+1 def func2():
for i in range(10000000):
i+1 start = time.time()
func1()
func2()
stop = time.time() #1.094691514968872
print(stop - start) #基于yield并发执行 有yield在函数内,加括号调用时变成生成器
import time
def func1():
while True:
yield def func2():
g=func1()
for i in range(10000000):
i+1
next(g) start=time.time()
func2()
stop=time.time() # 1.3715009689331055
print(stop-start)
:第一种情况的切换。在任务一遇到io情况下,切到任务二去执行,这样就可以利用任务一阻塞的时间完成任务二的计算,
(在运行和就绪态来回切换,等待阻塞的事件很短)效率的提升就在于此。
一旦遇到IO自己通过代码切换
给操作系统的感觉是你这个线程没有任何的IO
ps:欺骗操作系统 让它误认为你这个程序一直没有IO
从而保证程序在运行态和就绪态来回切换
提升代码的运行效率
3、实现了切换+保存的状态就一定能够提升效率吗?
执行效率最好,更节省资源的应该是:多进程下开多线程,多线程下再开协程
4、用yeild 只能够保持切换的状态(yield 保存上一次的结果),需要找到一个能识别io的工具 从而引入了 gevent 模块
Gevent 是一个第三方库,可以轻松通过gevent实现并发同步或异步编程,在gevent中用到的主要模式是Greenlet, 它是以C扩展模块形式接入Python的轻量级协程。
swpn( ) 用于监测I/O 操作 实现切换+保存的状态 在单线程下实现并发的效果
swpn() 内置封装 自带return 有返回值
from gevent import monkey;monkey.patch_all()
# 由于该模快经常被使用,建议这么写
from gevent import spawn
import time #注意gevent模块没办法自动识别time.sleep等io情况
# 需要你手动再配置一个参数 def heng():
print("天时地利")
time.sleep(2)
print("只前东风") def hei():
print("登高望楼")
time.sleep(2)
print("独坐西楼")
def haha():
print('who are you ')
time.sleep(2)
print('why') start = time.time()
g1= spawn(heng) # spawn会检测所有的任务
g2 = spawn(hei)
g3 = spawn(haha) g1.join()
g2.join()
g3.join() print(time.time()-start)
用spawn 检测掠过io 快速的切换+保存的状态 让系统误认为没有一个io的操作,提升执行的效率
5、利用单线程形式实现ftp的并发效果
利用genvent模块下的spawn() 自动检测io操作的功能实现
FTP客户端:
import socket
from threading import Thread,current_thread def client(): # 写成函数版
client = socket.socket()
client.connect(('127.0.0.1',8080))
n = 0
while True: data = '%s %s'%(current_thread().name,n)
client.send(data.encode('utf-8'))
res = client.recv(1024)
print(res.decode('utf-8'))
n += 1 for i in range(400):
t = Thread(target=client)
t.start()
FTP服务端:
from gevent import monkey;monkey.patch_all()
import socket
from gevent import spawn server = socket.socket()
server.bind(('127.0.0.1',8080))
server.listen(5) def talk(conn):
while True:
try:
data = conn.recv(1024)
if len(data) == 0:break
print(data.decode('utf-8'))
conn.send(data.upper())
except ConnectionResetError as e:
print(e)
break
conn.close() def server1():
while True:
conn, addr = server.accept()
spawn(talk,conn) # 自定检测io操作,在通讯和接受之间,快速实现切换+保存的状态,时间间隔很短,看起来就像是在并发 if __name__ == '__main__':
g1 = spawn(server1)
g1.join()
三、IO模型
为了更好地了解IO模型,我们需要事先回顾下:同步、异步、阻塞、非阻塞
Stevens在文章中一共比较了五种IO Model:
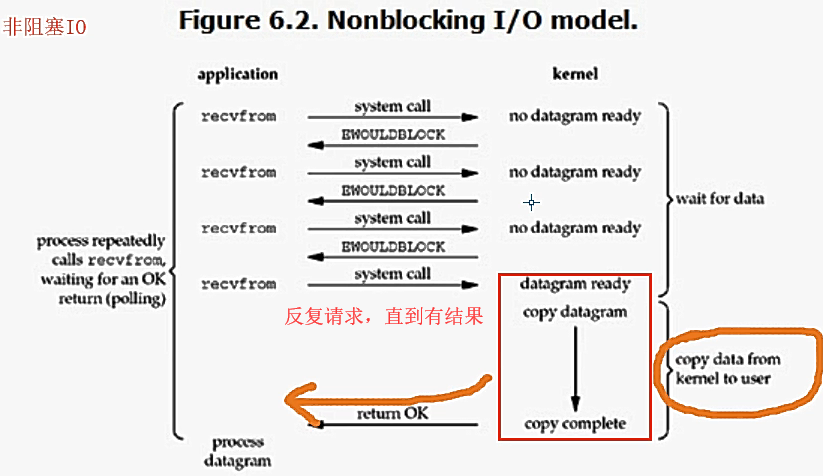
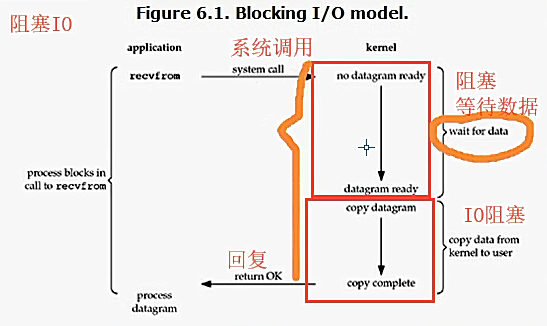
* blocking IO 阻塞IO
* nonblocking IO 非阻塞IO
* IO multiplexing IO多路复用
* signal driven IO 信号驱动IO
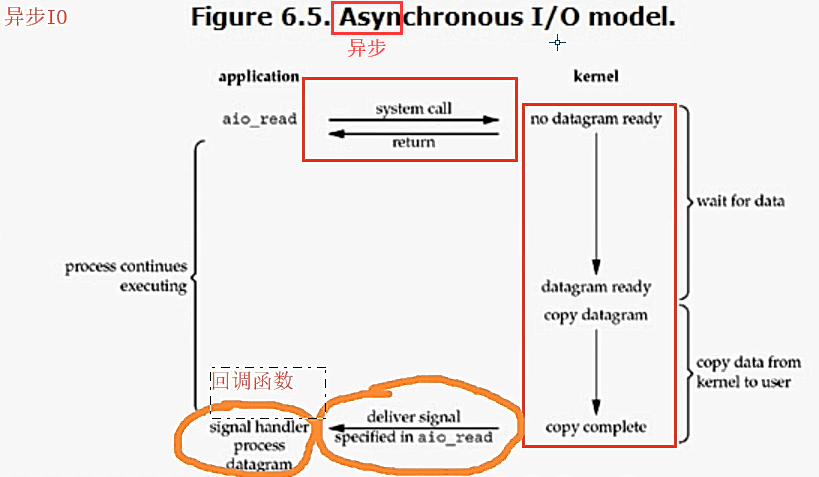
* asynchronous IO 异步IO
同步异步:指的是运行的任务的提交方式:
同步:提交的任务之后原地等待任务的返回结果,期间不做任何事
异步:提交任务后立刻执行下一行代码,不等待任务的返回结果,采用异步回调机制
阻塞与非阻塞:指的是程序的运行状态
阻塞:阻塞等待的状态
非阻塞:就绪态或者运行态

线程池-进程池-io模型的更多相关文章
- Python进阶----异步同步,阻塞非阻塞,线程池(进程池)的异步+回调机制实行并发, 线程队列(Queue, LifoQueue,PriorityQueue), 事件Event,线程的三个状态(就绪,挂起,运行) ,***协程概念,yield模拟并发(有缺陷),Greenlet模块(手动切换),Gevent(协程并发)
Python进阶----异步同步,阻塞非阻塞,线程池(进程池)的异步+回调机制实行并发, 线程队列(Queue, LifoQueue,PriorityQueue), 事件Event,线程的三个状态(就 ...
- 并发编程 - 线程 - 1.线程queue/2.线程池进程池/3.异步调用与回调机制
1.线程queue :会有锁 q=queue.Queue(3) q.get() q.put() 先进先出 队列后进先出 堆栈优先级队列 """先进先出 队列"& ...
- GIL 线程池 进程池 同步 异步 阻塞 非阻塞
1.GIL 是一个全局解释器锁,是一种互斥锁 为什么需要GIL锁:因为一个python.exe进程中只有一份解释器,如果这个进程开启了多个线程都要执行代码 多线程之间要竞争解释器,一旦竞争就有可能出现 ...
- GIL 线程池 进程池 同步 异步
1.GIL(理论 重点)2.线程池 进程池3.同步 异步 GIL 是一个全局解释器锁,是一个互斥锁 为了防止竞争解释器资源而产生的 为何需要gil:因为一个python.exe进程中只有一份解释器,如 ...
- Python并发编程之线程池&进程池
引用 Python标准库为我们提供了threading和multiprocessing模块编写相应的多线程/多进程代码,但是当项目达到一定的规模,频繁创建/销毁进程或者线程是非常消耗资源的,这个时候我 ...
- Python并发编程之线程池/进程池--concurrent.futures模块
一.关于concurrent.futures模块 Python标准库为我们提供了threading和multiprocessing模块编写相应的多线程/多进程代码,但是当项目达到一定的规模,频繁创建/ ...
- 《转载》Python并发编程之线程池/进程池--concurrent.futures模块
本文转载自Python并发编程之线程池/进程池--concurrent.futures模块 一.关于concurrent.futures模块 Python标准库为我们提供了threading和mult ...
- Python3【模块】concurrent.futures模块,线程池进程池
Python标准库为我们提供了threading和multiprocessing模块编写相应的多线程/多进程代码,但是当项目达到一定的规模,频繁创建/销毁进程或者线程是非常消耗资源的,这个时候我们就要 ...
- 线程池&进程池
线程池&进程池 池子解决什么问题? 1.创建/销毁线程伴随着系统开销,如果过于频繁会影响系统运行效率 2.线程并发数量过多,抢占系统资源,从而导致系统阻塞甚至死机 3.能够刚好的控制和管理池子 ...
随机推荐
- -webkit-appearance —— webkit外观样式属性
-webkit-appearance —— webkit外观样式属性 -webkit-appearance 是一个 不规范的属性(unsupported WebKit property),它没有出现在 ...
- WebFlux系列(十二)MongoDB应用,新增、修改、查询、删除
#Java#Spring#SpringBoot#Mongo#reactor#webflux#数据库#新增#修改#查询#删除# Spring Boot WebFlux Mongo数据库新增.删除.查询. ...
- C语言:大数求和
点击获取题目 1410: [蓝桥杯]高精度加法 时间限制: 1 Sec 内存限制: 256 MB提交: 28 解决: 20[状态] [提交] [命题人:外部导入] 题目描述 输入两个整数a和b,输 ...
- 十八、CI框架之数据库操作update用法
一.代码如图: 二.访问一下 三.我们来查看数据库,已经被修改了 不忘初心,如果您认为这篇文章有价值,认同作者的付出,可以微信二维码打赏任意金额给作者(微信号:382477247)哦,谢谢.
- javascript实现抽奖程序
昨天开年会的时候看到一个段子说唯品会年会抽奖,结果大奖都被写抽奖程序的部门得了,CTO现场review代码. 简单想了一下抽奖程序的实现,花了十几分钟写了一下,主要用到的知识有数组添加删除,以及ES5 ...
- Codeforces Round #604 (Div. 2) 部分题解
链接:http://codeforces.com/contest/1265 A. Beautiful String A string is called beautiful if no two con ...
- P1426 小鱼会有危险吗
题解: 在测试数据里有一个是临界值问题,探测范围是闭区间 #include<stdio.h>int main(){ double s,x; //注意:此 ...
- sqlcook sql经典实例 emp dept 创建语句
创建表语句 create table dept( deptno int primary key, dname varchar(30), loc varchar(30) ); create table ...
- DQL多表查询
DQL多表查询 一.多表查询实现多个表之间查询数据 1.交叉连接笛卡尔积:A表中的每一行匹配B表中的每一行基本结构:select [数据库名1.]表名1,属性名1,......, [数据库名.]表名. ...
- Centos6.5 安装zabbix3(收藏,非原创)
1.安装PHP Zabbix 3.0对PHP的要求最低为5.4,而CentOS6默认为5.3.3,完全不满足要求,故需要利用第三方源,将PHP升级到5.4以上,注意,不支持PHP7 rpm -ivh ...