postgre安装和使用(R&Python)
安装postgre
http://helianthus-code.lofter.com/post/1dfe03e0_1c68233aa
这里选C更好
这里口令密码输入就是黑的
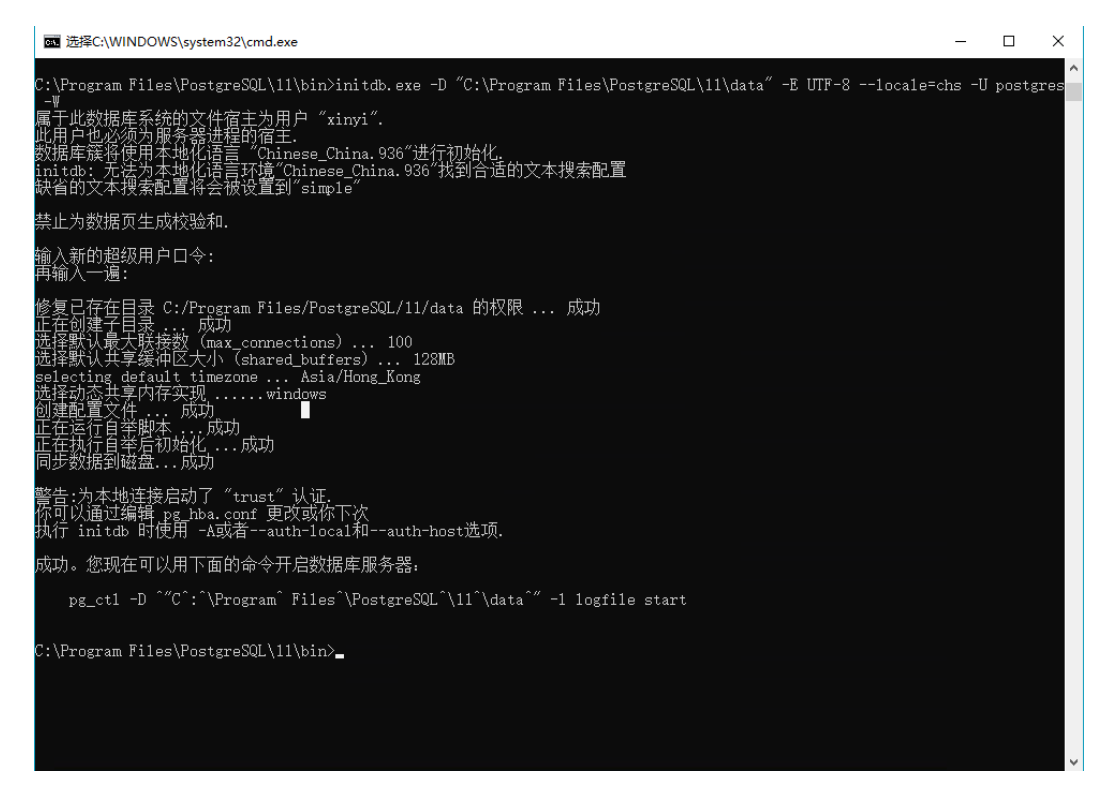
我装的时候反复报错,查了一下发现在一开始选择data为F盘时就在里面创建了一些文件,
需要回头把整个data文件夹都删掉,创建一个新的空的data文件夹,再创建一遍就成功了
换了网络后postgre启动不了
OperationalError: (psycopg2.OperationalError) could not connect to server: Connection refused (0x0000274D/10061)
Is the server running on host "127.0.0.1" and accepting
TCP/IP connections on port 5432?
办法:重启service中的 PostgreSQL
cd C:\Program Files\PostgreSQL\10\bin
pg_ctl start
start不行换pgctl_restart
添加新列
alter table schema_a.table_a add column descr varchar
如何设置自增id
看了两个小时终于解决了
先设置sequence

这个nextval设置在默认处一点用都没有,但是上面建立sequence的步骤是有用的,
之后建立以下查询并运行,是我在用英文搜索after setting sequence in postgresql the column still is null之后终于查到的,
下次遇到任何postgre问题我决定直接用英文搜stackoverflow,官方文档没解决任何问题
ALTER SEQUENCE sequence RESTART WITH 1;
UPDATE report_basic_info SET id=nextval('sequence');
两个stackoverflow链接:
R&postGRE
包
library(RPostgreSQL)
然后连接数据库并规定编码
drv <- dbDriver("PostgreSQL")
con <- dbConnect(drv, host="localhost", user= "postgres", password="#", dbname="postgres")
postgresqlpqExec(con, "SET client_encoding = 'gbk'")
导入表格
com_info = dbSendQuery(con, statement = 'SELECT * FROM listed_company')
com_info <- fetch(com_info, n = -1)
往数据库存入数据
dbWriteTable(con, "MyData", MyData)
Python&postGRE
基础sqlalchemy
# 导入包
from sqlalchemy import create_engine
import pandas as pd
from string import Template
# 初始化引擎
engine = create_engine('postgresql+psycopg2://' + pg_username + ':' + pg_password + '@' + pg_host + ':' + str(
pg_port) + '/' + pg_database)
query_sql = """
select * from $arg1
"""
query_sql = Template(query_sql) # template方法 df = pd.read_sql_query(query_sql .substitute(arg1=tablename),engine) # 配合pandas的方法读取数据库值 # 配合pandas的to_sql方法使用十分方便(dataframe对象直接入库)
df.to_sql(table, engine, if_exists='replace', index=False) #覆盖入库
df.to_sql(table, engine, if_exists='append', index=False) #增量入库
基础psycopg2
1.创建表
#!/usr/bin/pythonimport psycopg2 conn = psycopg2.connect(database="testdb", user="postgres", password="pass123", host="127.0.0.1", port="5432")print "Opened database successfully" cur = conn.cursor()
cur.execute('''CREATE TABLE COMPANY
(ID INT PRIMARY KEY NOT NULL,
NAME TEXT NOT NULL,
AGE INT NOT NULL,
ADDRESS CHAR(50),
SALARY REAL);''')print "Table created successfully" conn.commit()
conn.close()
2.插入记录
cur.execute("INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY) \
VALUES (1, 'Paul', 32, 'California', 20000.00 )");
3.select
cur.execute("SELECT id, name, address, salary from COMPANY")
rows = cur.fetchall()for row in rows:print "ID = ", row[0]print "NAME = ", row[1]print "ADDRESS = ", row[2]print "SALARY = ", row[3], "\n"print "Operation done successfully";
conn.close()
4.更新
cur.execute("UPDATE COMPANY set SALARY = 25000.00 where ID=1")
conn.commit
print "Total number of rows updated :", cur.rowcount
cur.execute("SELECT id, name, address, salary from COMPANY")
rows = cur.fetchall()for row in rows:print "ID = ", row[0]print "NAME = ", row[1]print "ADDRESS = ", row[2]print "SALARY = ", row[3], "\n"print "Operation done successfully";
conn.close()
5.删除
cur.execute("DELETE from COMPANY where ID=2;")
conn.commit
print "Total number of rows deleted :", cur.rowcount
cur.execute("SELECT id, name, address, salary from COMPANY")
rows = cur.fetchall()for row in rows:print "ID = ", row[0]print "NAME = ", row[1]print "ADDRESS = ", row[2]print "SALARY = ", row[3], "\n"print "Operation done successfully";
conn.close()
6.我自己的模板
# -*- coding: gbk -*-
import numpy as np
import pandas as pd
import psycopg2
from sqlalchemy import create_engine
from string import Template
import re
db_engine = create_engine('postgresql://postgres:###@127.0.0.1:5432/postgres')# 初始化引擎
x = pd.read_csv('report_basic_info.txt', delimiter="\t")
table='report_basic_info'
x.to_sql(table, db_engine, if_exists='replace', index=False)
postgre安装和使用(R&Python)的更多相关文章
- 【转】ubuntu下安装eclipse以及配置python编译环境
原文网址:http://blog.csdn.net/wangpengwei2/article/details/17580589 一.安装eclipse 1.从http://www.eclipse.or ...
- SUSE Linux Enterprise 11 离线安装 DLIB 人脸识别 python机器学习模块
python机器学习模块安装 我的博客:http://www.cnblogs.com/wglIT/p/7525046.html 环境:SUSE Linux Enterprise 11 sp4 离线安 ...
- 【转】安装第三方库出现 Python version 2.7 required, which was not found in the registry
安装第三方库出现 Python version 2.7 required, which was not found in the registry 建立一个文件 register.py 内容如下. 然 ...
- 安装第三方库出现 Python version 2.7 required, which was not found in the registry
安装第三方库出现 Python version 2.7 required, which was not found in the registry 建立一个文件 register.py 内容如下. 然 ...
- A Complete Tutorial on Tree Based Modeling from Scratch (in R & Python)
A Complete Tutorial on Tree Based Modeling from Scratch (in R & Python) MACHINE LEARNING PYTHON ...
- python 安装 easy_intall 和 pip python无root权限安装
http://www.cnblogs.com/haython/p/3970426.html easy_install和pip都是用来下载安装Python一个公共资源库PyPI的相关资源包的 首先安装e ...
- 7 Tools for Data Visualization in R, Python, and Julia
7 Tools for Data Visualization in R, Python, and Julia Last week, some examples of creating visualiz ...
- mongo db安装和php,python插件安装
安装mongodb 1.下载,解压mongodb(下载解压目录为/opt) 在/opt目录下执行命令 wget fastdl.mongodb.org/linux/mongodb-linux-x86_6 ...
- NLP︱高级词向量表达(一)——GloVe(理论、相关测评结果、R&python实现、相关应用)
有很多改进版的word2vec,但是目前还是word2vec最流行,但是Glove也有很多在提及,笔者在自己实验的时候,发现Glove也还是有很多优点以及可以深入研究对比的地方的,所以对其进行了一定的 ...
- odoo开发环境搭建(三):安装odoo依赖的python包
odoo开发环境搭建(三):安装odoo依赖的python包 http://www.cnblogs.com/jlzhou/p/5940815.html
随机推荐
- 微信小程序采坑之scroll-view
当设置了scroll-y为true之后,纵向是没有问题的,会出现滚动条. Android上一切都是那么的祥和, ios上你会发现如果你scroll-view里面的东西超过横向的宽度时,就会隐藏了. 也 ...
- Pro SQL Server Internal (Dmitri Korotkev)电子书翻译P8-14(12w)
数据行与数据列 数据库的控件逻辑上分成8KB的页,这些页从0开始,连续排序,对特定的文件ID和页码有借鉴意义.页码编号一定是连续的,当SQL服务器中的数据库文件增加时,新的数据页从最高的页码开始编码. ...
- Jave基本数据类型
基本类型,或者叫做内置类型,是JAVA中不同于类的特殊类型.它们是我们编程中使用最频繁的类型,因此面试题中也总少不了它们的身影,在这篇文章中我们将从面试中常考的几个方面来回顾一下与基本类型相关的知识. ...
- 内网渗透之权限维持 - MSF与cs联动
年初六 六六六 MSF和cs联动 msf连接cs 1.在队伍服务器上启动cs服务端 ./teamserver 团队服务器ip 连接密码 2.cs客户端连接攻击机 填团队服务器ip和密码,名字随便 ms ...
- python学习列表(Lists).基础二
列表(Lists) 序列是Python中最基本的数据结构,序列中的每个元素都分配一个数字,它的第一个索引是0第二个索引是1,依次类推. 列表是最常用的Python数据类型,它可以作为一个方括号内的逗号 ...
- Ubuntu部署Asp.net core网站无法访问
前几天应工作需要,在阿里云上部署一个测试站点.本以为分分钟的事情,没想到打脸了. 当时直接新建一个webapi项目,publish后直接上传到阿里云,随后设置nginx转发网站端口5000. 接着打开 ...
- 网页中三角型的CSS实现
我们在使用CSS框架的时候,经常会用到下拉框组件,一般该组件里面有个下三角.很多网上用到三角形,如图所示,这个三角形是如何实现的呢? 1.使用CSS可以实现,先来复习一CSS盒子模型相关知识.给出如下 ...
- lesson01
题目: Action3: 统计全班的成绩 班里有5名同学,现在需要你用numpy来统计下这些人在语文.英语.数学中的平均成绩.最小成绩.最大成绩.方差.标准差.然后把这些人的总成绩排序,得出名次进行 ...
- 【Python】pyinstaller打包运行报错failed to execute script main
前言 最近用pyinstaller打包的时候一直报"failed to execute script main". 最终使用"pyinstaller --hidden-i ...
- (转)浅析epoll – epoll例子以及分析
原文地址:http://www.cppfans.org/1419.html 浅析epoll – epoll例子以及分析 上篇我们讲到epoll的函数和性能.这一篇用用这些个函数,给出一个最简单的epo ...