第三周之Hadoop学习(三)
从上周的这篇教程中继续hadoop的安装过程:http://dblab.xmu.edu.cn/blog/install-hadoop-in-centos/
上节课安装到对hadoop中的输出的文件夹的进行了清空操作,现在接着对hadoop中的配置进行设置
(这里设置的是伪分布式的过程)
首先打开虚拟机吧centos 6.4开机
在终端中输入相应命令用gedit配置 ~/.bashrc 中的设置

添加教程中所给的命令到文件的末尾位置

输入命令使刚刚添加进去的内容生效
继续将对应的内容添加进hdfs-site.xml和core-site.xml中,保存
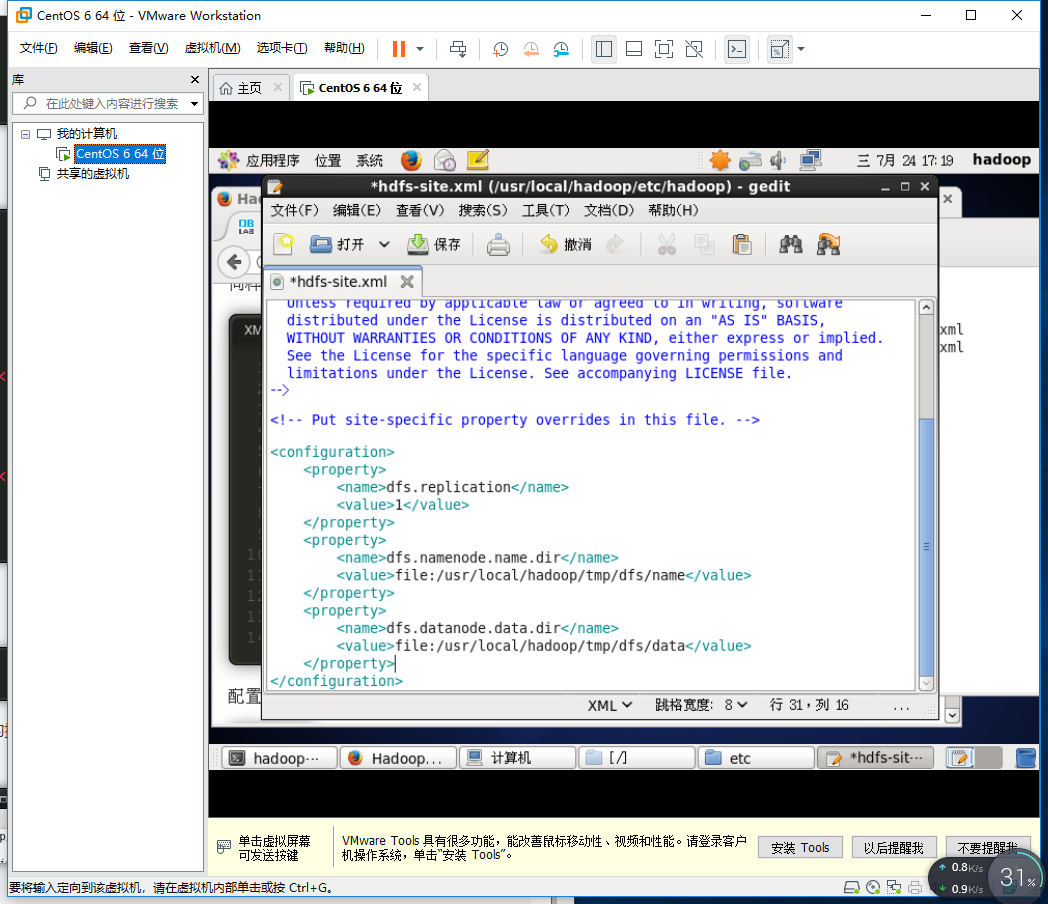
配置完成之后,执行NameNode的格式化
再根据教程中所给的命令,输入对应的命令之后,出现了一个错误

在其中的bin文件夹中确实没有找到相对应的文件,因此,在格式化的地址估计出现了错误,为了找到究竟是在什么位置。进行了百度一番,发现了这篇博客https://blog.csdn.net/tiankong_12345/article/details/80551930
其中我发现了他的bin/hdfs前面加了个
$HADOOP_HOME
这是刚刚在设置配置文件和配置环境变量的过程中使用到的一个环境变量
属于根据这篇博客中提供的这个位置,进行了大胆的尝试。
执行完之后

格式化的过程相当成功。
接着根据教程开启NameNode和DataNode的守护进程:

开启的过程中发现了相同的错误提示,因此,大致都是前面要加个$HADOOP_HOME才是正确的地址位置
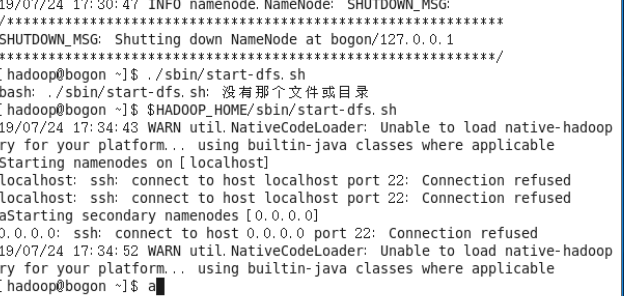
启动的过程中发现并没有输出最后的选项让我们选择继续操作,但是首先得验证是否启动成功,输入jps
发现了新问题:
由于OPENJDK在centos中已经是自动被安装了,前面的安装jdk的过程导致系统出现了多个jdk的版本,因此在安装之后,系统无法判断究竟要使用哪个jdk导致出现了

无法找到运行环境的提示。
根据网上的教程,删除了其中一个java的jdk,发现删除成安装的那个jdk了,而前面的教程说道系统自带的jdk是有问题的,因此,重新安装前面的jdk
过程省略,最终安装完毕
继续查看为什么会导致无法启动进程,进行百度后发现,其原因是没有启动ssh服务导致的
输入service sshd restart后再次启动守护程序,成功执行
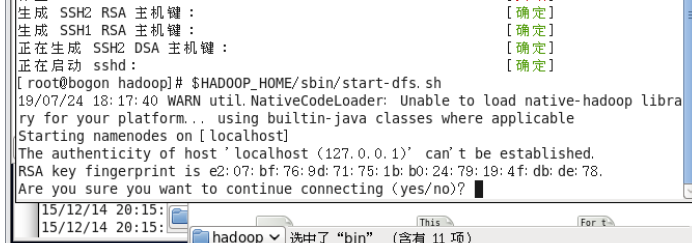
输入yes
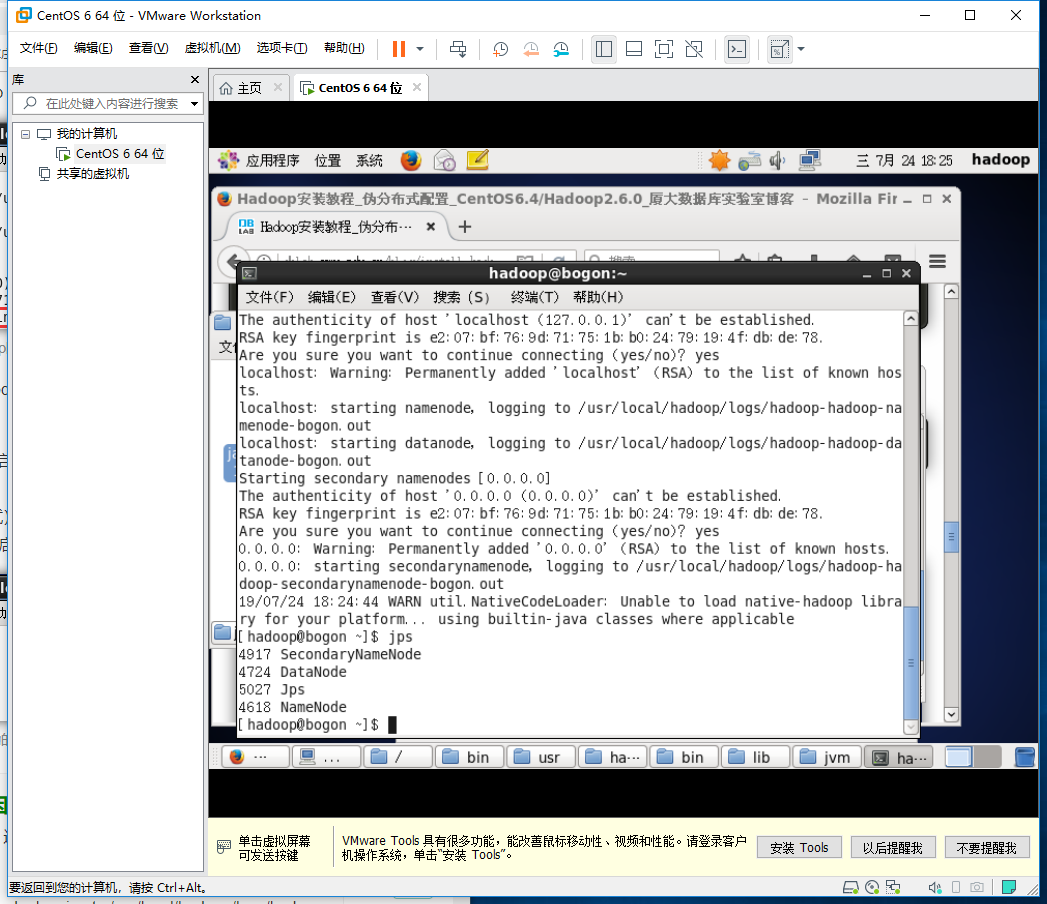
之后成功启动
输入jps检测如下:
通过网址Web 界面 http://localhost:50070 查看 NameNode 和 Datanode 信息
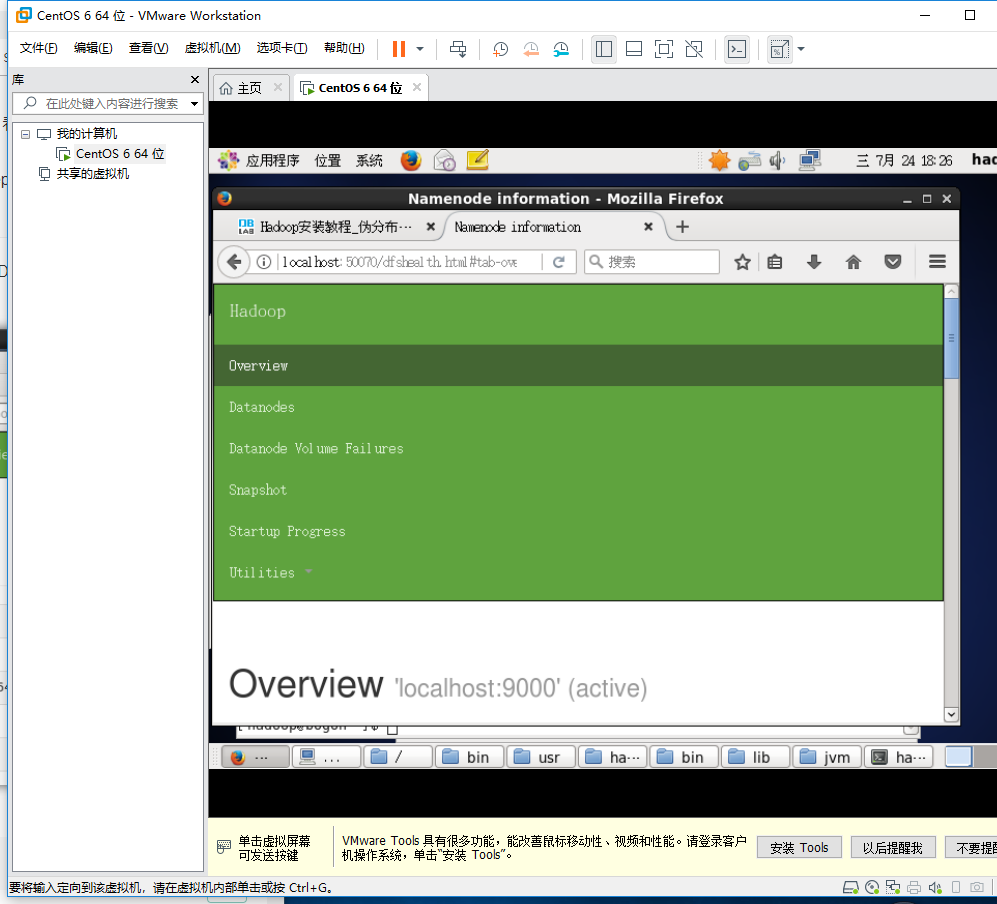
运行伪分布式实例:
关闭hadoop及其运行的命令:
./sbin/stop-dfs.sh
./sbin/start-dfs.sh(下次启动时无需再次进行NameNode的初始化)
最后关闭hadoop:

第三周之Hadoop学习(三)的更多相关文章
- “Hello World!”团队第三周召开的第三次会议
今天是我们团队“Hello World!”团队第三周召开的第三次会议.博客内容: 一.会议时间 二.会议地点 三.会议成员 四.会议内容 五.todo list 六.会议照片 七.燃尽图 八.代码地址 ...
- 20175215 2018-2019-2 第三周java课程学习总结
第三周 一.使用JDB调试java代码(主要内容为断点) 以下文字内容转自使用JDB调试java程序,图片则为自己的截图 我们提倡在Linux命令行下学习Java编程.学习时在Ubuntu Bash中 ...
- C语言程序设计(翁恺)--第三周课件中的三个遗留点
刚刚写完第二周遗留点,下面写第三周的 第三周:判断 1.if和else后面也可以没有{}而是一条语句.如果if后不带{},但是后面跟了两条语句,并且后面还有else语句,那么程序会怎么执行? 在Dev ...
- 大二暑假第三周总结--开始学习Hadoop基础(二)
简单学习NoSQL数据库理论知识 NoSQL数据库具有以下几个特点: 1.灵活的可扩展性(支持在多个节点上进行水平扩张) 2.灵活的数据模型(与关系数据库中严格的关系模型相反,显得较为松散) 3.与与 ...
- 第三周vim入门学习2
一.vim重复命令 1.重复执行上次命令 在普通模式下.(小数点)表示重复上一次的命令操作 拷贝测试文件到本地目录 $ cp /etc/protocols . 打开文件进行编辑 $ vim proto ...
- 第三周 day3 python学习笔记
1.字符串str类型,不支持修改. 2.关于集合的学习: (1)将列表转成集合set:集合(set)是无序的,集合中不会出现重复元素--互不相同 (2)集合的操作:交集,并集.差集.对称差集.父集.子 ...
- hadoop学习(三)----hadoop2.x完全分布式环境搭建
今天我们来完成hadoop2.x的完全分布式环境搭建,话说学习本来是一件很快乐的事情,可是一到了搭环境就怎么都让人快乐不起来啊,搭环境的时间比学习的时间还多.都是泪.话不多说,走起. 1 准备工作 开 ...
- 第三周vim入门学习1
一.vim模式介绍 1.概念:以下介绍内容来自维基百科Vim 从vi演生出来的Vim具有多种模式,这种独特的设计容易使初学者产生混淆.几乎所有的编辑器都会有插入和执行命令两种模式,并且大多数的编辑器使 ...
- 暑假第三周总结(学习HDFS操作方法)
本周由于自己出去玩,以及家里的各种事也没好好看书,就对HDFS的一些常用的shell命令进行了学习与应用,观看了林子雨老师关于HDFS的视频,对HDFS的一些存储的原理.规则进行了一定的了解.对uba ...
随机推荐
- Educational Codeforces Round 76 (Rated for Div. 2) A. Two Rival Students
You are the gym teacher in the school. There are nn students in the row. And there are two rivalling ...
- eclipse从svn导入静态文件
1.从eclipse 选择 导入 2.选择仓库和项目,选择finish 3.选择project项目导出
- 微信小程序--缓存,支持过期时间的二次开发封装
简介 微信小程序提供了缓存的api,包括同步和异步两种,具体api不多说明,可自行查看官方文档 现在微信小程序缓存api存在一个问题就是没有设定过期时间,下面给大家介绍一下对小程序缓存的二次封装,使其 ...
- via/route blockage/size blockage/wire/pin guide/pin blockage/partition
1.via 中文名称互连线通孔.我们知道,芯片的连线有不同层的金属互连线相互连接.而Via的作用就是连接这些不同层的金属.如下图所示: 一个完整的通孔是由三层组成的,包括两个互连层和一个cut层,cu ...
- 使用Docker搭建Spark集群(用于实现网站流量实时分析模块)
上一篇使用Docker搭建了Hadoop的完全分布式:使用Docker搭建Hadoop集群(伪分布式与完全分布式),本次记录搭建spark集群,使用两者同时来实现之前一直未完成的项目:网站日志流量分析 ...
- linux日常运维工作
Linux的使用环境也日趋成熟,各种开源产品络绎不绝,大有百花齐放的盛景,那么当Linux落地企业,回归工作时,我们还要面对这Linux运维方面的诸多问题,今天我们特意组织一场有关Linux 在企业运 ...
- Google 开源的依赖注入库,比 Spring 更小更快!
Google开源的一个依赖注入类库Guice,相比于Spring IoC来说更小更快.Elasticsearch大量使用了Guice,本文简单的介绍下Guice的基本概念和使用方式. 学习目标 概述: ...
- 爬虫 - Scrapy中间件
前提:看Scrapy架构图 不管什么Middlewares,都写在middlewares.py里面. 然后在settings.py里的DOWNLOADER_MIDDLEWARES或者SPIDER_MI ...
- 原生JS实现旋转木马轮播图特效
大概是这个样子: 首先来简单布局一下(emm...随便弄一下吧,反正主要是用js来整的) <!DOCTYPE html> <html lang="en"> ...
- 迭代器,for循环本质,生成器,常用内置方法,面向过程编程
一.迭代器 1.迭代:更新换代(重复)的过程,每次的迭代都必须基于上一次的结果 迭代器:迭代取值的工具 2.迭代器给你提供了一种不依赖于索引取值的方式 3.可以迭代取值的对象:字符串,列表,元组,字典 ...