Linux高性能服务器技术总结
文章目录
1 服务器简介
服务器是提供计算服务的设备, 由于服务器需要响应用户请求,因此在处理能力、稳定性、安全性、可扩展性、可管理性等方面提出了较高要求。随着虚拟化技术的进步, 云服务器(ECS) 已经快速的在国内普及开来, 其管理方式比物理服务器更简单高效。用户可迅速创建或释放任意多台云服务器, 帮助企业降低开发运维的难度和整体 IT 成本, 使整个研发周期更专注于核心业务的创新。在网络环境下,根据服务器提供的服务类型不同,分为文件服务器、 数据库服务器、应用程序服务器、 WEB 服务器等。
此次学习总结的主要内容:
- 如何处理多个客户端连接。
- 探讨面对百万千万级客户端连接时的性能优化。
- 服务器如何高效处理并发的数据。
- 深度分析大数据通信时, Linux 内核瓶颈。
- 如何攻克瓶颈
2 I/O复用技术
2.1 循环方式
当服务器有多个网络连接需要看管,那么循环遍历打开的网络连接的列表,来判断是否有要读取的数据。
缺点:
- 速度缓慢(必须遍历所有的网络连接)
- 效率低(处理一个连接时可能发生阻塞,妨碍其他网络连接的检查和处理)
示例:
typedef struct ClientInfo{
int client_fd;
string client_ip;
}ClientInfo;//客户端结构体
std::deque<ClientInfo> m_client1;//客户端队列 1
std::deque<ClientInfo> m_client2;//客户端队列 2
void MServer::ClientHandel(std::deque<ClientInfo> *client){
char data[1024] = {0};
int len = 0;
for(int i = 0; i < client->size(); ++i){
//当没有数据可读时, 发生阻塞
len = read(client->at(i).client_fd, data, sizeof data);
//处理数据
bzero(data,sizeof data);//清空缓存
}
}
2.2 select 方式
select 首先将第二三四个参数指向的 fd_set 拷贝到内核,对每个被 SET 的描述符进行 poll,记录在临时结果中(fdset),如果有事件发生, select 会将临时结果写到用户空间并返回。
缺点:
select 返回后,需要逐一检查描述符是否被 SET(事件是否发生)。(select 支持的
文件描述符数量太小了,默认是 1024)。
示例:
void MServer::ClientHandel(std::deque<ClientInfo> *client){
char data[1024] = {0};
fd_set input;// fdset 记录 poll 结果
int len = 0;
int retval = 0;
FD_ZERO(&input);//清空记录
for(int i = 0; i < client->size(); ++i){
FD_SET(client->at(i).client_fd, &input);
retval = select(client->at(i).client_fd + 1, &input, NULL, NULL, NULL);
//检测事件是否发生
if(retval > 0 && FD_ISSET(client->at(i).client_fd, &input)){
//读取数据
len = read(client->at(i).client_fd, data, sizeof data);
//处理数据
bzero(data,sizeof data);
}
//处理其他事情
}
}
2.3 poll方式
poll 与 select 不同,通过一个 pollfd 数组向内核传递需要关注的事件,故没有描述符个数的限制, pollfd 中的 events 字段和 revents 分别用于标示关注的事件和发生的事件,故 pollfd 数组只需要被初始化一次。 poll 的实现机制与 select 类似,其对应内核中的 sys_poll,只不过poll 向内核传递 pollfd 数组,然后对 pollfd 中的每个描述符进行 poll,相比处理 fdset 来说, poll 效率更高。
缺点:
poll 需要对 pollfd 中的每个元素检查其 revents 值,来得知事件是否发生。
示例:
std::vector<struct pollfd> pollfds;
void MServer::ClientHandel(std::deque<ClientInfo> *client){
int nready = 0;
int len = 0;
char data[1024] = {0};
//初始化 pollfds 容器
for(int i = 0; i < client->size(); ++i){
struct pollfd pfd;
pfd.fd = client->at(i).client_fd;//设置 pollfd
pfd.events = POLLIN;//设置 pollin 事件
pfd.revents = 0;//设置没有任何事件返回,置为零pollfds.push_back(pfd);
}
while(1){
nready = poll(&*pollfds.begin(), pollfds.size(), -1);//负数表示无限等待,直到发生事
件才返回
for(PollFdList::iterator it = pollfds.begin(); it != pollfds.end() && nready > 0; ++it){ //遍历查看 fd 产生的事件
if (it->revents & POLLIN){
len = read(it->fd, buf, sizeof data);
//处理数据
bzero(data,sizeof data);
}
}
//处理其他事情
}
}
2.4 epoll 方式
epoll 与 select、 poll 不同,其不用每次调用都向内核拷贝事件描述信息,在第一次调用后,事件信息就会与对应的 epoll 描述符关联起来。其次, epoll 不是通过轮询,而是通过在等待的描述符上注册回调函数,当事件发生时,回调函数负责把发生的事件存储在就绪事件链表中,最后写到用户空间。
epoll 返回后,该参数指向的缓冲区中即为发生的事件,对缓冲区中每个元素进行处理即可,而不需要像 poll、 select 那样进行轮询检查。
示例:
void MServer::ClientHandel(std::deque<ClientInfo> *client){
int wait_fds;//事件产生的数量
int i = 0;
int len = 0;
char data[1024] = {0};
int epoll_fd = epoll_create(1024);//创建 epoll
for(i = 0; i < client->size(); ++i){
struct epoll_event ev;
ev.events = EPOLLIN | EPOLLET;//设置触发事件的类型
ev.data.fd = client->at(i).client_fd;
//向 epoll 中增加 client_fd
if( epoll_ctl( epoll_fd, EPOLL_CTL_ADD, client->at(i).client_fd, &ev ) < 0 ){
printf("Epoll Error : %d\n", errno);
exit( EXIT_FAILURE );
}
}struct epoll_event evs[1024];//epoll 事件缓存区
while(1){
if( ( wait_fds = epoll_wait( epoll_fd, evs, 0, -1 ) ) == -1 ){
break;
}
for( i = 0; i < wait_fds; ++i){
len = read( evs[i].data.fd, data, sizeof data);
//处理数据
bzero(data,sizeof data);
}
}
}
3 多线程方式
多线程技术也可以处理高并发的客户端连接,因为在服务器中可以创建大量的线程来监视连接。
缺点:
多线程技术则不太适合处理长连接,因为建立一个线程 linux 中会消耗栈空间, 当产生大量的连接后, 会导致系统内存消耗殆尽。
示例:
typedef struct ClientInfo{
int client_fd;
pthread_t pid;
bool pthread_enlable;
}ClientInfo;
std::deque<ClientInfo> client;//客户端队列
void MServer::ClientHandel(){
int i = 0;
//创建多线程处理连接
for(i = 0; i < client.size(); ++i){
if(pthread_create(&client[i].pid, NULL, ClientPthread, &client[i]) != 0){
client[i].pthread_enlable = true;
}
}
//等待线程结束
for(i = 0; i < client.size(); ++i){
if(client[i].pthread_enlable)
pthread_join(client[i].pid, NULL);
}
}//end func ClientHandel
void *MServer::ClientPthread(void *arg){
char data[1024] = {0};
int len = 0;
while(1){
len = read(((MServer*)arg)->client_fd, data, sizeof data);
//处理数据
bzero(data,sizeof data);//清空缓存
}
pthread_exit(NULL);
}
多线程 + I/O 复用技术,使用一个线程负责监听一个端口和描述符是否有读写事件产生,
再将事件分发给其他的工作线程处理数据。
模型架构:
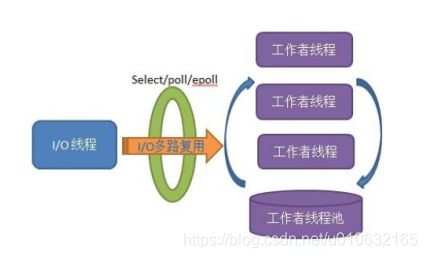 这种架构主要是基于单线程 I/O 多路复用(select/poll/epoll),达到高并发效果,同时避免了多线程 I/O 来回切换的各种开销,而基于线程池的多工作者线程,进一步提高业务处理能力和避免产生过多线程。
这种架构主要是基于单线程 I/O 多路复用(select/poll/epoll),达到高并发效果,同时避免了多线程 I/O 来回切换的各种开销,而基于线程池的多工作者线程,进一步提高业务处理能力和避免产生过多线程。
4 CPU多核并行计算
程序的线程是指能同时并发执行的逻辑单元的个数,是通过时间片分配算法实现的;
CPU 的线程是指将 CPU 的指令执行过程(取指、译指、执行、 访存、写数)做出流水线从而提高并发度的方法。
并行计算和多线程的区别:
- 并行计算比多线程具有更高的 CPU 利用率,因此效率相对更高。
- 并行计算是利用 CPU 的多核进行计算,而多线程是利用 CPU 一个核在不同时间段内
进行计算。 - 并行计算是多个线程运行在多核 CPU 上,多线程是多线程运行在单核 CPU 上。
综合上述得出多线程并不能真正提高数据处理能力, 其局限于单核 CPU 的性能, 当服务器
需要进行大量的数据运算(如图形处理、 复杂的算法) 时考虑多核并行计算。
5 深度分析内核性能
5.1 中断处理
当网络中大量数据包到来时,会产生频繁的硬件中断请求,这些硬件中断可以打断之前较低优先级的软中断或者系统调用的执行过程,如果这种打断频繁的话,将会产生较高的性能开销。
5.2 内存拷贝
正常情况下,一个网络数据包从网卡到应用程序需要经过如下的过程:数据从网卡通过 DMA (直接存储器访问) 等方式传到内核开辟的缓冲区,然后从内核空间拷贝到用户态空间,在 Linux 内核协议栈中,这个耗时操作甚至占到了数据包整个处理流程的 57.1%。
5.3 上下文切换
频繁到达的硬件中断和软中断都可能随时抢占系统调用的运行,这会产生大量的上下文切换开销。另外,在基于多线程的服务器设计框架中,线程间的调度也会产生频繁的上下文切换开销,同样,锁竞争的耗能也是一个非常严重的问题。
5.4 局部性失效
如今主流的处理器都是多个核心的,这意味着一个数据包的处理可能跨多个 CPU 核心,比如一个数据包可能中断在 cpu0,内核态处理在 cpu1,用户态处理在 cpu2,这样跨多个核心,容易造成 CPU 缓存失效,造成局部性失效。
5.5 内存管理
传统服务器内存页为 4K,为了提高内存的访问速度,避免 cache miss,可以增加 cache 中映射表的条目,但这又会影响 CPU 的检索效率。综合以上问题,可以看出内核本身就是一个非常大的瓶颈所在, 解决方案就是想办法绕过内核。
6 高性能网络框架DPDK
DPDK 为 Intel 处理器架构下用户空间高效的数据包处理提供了库函数和驱动的支持,它不同于 Linux 系统以通用性设计为目的,而是专注于网络应用中数据包的高性能处理。
DPDK 官网: https://www.dpdk.org/
DPDK 架构图:
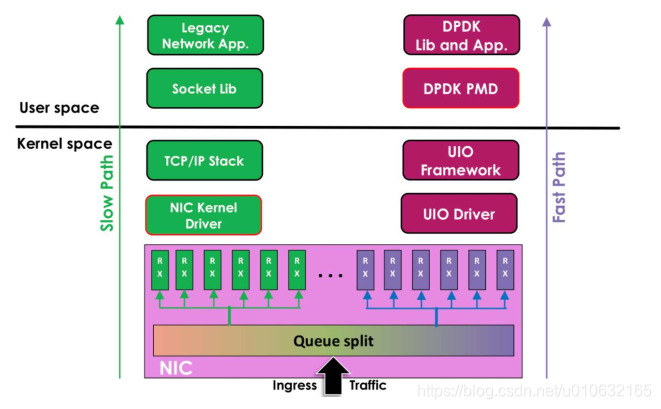
Linux 内核网络数据流程:
硬件中断--->取包分发至内核线程--->软件中断--->内核线程在协议栈中处理包--->处理
完毕通知用户层
用户层收包-->网络层--->逻辑层--->业务层
DPDK 网络数据流程:
硬件中断--->放弃中断流程
用户层通过设备映射取包--->进入用户层协议栈--->逻辑层--->业务层
下面就具体看看 dpdk 做了哪些突破?
UIO (用户空间的 I/O 技术)的加持, dpdk 能够绕过内核协议栈,本质上是得益于 UIO技术,通过 UIO 能够拦截中断,并重设中断回调行为,从而绕过内核协议栈后续的处理流程。
Linux高性能服务器技术总结的更多相关文章
- Linux 高性能服务器编程——I/O复用
问题聚焦: 前篇提到了I/O处理单元的四种I/O模型. 本篇详细介绍实现这些I/O模型所用到的相关技术. 核心思想:I/O复用 使用情景: 客户端程序要同时处理多个socket ...
- Linux 高性能服务器编程——高性能服务器程序框架
问题聚焦: 核心章节. 服务器一般分为如下三个主要模块:I/O处理单元(四种I/O模型,两种高效事件处理模块),逻辑单元(两种高效并发模式,有效状态机)和存储单元(不讨论). 服务器模 ...
- Linux 高性能服务器编程——多线程编程
问题聚焦: 在简单地介绍线程的基本知识之后,主要讨论三个方面的内容: 1 创建线程和结束线程: 2 读取和设置线程属性: 3 线程同步方式:POSIX信号量,互斥锁和条件变量 ...
- Linux 高性能服务器编程——多进程编程
问题聚焦: 进程是Linux操作系统环境的基础. 本篇讨论以下几个内容,同时也是面试经常被问到的一些问题: 1 复制进程映像的fork系统调用和替换进程映像的exec系列系统调 ...
- Linux 高性能服务器编程——Linux服务器程序规范
问题聚焦: 除了网络通信外,服务器程序通常还必须考虑许多其他细节问题,这些细节问题涉及面逛且零碎,而且基本上是模板式的,所以称之为服务器程序规范. 工欲善其事,必先利其器,这篇主要来探 ...
- Linux 高性能服务器编程——Linux网络编程基础API
问题聚焦: 这节介绍的不仅是网络编程的几个API 更重要的是,探讨了Linux网络编程基础API与内核中TCP/IP协议族之间的关系. 这节主要介绍三个方面的内容:套接字(so ...
- Linux 高性能服务器编程——TCP协议详解
问题聚焦: 本节从如下四个方面讨论TCP协议: TCP头部信息:指定通信的源端端口号.目的端端口号.管理TCP连接,控制两个方向的数据流 TCP状态转移过程:TCP连接的任意一 ...
- Linux 高性能服务器编程——IP协议详解
1 IP服务特点 IP协议是TCP/IP协议族的动力,它为上层协议提供无状态.无连接.不可靠的服务. 无状态:IP通信双方不同步传输数据的状态信息,因此IP数据包的发送.传输和接收都是无序的. ...
- Linux 高性能服务器编程——TCP/IP协议族
1 TCP/IP协议族体系结构 数据链路层: 职责:实现网卡接口的网络驱动程序,一处理数据在物理媒介(如以太网.令牌环等)上的传输. 常用协议:ARP协议(地址解析协议),RARP协议 ...
随机推荐
- 复习python的__call__ __str__ __repr__ __getattr__函数 整理
class Www: def __init__(self,name): self.name=name def __str__(self): return '名称 %s'%self.name #__re ...
- 王者荣耀英雄全皮肤4K高清大图,python爬虫帮你保存下来
前言 文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行获取t.cn ...
- 借助Python来实现的定量城市研究
一.数据处理基础 (一)数据分析的概念 城市数据分析,可以从数据分析的广义和狭义两个角度来看: 狭义的数据分析是指根据分析目的,采用对比分析.分组分析.交叉分析和回归分析等分析方法,对相关城市数据(包 ...
- stand up meeting 11/16/2015
第一周,熟悉任务中~ 大致写下一天的工作: 冯晓云:熟悉bing接口,本意是调在线的必应词典API,参阅了大量C#调用API开发.net的工作,[约莫是因为有个窗口互动性更强,所以这样的工作更有趣,也 ...
- eclipse git 文件状态 及git分支的创建与合并与删除
eclipse里面Git文件状态及图标展示 EGit会出现如下图标,其对应状态及意义如下: 1)忽略[ ignored ]:仓库认为该文件不存在(如bin目录,不需要关注).通过右键Te ...
- 这份Mybatis总结,我觉得你很需要!
前言 只有光头才能变强. 文本已收录至我的GitHub精选文章,欢迎Star:https://github.com/ZhongFuCheng3y/3y Mybatis应该是国内用得最多的「数据访问层」 ...
- 不是广告--如何学Java,我说点不太一样的学习方式
首先声明,这篇文章不是卖课程.介绍培训班的广告. 最近有不少读者通过微信问我:小白应该怎么学好 Java? 提问的人里有在校大学生.有刚参加工作的.有想转行做程序员的,还有一部分是最近找工作不顺的. ...
- Scrapy爬虫框架(1)--安装配置与常用命令
安装与配置 Scrapy有几个安装依赖,一般来说可以直接pip install scrapy,这个过程会自动下载安装其他几个依赖. 上述安装方法不成功,则需要手动安装依赖包 步骤 安装 lxmlpip ...
- bootstrop设置背景图片自适应屏幕
如果不用bootstrop框架,想让背景图片自适应窗口大小,可以这样做: <style type="text/css"> html{height: %;} body.a ...
- RedHat Linux server 6.5系统关机重启失败问题总结
今天晚上升级服务,由于服务器(red hat Linux server 6.5操作系统)没有正常关机,再重启的过程中遇到了如下问题: 1 服务器配置挺高的,认为启动过程有点慢是正常的,当时就没有上心, ...